微表情检测(二)----SOFTNet论文总结
MACRO- AND MICRO-EXPRESSION SPOTTING FROM LONG VIDEOS
ABSTRACT
面部表情从明显的到微妙的都有所变化。近年来,对微表情进行分析,即由于抑制真实情感而产生的自然表达,引起了研究人员的广泛关注,具有广泛的潜在应用。然而,在与正常或宏表情交织在一起的情况下,识别视频中的微表情变得越来越具有挑战性。在本文中,我们提出了一种浅层光流三流卷积神经网络(SOFTNet)模型,用于预测一个捕捉帧可能处于表情间隔的概率的分数。通过将定位任务构建为回归问题,我们引入了伪标签以促进学习过程。我们在最近的MEGC 2020基准上展示了所提方法的有效性和效率,在CAS(ME)2上实现了最先进的性能,并在SAMM Long Videos上取得了同样令人期待的结果。
关键词----微表情,宏观表情,,光流,浅层卷积神经网络
/*----------------------------------------------------***---------------------------------------------------------*/
捕捉帧:
在上下文中,"捕捉帧"(capture frame)指的是视频中的一个静止画面或帧,即视频的一个单独的图像。在这篇论文中,研究者们提到“捕捉帧可能处于表情间隔的概率的分数”,意味着他们的模型旨在预测每一帧图像属于包含微表情的时间段的概率得分。这样的预测可以帮助识别视频中的微表情,即面部表情的瞬时而微弱的变化。
光流:光流图像(optical flow image)是指在视频序列中,由于物体的运动而引起的像素位移的表示。它包含了每个像素在两帧之间的运动信息,显示了图像中不同区域的运动方向和速度。
光流图像可用于分析视频中的运动模式,对于人脸表情识别等任务,光流图像能够提供关于面部运动的有用信息。在文中,作者提到了“shallow optical flow three-stream CNN”(SOFTNet)模型,这意味着他们的模型使用了光流图像的三个流(streams)或通道,可能分别捕捉不同方向的运动信息,以更好地预测表情的存在。
光流(Optical flow)是指图像中物体在时间上的运动导致的像素位移的模式。光流图像是通过对图像序列进行分析而获得的,它表示了图像中每个像素点在时间上的运动方向和速度。在计算光流时,通常会得到三个流分量,它们分别是:
1. 水平分量(U): 表示像素在图像平面上水平方向上的运动分量。正值表示向右移动,负值表示向左移动。
2. 垂直分量(V): 表示像素在图像平面上垂直方向上的运动分量。正值表示向下移动,负值表示向上移动。
3. 时间分量(T): 表示像素在时间上的运动分量。光流是通过对连续帧之间的图像进行比较而得到的,时间分量表示图像序列中的时间变化。
这三个分量合在一起构成了光流向量(U,V,T),描述了图像中每个像素点的运动情况。光流的计算对于许多计算机视觉任务,如运动估计、目标跟踪等都是非常重要的。
/*----------------------------------------------------***---------------------------------------------------------*/
本文创新点:
- 通过构造伪标签使用回归问题去取代检测问题
- 使用三流(水平、垂直以及光学应变)进行网络的特征提取和融合。
- 对每一帧的预测进行打分,每一帧的打分准则为第I帧的前k帧,以及第I帧的后K帧。总计2k+1帧计算平均值作为该帧的打分。阈值定义为:T=ˆ Smean + p × ( ˆ Smax − ˆ Smean);通过找到局部最大值(峰值之间的最小距离为 k)并向两侧扩展 k 帧,发现峰值帧 SP,φ,从而获得用于评估的发现间隔 ˆ Eφ= [sP,φ − k, sP,φ + k]。
4、伪标签生成算法。
1. INTRODUCTION
在大多数自然场景中,自发的面部表情可能以不同强度和短暂性的形式出现,从明显可见到微妙很难分辨。这些宏表情和微表情的发生可以同时存在或独立发生。微表情通常持续时间较短,介于1/25到1/5秒之间,强度较低,当一个人试图在高风险情境中掩饰真实情感时发生[1]。另一方面,宏表情更容易识别,即使没有适当的训练,因为它们持续时间较长且强度较高。近期深度学习的进展在识别任务中取得了广泛的成功,而在定位任务上,特别是在长时间的“未剪辑”视频上,进展相对较小[2]。因此,微表情研究领域最近组织了第三届MEGC研讨会(MEGC2020)[3],以挑战研究人员在长视频中定位宏观和微观表情。总的来说,面部表情经历三个明显的阶段:起始、顶峰和结束(对应起始帧、顶点帧以及结束帧)。正如[4]中准确描述的那样,起始发生在面部肌肉开始收缩时;顶峰是面部动作强度达到最大的阶段;结束表示肌肉回到中性状态。本文重点介绍了定位宏观和微观表情序列的任务,即从起始到结束。
早期的研究,尤其是[5]和[6],显著地奠定了该任务的基本机制;后者尤其采用了LBP(Local Binary Pattern)作为特征描述符,并使用χ2距离进行两帧之间的特征差异(FD)分析,这两帧在固定时间内。如果帧的特征向量超过为峰值检测设置的阈值,就确定为微表情。大多数研究利用已建立的预处理技术,包括地标检测[7, 8]、区域遮罩[5, 9],以及通过ROI(感兴趣区域)选择强调特定面部区域[10, 11, 12]。
基于运动的方法可以表征面部微妙运动。Shreve等人[5]首次引入了光学应变(光流的导数),以分析基于面部皮肤组织的弹性变形的微妙运动变化。考虑在不同面部区域观察到的应变量(通过对其幅度求和)随时间的变化。MEGC2020的基准方法MDMD [13]对主运动方向上的最大差异幅度进行编码,以预测是否存在宏观或微观表情。与此同时,[10]构建了用于顶峰定位的光学应变特征。最近一些工作[14, 12]已经开始采用深度学习方法进行定位。[14]在替代基准策略下尝试了CNN和RNN模型,而[12]将预先计算的HOOF(Histogram of Optical Flow)特征输入到一个RNN中,该RNN被设计用于定位可能的微小运动的短时间间隔。为了解决微表情样本不足和模型过于复杂等问题,[15]提出使用浅层卷积网络并采用多流输入信息。然而,他们的工作是为了识别任务而设计的。
受[15]的启发,我们假设这类模型可以被训练以缓解数据不足的问题,同时利用运动信息的优势。为了实现这一目标,我们将定位任务构建为一个回归问题,预测一帧很可能属于宏表情或微观表情。在核心部分,我们构建了一个浅层光流三流CNN(SOFTNet),以从不同光流分量中捕获相关特征。本文的贡献总结如下:
1. 我们提出了一种多流浅层网络,融入了光流输入,用于回归生成用于定位的分数。
2. 我们提出了一种新的自动伪标签帧的方法,以便训练回归模型。
3. 我们在MEGC2020基准测试上展示了所提方法在F1分数和计算时间方面的有效性,在CAS(ME)2数据集上取得了最先进的结果。
4. 我们重新探讨了一种检测度量的可行性,该度量提供了更公正和一致的方式来定位宏观和微观表情的发生。
2. PROPOSED FRAMEWORK
所提出的框架如图2所示。本节讨论框架的四个阶段:光流分量的初始特征提取、一系列预处理步骤、使用SOFTNet回归网络进行特征学习,最后是表情发现过程。
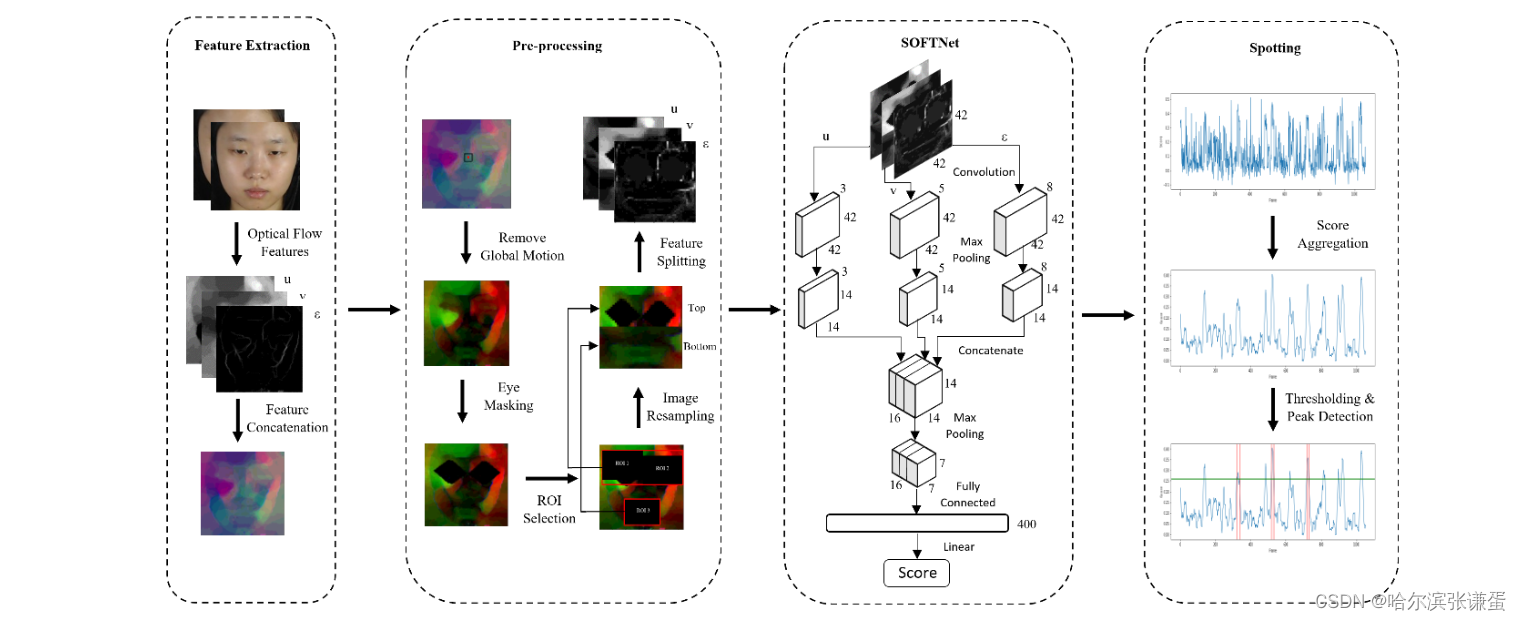
图2:所提方法及其四个阶段的框架。
2.1. Feature Extraction
在微表情分析的多个研究中,光流特征的广泛应用([5, 15, 16])显示了时空运动信息的实用性。为了规范化面部分辨率,每一帧中的面部区域被裁剪并调整大小为128 × 128像素。裁剪是使用dlib工具箱[17]进行的,该工具箱在检测到每个原始视频的第一帧(参考帧)中的68个地标点之后进行操作。
随后,光流特征从两帧图像计算得到,即当前帧Fi和距离i第k帧Fi+k,其中k是表情平均长度的一半。水平和垂直分量分别用TV-L1光流方法[18]计算,分别表示为u和v。此外,光学应变采用了无穷小应变理论,用于捕捉光流分量中微妙的面部变形[5]。其定义如下:
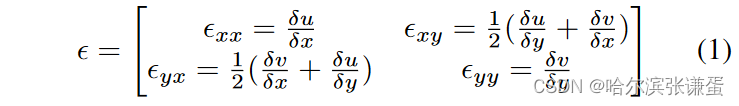
其中,Exx 和 Eyy 表示正应变分量,而 Exy 和 Eyx 表示剪切应变分量。光学应变的大小 E 可以计算如下:
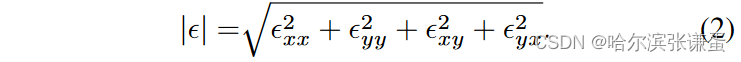
这三个组件(u、v 和 E)代表了模型学习阶段的输入数据。
2.2. Pre-processing
在学习阶段之前,引入了一系列的预处理步骤,以确保在模型学习之前数据的一致性。受[19]工作的启发,我们采用鼻部区域的地标位置,带有五个像素的边距,以消除每一帧的全局头部运动。remove global motion 移除全局头部
/*----------------------------------------------------***---------------------------------------------------------*/
"Remove global motion" 意味着从图像或视频序列中消除全局运动的影响。全局运动通常是整个图像或视频中所有像素移动的趋势,这可能是由于相机移动、整个场景的平移或旋转等引起的。
在计算机视觉和图像处理中,移除全局运动的目的可能是更好地聚焦于局部细节,或者为某些任务(例如目标跟踪、物体检测等)提供更准确的输入。这通常涉及到对图像或视频进行预处理,以抵消或抑制全局运动。
常见的方法包括使用光流估计技术来估计每个像素的运动,并将这些运动从图像中减去,从而得到一个相对于全局运动稳定的图像。另一种方法是使用稳定的背景建模技术,将全局运动视为场景中的背景,并尝试提取前景中的对象。
移除全局运动是在许多计算机视觉任务中的一个关键预处理步骤,以确保模型能够更好地专注于任务相关的信息,而不受到全局运动的影响。
/*----------------------------------------------------***---------------------------------------------------------*/
接着,由于光流特征对眼部眨眼动作非常敏感[9],我们省略左右眼区域。在这项工作之后,我们应用一个多边形(在高度和宽度上额外增加15个像素的边距)来掩盖这些眼部区域。接下来,基于它们通常包含显著运动的事实,选择了由三个区域(在高度和宽度上额外增加12个像素的边距)界定的区域:(1)左眼和左眉毛;(2)右眼和右眉毛;(3)嘴巴。获得的区域被重新采样以形成一个大小为42 × 42(高度,宽度)的图像,保留了重要的特征。具体而言,顶部部分是通过水平堆叠相似大小为21 × 21的重新调整大小的ROI 1和ROI 2获得的,而底部部分来自大小为21 × 42的重新调整大小的ROI 3。
2.3. Shallow Optical Flow Three-stream CNN
模型旨在预测每一帧图像属于包含微表情的时间段的概率得分。这样的预测可以帮助识别视频中的微表情,即面部表情的瞬时而微弱的变化。
SOFTNet。受[15]中的架构启发,我们提出了SOFTNet,并进一步考虑了以下因素:(1)卷积层应用了5 × 5的滤波器,而不是3 × 3,增加感受野的覆盖范围,以适应宏观表情;(2)添加了一个回归输出层,用于预测每帧的分数,表示其可能参与表情间隔的概率。直观地说,光流特征在序列的中间帧(图3中的黄色窗口)通常不如接近Fonset和Foffset的帧那样显著,因此回归一个高分数以进行峰值检测是可取的。
///
在文中提到光流特征在序列的中间帧相对较不显著的情况下,可能是因为面部表情的变化通常在表情开始(Fonset)和表情结束(Foffset)时更为显著。作者可能根据这两个时间点附近的帧来预测和检测面部表情的发生。
///
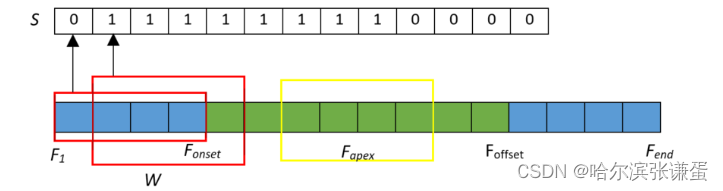
图3:使用滑动窗口方法在视频中进行伪标记。蓝色帧不属于表达间隔的一部分,而绿色帧在间隔内。
SOFTNet是一个三流(非常)浅的架构,其中每个流由一个包含3、5和8个卷积核的卷积层组成,然后是一个最大池化层以减小特征图的大小。每个流的特征图然后以通道方式堆叠以合并特征,随后是maxpooling。最后,它展平成一个400节点层,通过线性激活完全连接到单一的输出分数。具体而言,学到的模型M以第i帧的三个光流分量u、v和 E 作为输入,每个流预测一个发现置信度分数 ˆ si。分别学习用于发现宏观表情(α)和微表情(β)的模型,即 ˆ si,φ = Mφ(ui, vi, Ei),其中 φ = {α, β}。
伪标记。由于ground truth仅提供了起始帧、顶点帧以及结束帧的索引,为了实现滑动窗口机制,我们需要为每个窗口位置创建标签。为了对视频中的帧进行标记,滑动窗口Wj在第j个位置,长度为k1,对应于间隔[Fi,Fi + k - 1](对Fi,Fi + k – 1的间隔产生一个标签),在每个视频中进行扫描。我们施加一个伪标记函数g(对于重叠联合函数,如果IoU ≤ 0,则g(IoU) = 0,否则g(IoU) = 1),用于确定从W和E计算的每个j-th窗口的分数s:
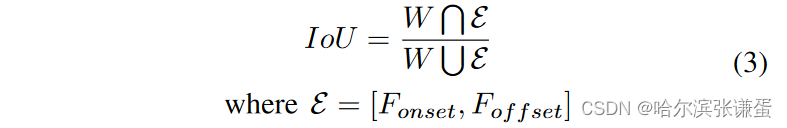
最后,得到了伪标签集合S = {Si,φ for i = 1, . . . , Fend − k},表示SOFTNet输入的标签(φ),如图3示例所示。在实验中发现,其他伪标记函数,如线性函数和阶跃函数,效果不如上述所述的函数。
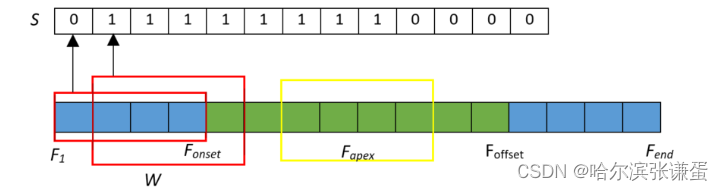
图3:使用滑动窗口方法在视频中进行伪标记。蓝色帧不属于表达间隔的一部分,而绿色帧在间隔内。
训练配置。在我们的实验中,我们采用学习率为5 x 10^−4的SGD,将epoch数设置为10。由于数据集极度不平衡,我们选择每2个非表情帧中采样1个,类似于 [11] 中的策略。数据增强,包括水平翻转、高斯模糊(7 × 7)以及在微表情训练期间仅进行的随机高斯噪声添加(N(0,1)),以解决小样本问题。
2.4. Spotting
每个帧的预测分数被聚合为:

其中,从当前第i帧开始的前k帧到后k帧的预测分数被平均(以第i帧为锚点,向前k帧,向后k帧,并取在这2k+1帧上打分的均值为第i帧的得分si,φ,),以实现平滑处理。直观地说,现在每一帧都表示通过累积置信度分数形成的表情间隔的潜在部分。最后,我们采用 [6] 中的标准阈值和峰值检测技术,在每个视频中发现峰值,其中阈值定义为:
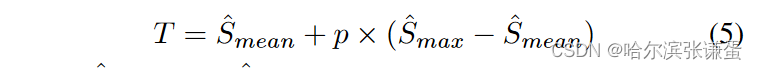
其中,ˆ Smean 和 ˆ Smax 分别是整个视频中的平均和最大预测分数,p 是范围在 [0, 1] 之间的调整参数。如图2的发现阶段所示,绿线(底部行)是阈值,红线表示几个表情的间隔。通过找到局部最大值(峰值之间的最小距离为 k)并向两侧扩展 k 帧,发现峰值帧 SP,φ,从而获得用于评估的发现间隔 ˆ Eφ= [sP,φ − k, sP,φ + k]。
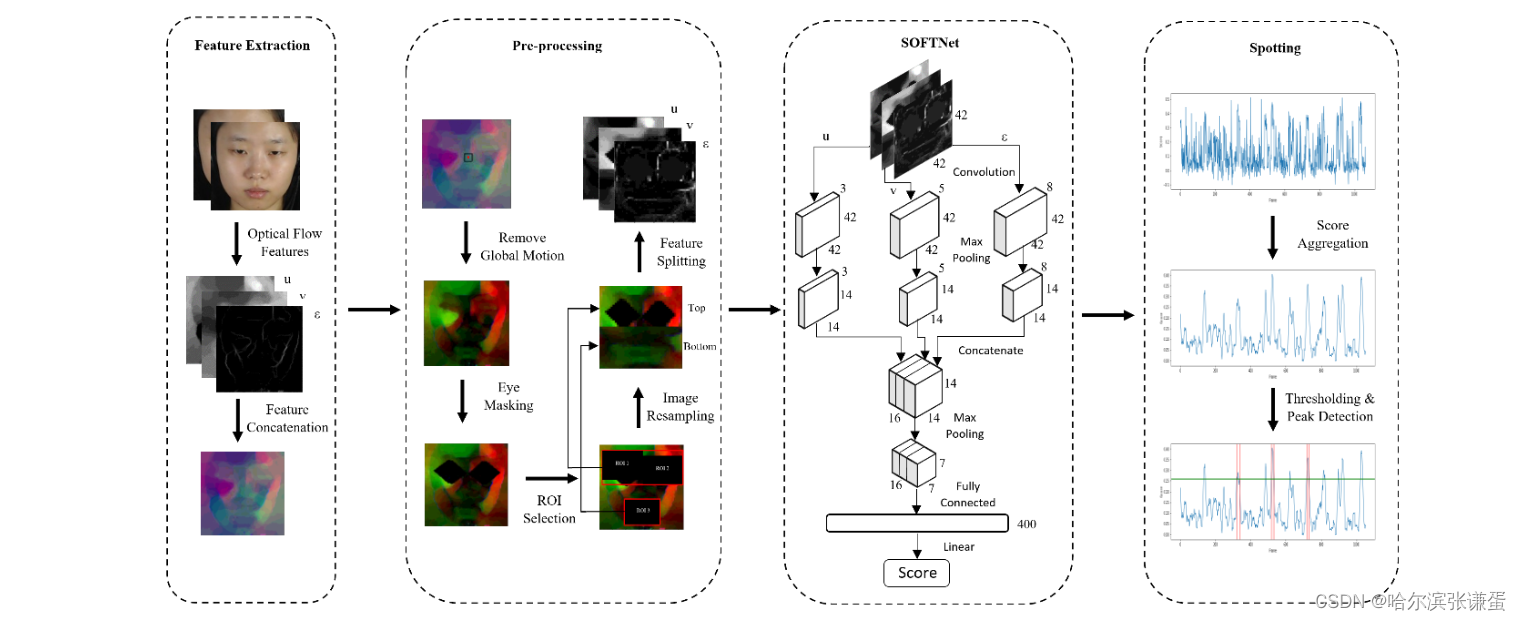
图2:所提方法及其四个阶段的框架。
3. EXPERIMENTS
为了展示所提框架的有效性,我们在MEGC 2020的发现基准上进行了大量实验。值得注意的是,SOFTNet模型分别为宏观表情和微表情进行训练和推断
3.1. Evaluation Details
数据集。使用了两个基准数据集,分别是CAS(ME)2 [22] 和SAMM Long Videos [21]。简要而言,CAS(ME)2 包含98个长视频,其中包括来自22名受试者的300个宏观表情和57个微表情;SAMM Long Videos 是SAMM [23] 的扩展,SAMM是这一领域中文化多样性最丰富的数据集之一,包含了来自32名受试者的147个长视频(343个宏表情,159个微表情)。然而,由于模糊的起始注释,少量(10个)宏观表情样本被丢弃。尽管如此,这两个数据集都由专业编码人员进行了完整的起始帧、巅峰帧以及结束帧的注释。
性能度量。我们将我们提出的方法与MEGC 2020 [3] 的最新工作进行基准比较,采用相似的F1分数度量来评估宏观和微表情的发现。此外,我们提出使用在不同交并比(IoU)阈值从0.5到0.95,步长为0.05的情况下的平均精度(Average Precision,简称AP,表示为AP@[0.5:0.95]),这是在MS COCO [24] 中广泛使用的一种度量标准,用于提供对发现结果质量的更一致的衡量。
设置。采用离一主体交叉验证(Leave-one-subject-out, LOSO)确保对所有样本进行评估。对于峰值检测,我们经验性地选择p = 0.55用于SOFTNet,p = 0.5用于没有SOFTNet。参数k计算为{6, 18}用于CAS(ME)2和{37, 174}用于SAMM(对于微表情采用较小的值,对于宏观表情采用较大的值)。
/*----------------------------------------------------***---------------------------------------------------------*/
"Leave-One-Subject-Out"(LOSO)是一种交叉验证的策略,通常用于评估机器学习模型在处理个体差异时的性能。在这个策略中,每次迭代时,都会从数据集中留出一个独立的主体(subject),然后使用其余的主体进行训练,最后评估留出的主体对模型的性能影响。
具体步骤如下:
1. 留出:选择一个主体(subject)并将其数据从训练集中移除。
2. 训练:使用剩余的数据对模型进行训练。
3. 评估:使用留出的主体的数据进行模型性能评估。
4. 重复:重复上述步骤,每次选择不同的主体。
5. 汇总:对所有迭代的性能度量进行汇总,例如计算平均性能。
LOSO 的优点在于能够更好地评估模型在处理个体差异时的泛化性能。因为每个主体都至少被用于一次的测试,所以可以更全面地了解模型对不同主体的泛化效果。然而,LOSO也可能会面临数据不足的问题,特别是在主体数量较少的情况下。
这种策略通常用于处理生物医学、心理学等领域的数据,其中个体差异可能对模型的性能产生显著影响。
/*----------------------------------------------------***---------------------------------------------------------*/
3.2. Results and Discussions
表1比较了我们提出的方法在两个数据集上的性能与MEGC 2020 [3] 中已接受的提交结果(来自原始出版物)。我们的最佳方法能够在CAS(ME)2上胜过其他方法,而在SAMM Long Videos上,我们在微表情的F1分数上取得最高,而在宏观表情方面,仅次于原始数据集的作者 [21]。消融实验(没有SOFTNet和在预处理中进行图像重采样)通过对每帧的特征图求和的方式确定发现得分,这是根据 [5] 中的建议进行的。通过在表2中详细检查我们的SOFTNet方法,我们获得的TP量与其他方法相当,而FP则低得多。FN问题较小,但在SAMM Long Videos中被证明是一个障碍。AP@[.5:.95]度量通过考虑匹配间隔的不同IoU水平,提供了一种平衡半窗口长度k影响的方法。
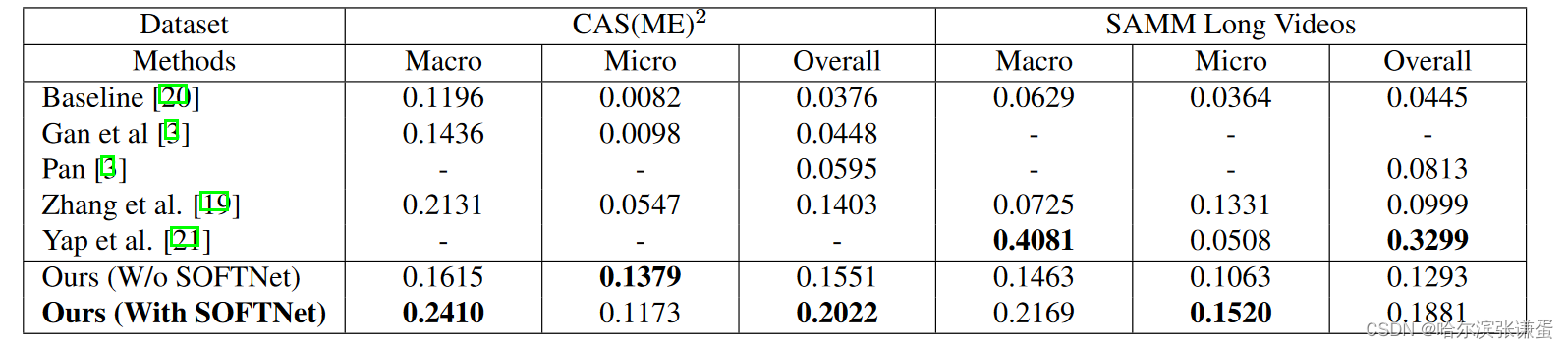
表1:在F1分数上比较了所提方法与baseline和最先进方法
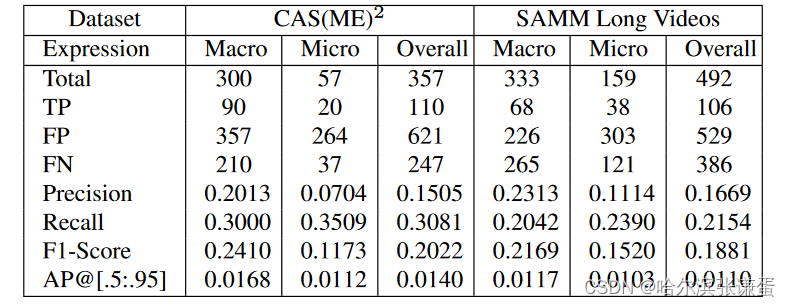
表2:所提出的SOFTNet方法的详细结果
消融研究和见解。表3比较了SOFTNet与一些流行的架构,展示了它在从准确性到效率的各个方面的优越性。关于伪标记函数g的选择的另一个消融研究显示,单位阶跃(0.2410)在F1分数上表现优于线性(0.2269)和阶跃(0.2092)函数。为了提供对预测的见解,我们使用时间轴图和GradCAM [25] 热图来可视化发现的时空位置。图1显示了每个流对最终结果的贡献的示例。

表3:各种网络骨干(用于CAS(ME)2宏观表情)的性能比较
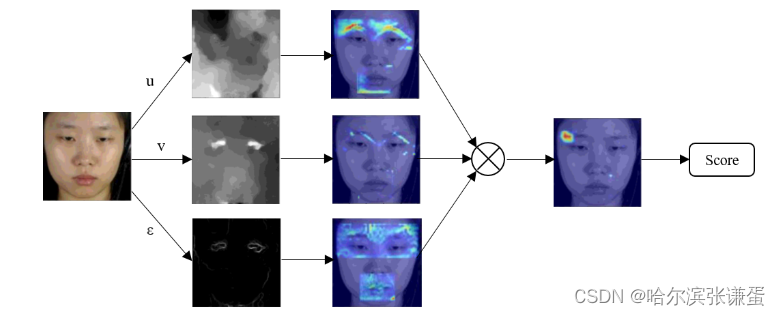
图1:直观地说,用于每个三个流的光流分量捕捉不同的显著运动信息,以揭示宏观和微观表情。
4. CONCLUSION
这篇论文提出了一种基于回归的新策略,通过基于光流信息的三流浅网络,在长视频中发现宏观和微表情。在MEGC 2020基准测试中,我们的方法在CAS(ME)2和SAMM Long Videos上取得了令人满意的结果。同样重要的是,我们重新引入了AP@[.5:.95]度量(来自目标检测),该度量在两种表达类型之间更一致地测量。通过本文的研究发现,发现微表情和宏观表情都需要对局部面部转换和稳健的峰值检测进行创新建模。
致谢:本工作部分得到马来西亚教育部FRGS研究资助(项目编号:FRGS/1/2018/ICT02/MMU/02/2)的支持。
Supplemental Notes
这份补充资料提供了我们参数选择的理由、其他测试过的伪标记函数,以及来自CAS(ME)2数据集的选定样本的时间轴图和类激活映射的可视化示例。
A. Parameter Selection
I. Spotting tuning parameter p
在峰值检测中选择阈值参数p(论文中的方程5),我们通过在p从0.05变化到0.95,步长为0.05的范围内进行实证测试来测试我们的提出的方法。SOFTNet方法的结果报告在表4中,而没有SOFTNet的方法显示在表5中。我们观察到,当p在[0, 1]范围的中间位置时,F1分数最高。
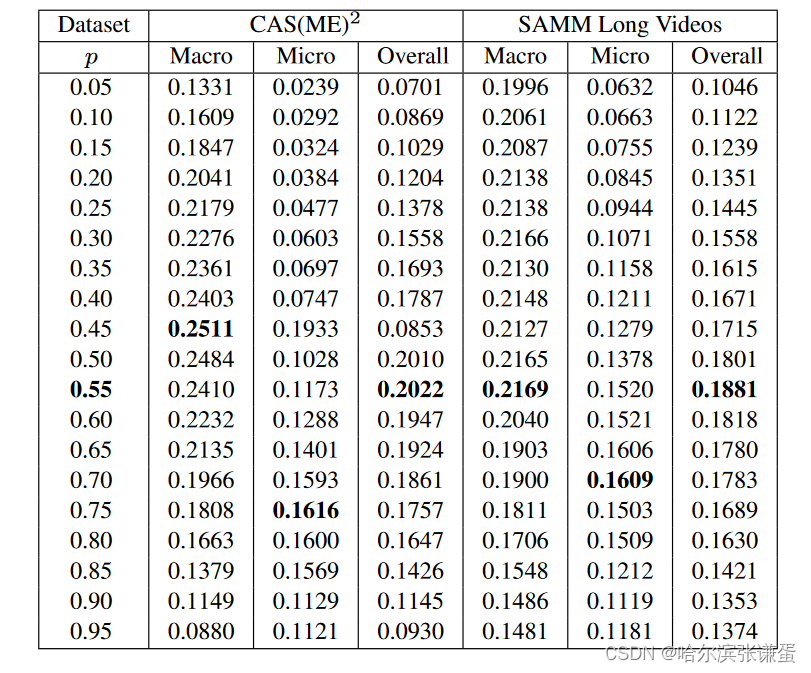
表4:参数p在0.05到0.95范围内变化时所提出的SOFTNet方法的F1分数结果
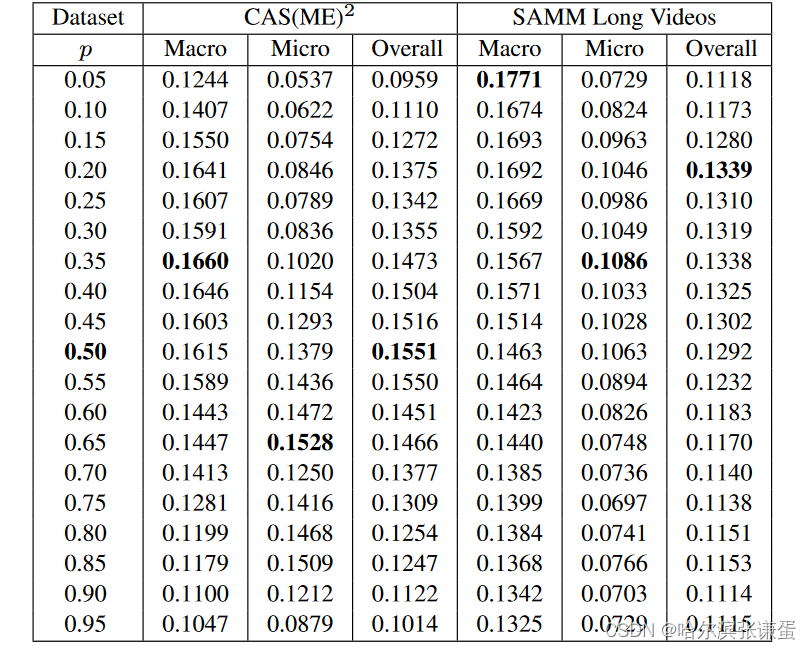
表5:参数p在0.05到0.95范围内变化时,没有SOFTNet的方法的F1分数结果
II. Sliding window length k
在伪标记步骤(论文中的第2.3节)中使用的滑动窗口长度k是通过获取每个数据集中特定类型的表达(微表情或宏表情)的平均长度N的一半来确定的,即k = (N + 1)/2。表6指定了从每个数据子集中确定的k值,其实际持续时间(以秒为单位)在括号中给出。需要注意的是,微表情的k在通常接受的1/25到1/5秒的范围内 [1],而更明显的宏观表情通常在1/2秒到4秒之间 [26]。我们的k值符合这些可接受的持续时间范围。

表6:用于不同数据集和表达类型的滑动窗口长度k。实际持续时间在括号中。
B. Pseudo-labeling
据我们所知,这是第一个使用伪标记函数为视频中的每个宏观和微观表情帧提供置信度分数的工作。为了在训练模型之前实施伪标记步骤,我们尝试了一些常见的函数,以处理边界上的标签(即从正常帧到表情帧,反之亦然),这是基于论文中方程3中定义的IoU的。这些函数在图4中进行了说明,其中x轴是滑动窗口W和宏观或微表达间隔E之间的IoU得分。经过测试的函数方程如下:
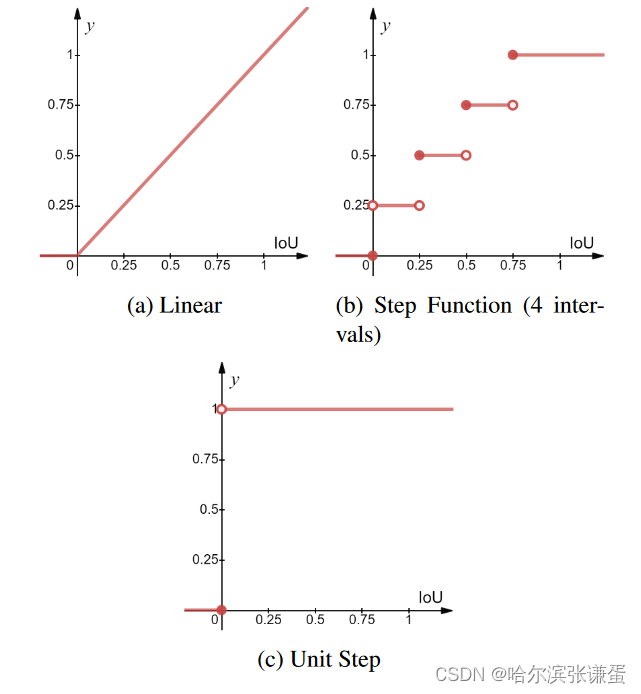

图4:帧标注方法的图示
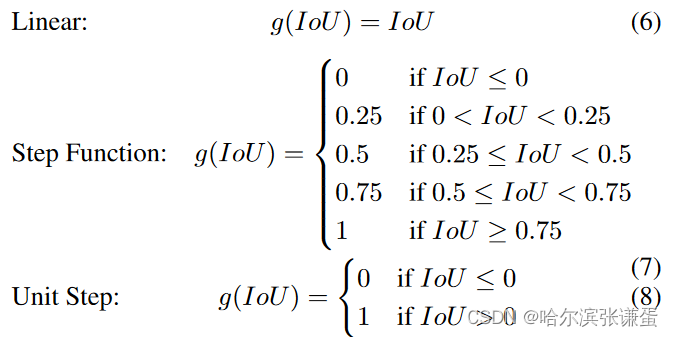
我们对这些不同函数进行了消融研究,以更好地确定它们在我们打算将任务建模为回归问题时对发现的影响。在我们有限的测试中(在撰写时),我们观察到在CAS(ME)2宏观表达子集上进行实验时,单位(Heaviside)阶跃函数方法在F1分数方面表现优于其他方法,尽管在AP@[.5:.95]度量上,线性函数似乎稍微更好。
在未来,这将进一步开展对表达边界最佳刻画方式的研究。过去的研究已经探讨了在微表情中使用表达状态 [27] 和在表达中识别时间相位 [4] 的方法。
C. Visualization
I. Timeline plot for long video spotting长视频定位的时间线图
为了有意义地展示在长视频中的发现任务的结果,我们构建了时间轴图,以更仔细地研究成功和失败的情况。图6描述了两个样本长视频(两者都包含来自CAS(ME)2的各种微表情和宏表情)中宏观和微观表情的归一化发现置信度得分图。x轴表示视频的帧数,而y轴表示归一化的置信度得分。水平线表示用于峰值检测的相应阈值(T)。在图下方,提供了预测的间隔ˆ Eφ和地面实况间隔Egt;由于复合表情的注释,即在相同时间附近两个情绪类别的组合,一些样本重叠在一起。
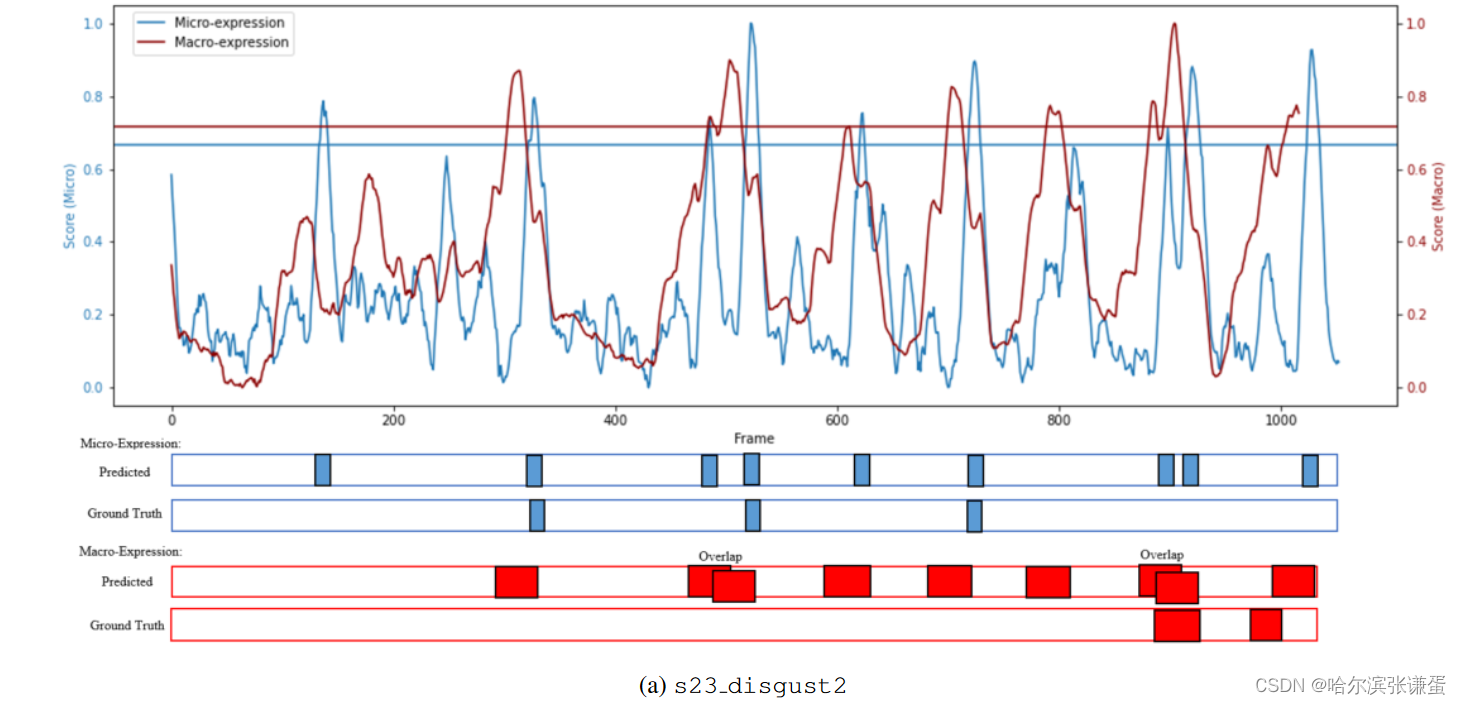
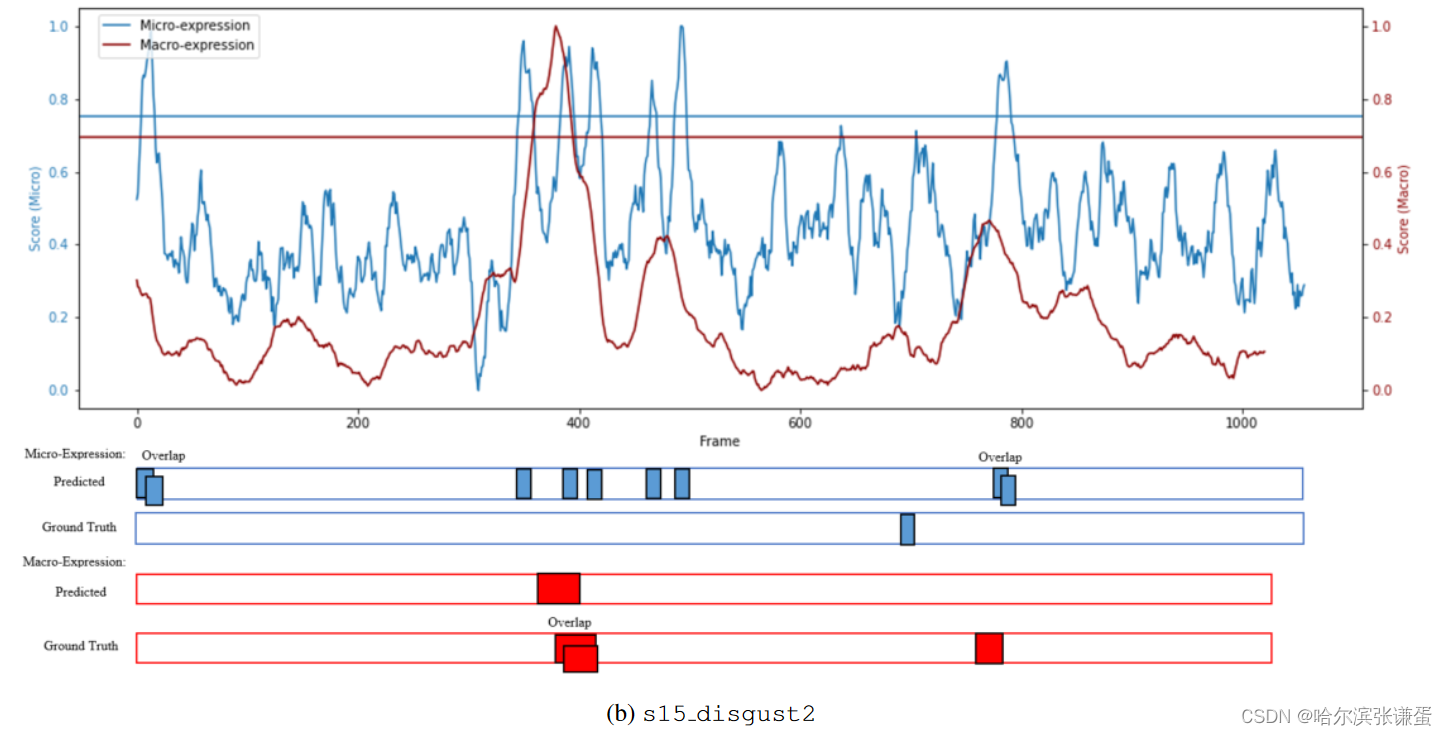
图6:长视频中宏观和微观表达样本的可视化
II. Class activation maps
为了了解SOFTNet模型在每个帧中“attention”的地方(特别是在表达的开始),我们应用了Gradient-weighted Class Activation Mapping (GradCAM) [25]来可视化模型在推断期间如何得出预测决策。流向最终按通道连接的层的梯度生成了图5中显示的粗略定位图。请注意,由于3×的上采样因子(从14×14到输入尺寸42×42),热图的分辨率不高。然而,它足以突出显示对最终发现得分预测起到作用的面部区域。在这些例子中,我们选择了具有高度自信的预测得分的示例帧。
从图5中,热图表明网络能够学习与特定表情触发的相应动作单元(AU)密切对应的面部区域:(图5a、5b)当发生厌恶和愤怒时,Brow Lower(AU 4)被激活;(图5b)当愤怒发生时,Lip Pressor(AU 24)被强调;(图5c)Jaw Sideways(AU 30)通常表示快乐的情感。
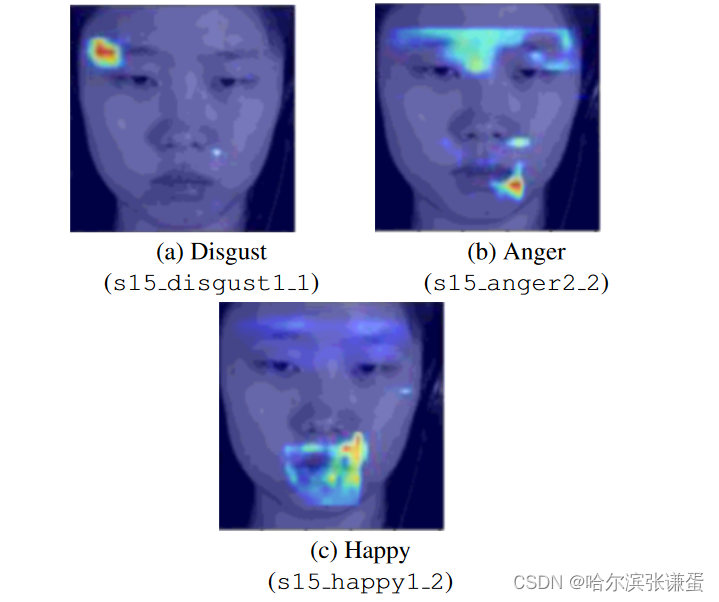
图5:在CAS(ME )2宏观表达中使用SOFTNet的GradCAM可视化类激活映射。