交叉验证以及scikit-learn实现
交叉验证
交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。
主要有三种方式:
- 简单交叉验证(HoldOut检验)、
- k折交叉验证(k-fold交叉验证)、
- 自助法。
本文仅针对k折交叉验证做详细解释。
简单交叉验证
方法:将原始数据集随机划分成训练集和验证集两部分。比如说,将样本按照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。
缺点:
(1)数据都只被所用了一次,没有被充分利用;
(2)在验证集上计算出来的最后的评估指标与原始分组有很大关系。

k折交叉验证
为了解决简单交叉验证的不足,提出k-fold交叉验证。
1、首先,将全部样本划分成k个大小相等的样本子集;
2、依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
3、最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k通常取10.
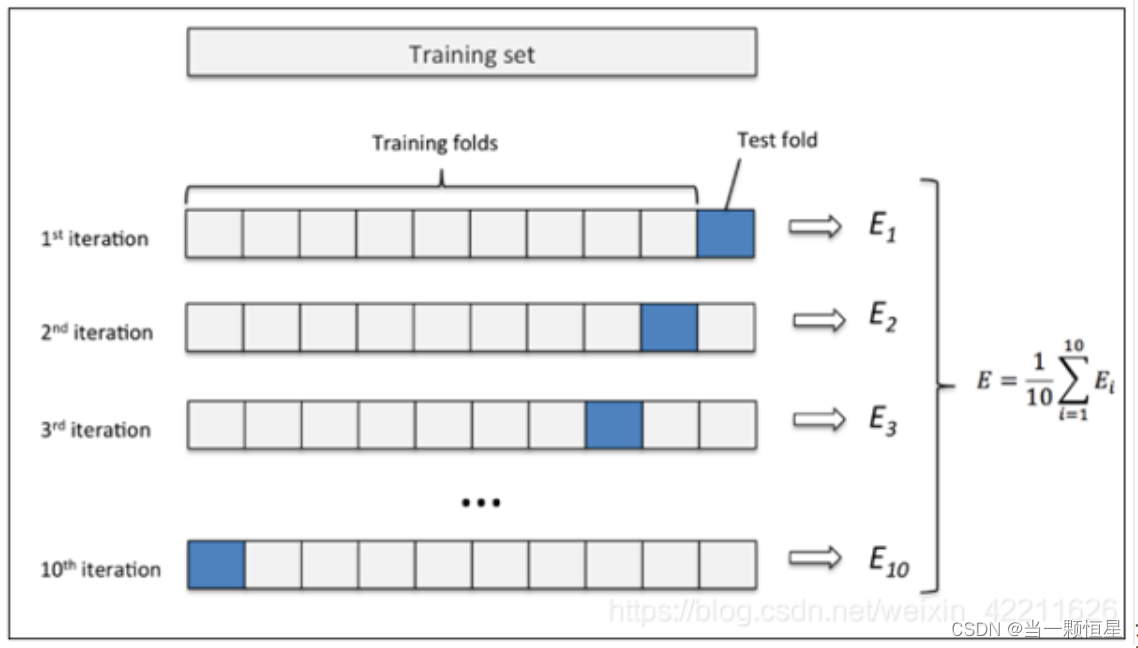
举个例子:这里取k=10,如下图所示:
(1)先将原数据集分成10份
(2)每一将其中的一份作为测试集,剩下的9个(k-1)个作为训练集
此时训练集就变成了k * D(D表示每一份中包含的数据样本数)
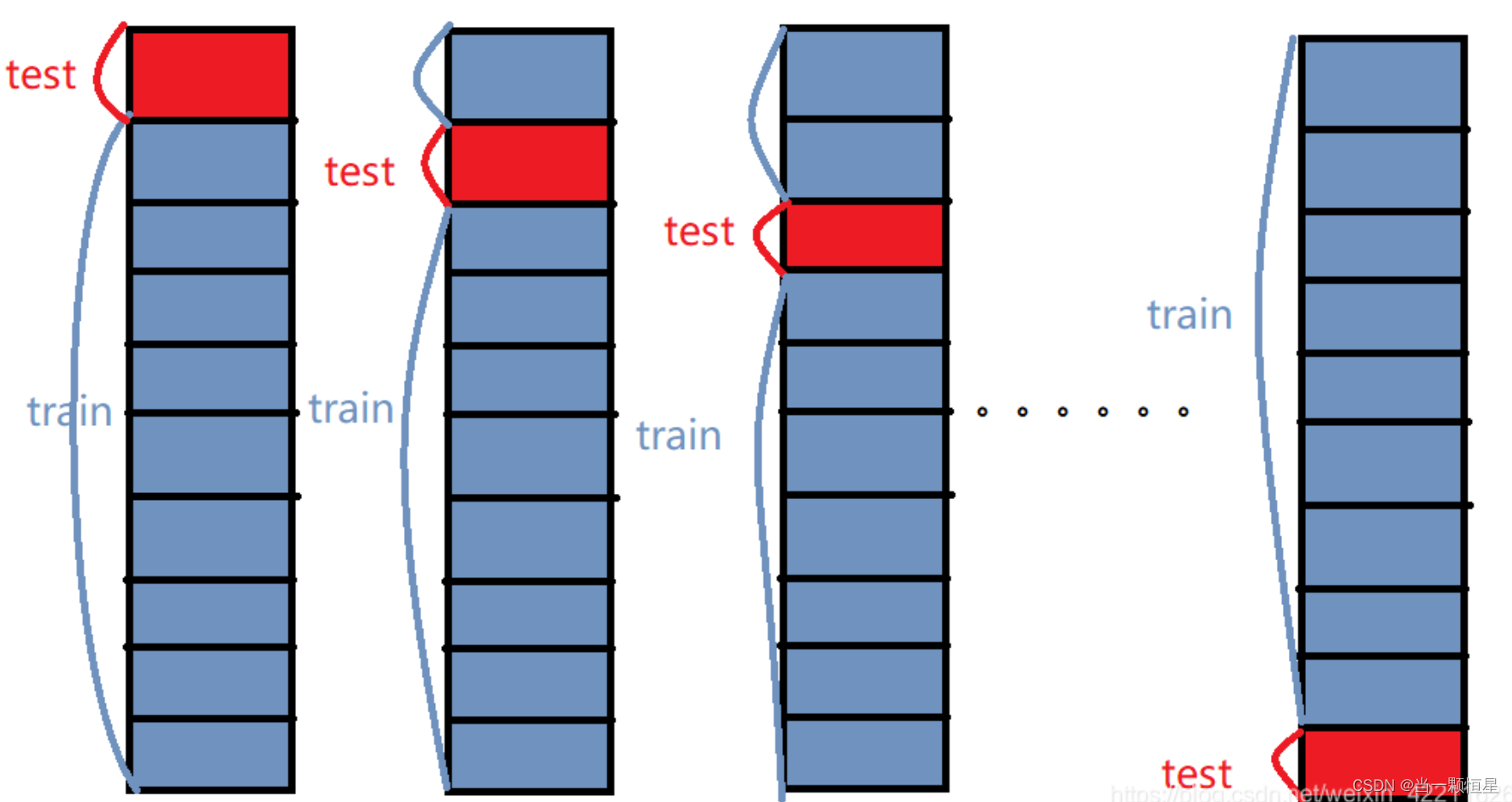
(3)最后计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率
交叉验证的方式,要简单于数学理解,而且具有说服性。需要谨记一点,当样本总数过大,若使用 留一法时间开销极大。
具体API和参数介绍参考原文:
参考文章: https://blog.csdn.net/weixin_42211626/article/details/100064842