GPT 中文提示词技巧:参照 OpenAI 官方教程
前言
搜了半天什么 prompt engineering 的课,最后会发现 gpt 官方其实是有 prompt 教程的。因此本文主要是学习这篇教程。
概述 - OpenAI API
部分案例是参考:根据吴恩达老师教程总结出中文版prompt教程_哔哩哔哩_bilibili up主的内容。
一、尽可能清晰的指示
指示越少,限定 GPT 输出范围越小,我们得到的答案越准确。
详细信息查询
这一点应该大多数同学不会犯错。比如“谁是总统?”和“谁是2021年的美国总统?” 我认为对于大多数同学来说这样的检索能力很简单。
定义AI角色
很经典的限定,让输出更专业化。
在 api 里,我们可以传输3种不同角色的消息类型。
- system:用于定义背景,比如 AI 角色,输出格式。
- user:我们的问题。
- assistant:我们对回复的举例,用于给 gpt 提示。
比如,“When I ask for help to write something, you will reply with a document that contains at least one joke or playful comment in every paragraph."
这样,当 user 要求写东西时生效。
分隔符限定输入分区
给 gpt 明确不同部分输入文字分别是什么。
Summarize the text delimited by triple quotes with a haiku.
“”“insert text here”“”
用 delimited 限定俳句的参考文本。
指定处理步骤
多任务分步骤执行。以下示例为先总结后翻译。
Use the following step-by-step instructions to respond to user inputs.
Step 1 - The user will provide you with text in triple quotes. Summarize this text in one sentence with a prefix that says "Summary: ".
Step 2 - Translate the summary from Step 1 into Spanish, with a prefix that says "Translation: ".
利用 assistant 提供示例
我自己先输出一次给他看,让他看看我期望的效果。

限定输出长度
如:50个字以内,3个要点(3 bullet points)。
二、提供参考文本
指示参考文本
比如没找到输入信息回复”我没找到“,可以帮助我们判断 GPT 是否正常读取了我们的输入:
Use the provided articles delimited by triple quotes to answer questions. If the answer cannot be found in the articles, write “I could not find an answer.”
也可以自己加上一些限定,比如评论分为几种提示:


指示使用引文
如阅读理解,参考我的文档回答我的问题,没找到答案回复“没找到”,找到了回复引用范围:
You will be provided with a document delimited by triple quotes and a question. Your task is to answer the question using only the provided document and to cite the passage(s) of the document used to answer the question. If the document does not contain the information needed to answer this question then simply write: “Insufficient information.” If an answer to the question is provided, it must be annotated with a citation. Use the following format for to cite relevant passages ({“citation”: …}).
三、把任务分成子任务
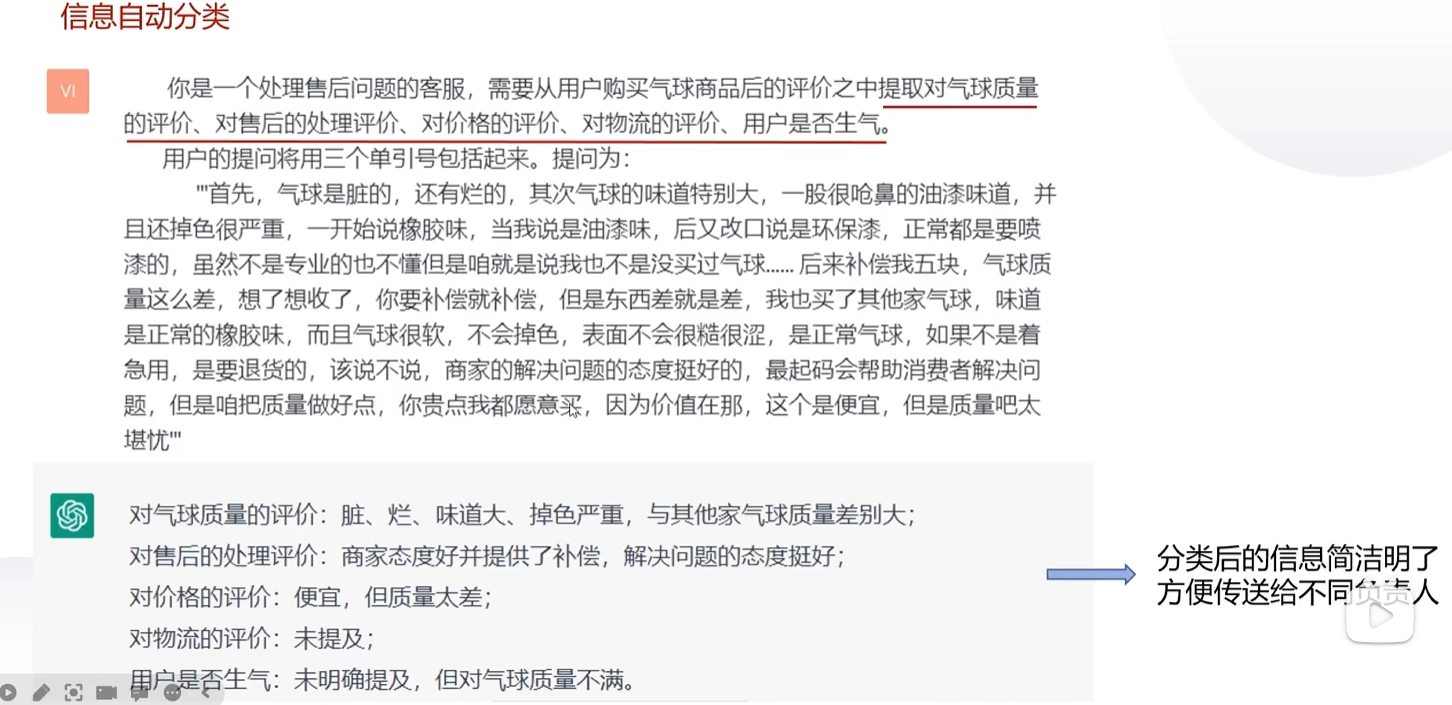
对查询类型分类
类似淘宝用户评价处理这一类应用。这也是能大幅节约 API 开销的 prompt 方法。
You will be provided with customer service queries. Classify each query into a primary category and a secondary category. Provide your output in json format with the keys: primary and secondary.
Primary categories: Billing, Technical Support, Account Management, or General Inquiry.
Billing secondary categories: - Unsubscribe or upgrade - Add a payment method - Explanation for charge - Dispute a charge
Technical Support secondary categories: - Troubleshooting - Device compatibility - Software updates
Account Management secondary categories: - Password reset - Update personal information - Close account - Account security
General Inquiry secondary categories: - Product information - Pricing - Feedback - Speak to a human
以上是将用户输入分类给不同部门的查询分类,比如我输入“买回来的电脑坏了”,分类结果是技术支持-故障排除。我说“我想升级一下电脑”分类结果是账单-取消订阅或升级。
将信息分类,这样更方便我们对信息的传输(比如分发给不同的部门)。
对于状态机的切换,我们可以设定输入一定特殊字符串时切换。比如用户中途突然想切换服务了。
突破长度限制1:触发总结查询
我们知道 GPT 允许输入文本长度有限,有以下几种方法:
- 到达长度限制后,先前内容的摘要和后面的部分内容合并作为输入。
- 动态选择与当前回答最相关的先前部分。
突破长度限制2:分段递归查询
把文章分几段,每段提取一下摘要,最后所有摘要总结生成摘要。
四、给模型思考的时间
有时候我们会发现,问一些简单问题(如计算加减法)不知道为什么 GPT 也会犯错。官方提示是可以不要立即寻求答案,给予其思考的时间。
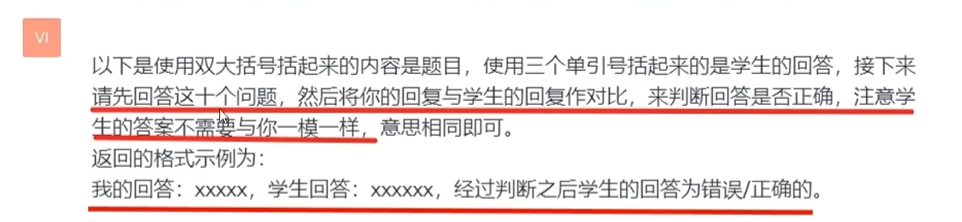
下定结论前,先得出 GPT 自己的答案,再比较判断用户答案
涉及到一点输出顺序影响结果的问题,因为 GPT 是根据前文内容生成后面的内容的。一个很有趣的例子:
GPT 的回答也不一定准确(比如视频演示中,对于问题7,回答是“矩形的面积”,驴唇不对马嘴)。我们可以让他拿自己的答案与学生答案作对比提高准确度。
还有一种误判情况:
原因在于让 GPT 先判断对错,再对比结果。
解决方案可以是:
第一是让他对比答案不用完全一样;
第二是先输出两个回答顺序,再判断正误,因为其生成内容的先后顺序。



隐藏中间步骤
这个推理过程并不一定是我们想要的,比如老板说我只要 TF 的结果。
我们可以做一定的输出格式限定:

只有 Hint 后面的部分是最终结果,‘’’ 中的都是中间步骤。
询问是否有遗漏
提示不要重复摘要,不要遗漏摘要:

五、使用外部工具
嵌入文本搜索
比如先提供给 GPT 一定的信息供参考。
甚至可以使用外部数据库 API,地址如下:矢量数据库 |OpenAI 食谱
这里我就暂时不深入学习了~
执行代码或调用外部 API
比如计算,直接调 Python 库执行代码会更加准确。但是我试了一下,貌似 GPT3.5 是没法执行的。
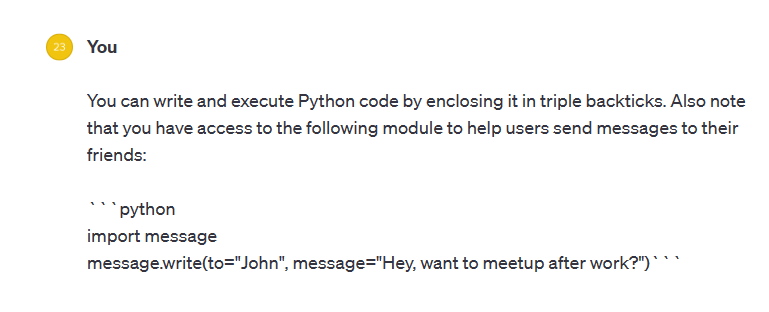
不过要确保代码安全性。
六、系统地测试修改
阅读理解:能否从用户输入推出 answer

我告诉 GPT,我会给你输入一些文本,你看看给定的这两条 answer 是否包含在其中。
步骤:
- 重写用户输入的要点。
- 重写一个比较接近用户输入要点的 answer 版本。
- 你觉得不知道这件事的人通过阅读 answer 能否得出用户输入要点的答案,并解释原因。
- 统计 YN 数量。
比如我输入了一段诗:
“”“In the summer of '69, a voyage grand, Apollo 11, bold as legend’s hand. Armstrong took a step, history unfurled, “One small step,” he said, for a new world.”“”
其实这里面都没提月球,所以是推不出答案的。
不过我的 GPT3.5 提示可以推出 answer1,无法推出 answer2. 还是有点笨笨的哈哈。
判题:给定用户答案和标准答案,判断用户答案是否正确
模型中的变量太多了,我们可以通过并交集判断用户答案和专家答案之间的集合关系进一步判断其正确性。
