《深入理解计算机系统》学习笔记 - 第四课 - 机器级别的程序
Lecture 05 Machine Level Programming I Basics 机器级别的程序
文章目录
- Lecture 05 Machine Level Programming I Basics 机器级别的程序
- intel 处理器的历史和体系结构
- 芯片的构成
- AMD 公司(Advanced Micro Devices,先进的微型设备)
- C, 汇编, 机器代码
- 定义
- 汇编/机器代码
- C程序转换为目标代码
- 编译为汇编代码
- 汇编的特性:数据类型
- 汇编的特性:操作
- 机器指令解析示例
- 反汇编代码
- 反汇编器 objdump
- 反汇编 gdb
- 汇编基础:寄存器,操作数,移动
- 寄存器
- 移动数据 mov
- 简单的内存地址模式
- 地址模式示例
- 实际中交换方法
- 完整的内存地址模式
- 地址计算指令 `lea`
- 示例
- 算术运算 和 逻辑运算
- 示例
- 《深入理解计算机系统》书籍学习笔记
intel 处理器的历史和体系结构
- 复杂指令集电脑(complex instruction set computer)
- 精简指令集电脑 Reduced Instruction Set Computers(RISC)
芯片的构成
broadwell 型号模型:
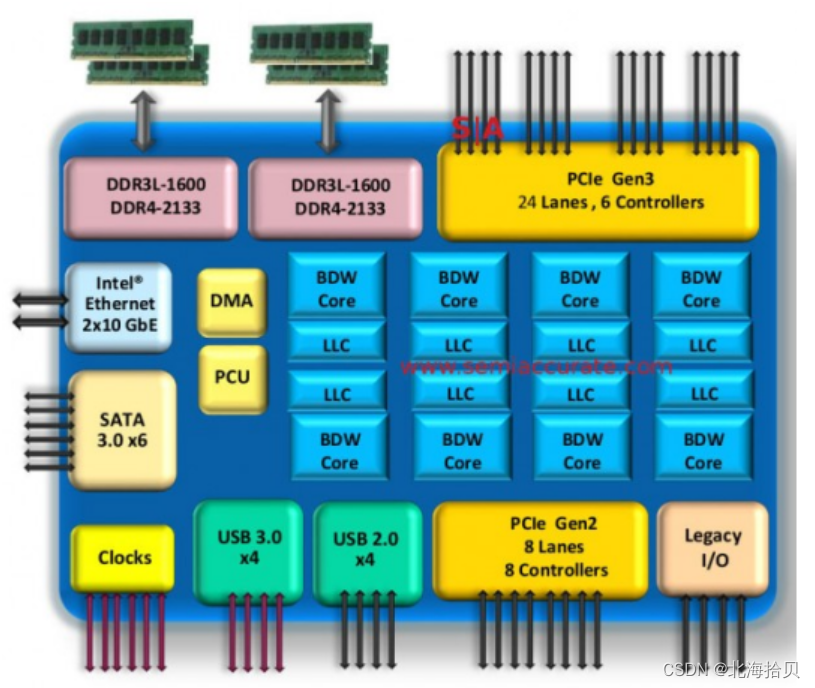
- 一个芯片有多个内核。
- 芯片的边缘有许多接口连接其余的设备。
- DDR是连接到主存储器的方式,即所谓的DRAM 动态 RAM。
- PCI 是与外围设备的连接。
- SATA 是与不同类型盘的连接。
- 以太网接口,连接到一个网络。
因此,所有集成到单个芯片上的不仅仅是处理器本身,而是很多逻辑单元粘在一起所组成的更大的系统。
AMD 公司(Advanced Micro Devices,先进的微型设备)
紧随Intel公司的后面,相对落后一点,但是价格便宜。
C, 汇编, 机器代码
定义
- 架构(ISA: Instruction set architecture, 指令集架构)
需要理解或编写汇编/机器代码的处理器设计部分。
指令和指令集:这是编译器的目标,为你提供一系列指令,告诉机器确切地做什么。
发明硬件地人们想到了各种巧妙地实施指令方式,其中一些非常快,但需要大量地硬件,有些很慢,但根本不需要太多硬件。因此他们设法创建了这种称为指令集架构地抽象。
编译器地目标就是他们。
而如何最好地实现它是硬件研究者地工作。
-
微架构
对架构的补充。
低级别地东西,如何实现它被称为微结构 -
代码形式
- 机器代码
处理器执行的字节级程序。 - 汇编代码
机器代码的文本表示形式。
- 机器代码
一些指令架构集:
* intel: x86,IA32, Itaniu, x86-64.
* ARM (Acorn RISC Machine,橡树种子精简指令机器)
ARM指令体系结构。
他们向公司出售使用其涉及的许可权力,他们真正卖的是知识产权而不是芯片。
汇编/机器代码
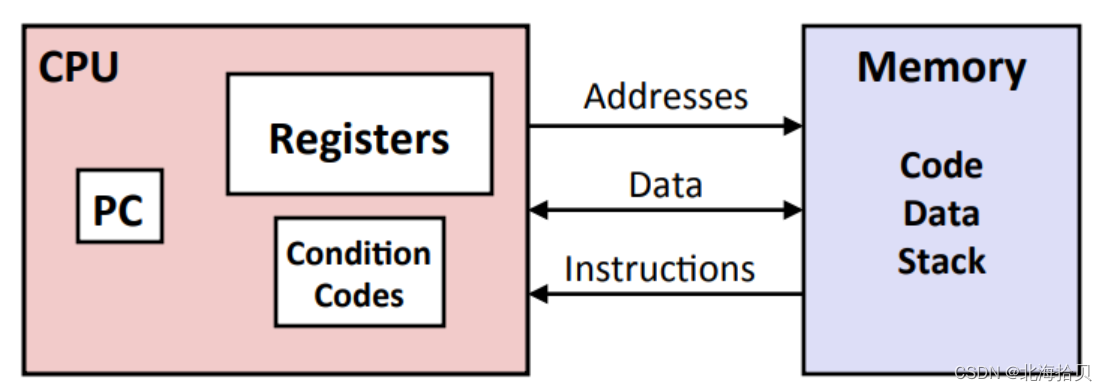
处理器部分:
-
PC: Program counter 程序计数器
存储下一条指令的地址。 -
Register file 寄存器文件,寄存器集
大量使用的程序文件 -
Condition Code 条件码
状态寄存器。
存储最近的算术或者逻辑运算的结果状态:产生的值为0?为正值或者负值?
用于实现条件分支
存储部分:
- Memory 内存
字节可寻址数组
代码和用户数据
用于支持程序的堆栈
内存是你可以逻辑地认为只是一个字节数组,这就是机器程序员所看到的。
如前所述,它实际上是一种用不同方式实现虚构对象,操作系统和硬件之间存在一种协作,他们称之为虚拟内存,使处理器上运行的每个程序看起来拥有自己独立的字节数组,它们可以访问。即使它们实际上在物理内存内部都是共享这些字节数组。
C程序转换为目标代码
你有一个程序,是c程序,包含多个文件,将使用一些库代码。
编译过程:将你写的代码内容,转换为机器代码,并将其与编译后的,编译器为库生成合并代码,最终生成一个文件,可执行文件。
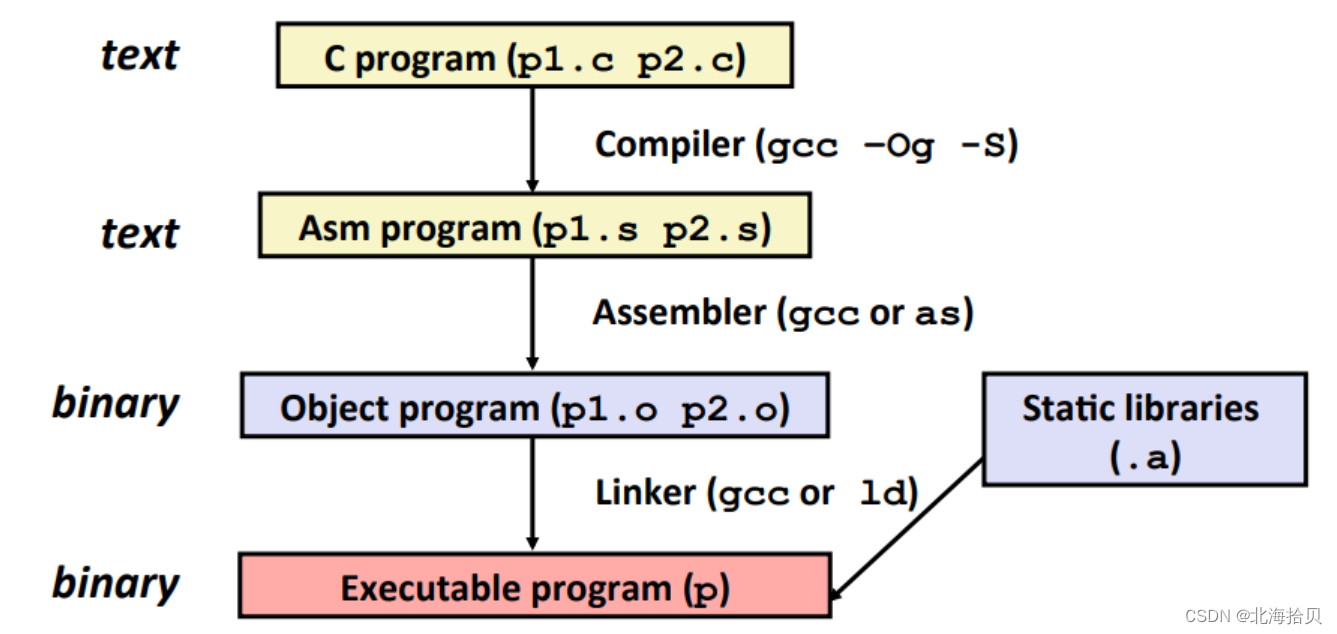
步骤:
- 文本形式的c程序文件,通过编译器生成文本形式的汇编代码
- 汇编代码,通过汇编器生成二进制的目标程序(字节形式)
- 通过链接器,将不同的文件融合在一起,包含你单独的文件,已编译版本和库代码,最终生成一个可执行程序。
- 实际有一些库在程序首次开始执行时动态导入的。
汇编器:
- 将
.s汇编文件转换为.o目标文件 - 二进制编码指令
- 几乎完整的可执行代码映像
- 缺少不同文件中代码之间的链接(链接器来完成)
链接器:
- 解决文件之间的引用
- 与静态运行时(run-time)库结合使用,例如:malloc(),printf()等
- 一些库是动态链接的。当程序开始执行时链接。
编译为汇编代码
- c编码
long plus(long x, long y);
void sumstore(long x, long y, long *dest)
{
long t = plus(x,y);
*dest = t;
}
- 汇编码
运行命令,生成汇编代码:gcc -Og -S sum.c
-Og: O optimize 优化。指定编译器做什么样的优化的规范。
如果不给它指示,它将生成完全未经过优化的代码,实际上很难读该代码,它的运行过程非常繁琐。
-O1: 这是过去打开优化器的过程,gcc 做了很多优化,为了优化目的,使代码很难理解。
因此,最近几代GCC中的一个出现这个名未g的调式级别
.file "sum.c"
.text
.globl sumstore
.type sumstore, @function
sumstore:
.LFB0:
.cfi_startproc
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movq %rdx, %rbx
call plus
movq %rax, (%rbx)
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE0:
.size sumstore, .-sumstore
.ident "GCC: (GNU) 8.5.0 20210514 (Red Hat 8.5.0-15.0.2)"
.section .note.GNU-stack,"",@progbits
以句点开头的.,这些实际上指示它们是别的东西,它们与某些被需要的信息有关,要给调试器提供,使他能够定位程序的各个部分,一些信息告诉链接器,这是一个全局定义的函数,还有一些其他信息,我们暂时不需要考虑,忽视这些信息,是它们更具有可读性。
百分号前缀%: 寄存器名称
pushq: 将东西推到栈上。
movq: 将它从一个地方复制到另一个地方。
call:调用一些过程
popq: 和pushq相对的命令,从栈中取出东西。
ret:特定函数的返回。
每一行都是一个指令(用文本写的),每条都将变成目标代码文件中的一个实际指令。
汇编的特性:数据类型
-
整型数据类型:1,2,4,8 字节
在整数数据类型,它们不区分符号与无符号的存储方式。
地址和指针,都是以数字形式存储在计算机中。 -
浮点数数据类型:4,8,10 字节
-
代码;一系列指令编码的字节序列
-
没有聚合类型:数组和结构体
只是在内存中巧妙地分配了字节
汇编的特性:操作
-
实现算术运算方法通过寄存器和内存数据
-
在内存和寄存器之间转换数据
- 从内存中将数据加载到寄存器
- 将寄存器的数据存储到内存
-
转移控制
- 非条件跳转 到/从 过程
- 条件分支
机器指令解析示例
- c代码
将t的值存存储到dest指定的位置。
*dest = t
- 汇编代码
movq %rax, (%rbx)
移动8字节值到内存:4字
操作数:
* t: 寄存器 %rax
* dest: 寄存器 %rbx
* *dest: 内存 M[%rbx]
- 目标代码
3 字节指令。
0x40059e: 48 89 03
存储地址 0x40059e
拓展:
变量的所有名称,在汇编代码级别,机器代码级别完全丢失,东西都变成了寄存器和内存中的某个位置。
反汇编代码
先生成目标代码:gcc -Og sum.c -c
反汇编器 objdump
objdump -d sum.o
- 用于检查目标代码
- 分析一系列指令的代码
- 产生汇编代码的进士索引
- 可以在a.out(可执行文件) 或者 .o(目标文件)运行
反汇编得到的汇编代码:
0000000000000000 <sumstore>:
0: 53 push %rbx
1: 48 89 d3 mov %rdx,%rbx
4: e8 00 00 00 00 callq 9 <sumstore+0x9>
9: 48 89 03 mov %rax,(%rbx)
c: 5b pop %rbx
d: c3 retq
反汇编 gdb
gdb 是一个非常强大的调试程序。
你可以单步检查程序并对其中的程序进行一些操作,如果它的源代码可用,可以用它来调试。
安装gdb:
yum install gdb
调试程序:
gdb sum
disassemble sumstore
gdb 作用:
- 可以单步检查程序并对其中的程序进行一些操作。(源代码调试)
- 可以用来反汇编
反汇编是一种可以用作任何逆向工程工具的工具。
反汇编Microsoft Word:
Microsoft Word 和其他程序一样,只是一个可执行文件,而那个可执行文件只是一堆编码指令的字节。
如果你能找到文件位置,应用程序的实际可执行文件的位置。
objdump -d WINWORD.EXE
汇编基础:寄存器,操作数,移动
寄存器
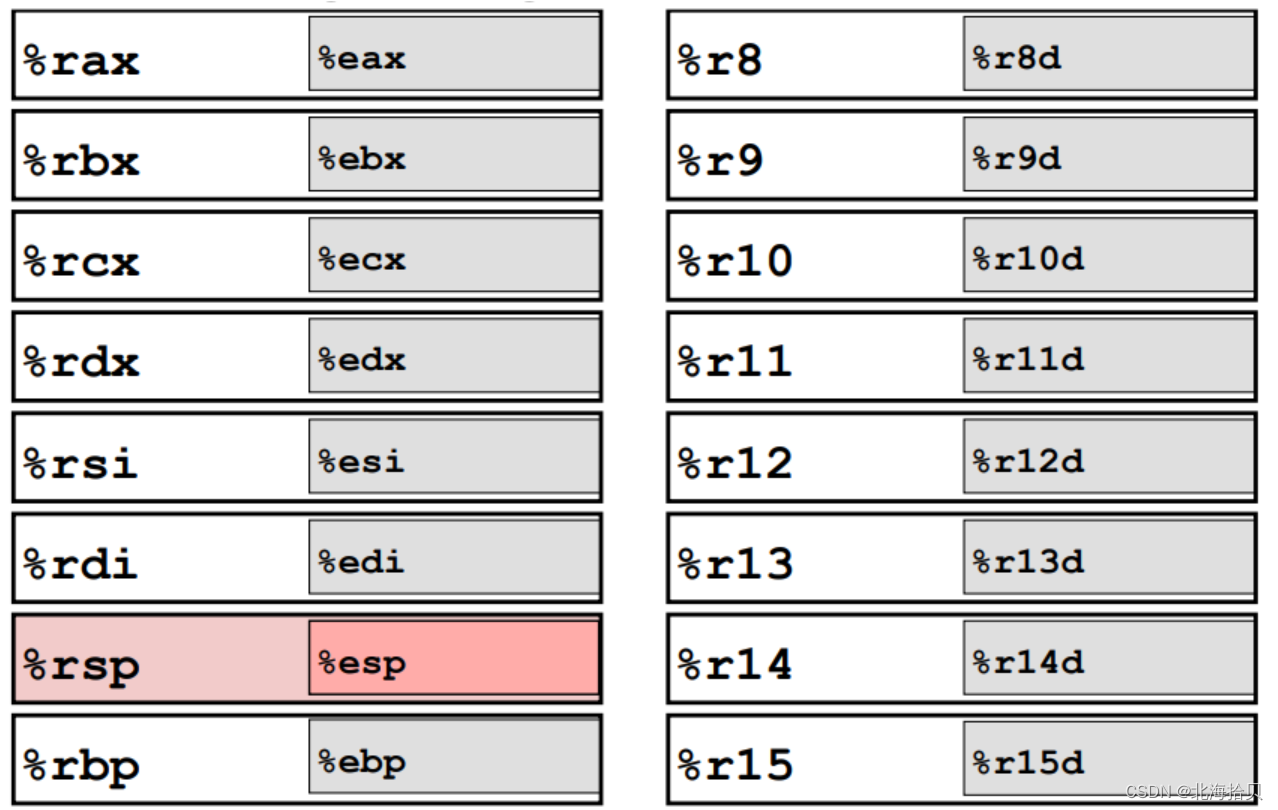
如果使用的是%r 开头的寄存器,你会得到64位。
如果使用的是 %e 开头的寄存器版本,你会得到32位。
%e 版本指示较大%r 实体低32位。
实际用法更多,你也可以引用低阶16位,和低8位。
从IA32 到 x86-64的变化之一是将寄存器数量增加一倍。
移动数据 mov
指令:
movq Source, Dest
操作数类型:
-
立即数 Immediate: 整型常数
示例:$0x400, $-533
和C常量,但是以$为前缀
编码1,2,4字节 -
寄存器 Register :16个寄存器中的一个
示例:%rax, %r13
%rsp保留自己的特殊用途
其他的寄存器有特殊用途对于特殊指令。 -
内存 Memory: 在寄存器给出的地址上有8个连续字节的内存
最简单的示例:(%rax)
各种其他“地址模式”

注意事项:
- 将立即值作为目的地没有意义,它是常数
- 出于硬件设计者的方便,它不允许你直接从一个内存位置复制到另一个内存位置。
你需要两个指令,一个从内存中读取值,将其复制到寄存器。第二个是在寄存器中取值并将其写入内存。
q: quad 四字节
简单的内存地址模式
- 正常模式
(R) Mem[Reg[R]]
寄存器R指定内存地址。
示例:
movq (%rcx), $rax
- 位移模式(Displacement)
D(R) Mem(Reg[R] + D)
寄存器R指定内存区域开始的位置。
常量位移D指出偏移量。
示例:
movq 8(%rbp), %rdx
地址模式示例
- c语言代码
void swap(long *xp, long*yp)
{
long t0 = *xp;
long t1 = *yp;
*xp = t1;
*yp = t0;
}
- 汇编代码
运行命令:gcc -S -Og swap.c
swap:
movq (%rdi), %rax # t0 = *xp
movq (%rsi), %rdx # t1 = *yp
movq %rdx, (%rdi) # *xp = t1
movq %rax, (%rsi) # *yp = t0
ret
寄存器对应的值:
- %rdi xp
- %rsi yp
- %rax t0
- %rdx t1
操作流程:
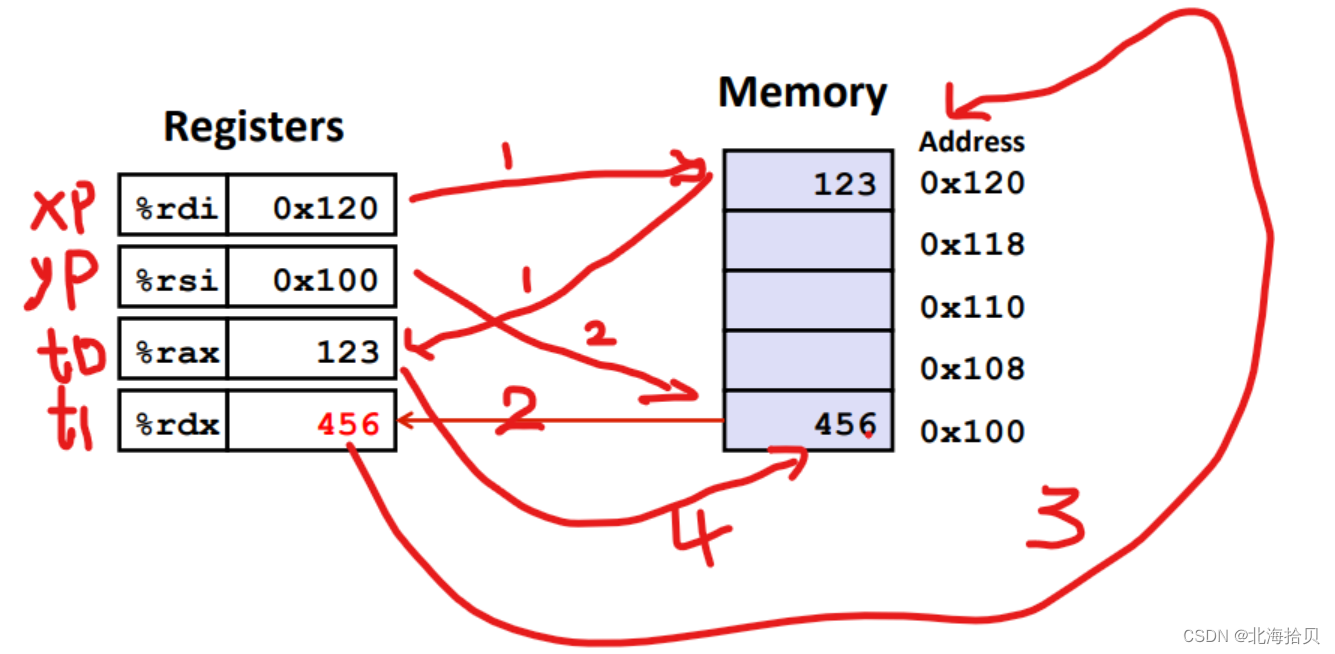
实际中交换方法
实际中我们只会使用中间变量来进行交换:
void swap(long *xp, long*yp)
{
long t0 = *xp;
*xp = *yp;
*yp = t0;
}
我们用命令得到汇编代码,会发现和上面的汇编代码是一样的。
为什么?
回到前面我们所说的mov指令。它不允许你直接从一个内存位置复制到另一个内存位置。
你需要两个指令,一个从内存中读取值,将其复制到寄存器。第二个是在寄存器中取值并将其写入内存。
所以 *xp = *yp的执行就是:
long t1 = *yp
*xp = t1
所以实际中我们这么只使用一个中间变量进行操作,和使用两个中间变量进行操作并没有多大影响。
只是代码更简洁一点而已。
完整的内存地址模式
- 常用形式
D(Rb, Ri, S) Mem[Reg[Rb] + S*Reg[Ri]+D]
D: Displacement, 位移。恒定位移 1,2,4 字节
Rb: Base Register, 基础寄存器。 16个寄存器中的一个。
Ri: Index Register, 索引寄存器。特别是%rsp。
S: Scale, 缩放。 1,2,4,8 固定是这些数。
这是实现数组索引的一种自然方式。
如果这是一组数组索引,我们必须通过我的数据类型的字节数来缩放索引值,如果它是一个int我们必须将索引缩放四倍,如果它是long,我们必须将其缩放八倍。(这就是S必须是1,2,4,8这些数)
- 特殊形式
缺失其中一些项。
(Rb,Ri) Mem[Reg[Rb]+Reg[Ri]]
D(Rb,Ri) Mem[Reg[Rb]+Reg[Ri]+D]
(Rb,Ri,S) Mem[Reg[Rb]+S*Reg[Ri]]
示例:
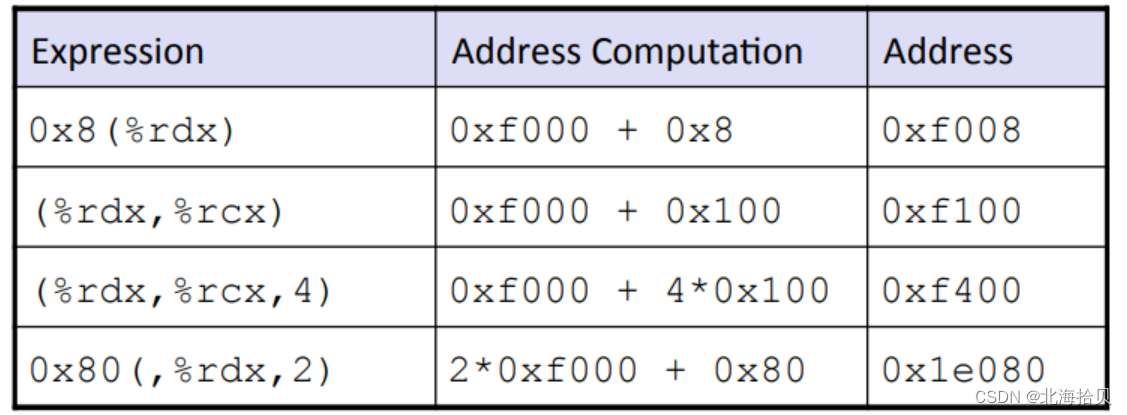
0xf000 = 1111 0000 0000 0000
2 * 0xf000 = 二进制左移1位 = 0001 1110 0000 0000 0000 = 0x1e000
2 * 0xf000 = 2 * 15 = 30 = 0x1e000
地址计算指令 lea
lea : load effective address, 加载有效地址。
对上面内存地址模式的运用。
leaq Src, Dst
Src : 地址模式表达式
Dst : 设置dst为用表达式表示的地址
使用:
-
计算没有内存引用的地址
例如:p = &x[i] -
计算算术表达式: x + k*y
k = 1,2,4,或8
示例
- c 代码
long m12(long x)
{
return x*12;
}
- 汇编码
教程中得到:
leaq (%rdi,%rdi,2), %rax # t <- x+x*2
salq $2, %rax # return t<<2
我得到:
leaq (%rdi,%rdi,2), %rdx
leaq 0(,%rdx,4), %rax
算术运算 和 逻辑运算
- 两个操作数的指令
格式 计算
addq Src,Dest Dest = Dest + Src
subq Src,Dest Dest = Dest - Src
imulq Src,Dest Dest = Dest * Src
salq Src,Dest Dest = Dest << Src
sarq Src,Dest Dest = Dest >> Src
shrq Src,Dest Dest = Dest >> Src
xorq Src,Dest Dest = Dest ^ Src
andq Src,Dest Dest = Dest & Src
orq Src,Dest Dest = Dest | Src
- 一个操作数的指令
incq Dest Dest = Dest + 1
decq Dest Dest = Dest - 1
negq Dest Dest = - Dest
notq Dest Dest = ~Dest
注意事项:
- 操作数的顺序与你期望他们的顺序相反,源操作数在前,目的操作数在后面。
示例
- c代码
long arith(long x, long y, long z)
{
long t1 = x+y;
long t2 = z+t1;
long t3 = x+4;
long t4 = y * 48;
long t5 = t3 + t4;
long rval = t2 * t5;
return rval;
}
- 汇编代码
leaq (%rdi,%rsi), %rax # t1
addq %rdx, %rax # t2
leaq (%rsi,%rsi,2), %rdx # 3y
salq $4, %rdx # t4 = 4 * 3y
leaq 4(%rdi,%rdx), %rcx # t5
imulq %rcx, %rax # rval
- 寄存器对应的变量
%rdi x
%rsi y
%rdx z
%rax t1,t2, rval
%rdx t4
%rcx t5
《深入理解计算机系统》书籍学习笔记
《深入理解计算机系统》学习笔记 - 第一课 - 课程简介
《深入理解计算机系统》学习笔记 - 第二课 - 位,字节和整型
《深入理解计算机系统》学习笔记 - 第三课 - 位,字节和整型
《深入理解计算机系统》学习笔记 - 第四课 - 浮点数
《深入理解计算机系统》学习笔记 - 第四课 - 机器级别的程序