淘宝用户体验VOC标签体系

本专题共10篇内容,包含淘宝APP基础链路过去一年在用户体验数据科学领域(包括商详、物流、性能、消息、客服、旅程等)一些探索和实践经验。
在商详页基于用户动线和VOC挖掘用户决策因子带来浏览体验提升;在物流侧洞察用户求助时间与实际物流停滞时长的关系制订表达策略带来物流产品满意度提升;在性能优化域构建主客观关联模型找到启动时长与负向反馈指标的魔法数字以明确优化目标;构建多源VOC标签体系综合运用用户行为和用户VOC洞察、落地体验优化策略,并总结出一套用户体验分析方法论。

前言
本文为此系列第六篇文章,前五篇见——
第一篇:淘宝用户体验分析方法论
第二篇:VOC数据洞察在淘宝详情页的应用与实践
第三篇:物流产品体验诊断与优化
第四篇:BPPISE数据科学案例框架
第五篇:数据驱动性能体验优化
▐ 什么是VOC标签
VOC数据指淘宝电商的用户原声数据,是消费者在进行电商业务过程中产生的咨询、沟通、评价、吐槽、投诉等非结构化数据;VOC标签建设即基于NLP技术对海量的VOC数据进行语义挖掘,对用户原声进行整理、分类,将VOC数据反映出来的问题体系化地呈现出来,帮助洞察消费者在淘宝的消费体验问题,落地驱动生意正向增长的体验数据解决方案。
▐ 淘宝VOC标签的特点与问题
当前淘宝的VOC原声数据基本特点为源头分散,形态多样。首先在原声来源上,分散在商家客服、心声库、千牛、小蜜、评价、吐槽吧等不同的端,不同来源的文本数据在处理上分别有各自的策略,给数据整合工作带来一定挑战。同时文本包含会话、单条评价、长文本、机器人知识性聊天文本等模态,由于文本产生的源头不同,文本本身的特征也多有不同,对语义挖掘带来了技术挑战。
同时,对于淘宝的VOC标签,各业务部门多年来已积攒下多批标签,但多为各独立业务解决自身问题而设计,在设计上存在严重的异构问题,可复用性较低,很少开放给公域,同时各行业下的行业化标签基本处于供给盲区。

淘宝用户体验VOC标签解决方案
针对淘宝用户VOC标签存在的问题,我们由业务需求驱动,建设了定义统一、丰富易用的淘宝VOC标签体系,解决了VOC标签来源、定义不统一造成的找标签难、用标签难的问题,在长期的标签生产实践中,沉淀了稳定的标签设计->标签评估->算法生产->服务开放的SOP,批量标签生产周期缩短至一周,标签生产准确率均保持在90%以上。
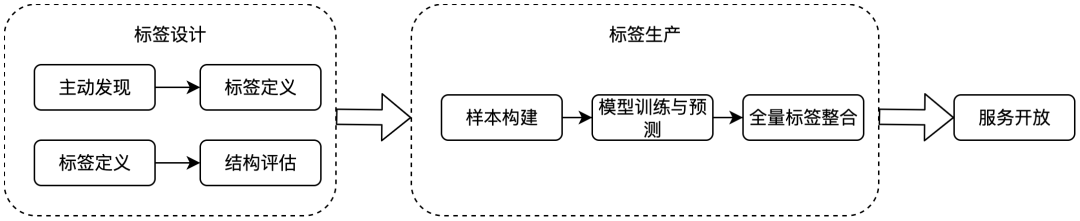
▐ VOC标签体系设计
在项目实施过程中,针对不同行业的实际场景诉求,每套行业标签结构的设计方法不尽相同,设计原则主要参照不同标签之间的对比跨度。因而在最终的标签体系设计中,需要结合不同行业标签结构的特点进行统一的设计。由此,我们将VOC标签体系整体结构设计为四级标签结构,其中一级至三级标签结构为通用型结构,在此基础上允许进行行业视角下的特色标签的定制,为定制型结构,即第四级标签,第四级标签以KV形式存储,允许为空。同时,四级标签和无子节点的三级标签定义为叶子标签,标签生产和维护聚焦叶子标签,允许用户根据业务场景自行定制标签结构,只需自行维护KV关系即可。
例如,一级标签按照淘宝消费者消费行为动线设计为商品咨询、活动价格、发货物流、服务咨询等域;二、三级标签基于一级标签域下钻,形成商品咨询->商品属性咨询->品牌的标签层级结构;四级标签为行业定制,如美妆:保湿补水。
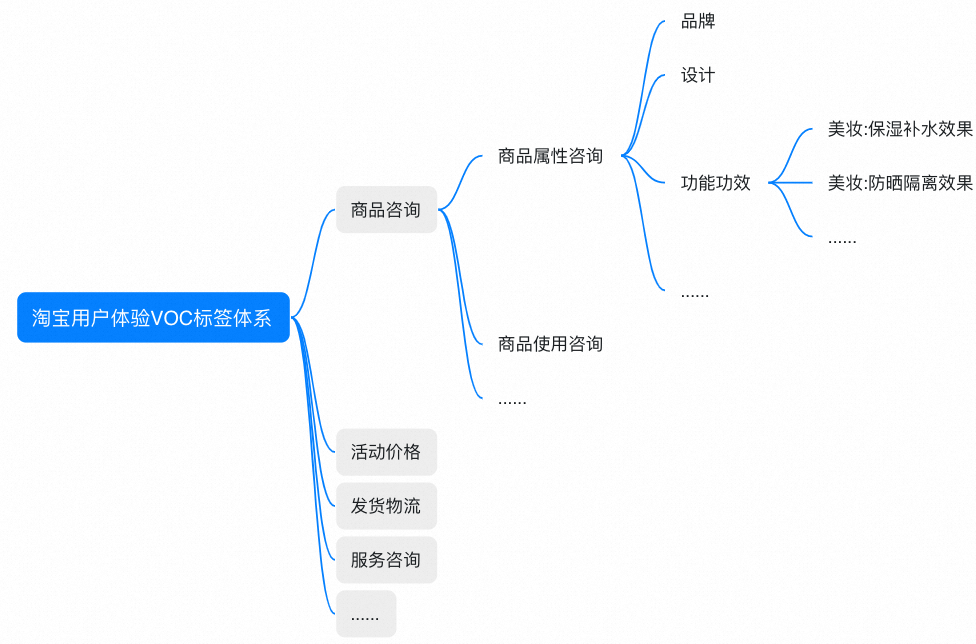
▐ VOC标签结构评估
为什么要进行标签结构评估
在项目过程中,初版标签树需求产出的方式,主要分为两种,一种是业务没有清晰标签结构定义,针对该情况通常先基于VOC文本聚类的结果产出大致的标签结构,业务需求方在此基础上确定最终标签需求,具体技术方案见【VOC标签主动发现】章节;另一种是业务有清晰的标签结构定义,本节主要针对该情况下的标签评估方案进行叙述。业务基于体验洞察场景的诉求,梳理提出所需标签后,需要对提出的标签体系作出技术侧的评估。即,业务侧的输入通常不考虑标签结构设计的合理性和实际的VOC原声数据的分布,往往会直接影响到标签生产的质量。
例如,在茶类目标签的初版设计中,有关茶香和口味的标签本属于不同层面的语义描述,但是在茶类目背景下,这些标签对应的VOC原声文本几乎都集中在<高香>、<回甘>、<特浓>等关键词为核心的描述上,即在茶这一领域,该类标签应当合并为同一标签;再如,有关适用人群和商品功效的标签,对应的VOC原声文本又集中在<脾虚>、<便秘>、<养胃>、<清火>等关键词为核心的描述上,即该类标签也应当合并为同一标签。
除此之外,存在标签定义粒度过粗等问题。因而技术侧需要基于对VOC数据的分析和探查,判断提来的标签结构设计是否合理,给出专业的合理性评估和调整策略。
标签结构评估面临的核心问题
对于标签结构的评估工作,最初时依靠人工,对样本集中每个标签对应的VOC数据进行人工分析,具体方法为根据样本数据构建<关键词词典>,对标签对进行1V1对比。该方法人力成本高,且主观因素影响较大,需要多方确认。对于n个标签,需要人工对比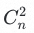 次,效率低下。因而需要建立起对标签结构评估的自动化流程,提高生产效率。由此,标签结构评估工作面临的两个核心问题为:
次,效率低下。因而需要建立起对标签结构评估的自动化流程,提高生产效率。由此,标签结构评估工作面临的两个核心问题为:
标签结构质量的衡量标准
标签结构评估的提效
标签结构评估解决方案
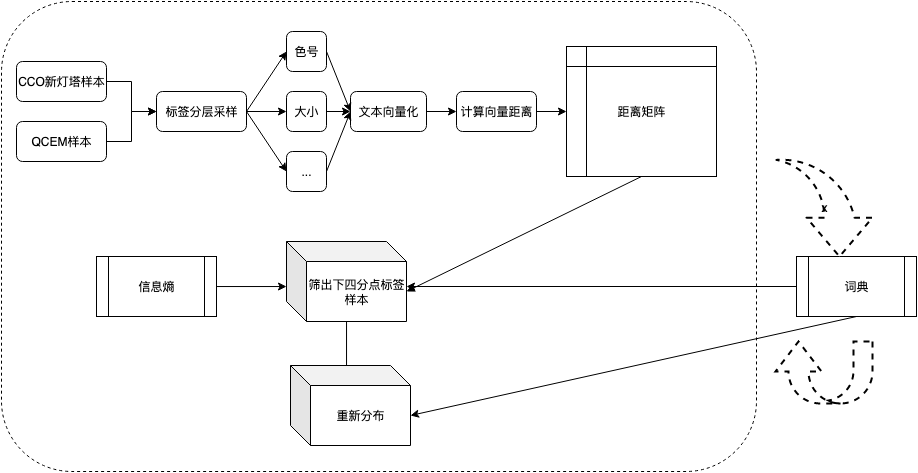
标签结构设计自动化评估的整体方案为:基于VOC样本集,按照标签进行分层采样,对文本进行向量化后,计算不同标签之间的文本距离,输出文本距离矩阵。之后对出先聚集情况的标签做重点分析,对需要重新设计的标签按照不同的合并方案进行调整,给出最优的标签结构。最后引入人工词典作最后校正,评估策略和调整方案的可靠性。
标签结构质量的衡量标准:经过对大量标签设计进行结构分析后,发现标签设计的主要问题是设计过程中经常出现设计粒度过细,部分标签区分度小。而一个好的标签体系结构,应当尽肯能少的出现标签语义聚集现象,即,整体标签对应的语义分布应当尽可能是均匀的,语义分布离散度尽可能小的。由此确定了标签结构质量的定性衡量标准,以形式化语言对该标准进行描述并将其转换为定量的数学问题,即为标签设计寻优的目标函数:
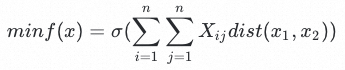
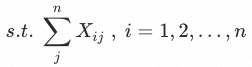
其中,n为标签数量,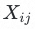 为不同标签的组合,dist为不同标签对应样本的文本向量距离,
为不同标签的组合,dist为不同标签对应样本的文本向量距离,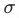 为方差计算。即用方差衡量分布离散度,因此标签结构设计的目标为令上述函数取值最小。
为方差计算。即用方差衡量分布离散度,因此标签结构设计的目标为令上述函数取值最小。
VOC文本采样策略:本节采用的策略为基于标签的分层采样,保证每个标签下的样本量一致。
VOC文本表示:对于文本表示,在标签结构质量评估中,经过对照实验,同时结合下文标签主动发现章节中进行的大量实验,确定基于文本向量距离矩阵做语义聚集分析的场景下,TF-IDF做文本向量化表示的计算结果最优。本阶段基于《电商评价分词词典》+《电商搜索分词词典》+TD-IDF计算输出m维文本向量。
标签文本向量距离矩阵及其分析:计算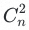 个标签对之间的欧式距离,形成标签距离矩阵。
个标签对之间的欧式距离,形成标签距离矩阵。
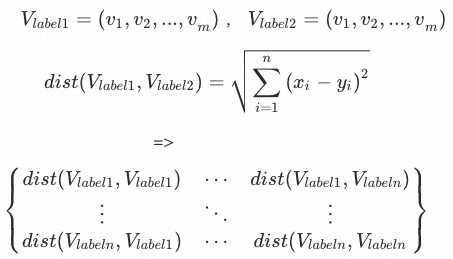
在得到距离矩阵后进行标签语义聚集现象的分析,首先是聚集的判定。在项目过程中,经过多组实验得到经验值,选择下四分位点的标签对作为待优化的标签候选集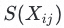 ,候选集中标签对数量为k。
,候选集中标签对数量为k。
标签结构优化策略:基于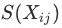 进行标签重组的优化。优化的策略为:
进行标签重组的优化。优化的策略为:
遍历所有二元重组方案,共2k次搜索
引入数据信息熵,计算每次重组方案
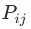 下,对标签结构全局的信息增益率
下,对标签结构全局的信息增益率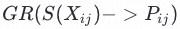
完成第一轮遍历,取信息增益率最大的重组方案
 ,并将对应的标签对从
,并将对应的标签对从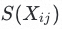 中移除
中移除基于
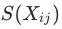 为空进行下一轮遍历,直至
为空进行下一轮遍历,直至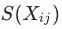
完成所有遍历后,计算标签结构全局分布离散度即目标函数,取最优方案,重组标签为k-
基于词典作最后确认,只需确认发生重组的k-个标签,对比工作量由
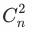 降为
降为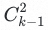
词典的构建:在项目过程中,构建了《淘宝电商评论词典》、《淘宝搜索词典》、《行业专业词典》等词典的构建过程为:
▐ VOC行业标签生产
算法路线选择
项目过程中,VOC行业标签的每次迭代都是百以上量级的标签,VOC文本标签生产的本质是判定式的分类模型训练。在标签数量过多的时候存在两种算法路线:
对n个标签训练n个二分类模型,基于n个二分类模型做标签结果判定,该路线优点是二分类模型准确率高,标签质量好且兼容多标签场景,缺点是效率太低。
对n个标签训练一个n分类模型,直接判定标签结果,该路线优点是在大规模标签生产中效率高,缺点是多分类随着类别数增加,准确率会不可避免的损失,且不兼容多标签场景。
算法架构方案
经过大量调研与比实验,最终确定自研标签生产的算法架构为:基于标签分组训练多个多分类模型,保障标签生产的质量与效率。
VOC训练样本的获取和处理
构建标签生产模型的第一步为构建带label的训练样本。整体方案如图
样本获取:最佳的方案应当是基于人工做数据集的标注,但基于项目迭代速度快、缺乏标注人力的现状,样本的原始获取手段为:基于能够获得到的淘内存量VOC数据及标签直接构造样本集,该方法优点为可以快速获得所需样本,缺点是本身各源头标签样本本身存在标注错误,基于该样本进行训练,不可避免的存在质量损失。为尽可能保证样本质量,只选择置信度>0.99的标签数据做样本;同时对于不同来源、不同模态的标签及数据做整合,整合策略见《VOC全量标签整合》章节。
采样策略:针对在标签数量多、同时要保障标签生产质量的问题,最终确定了基于标签分组训练多个多分类模型,因而在样本的采样策略上,也是以分组作为基础方案,同时重点解决样本集不平衡的问题。
首先对原始样本中所有标签对应VOC原声进行清洗,过滤噪声,之后观察其分布,尽可能的将原声量级相近的标签样本分到同组,即一个Group,同时限定
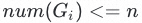 ,减少后续模型训练的复杂度。
,减少后续模型训练的复杂度。进行完上一步操作后,依然存在无法分组的标签,通常是存在原声量过多或过少的问题,是造成样本集不平衡的核心因素,针对存在这两个问题的标签分别进行降采样和过采样,缓解样本不平衡问题。
经过采样处理后,分组后的样本集
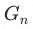 。
。
VOC文本的向量化表示
完成训练样本构造后需要对文本进行向量化计算,本项目根据不同的场景选择不同的方法进行文本表示,具体为
在标签结构评估场景下的文本距离计算、分类场景下的FT训练、 文本相似度计算中,首先使用之前构造的淘宝电商词典进行软干预分词,之后基于word2vec或tf-idf产出文本的词向量表示。
在深度训练中,基于BERT预训练模型,无需分词,直接输入文本,产出文本的句子向量表示。
VOC分类模型的训练与预测
算法训练及预测的框架如图:
训练阶段:
整体采用stacking集成框架,针对每个分组样本 训练最终模型
训练最终模型 ,基于FastText和txtCNN做stacking的基学习器,分别为
,基于FastText和txtCNN做stacking的基学习器,分别为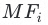 和
和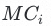 。
。
在stacking基学习器的内部采用Boosting集成方法,通过参数扰动,针对每个样本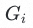 生成n个弱学习器队列,每个弱学习器队列中包含m个弱学习器,形成2个弱学习器矩阵。基于Boosting融合,最终得到两个强学习器队列分别为以下两个:
生成n个弱学习器队列,每个弱学习器队列中包含m个弱学习器,形成2个弱学习器矩阵。基于Boosting融合,最终得到两个强学习器队列分别为以下两个:
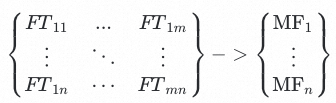

基于线性回归对两个强学习器队列做stacking融合,最终的模型队列:
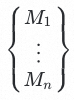
预测阶段:
将经过文本表示处理的待预测打标的VOC原声数据分别输入队列中的每个模型,模型输出预测结果队列
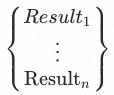
和预测的置信分数队列
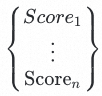
取分数最高的预测结果作为最终的标签预测结果。

VOC全量标签整合
对于淘内存量VOC标签的整合工作,核心解决数据和标签的多源问题,在项目过程中遇到的问题,主要是会话(session)和单聊、单评论的冲突,通常一段会话中包含多个语义,即多个标签;同时多处源头的原声数据为黑盒,其标签并未打到原声粒度,以轻度汇总形式存在,都对标签数据整合带来了挑战。具体的整合策略为:
对于商家客服的session,首先将其按照时间分拆为不同的touch,进一步去除废话、黄暴等文本,分拆成单条关键message,在粒度上和其他文本进行统一。
对分散的数据,按照一个buyer_id在一个time_stamp就一个item_id向一个seller_id的发起文本沟通的用户行为动线进行原声的关联。需注意,当用户是从详情页进入客服页面,item_id值不为空,当用户是从消息页进入客服页面,且session中不包含商品链接时,item_id为空。
对所有来源的VOC文本数据,基于生成的message_id,加上seller_id和时间戳生成MD5编码做弹内全局唯一标识primary_key。
标签整合:对淘内存量的VOC原声数据-标签进行分析后发现,不同源头的标签原声数据交集比例极低,即各方都是基于全量VOC原声中的某一子集做生产。因而对于不存在交集VOC原声-标签,可直接做拼接。存在交集的部分,以行业需求为最高优先级进行去重计算。
标签结构的维护
标签体系的结构以ODPS维表的形式维护,后续的项目迭代及整合均以该维表的变更为准
淘内各存量源头与标签体系的映射关系分别维护ODPS维表,供原始查询使用。

VOC标签主动发现
▐ 为什么要做标签主动发现
上文章节所述都是基于设计好的标签体系,对淘内的VOC数据进行标签生产,基于生产后的VOC原声进行分析,发现用户体验问题。而在实际的业务场景中,往往存在大量的未被定义、未被发现的问题,以体验平台产品为例,多个业务类别下,无法归档至已有标签的原声量占比高达40%-60%。同时,在实际需求对接过程中,也存在业务对所需的标签结构没有清晰定义的情况,此时也需要基于问题的主动发现结果给业务做选择题。对未被发现的体验问题做主动发现与定义,对于体验问题的洞察有巨大价值。
▐ 标签主动发现当前的技术路线
标签主动发现能力建设的主要技术路线为基于VOC文本聚类做问题发现,然后进行定义。以【详情】、【支付】等业务场景为试点进行落地,已初步具备规模化生产与交付的能力。
当前存在主要难点
聚类效果衡量指标(业务侧衡量指标)难以确定,技术侧采用纯度、兰德系数与F值来来衡量,但业务侧对聚类效果的衡量,在聚类簇数、聚簇分割的粗细程度上完全基于主观判断,不同的场景其判断标准并不一致;例如,在【详情】业务的聚类过程中,前后交付的版本中,20簇和40簇的分割均为正确分割,但业务侧实际使用过程中认为20簇太粗,40簇太细,之后采用DBSCAN、Brich等方法进行实验,无需指定簇数,但仍需输入半径等其他相关启动参数,且自动簇数的方式结果与需求方预期颗粒度并不匹配。我们基于现有场景做了大量技术调研,并进行了40余组对照实验后,确定了当前的技术路线。
当前实施的技术路线
主要探索了两条技术路线:
对于聚类算法启动时需要的eps、 min_samples、簇数等关键参数,以实验得到的经验值为基础,在做实际场景的聚类计算时基于经验值做微调,该路线优点是计算速度快,缺点是以存量实验为基础,在面对越来越多的下游场景时,经验值往往“不靠谱”。
对于聚类算法启动时需要的eps、 min_samples、簇数等关键参数,进行大范围的参数策略搜索,得到最优启动参数值,该路线的优点是保证参数策略最优解,缺点是需要消耗大量ODPS队列计算资源,运行速度慢。
在实际的项目中,暂时确定第二种路线作为主要的聚类实施方案,同时,考虑到聚类项目中存在大量基于场景的一次性计算的现象,为了保障聚类效果及提升开发效率,具体实施的方案为:
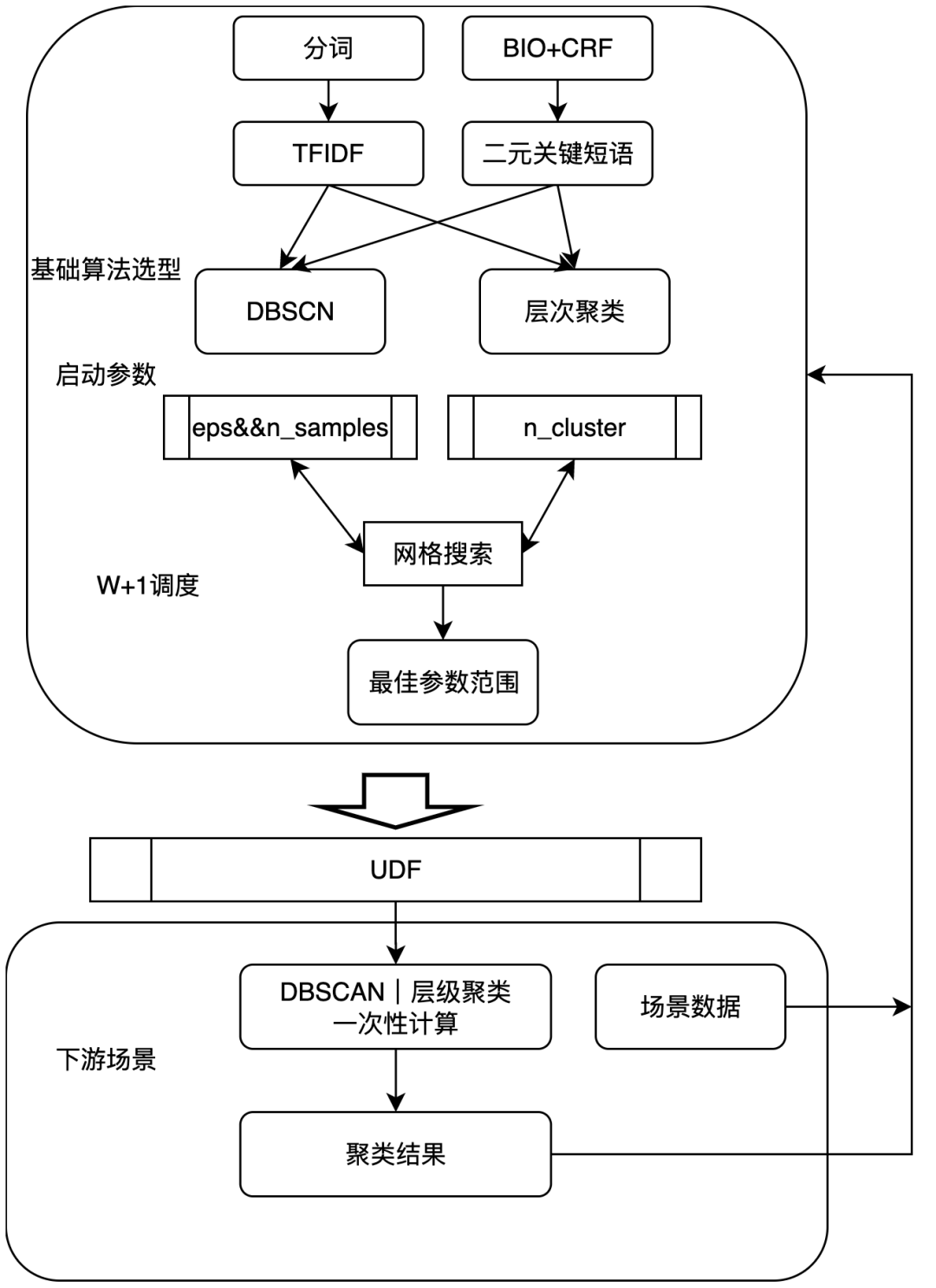
通过实验,确定在聚类中,文本表示的最佳方案为TFIDF和基于BIO+CRF生成的二元关键短语的方法。
算法选型综合考虑,确定DBSCAN和层级聚类作为基本聚类算法。对于DBSCAN启动所需的半径、最小样本数参数组,层次聚类所需的簇数参数,基于全量VOC数据,在大跨度范围内进行暴力搜索,得到最佳参数组,并进行存储。
将分词+TFIDF+最佳参数组封装为UDF函数提供给下游使用,仅支持DBSCAN和层级聚类,下游基于UDF中的最佳参数做一次性计算,快速得到聚类结果,允许进行小范围的参数微调。
下游完成一次性计算后,会将下游场景下进行聚类的文本数据及聚簇结果通过函数insert到线上VOC数据表中,次周将基于合并后的新数据集进行暴力搜索计算,得出新的最佳参数组。

VOC标签服务优化
交付模式优化
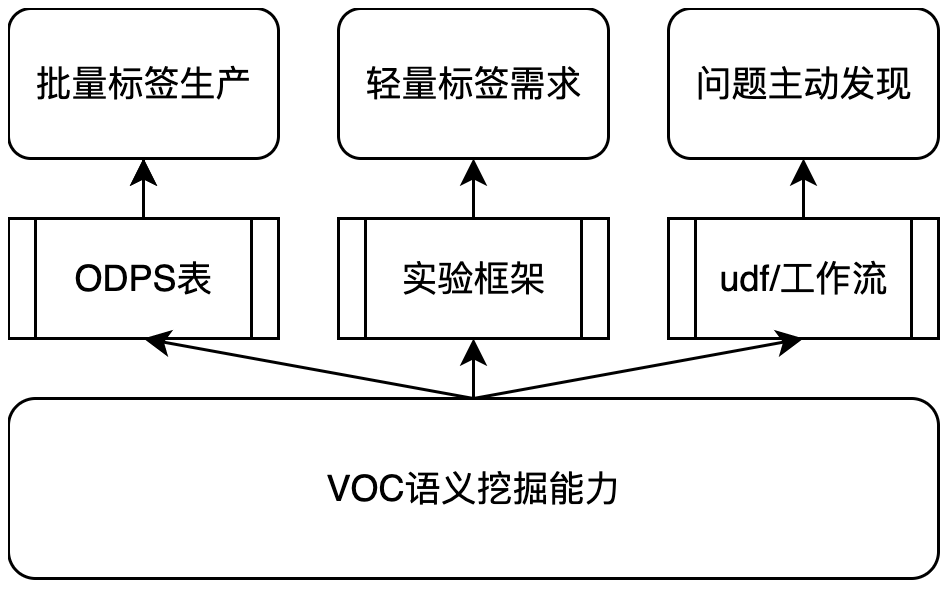
对于需要进行批量大规模训练生产的标签需求,如【详情行业化】,以标签生产结果ODPS表交付
对于轻量的标签需求,提供代码/成熟model/算法框架&&实验策略,供下游快速产出分析
对于聚类等需求,将动态参数的寻优、基础模型训练等复杂计算封装,提供UDF、D2工作流两种模式,供下游做一次性计算。

总结
我们以淘宝用户体验项目为驱动,建设了淘宝用户体验VOC标签体系,同时在生产过程中沉淀了一套稳定的标签生产SOP,行业标签生产周期缩短至一周左右。在支持用户体验项目及产品上发挥了VOC原声挖掘的价值。我们也会持续在VOC大模型应用、VOC标签服务化等方向上持续探索优化,欢迎大家多多交流。

团队介绍
我们是大淘宝技术行业数据技术团队,是集团内离业务最近的数据团队,团队深耕数据技术多年,在数据研发、数据挖掘、数据治理等方面都有丰富的经验,致力于围绕商家、商品、消费者、营销、行业等电商全域要素,面向淘宝天猫最复杂的业务场景提供全方位、多层次的数据服务。当前团队正在招聘中,欢迎拥有数据技术背景的同学加入。有兴趣可将简历发送至lyf222310@taobao.com。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法