bpftrace原理与使用方法
Bpftrace
- 概念和原理
- bpftrace安装
- bpftrace 语法结构
- bpftrace 变量
- 内置变量
- 自定义变量
- Map变量
- 内置函数
- Bpftrace操作案例
- 文件系统
- 磁盘
- 进程
- 内存
bpftrace是一种基于eBPF(Extended Berkeley Packet Filter)的跟踪工具,用于在Linux系统中进行动态跟踪和系统性能分析。理解bpftrace的概念、原理和使用方法有助于更好地使用和应用它。
概念和原理
- eBPF(Extended Berkeley Packet Filter):eBPF是一种虚拟机技术,允许在内核中运行安全的、可编程的代码片段,以便对系统执行深入的跟踪和监视。eBPF提供了一种灵活且高效的方式来扩展内核的功能,并允许用户空间应用程序与内核交互。
- bpftrace语言:bpftrace提供了一种高级脚本语言,使用类似于awk的语法,用于编写跟踪脚本。bpftrace脚本通过eBPF提供的虚拟机执行,可以捕获和分析各种系统事件和指标。
- 动态加载和执行:bpftrace的一个关键特性是它可以在运行时动态加载和执行脚本,而无需重新编译内核或应用程序。这使得它非常适合于实时系统性能分析和故障排查。
bpftrace安装
根据你的Linux发行版和版本,使用包管理器(如apt、dnf、yum等)安装bpftrace(我使用的是Ubuntu):
sudo apt install bpftrace
bpftrace 语法结构
bpftrace 的语法结构是参考 awk 的。
probes /filter/ { action }
probes :事件,tracepoint, kprobe, kretprobe, uprobe。两个特殊事件BEGIN/END,用于脚本开始和结束处执行
filter :过滤条件,事件触发时,判断条件,例如:/pid == 3245/,表示 pid为 3245 的进程执行。
action :具体执行的操作,例如:{ printf(“close\n”);} 打印 close
probes

案例:
bpftrace -e 'BEGIN { printf("hello\n"); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_accept { printf("accept\n"); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_accept4 { printf("accept4\n"); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_connect { printf("connect\n"); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_read { printf("read\n"); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_write { printf("write\n"); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_close { printf("close\n"); }'
bpftrace 变量
内置变量
bpftrace 脚本常用变量如下:
uid:用户 id。
tid:线程 id
pid:进程 id。
cpu:cpu id。
cgroup:cgroup id.
probe:当前的 trace 点。
comm:进程名字。
nsecs:纳秒级别的时间戳。
kstack:内核栈描述
curtask:当前进程的 task_struct 地址。
args:获取该 kprobe 或者 tracepoint 的参数列表
arg0:获取该 kprobe 的第一个变量,tracepoint 不可用
arg1:获取该 kprobe 的第二个变量,tracepoint 不可用
arg2:获取该 kprobe 的第三个变量,tracepoint 不可用
retval: kretprobe 中获取函数返回值
args->ret: kretprobe 中获取函数返回值
自定义变量
以'$'标志起来定义与引用变量,例如:$idx = 0;
Map变量
Map 变量是用于内核向用户空间传递数据的一种存储结构,定义方式是以'@'符
号作为标志
@path[tid] = nsecs;
@path[pid, $fd] = nsecs;
Bpftrace 默认在结束时会打印从内核接收到的 map 变量
内置函数
exit():退出 bpftrace 程序
str(char *):转换一个指针到 string 类型
system(format[, arguments ...]):运行一个 shell 命令
join(char *str[]):打印一个字符串列表并在每个前面加上空格,比如可以用
来输出 args->argv
ksym(addr):用于转换一个地址到内核 symbol
kaddr(char *name):通过 symbol 转换为内核地址
print(@m [, top [, div]]):可选择参数打印 map 中的 top n 个数据,数
据可选择除以一个 div 值
bpftrace 内置了 map 对象操作函数,用于传递数据给 map 变量
count():用于计算次数
sum(int n):用于累加计算
avg(int n):用于计算平均值
min(int n):用于计算最小值
max(int n):用于计算最大值
hist(int n):数据分布直方图(范围为 2 的幂次增长)
lhist(int n):数据线性直方图
delete(@m[key]):删除 map 中的对应的 key 数据
clear(@m):删除 map 中的所有数据
zero(@m):map 中的所有值设置为 0
Bpftrace操作案例
注意:由于bpftrace需要访问内核资源,因此通常需要以超级用户(sudo)权限运行。
文件系统
统计调用 read 的次数:
bpftrace -e 't:syscalls:sys_enter_read {@[probe]=count(); }'

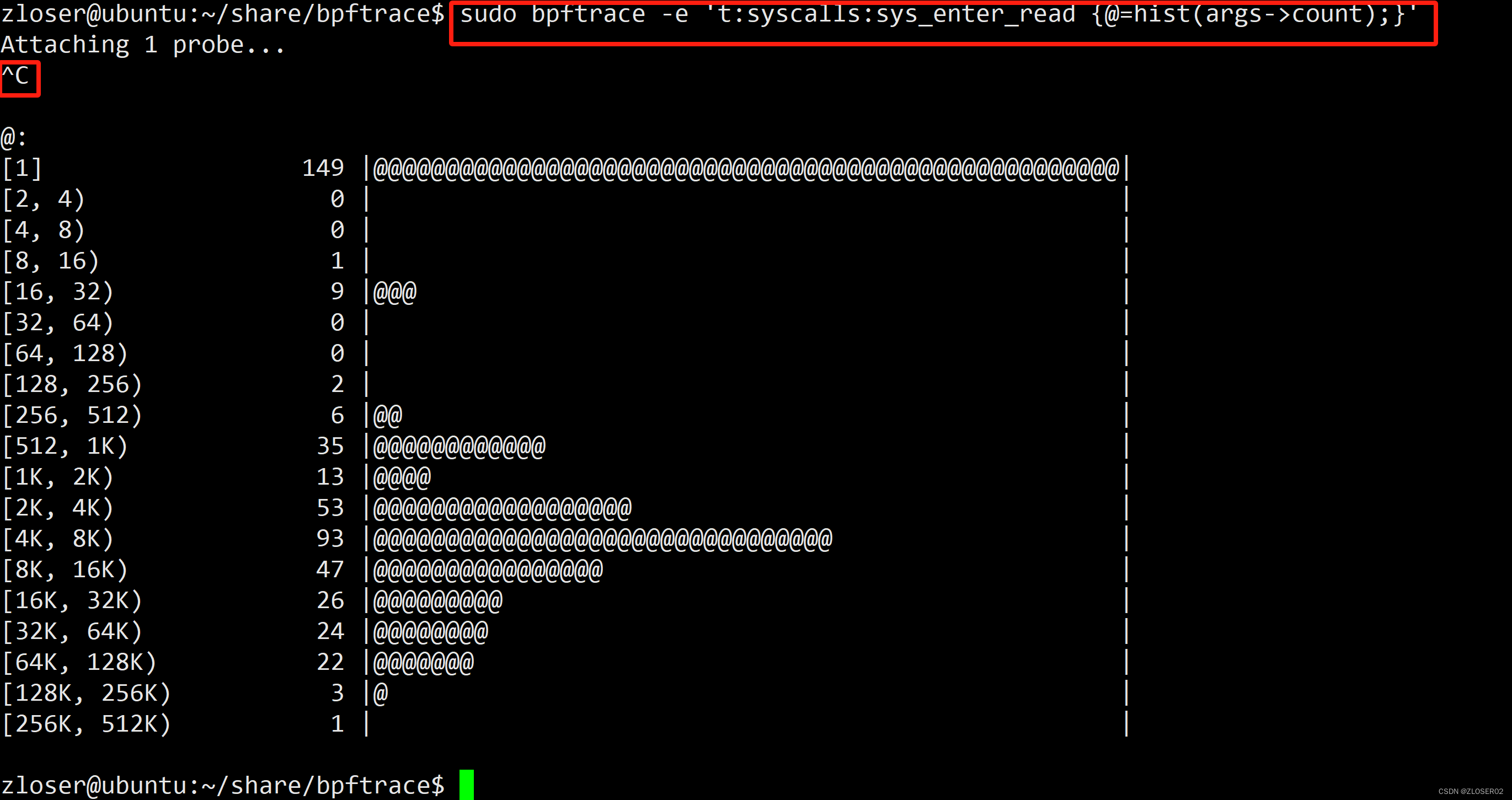
跟踪系统调用"read"的使用情况,并创建一个直方图来显示"read"系统调用的参数"count"的分布情况:
bpftrace -e 't:syscalls:sys_enter_read {@=hist(args->count);}'
跟踪系统调用"openat"的使用情况,并打印出调用该系统调用的进程名和打开的文件名:
bpftrace -e 't:syscalls:sys_enter_openat { printf("%s–> %s\n",comm,str(args->filename)); }'

通过脚本文件执行:
vim vfs.bt
#include <linux/fs.h>
#include <linux/path.h>
#include <linux/dcache.h>
kprobe:vfs_open
/ comm == "cat"/
{
printf("vfs_open: %s, name: %s\n", comm, str(((struct path*)arg0)->dentry->d_name.name));
}
kprobe:vfs_write
/ comm == "cat"/
{
$file = str(((struct file*)arg0)->f_path.dentry->d_name.name);
printf("vfs_write: %s, count: %d, buf:%s\n", $file, arg2, str(arg1));
}
执行:bpftrace vfs.bt
磁盘
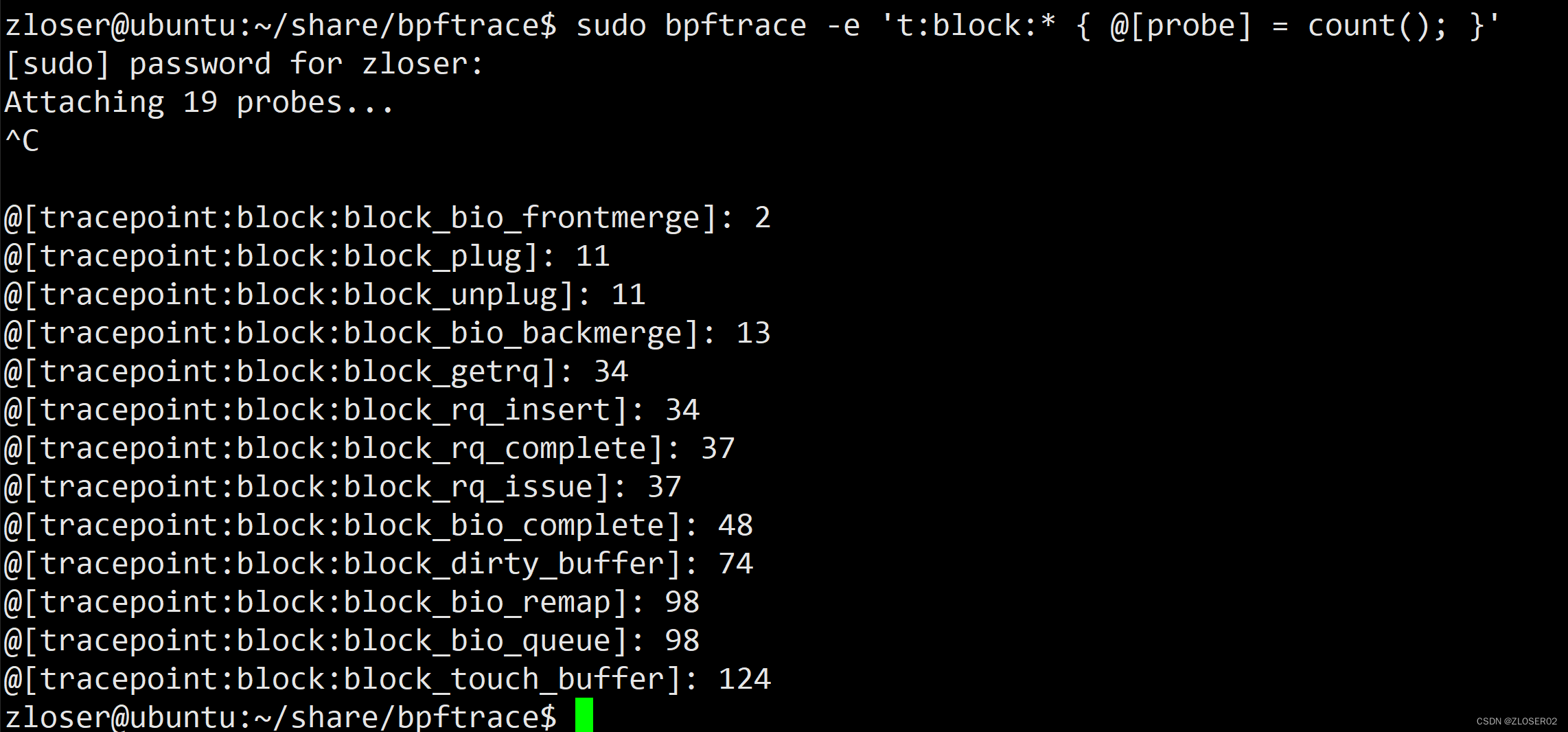
统计阻塞 io 事件:
bpftrace -e 't:block:* { @[probe] = count(); }'
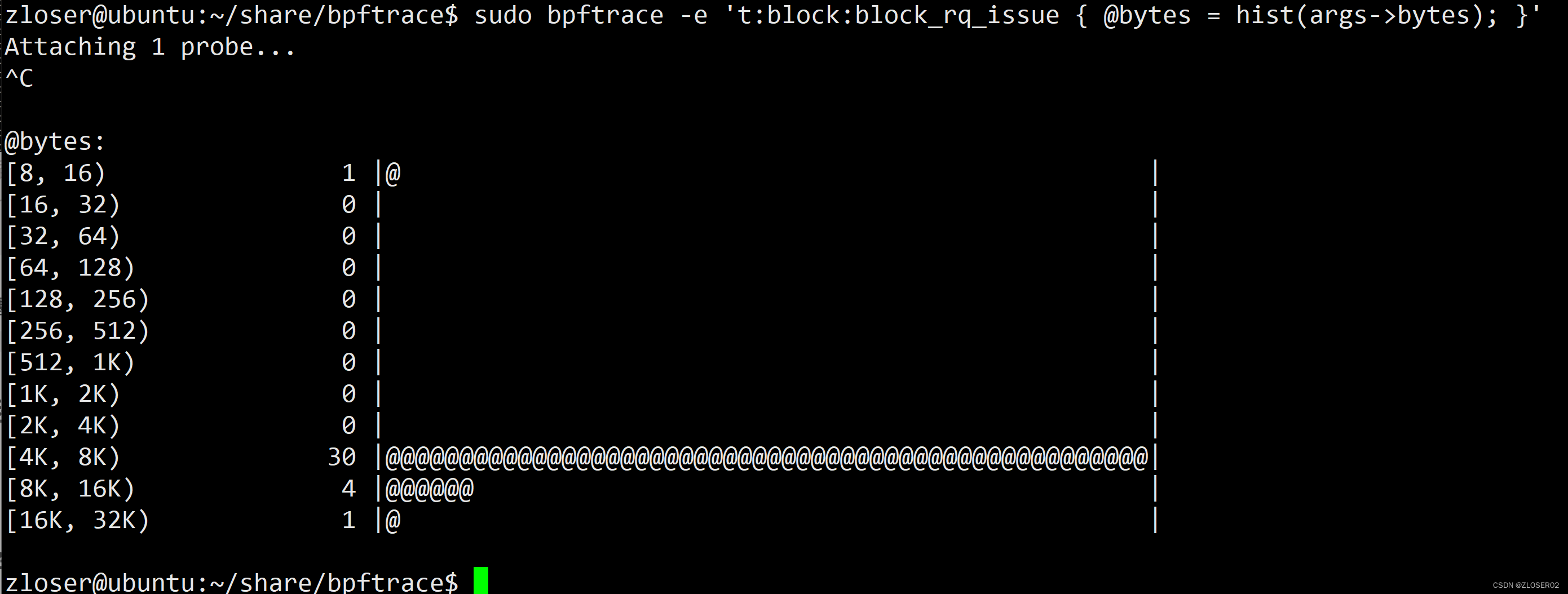
统计 阻塞 io 操作数据大小:
bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'
进程
启动的进程名与命令行参数:
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'

进程调度:
bpftrace -e 'tracepoint:sched:sched_switch { @[kstack] = count(); }'

内存
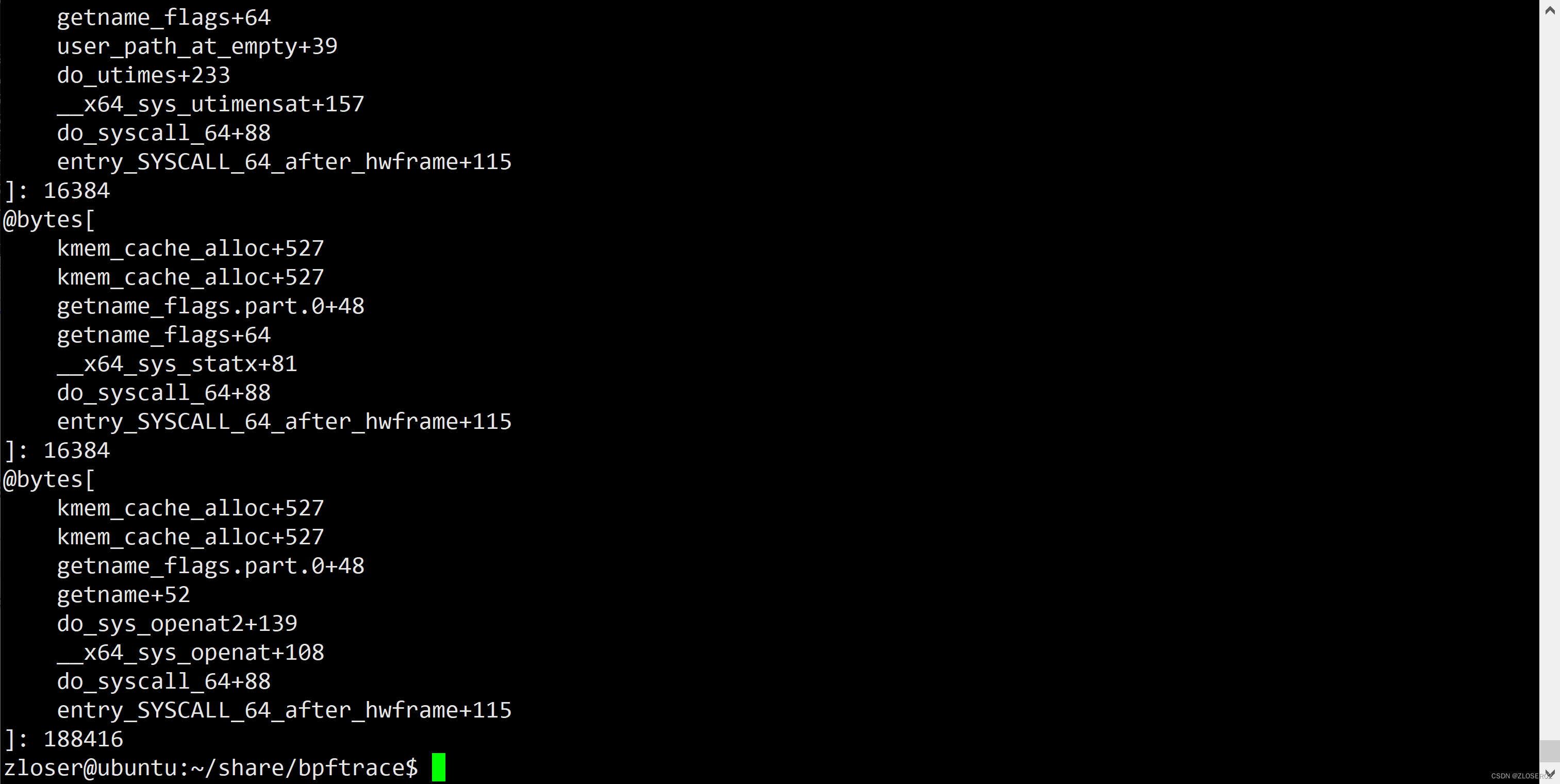
内核内存栈
bpftrace -e 't:kmem:kmem_cache_alloc { @bytes[kstack] = sum(args->bytes_alloc); }'
Malloc 调用统计:
bpftrace -e 'u:/lib/x86_64-linux-gnu/libc.so.6:malloc {@[ustack, comm] = sum(arg0); }'
