获取网络ppt资源
背景:
某度上有很多优质的PPT资源和文档资源,但是大多数需要付费才能获取。对于一些经济有限的用户来说,这无疑是个遗憾,因为我们更倾向于以免费的方式获取所需资源。
解决方案:
然而,幸运的是,我们可以通过一些技巧和工具来实现免费获取PPT的目标。使用一些爬虫技术和数据抓取工具,我们可以自动化地获取这些收费PPT,无需付费就能获得所需资源。一句话,我要白嫖白嫖!!!
实现:
步骤1:
爬取pptx中的所有图片:
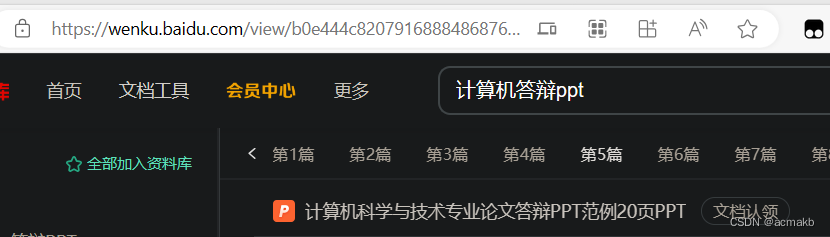
比如这个网页的ppt。
import requests
import os
from lxml import etree
from pptx import Presentation
from pptx.util import Inches
# 创建目录方法
def create_file(file_path):
if not os.path.exists(file_path):
os.makedirs(file_path)
# PPT的网页链接 替换成你需要的资源网站
url = 'https://wenku.baidu.com/view/b0e444c82079168884868762caaedd3382c4b55e?aggId=b4ee6f9724c52cc58bd63186bceb19e8b9f6ecc3&fr=catalogMain_graph_v10_recall%3Awk_recommend_main3&_wkts_=1701780975704&bdQuery=%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%AD%94%E8%BE%A9ppt'
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
img_list = html.xpath('//div[@class="mod flow-ppt-mod"]/div/div/img')
# 计数
cnt = 1
# 爬取的ppt图片保存的文件夹
file_path = './ppt/'
create_file(file_path)
new_list = []
# 获取图片
for i in img_list:
try:
img_url = i.xpath('./@src')[0]
except:
img_url = i.xpath('./@data-src')[0]
# 文件名称
file_name = f'{file_path}page_{cnt}.jpg'
new_list.append(file_name)
print(file_name, img_url)
# 下载保存图片
resp = requests.get(img_url)
with open(file_name, 'wb') as f:
f.write(resp.content)
cnt += 1
我们接下来看看结果:
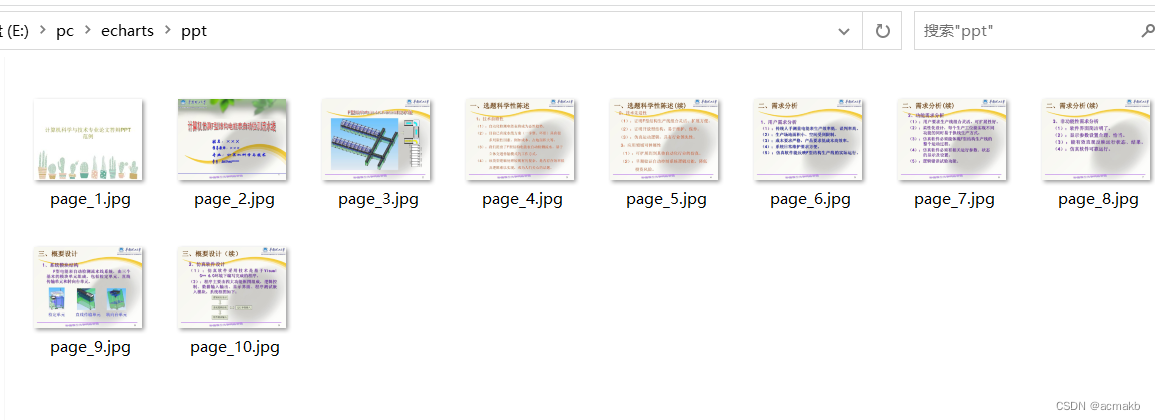
步骤2:
但是这还没完,如何将ppt连接起来呢?
再执行一下如下代码:
# 将图片合成到PPT中
prs = Presentation()
left = top = 10
height = 10
blank_layout = prs.slide_layouts[6]
for i in range(len(new_list)):
slide = prs.slides.add_slide(blank_layout)
slide.shapes.add_picture(new_list[i],left,top)
prs.save('./demo.pptx')
好叻,我们看看结果:
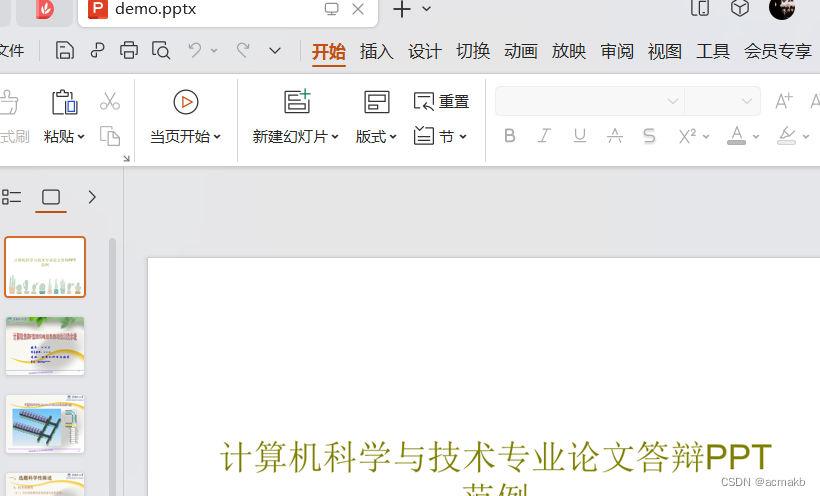
完整代码:
import requests
import os
from lxml import etree
from pptx import Presentation
from pptx.util import Inches
# 创建目录方法
def create_file(file_path):
if not os.path.exists(file_path):
os.makedirs(file_path)
# PPT的网页链接
url = 'https://wenku.baidu.com/view/b0e444c82079168884868762caaedd3382c4b55e?aggId=b4ee6f9724c52cc58bd63186bceb19e8b9f6ecc3&fr=catalogMain_graph_v10_recall%3Awk_recommend_main3&_wkts_=1701780975704&bdQuery=%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%AD%94%E8%BE%A9ppt'
resp = requests.get(url)
text = resp.text
html = etree.HTML(text)
img_list = html.xpath('//div[@class="mod flow-ppt-mod"]/div/div/img')
# 计数
cnt = 1
# 文件保存路径
file_path = './ppt/'
create_file(file_path)
new_list = []
# 获取图片
for i in img_list:
try:
img_url = i.xpath('./@src')[0]
except:
img_url = i.xpath('./@data-src')[0]
# 文件名称
file_name = f'{file_path}page_{cnt}.jpg'
new_list.append(file_name)
print(file_name, img_url)
# 下载保存图片
resp = requests.get(img_url)
with open(file_name, 'wb') as f:
f.write(resp.content)
cnt += 1
# 将图片合成到PPT中
prs = Presentation()
left = top = 10
height = 10
blank_layout = prs.slide_layouts[6]
for i in range(len(new_list)):
slide = prs.slides.add_slide(blank_layout)
slide.shapes.add_picture(new_list[i],left,top)
prs.save('./demo.pptx')
温馨提示:
本文旨在分享数据获取技术的应用和原理,以促进技术交流和知识共享,切勿用于非法和破坏性行为!
谢谢您的理解和合作!