一文吃透Http协议
Http 协议
1. 初始 Http
Http 协议 , 是应用层最为广泛使用的协议 , Http 就是浏览器和服务器之间的桥梁. Http 是基于 TCP 协议实现的 ,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9HGwWb3V-1681167552380)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402150600543.png)]](https://img-blog.csdnimg.cn/ef4fa8ee683a46fb9b71216e07196133.png)
通常我们输入搜索框中的网址 (URL) , 浏览器就会根据这个 URL 构造出一个 Http 请求 , 发送给服务器. 服务器就会返回一个 Http 响应(包含 html, css , js) , 浏览器再把得到的 html 等数据显示出来(渲染) , 这也就是为什么 http 被称为超文本传输协议 , 因为传输的不仅仅是文本.

2. fiddler 抓包
http 协议的详细交互过程 , 可以借助第三方工具 fiddler , 来抓包.
fiddler 本质是一个代理程序 , 使用时注意事项:
- 可能和别的代理程序冲突 , 使用时要关闭其他的代理程序(包括一些浏览器插件)
- 想要正确抓包还需开启 htpps 功能 , 当前互联网绝大多数服务器都是 https 的 , fiddler 默认不能抓 https 的包 , 需要手动启动 https 并安装证书.
打开 csdn , fiddler 会抓取很多的请求 , 通常蓝色是 html 主页 , 绿色是 , 黑色是单纯的返回数据. 浏览器再解释执行 html 和 js 的时候 , 遇到一个请求就发送一个.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Yf8qzM9-1681167552381)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402153932443.png)]](https://img-blog.csdnimg.cn/d79b0ff85ccf426ebc9b81c39bf6b20e.png)
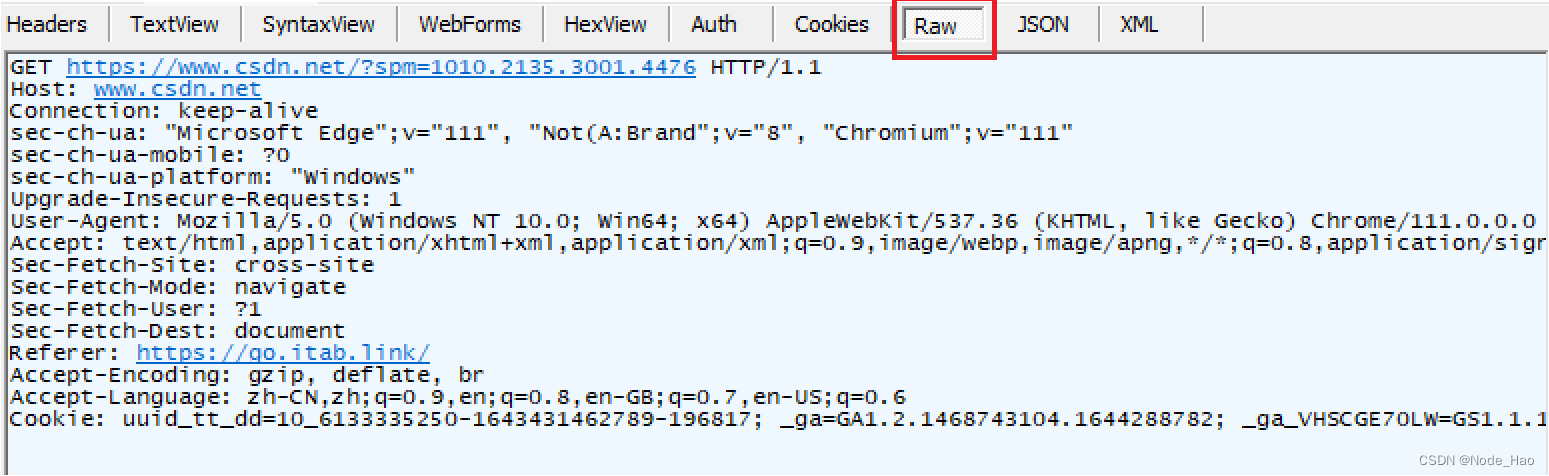
http 请求 , 有一定的格式. fiddler 会按照格式解析 , 会呈现出不同的效果 , 点击raw就可以看到最原始的效果. view in Notepad 可以看到更详细的页面.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ReedsO3E-1681167552381)(https://gitee.com/liu-xuixui/clouding/raw/master/img/image-20230402154850128.png)]](https://img-blog.csdnimg.cn/542c82a2e19743d19f2e0907b817fb02.png)
观察抓包结果 , 可以看到 , 当前 http 请求 , 其实是个行文本格式的数据.
响应数据本来也是文本 , 但有的服务器会对响应进行压缩.( 为了节省带宽)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mB8PmlF1-1681167552381)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402155556420.png)]](https://img-blog.csdnimg.cn/1d3057562d89403186bbe3f30cf6c377.png)
手动解压缩之后 , 我们就可以看到 csdn 主页的文本数据 , 也就是 html 的内容.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BE39vsTO-1681167552381)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402155848921.png)]](https://img-blog.csdnimg.cn/30d6be1b8b494011aa62c2f19cd5a4a6.png)
3. Http 报文格式
学习一个协议 , 本质上就是了解它的报文格式.
1. Http 请求
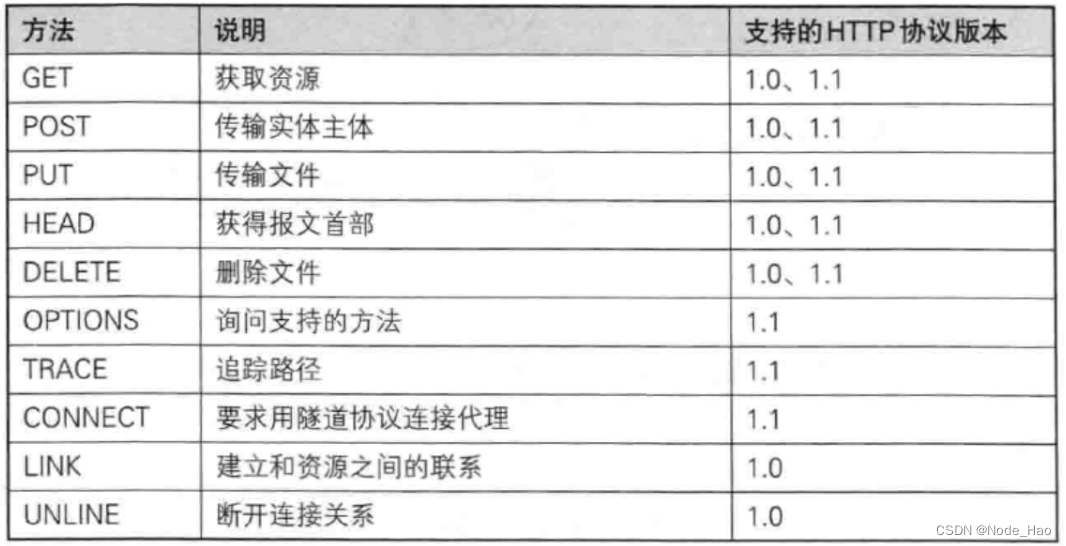
http 请求可以分为 4 部分:
- 首行
- 请求头(header)
- 空行
- 正文(body)
首行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QCqdA4c3-1681167552382)(https://gitee.com/liu-xuixui/clouding/raw/master/img/image-20230402160140301.png)]](https://img-blog.csdnimg.cn/14fea61e12f84a8abd657764d30dabbc.png)
首行包含三个部分. 之间使用空格来区分.
-
GET: http 的方法(method)
-
URL: 也就是唯一资源定位符. 标识互联网上唯一资源的位置(在哪个服务器的哪个目录下的哪个文件) , URI 唯一资源标识符 , 为了和别的资源区分开. 实际上 URL 也可以视为是一个 URI. 开发中常常混用. URL 不是 http 专属的. 很多协议都可以使用 URL.
-
版本号: HTTP/1.1
认识URL
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vaveWDUw-1681167552382)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402161403398.png)]](https://img-blog.csdnimg.cn/65ace1e7b6584af9a54da12fee08aebc.png)
举个例子: 假设我在学校餐厅租了一个档口卖重庆小面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mf2u2jmK-1681167552382)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402165600981.png)]](https://img-blog.csdnimg.cn/7cb9932f700046998af7386084f2abc5.png)
一个 URL 有些部分是可以省略的:
例如:
-
端口号可以省略 , 浏览器提供默认端口. 对于 http 来说默认端口是 80 , 对于 https 来说默认端口是 443.
-
/ 代表 http 服务器的根目录 , http 服务器是系统上的一个进程. 于是委托这个服务器管理系统上的一个特定目录 , 这个目录里的资源都可以让外界进行访问.(服务器管理的根目录 , 可以是系统上任意一个地方 , 具体根据服务器配置)
-
查询字符串也是可有可无 .
查询字符串以 ? 开头 , 以键值对的形式组织 , 键值之间用**&分割 , 键和值之间用=**分割. 有时 URL 有些字符是由特点含义的 , 就需要对内容重新编码 , 通常使用urlencode(转义字符) , 如果不编码直接写中文 , 浏览器可能无法识别.
认识方法(Method)
实际开发中 , 这里的方法 , 大部分都是用不到的. 最常见的就是 GET 和 POST.
GET 触发场景:
- 在浏览器地址栏直接输入 URL
- html 里的 link , script , img , a…等标签
- 通过 js 来构造 get 请求.
GET 与 POST 的区别:
- 如果是 GET 请求 , 没有 body. POST 请求, 有 body. POST 的 body 中是程序员自定义的内容.
- GET 给服务器传递消息一般存放在 quert string , POST 传递消息则是通过 body.
- GET 请求一般从服务器获取数据 , POST 一般是用于给服务器提交数据.
- GET 通常情况下是幂等的 , POST 则不做要求.(相同的输入 , 结果也是确定的 )
- GET 可以被缓存 , POST 则一般不能被缓存.(缓存的前提是幂等)
实际上GET 与 POST 的区别只是一个习惯用法 , 很多场景下彼此都可以替换.
认识 header
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oJFh33yD-1681167552382)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402195614835.png)]](https://img-blog.csdnimg.cn/5ceb2dc7271c4ac89c1b8cf9fb9e9c74.png)
header 里的键值对都是 http 事先定义好的 , 有特定含义.
-
HOST: 描述了服务器所在的地址 和 端口 , 用来描述你最终要访问的目标 , 通常情况下内容和 URL一样.
-
Content-Length: 表示 body 中的数据长度.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I8VzgZ9s-1681167552382)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402200059839.png)]](https://img-blog.csdnimg.cn/2a1d9a86aaee412fb8ba398d28dda1a6.png)
- Content-type: 表示请求的 body 中的数据格式. 常见的格式有 json 和 form等.

- User-Agent (简称 UA)
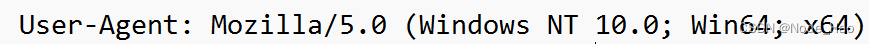
描述了浏览器和操作系统的版本 , 早起浏览器只支持文本 , 后来支持各种图片 , 音频, js … 对于网站开发者来说 , 开发网页时是否支持这些新功能是个问题 , 后来提出解决办法 , 那就是发布不同的版本来适用各种浏览器 , 根据 User-Agent 就可以解决这个问题 , 后来浏览器的差别小了 , User-Agent 主要用来区分是移动端还是PC 端.
- Refer: 表示当前页面"来源" , 如果直接在地址栏搜索 , 收藏夹等 , 则没有Refer.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wG2aD2WK-1681167552383)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230402204445933.png)]](https://img-blog.csdnimg.cn/8434285e926b4cd9ad063e5b877a94bd.png)
广告计费服务 , 广告主的页面会有许多其他网站转过来 , 为了更好的结算计费 , 广告主只需通过 refer 记录日志即可. 但是 http 本身明文传输 , 会遭到运营商劫持将refer篡改成其他的.
- Cookie: 本质上是浏览器给网页提供的本地存储数据机制 , 为了保证安全 , 网页默认是不允许访问到计算机的本地硬盘. cookie 浏览器对于访问硬盘作出了明确限制 , 通过键值对方式来组织数据.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-amgINwYc-1681167552383)(https://gitee.com/liu-xuixui/clouding/raw/master/img/image-20230402204537742.png)]](https://img-blog.csdnimg.cn/4f1d371e5eb64e47b681b76d708b445e.png)
Cookie 中具体存啥内容 , 由程序员自定义.这里是数据是啥意思 , 只能由开发的程序员知道.
Cookie 从哪里来? Cookie中的数据来自服务器 , 服务器会通过 ==http 响应的报头==部分(set-cookie 字段) , 来决定浏览器的 Cookie 要存什么.
Cookie 存在哪里? 可以认为存在于硬盘上 , Cookie 在存的时候 , 是按照浏览器 + 域名的纬度来进行细分的. 不同的浏览器各自存各自的 cookie , 同一个浏览器的不同域名 , 对应不同的 Cookie. 同时Cookie 还有过期时间 , eg: 很多网站登录一次会自动记录登录状态.
Cookie 要到哪里去? 客户端会通过Cookie 来保存用户使用的中间状态 , 当客户端访问浏览器的时候 , 就会自动把 Cookie 中的内容带入到请求中 , 服务器就知道客户端的状态.Cookie 里存的往往是"上下文" 这样的状态 , 当浏览器保存好 cookie后 , 后续再给服务器发送请求时 , 就会自动带上 . cookie 就像是服务器在浏览器这边搞的一个寄存处一样的东西.
认识请求正文
正文中的内容和header 中的Content-Type密切相关 , 常见以下三种:
- application/x-www-form-urlencode
- multipart/form-data
- application/json
2.Http 响应
响应由四个部分组成:
- 1.首行

- 2.header
- 3.空格 表示 header 的结束标记
- 4.body
Http 状态码: 描述了这次响应的结果.(成功?失败?失败原因是啥?)
常见:
-
200 ok 成功了.
-
404 NotFound 访问的资源不存在 , 服务器上没找到.
-
403 Forbidden 访问被拒绝(没有权限)
-
302 Move temporarily 重定向 , 旧域名跳转到新域名. 302 这样的响应报文 , 会在 header 里带个 Location 属性 , 通过这个属性来描述要跳转到哪个地址.
重定向: 是 http 提供的机制

请求转换: 是spring 和 servlet 中提供的机制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4ZMqNscV-1681167552383)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230403093731905.png)]](https://img-blog.csdnimg.cn/c6c89ddc007c46eca68831ba47f9d813.png)
重定向与请求转发的区别:
重定向可以可以重定向到外部资源(跳转到别的网站) , 请求转发只能在该服务内部的资源之间转发 , 少了一次交互更加高效.
- 500 服务器内部错误 (服务器代码抛异常了)
- 504 gateway timeout (响应时间太久 , 浏览器等不急了)
gateway 网关 , 代表一个网络的入口/出口. 想要访问一个服务器中的内容 , 需要先经过网关 , 通常也用来代指一个机房的入口服务器.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QKaD0zru-1681167552384)(C:/Users/86178/AppData/Roaming/Typora/typora-user-images/image-20230403091004101.png)]](https://img-blog.csdnimg.cn/ff4259b9b20e4b7d8a7f4feec18a27b9.png)
综上: 2** 成功 , 3** 重定向 , 4** 客户端错误 , 5** 服务器错误
认识响应报头(header)
响应报头和请求报头的格式基本一致. 类似于 Content-Type 和 Content-Length 等属性的含义和请求也基本一致.
认识响应"正文"(body)
正文的格式取决于 Content-Type
由于返回响应会传递 html , css , js , 图片等. 因此会多几种数据格式:
- text/html: body 数据格式是 html
- text/css: body 数据格式是 CSS
http 协议报文格式总结:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-REthwgkx-1681167552384)(https://gitee.com/liu-xuixui/clouding/raw/master/img/image-20230403100530328.png)]](https://img-blog.csdnimg.cn/9b8b7326a02e4304ac13081fa3fe3b20.png)