了解 ignore_above 参数对 Elasticsearch 中磁盘使用的影响
在 Elasticsearch 中,ignore_above 参数允许你忽略(而不是索引)长于指定长度的字符串。 这对于限制字段的大小以避免性能问题很有用。 在本文中,我们将探讨 “ignore_above” 参数如何影响 Elasticsearch 中字段的大小,并将比较两个不同的 ignore_above 参数之间的磁盘使用情况。

首先,我们创建一个名为 “test_index” 的索引,其中包含三个字段:“field_ignore_above_4”、“field_ignore_above_256” 和 “field_ignore_above_512”。 每个字段的类型都是 “keyword”,并且具有不同的 “ignore_above” 设置:
PUT test_index
{
"mappings": {
"properties": {
"field_ignore_above_4": {
"type": "keyword",
"ignore_above": 4
},
"field_ignore_above_256": {
"type": "keyword",
"ignore_above": 256
},
"field_ignore_above_512": {
"type": "keyword",
"ignore_above": 512
}
}
}
}接下来,我们将文档插入到 `test_index` 中:
PUT test_index/_doc/1
{
"field_ignore_above_4": "some value",
"field_ignore_above_256": "some value",
"field_ignore_above_512": "some value"
}当我们对 “test_index” 执行搜索时,我们可以看到 “field_ignore_above_4” 被忽略,因为它的值超出了 “ignore_above” 限制:
GET test_index/_search
响应显示 “field_ignore_above_4” 被忽略。这是因为 "some value" 的字符串长度超过 4。
我们做如下的查询:
GET test_index/_search
{
"query": {
"term": {
"field_ignore_above_256": {
"value": "some value"
}
}
}
}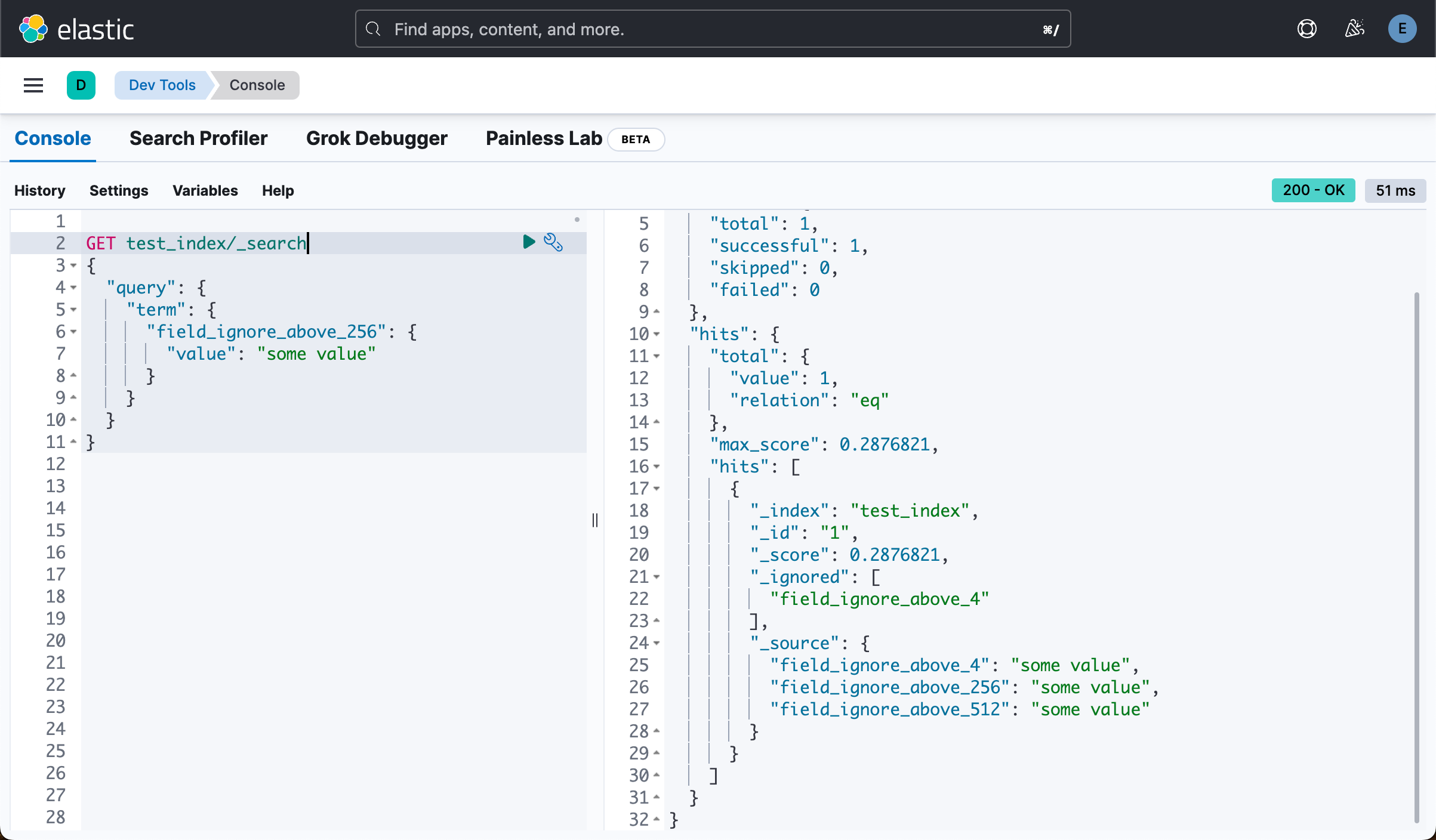
上面显示是有一个文档的。我们如下针对字段 field_ignore_above_4 来做查询:
GET test_index/_search
{
"query": {
"term": {
"field_ignore_above_4": {
"value": "some value"
}
}
}
}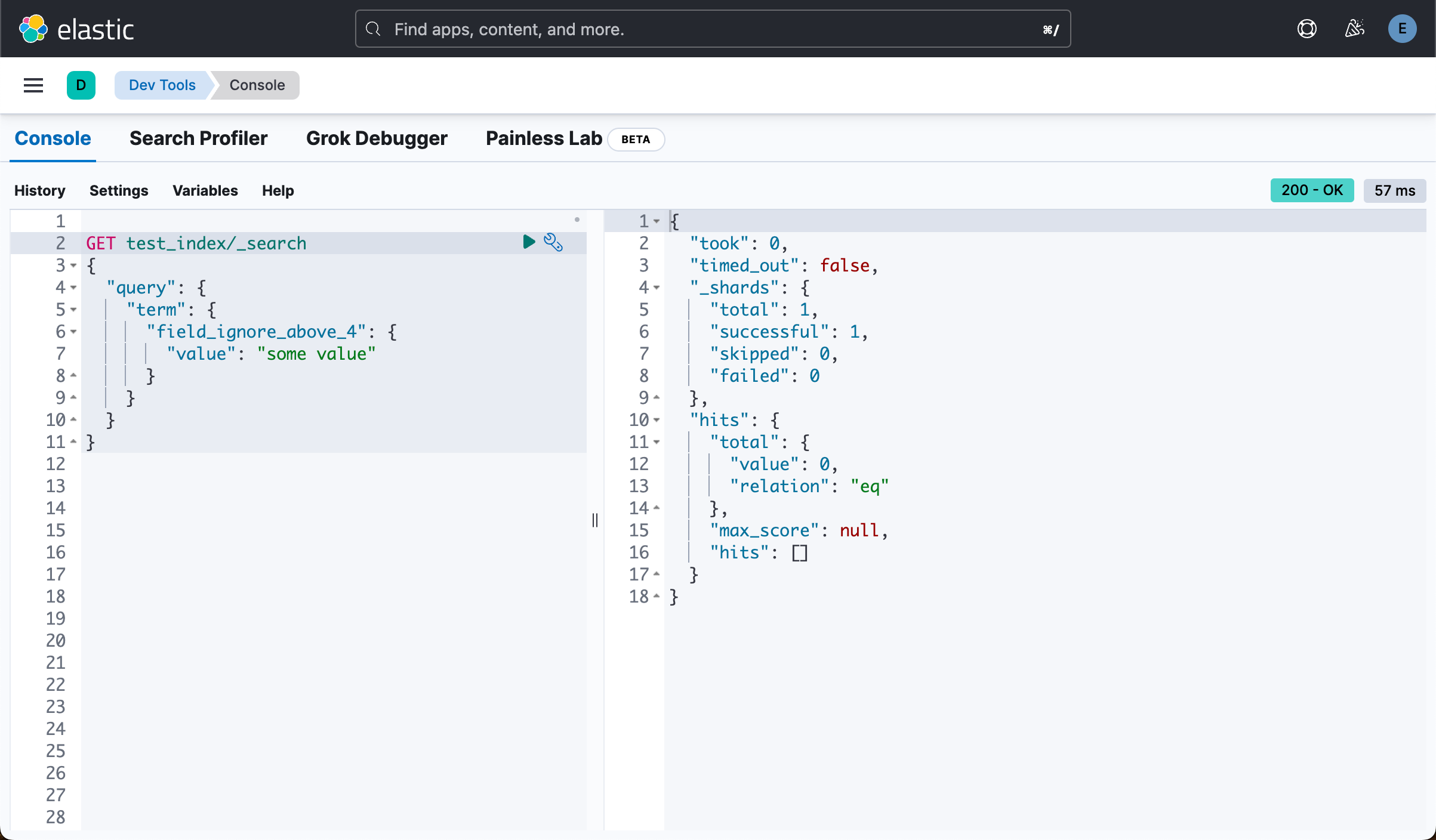
上面是不显示任何的文档的。这说明这个 field_ignore_above_4 字段确实是被忽略了。
现在,我们可以使用 “_disk_usage” API 计算字段的大小:
POST /test_index/_disk_usage?run_expensive_tasks=true&filter_path=**.fields.field*响应提供有关每个字段大小的详细信息:
{
"test_index": {
"fields": {
"field_ignore_above_256": {
"total": "30b",
"total_in_bytes": 30,
"inverted_index": {
"total": "19b",
"total_in_bytes": 19
},
"stored_fields": "0b",
"stored_fields_in_bytes": 0,
"doc_values": "11b",
"doc_values_in_bytes": 11,
"points": "0b",
"points_in_bytes": 0,
"norms": "0b",
"norms_in_bytes": 0,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
},
"field_ignore_above_512": {
"total": "30b",
"total_in_bytes": 30,
"inverted_index": {
"total": "19b",
"total_in_bytes": 19
},
"stored_fields": "0b",
"stored_fields_in_bytes": 0,
"doc_values": "11b",
"doc_values_in_bytes": 11,
"points": "0b",
"points_in_bytes": 0,
"norms": "0b",
"norms_in_bytes": 0,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
}
}
}
}从响应中,我们可以看到 field_ignore_above_256 和 field_ignore_above_512 的总大小相同,均为 30 字节。
有趣的是,“field_ignore_above_4” 不包含在磁盘使用统计信息中,因为它在索引过程中由于 “ignore_above” 设置而被忽略。 这演示了如何使用 “ignore_above” 参数来控制字段的大小并优化 Elasticsearch 存储的使用。