根据既定数组创建数组的方法汇总 (第3讲)
根据既定数组创建数组的方法 (第3讲)

🍹博主 侯小啾 感谢您的支持与信赖。☀️
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
✨本博客收录于专栏Python数据分析宝典.。
✨专栏特点:
①逻辑清晰,循序渐进,符合初学者思维,内容友好程度高。
②内容精炼,且不失重点,入门时间周期短。性比价高。
③能够兼容非科班,如金融,经济,统计,数学等专业的小伙伴。
④附实战案例加持,搭乘数分精通之路的直通车!
✨更多精彩内容敬请期待,小啾持续为您输出中!
文章目录
- 1. `asarray()`函数
- 2. `frombuffer()` 函数
- 3. `fromiter()` 函数
- 4. `empty_like()` 函数
- 5. `zeros_like()` 函数
- 6. `ones_like()` 函数
- 7. `full_like()` 函数
1. asarray()函数
asarray方法是NumPy库中的一个函数,用于将输入转换为一个数组。如果输入已经是一个数组,则返回该数组本身,否则返回一个新的数组对象。
asarray方法的基本语法如下:
numpy.asarray(a, dtype=None, order=None)
参数说明:
a:输入的数据,可以是列表、元组、数组等可迭代对象。dtype:可选参数,输出数组的数据类型。如果不指定,则根据输入的数据自动推断。order:可选参数,指定数组在内存中的布局方式。可以是’C’(按行)、‘F’(按列)或’A’(原始顺序,默认)。
asarray方法可以将列表、元组、数组等可迭代对象转换为数组。如果输入已经是一个数组,则返回该数组本身。如果不指定数据类型(dtype),则根据输入的数据自动推断数据类型。默认情况下,asarray方法返回的数组与输入数据共享相同的数据缓冲区,即它们引用相同的内存地址。
代码示例:
import numpy as np
# 将列表转换为数组
arr1 = np.asarray([1, 2, 3])
print(arr1)
print("-" * 20)
# 将元组转换为数组
arr2 = np.asarray((4, 5, 6))
print(arr2)
print("-" * 20)
# 创建一个数组,并指定数据类型
arr3 = np.asarray([7, 8, 9], dtype=float)
print(arr3)
输出:
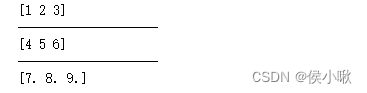
2. frombuffer() 函数
用formbuffer()方法创建数组,该方法的特点及优势在于,该方法接收字节流形式的参数。
frombuffer() 方法用于从指定的缓冲区中创建一个新的一维数组。该方法将缓冲区解释为一维数组,并返回一个由缓冲区数据构成的数组。
frombuffer() 方法的基本语法如下:
numpy.frombuffer(buffer, dtype=float, count=-1, offset=0)
参数说明:
buffer:输入的缓冲区对象,可以是字节串、字节数组或可被转换为缓冲区的对象。dtype:可选参数,输出数组的数据类型,默认为 float。count:可选参数,要读取的元素数量,默认为 -1(表示读取所有元素)。offset:可选参数,从缓冲区的偏移量开始读取数据,默认为 0。
示例使用:
import numpy as np
# 使用字节数组创建数组
buffer1 = bytearray(b'abcdefgh')
arr1 = np.frombuffer(buffer1, dtype='S1')
print(arr1)
print("-" * 20)
# 使用字节串创建数组
buffer2 = b'12345678'
arr2 = np.frombuffer(buffer2, dtype=np.uint8)
print(arr2)
print("-" * 20)
# 使用偏移量和数量参数创建数组
buffer3 = b'abcdefgh'
arr3 = np.frombuffer(buffer3, dtype='S1', count=4, offset=2)
print(arr3)
输出:
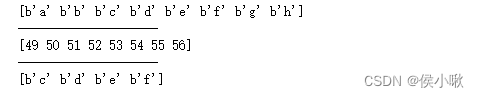
需要注意的是,frombuffer() 方法将缓冲区解释为一维数组,并返回由缓冲区数据构成的数组。在创建数组时,可以指定数据类型、读取元素数量以及偏移量的位置。
3. fromiter() 函数
在NumPy 库中,fromiter() 函数用于从可迭代对象中创建一个新的一维数组。
fromiter() 的基本语法如下:
numpy.fromiter(iterable, dtype, count=-1)
参数说明:
iterable: 可迭代对象,例如列表、元组等。dtype: 输出数组的数据类型。count: 可选参数,指定要从可迭代对象中读取的元素数量。默认为 -1,表示读取所有元素。
示例使用:
import numpy as np
# 从列表中创建数组
my_list = [1, 2, 3, 4, 5]
arr1 = np.fromiter(my_list, dtype=int)
print(arr1)
print("-" * 20)
# 从生成器中创建数组
generator = (x**2 for x in range(5))
arr2 = np.fromiter(generator, dtype=float)
print(arr2)
输出:

在这个示例中,我们从一个列表和一个生成器中分别创建了数组。通过指定数据类型和可迭代对象,fromiter() 函数将可迭代对象中的元素转化为数组。需要注意的是,默认情况下会读取可迭代对象中的所有元素,但可以通过设置 count 参数来限制读取的元素数量。
4. empty_like() 函数
empty_like() 是 NumPy 库中的一个函数,用于创建一个与给定数组具有相同形状和数据类型的空数组。
empty_like() 的基本语法如下:
numpy.empty_like(prototype, dtype=None, order='K', subok=True)
参数说明:
prototype: 输入的数组或类数组对象,用于确定新数组的形状和数据类型。dtype: 可选参数,输出数组的数据类型。如果不指定,则继承自输入数组的数据类型。order: 可选参数,指定数组在内存中的布局方式。可以是’C’(按行)、‘F’(按列)或’A’(原始顺序,默认)。subok: 可选参数,是否允许子类继承输入数组的类型。默认为 True。
示例使用:
import numpy as np
# 创建一个与给定数组形状相同的空数组
arr1 = np.array([1, 2, 3, 4])
empty_array1 = np.empty_like(arr1)
print(empty_array1)
print("-" * 20)
# 创建一个与给定二维数组形状相同的空数组
arr2 = np.array([[1, 2, 3, 5], [4, 6, 8, 9]])
empty_array2 = np.empty_like(arr2)
print(empty_array2)
输出:

在这个示例中,我们使用 empty_like() 函数创建了两个空数组。第一个数组的形状与给定一维数组 arr1 相同,第二个数组的形状与给定二维数组 arr2 相同。这些空数组不会被初始化为任何具体值,而是根据给定的形状和数据类型分配了相应的内存空间。
5. zeros_like() 函数
zeros_like() 是 NumPy 库中的一个函数,用于创建一个与给定数组具有相同形状和数据类型的全零数组。
zeros_like() 的基本语法如下:
numpy.zeros_like(prototype, dtype=None, order='K', subok=True)
参数说明:
prototype: 输入的数组或类数组对象,用于确定新数组的形状和数据类型。dtype: 可选参数,输出数组的数据类型。如果不指定,则继承自输入数组的数据类型。order: 可选参数,指定数组在内存中的布局方式。可以是’C’(按行)、‘F’(按列)或’A’(原始顺序,默认)。subok: 可选参数,是否允许子类继承输入数组的类型。默认为 True。
示例使用:
import numpy as np
# 创建一个与给定一维数组形状相同的全零数组
arr1 = np.array([1, 2, 3])
zeros_array1 = np.zeros_like(arr1)
print(zeros_array1)
print("-" * 20)
# 创建一个与给定二维数组形状相同的全零数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
zeros_array2 = np.zeros_like(arr2)
print(zeros_array2)
输出:
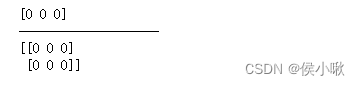
在这个示例中,我们使用 zeros_like() 函数创建了两个全零数组。第一个数组的形状与给定一维数组 arr1 相同,第二个数组的形状与给定二维数组 arr2 相同。这些全零数组的元素都被初始化为 0,并且与给定数组具有相同的形状和数据类型。
6. ones_like() 函数
ones_like() 是 NumPy 库中的一个函数,用于创建一个与给定数组具有相同形状和数据类型的全一数组。
ones_like() 的基本语法如下:
numpy.ones_like(prototype, dtype=None, order='K', subok=True)
参数说明:
prototype: 输入的数组或类数组对象,用于确定新数组的形状和数据类型。dtype: 可选参数,输出数组的数据类型。如果不指定,则继承自输入数组的数据类型。order: 可选参数,指定数组在内存中的布局方式。可以是’C’(按行)、‘F’(按列)或’A’(原始顺序,默认)。subok: 可选参数,是否允许子类继承输入数组的类型。默认为 True。
示例使用:
import numpy as np
# 创建一个与给定一维数组形状相同的全一数组
arr1 = np.array([1, 2, 3])
ones_array1 = np.ones_like(arr1)
print(ones_array1)
print("-" * 20)
# 创建一个与给定二维数组形状相同的全一数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
ones_array2 = np.ones_like(arr2)
print(ones_array2)
输出:

在这个示例中,我们使用 ones_like() 函数创建了两个全一数组。第一个数组的形状与给定一维数组 arr1 相同,第二个数组的形状与给定二维数组 arr2 相同。这些全一数组的元素都被初始化为 1,并且与给定数组具有相同的形状和数据类型。
7. full_like() 函数
在NumPy库中, full_like() 函数,它可以用来创建一个与给定数组具有相同形状和数据类型的填充值数组。
full_like() 的基本语法如下:
numpy.full_like(prototype, fill_value, dtype=None, order='K', subok=True)
参数说明:
prototype:输入的数组或类数组对象,用于确定新数组的形状和数据类型。fill_value:要填充的值。dtype:可选参数,输出数组的数据类型。如果不指定,则继承自输入数组的数据类型。order:可选参数,指定数组在内存中的布局方式。可以是’C’(按行)、‘F’(按列)或’A’(原始顺序,默认)。subok:可选参数,是否允许子类继承输入数组的类型。默认为 True。
示例使用:
import numpy as np
# 创建一个与给定一维数组形状相同的填充值数组
arr1 = np.array([1, 2, 3])
filled_array1 = np.full_like(arr1, fill_value=5)
print(filled_array1)
print("-" * 20)
# 创建一个与给定二维数组形状相同的填充值数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
filled_array2 = np.full_like(arr2, fill_value=9)
print(filled_array2)
输出:
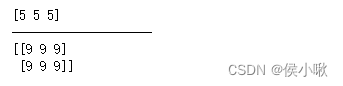
在这个示例中,我们使用 full_like() 函数创建了两个填充值数组。第一个数组的形状与给定一维数组 arr1 相同,并且填充值为 5。第二个数组的形状与给定二维数组 arr2 相同,并且填充值为 9。这些填充值数组的元素都被初始化为指定的填充值,并且与给定数组具有相同的形状和数据类型。