【C++学习】模板进阶——非类型模板参数 | 模板的特化 | 分离编译
🐱作者:一只大喵咪1201
🐱专栏:《C++学习》
🔥格言:你只管努力,剩下的交给时间!

模板我们之前一直都在使用,尤其是在模拟STL容器的时候,可以说,模板给类增加了更多的可能性,是C++最重要的部分之一。下面本喵来更深入的讲解一下模板。
模板进阶
- 📕非类型模板参数
- 📗std::array
- 📕模板的特化
- 📗函数模板的特化
- 📗类模板的特化
- 全特化
- 偏特化
- 类模板特化应用示例
- 📕分离编译
- 📕总结
📕非类型模板参数
#define N 10
namespace wxf
{
template<class T>
class array
{
public:
T& operator[](size_t index)
{
assert(index < _size);
return _array[index];
}
const T& operator[](size_t index) const
{
assert(index < _size);
return _array[index];
}
private:
T _array[N];
size_t _size;
};
}
在上面代码中,创建了一个数组的模板类,它相比于C语言中的数组,可以自动进行越界检查。
wxf::array<int> a1;
wxf::array<double> a2;
我们可以创建不同类型的对象,数组中的元素可以是int,也可以是double类型。但是,它们的大小都是一样的,都被define定义的N限制了。
如果此时我想让int类型的数组大小是10个元素,而double类型的数组大小是100个元素,该怎么办?
此时就用到了非类型模板参数,我们之前使用的模板,它的参数都是类型模板参数,也就是它的参数都是类型,可以是内嵌类型,也可以是自定义类型。
- 非类型模板参数:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
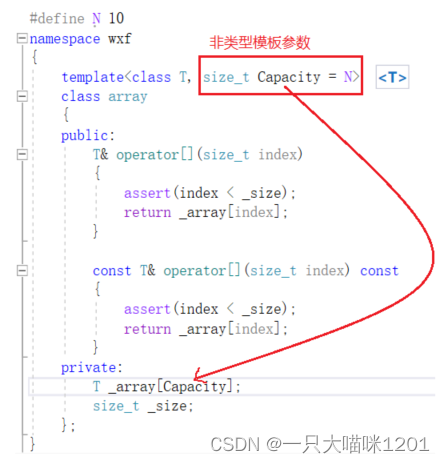
在模板中,加入第二个参数,不使用class或者typename关键字来修饰,表面它是一个非类型模板参数。并且将这个参数应用在定义数组的大小上,如上图所示。
- 模板参数可以使用缺省值。
wxf::array<int, 10> a3;
wxf::array<double, 100> a4;
此时再创建类对象,就可以在实例化类型的同时,指定数组的大小。指定数组大小的这个模板参数就是非类型模板参数。
- 非类型模板参数必须是整形家族的常量,比如char类型,int类型等等,不能是double以及float类型。
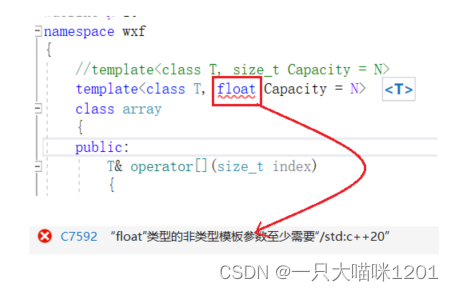
如上图所示,将非类型模板参数的类型改成float以后就会报错,现在不支持这样,以后不一定。
- 在实例化时,传模板参数必须传常量,不能传变量。
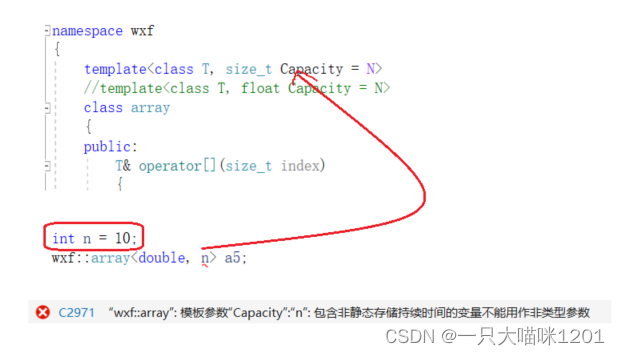
如上图所示,当实例化传给非类型模板参数的值是一个变量的时候,就会报错。
📗std::array
在C++11的STL中,官方同样给我们提供了array容器。

它就使用了非类型模板参数,下面看看它有什么接口。

这些接口和我们之前学习string,vector,list以及stack和queue中的接口非常相似,但是,array中没有push_back。
- STL中的array是一个静态的,它的大小在创建时候就指定了,并不会发生扩容。
- 它对标的是C语言中的数组,只是比C语言中数组多了越界检查。
C语言数组越界:
int a1[10];
cout << a1[11] << endl;
越界访问并没有报错。
int a1[10];
a1[11] = 5;
越界写也没有报错。
无论是写还是读,越界的时候都不会报错。不同的编译器对越界的处理不同,有的是采取抽查的策略。总得的来说,C语言的数组在越界检查上面存在缺陷。
std::array越界:
std::array<int, 10> a1;
cout << a1[11] << endl;
a1[11] = 10;
使用STL中的array容器就会进行越界检查。
📕模板的特化
📗函数模板的特化
namespace wxf
{
template<class T>
bool less(T left, T right)
{
return left < right;
}
}
定义一个函数模板,进行比较大小,当左值小于右值时返回真。

比较结果符合我们的预期。
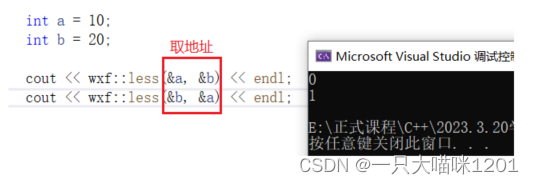
当传递的参数是两个变量的地址时,比较的结果就和刚刚的截然相反。
- 模板函数推断出来的类型是int*,按照函数模板的实现逻辑,比较的是两个地址的大小。
- 但是我们希望的是,即使传入的是地址,但是比较的仍然是两个数的大小。
此时我们就可以使用模板特化。
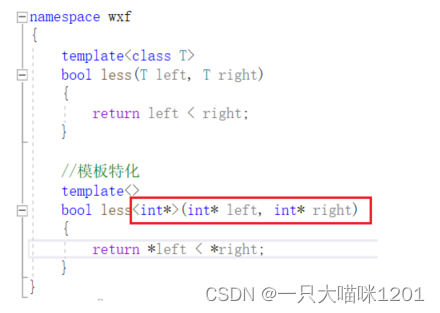
- 模板参数给空。
- 函数名后<>内放入要特化的类型,函数形参同样使用特化的类型。
- 改变特化后函数内部的逻辑。
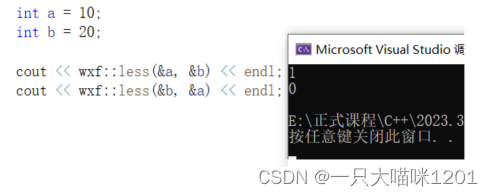
可以看到此时就符合我们的预期了,即使传入的是地址,但是比较的仍然是两个数的大小。
- 模板特化必须在原模版的基础上进行特化。
- 其他类型仍然会实例化原模版,需要特别处理的类型就会走特化后的模板。
但是:
一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
就像上面的比较函数,在处理指针类型的变量时,完全可以写一个具体的函数而不用函数模板。
bool less(int* left, int* right)
{
return *left < *right;
}
该种实现简单明了,代码的可读性高,容易书写,因为对于一些参数类型复杂的函数模板,特化时特别给出,因此函数模板不建议特化。
📗类模板的特化
全特化
template<class T1,class T2>
class Data
{
public:
Data()
{
cout << "Data<T1, T2>" << endl;
}
private:
T1 _a1;
T2 _a2;
};
定义个这样的数据类,类型模板参数有两个。
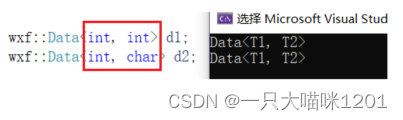
此时无论是用什么类型进行实例化,编译器都会按照上面的类模板去推演,去实例化。
- 如果此时我想让int和char类型对象进行特殊化处理,不按照原理的类进行创建呢?
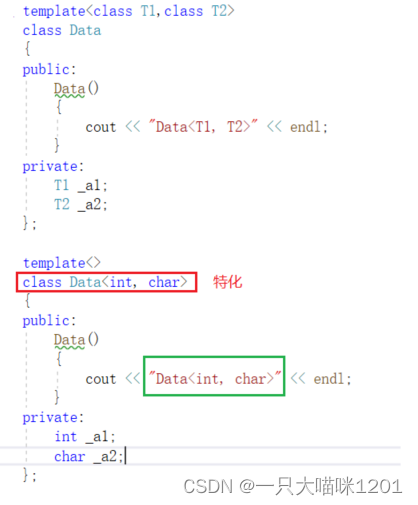
此时就可以将原本的类模板进行特化处理,对类型模板参数是int和char类型进行特殊化处理。
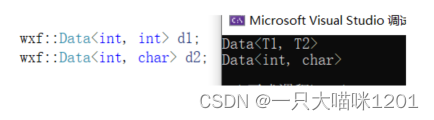
可以看到,用的类模板都不一样了,因为构造函数中打印的内容不一样。
全特化即是将模板参数列表中所有的参数都确定化。
偏特化
还是使用最初的Data数据类模板进行特化。偏特化有有两种:
- 部分特化

当两个模板参数中的第二个是double类型的时候,进行特殊处理。

无论第一个参数是什么类型,只要第二个是double类型的,就会按照这个部分特化后的模板进行实例化。
- 参数更进一步的限制
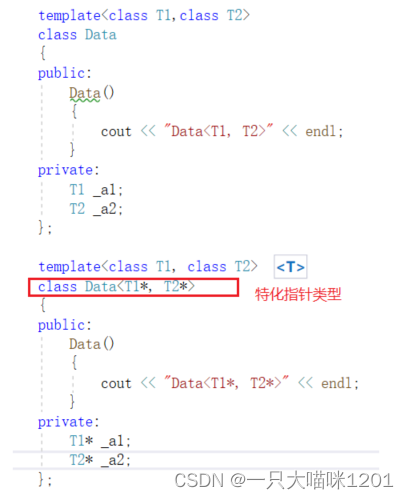
无论是什么类型,只有是指针类型,就进行特化处理。
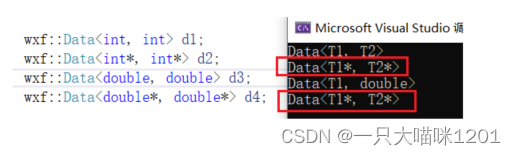
此时特化后的模板就限制在了只处理指针类型。
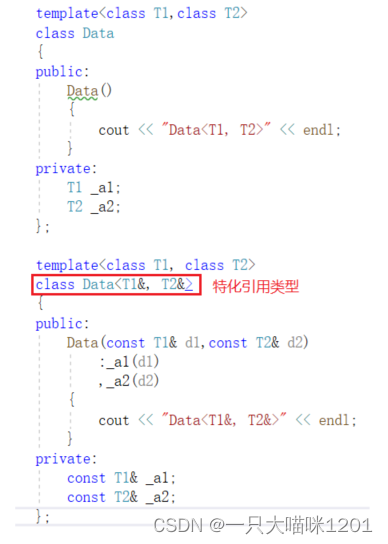
还可以对引用类型进行特化。但是引用类型必须进行初始化。

此时特化后的模板就只限制在了引用类型。
从模板特化中也可以看出来编译器在实例化时推演的规则:
- 有现成的就用现成的,不进行推演。
- 有全特化的就用全特化的。
- 有偏特化的就用偏特化的。
- 实在没办法才全部进行推演。
总得来说,编译器也是懒狗,能少干事就少干,能不推演就不推演,能少推演就少推演。
类模板特化应用示例
template<class T>
struct less
{
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
写一个两个数相比较的仿函数,左数小于右数的时候返回真。
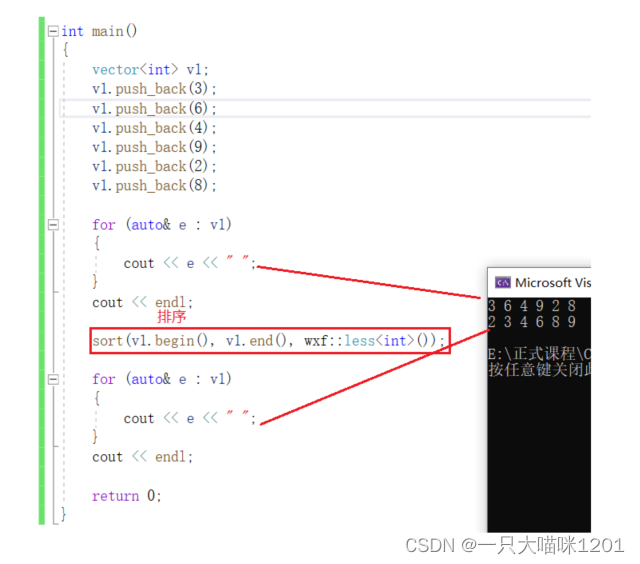
将vector中的数据按照升序进行排列。
- 使用的是算符库中的sort函数,需要使用到我们定义的仿函数。
同样,如果vector中放入的不是数据,而是数据的地址,但是我们又想按照升序排列。
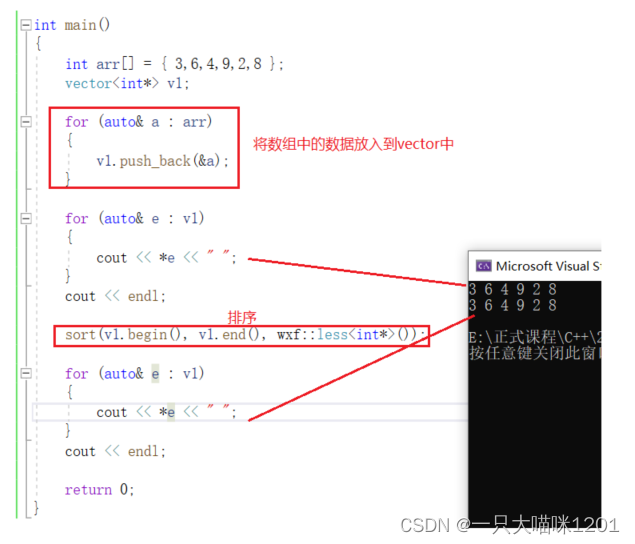
可以看到,此时排序后的结果和排序前是一样的。
- 数组中的地址是连续的,而且后面元素的地址比前面元素的地址大。
- 此时使用仿函数less还是按照之前逻辑,比较的是地址值,而不是地址指向数据的值。
所以我们需要将less仿函数进行特化处理:
//特化处理
template<class T>
struct less<T*>
{
bool operator()(T* const& x, T* const& y)
{
return *x < *y;
}
};

此时传的是地址,但是仍然按照升序重新排列好了。
说明:

看红色框中的参数类型,来复习一下const的用法。
- 通常情况下const T& x,目的是防止x被修改。
- 此时是T*类型的变量,仍然需要防止变量被修改。
- T* const& x,也是防止x被修改。
- const T*& x,防止的是指针x指向的内容被修改。
📕分离编译
通常我们会将定义的类,函数声明等等放在一个头文件中,具体的实现放在源文件中,采用声明和定义分离的方式。
同样,模板类也可以这样。以vector举例。
头文件中代码:
#include <iostream>
namespace wxf
{
template<class T>
class vector
{
public:
vector(int capacity = 10);
int size();
private:
T* _arr;
int _size;
};
}
源文件中代码:
#include "myvector.h"
namespace wxf
{
template<class T>
vector<T>::vector(int capacity)
:_arr(nullptr)
,_size(capacity)
{
std::cout << "成功创建" << std::endl;
}
template<class T>
int vector<T>::size()
{
return _size;
}
}
此时对于我们实现的这个vector模板类,就是采用的声明和定义分离的方式。

但是在使用的时候,报的是链接错误。
原因分析
首先回忆一下编译链接的过程,它有如下几步:
- 预处理
myvector.h myvector.cpp test.cpp
- 将头文件在两个源文件中展开
- 去注释
- 宏替换
- 条件编译
- 编译
myvector.i test.i
- 两个.i文件分别进行编译,互相独立。
- 进行词法分析,语法分析,生成中间代码,优化(生成汇编语言)。
- 形成符号表,错误表等。
- 汇编
myvector.s test.s
- 两个.s文件分别进行汇编,相互独立。
- 生成二进制机器码。
- 链接
myvector.o test.o
- 多个.o文件进行链接。
- 合并符号表。
- 生成可执行文件。
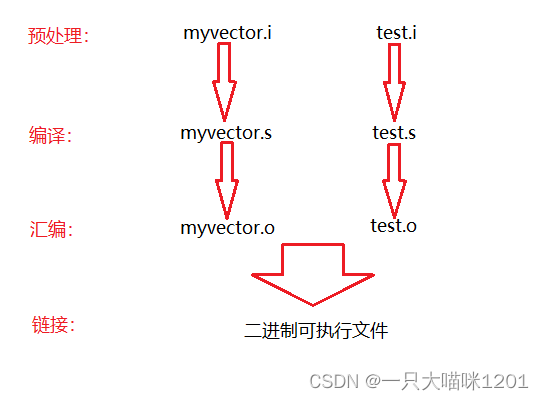
两个源文件进行编译链接的过程是独立的。
对于myvctor.cpp:
- 在编译的时候会形成符号表。
- 由于此时只有模板类的声明和定义,并没有实例化,所以不能形参一个完整的类。
- 所以在最后生成的.o中,没有生成符号表。
对于test.cpp:
- 同样在编译的时候会形成符号表。
- 由于此时只有模板类的实例化和声明,但是没有定义。
- 所以生成暂时的符号表,等链接时候去寻找定义。
链接过程:
- 当test.o根据自己的符号表去myvector.o的符号表中寻找相同符号的具体定义时。
- 发现myvector.o中没有生成符号表,所以无法找到定义,也就是无法完成链接。
- 所以报链接错误。
解决方案一:
我们知道在myvector.cpp中确实模板类的实例化,所以给它加上实例化:
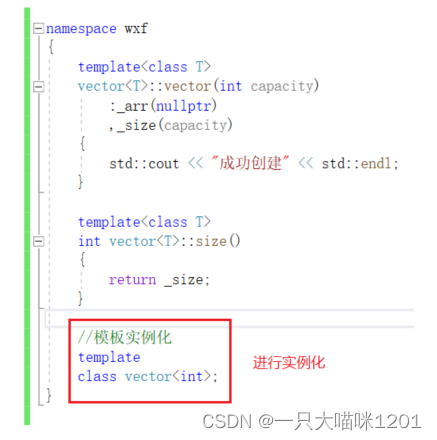
此时创建成功。
解决方案二:
我们知道,在test.cpp中确实模板类的定义,所以我们给它加上定义:
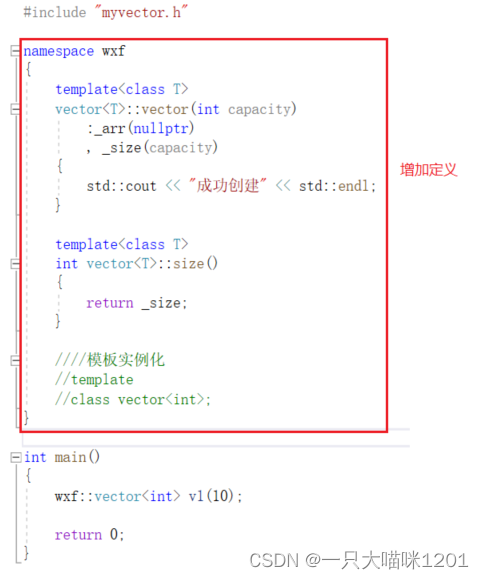
同样创建成功。
虽然两种方案都可以解决,但是第一种使用的非常别扭,所以我们常常使用第二种方案的改进版本。
- 在预处理的时候,myvector.h被复制展开到了test.cpp中,所以有了模板类的声明。
- 在test.cpp中增加模板类的定义后,相比于最开始的test.cpp,既有了声明又有了定义。
- 所以我们将声明定义都放在myvector.h中,在预处理后,test.cpp中自然就又有了声明,也有了定义。
- 若将模板类的定义放在实例化之前,那么就可以不要模板类的声明。
- 因为编译器是从下往上找,所以从实例化处向上寻找之间可以找到定义,声明和没有必要了。
通常将同时有模板类的声明和定义的文件,取后缀为.hpp。
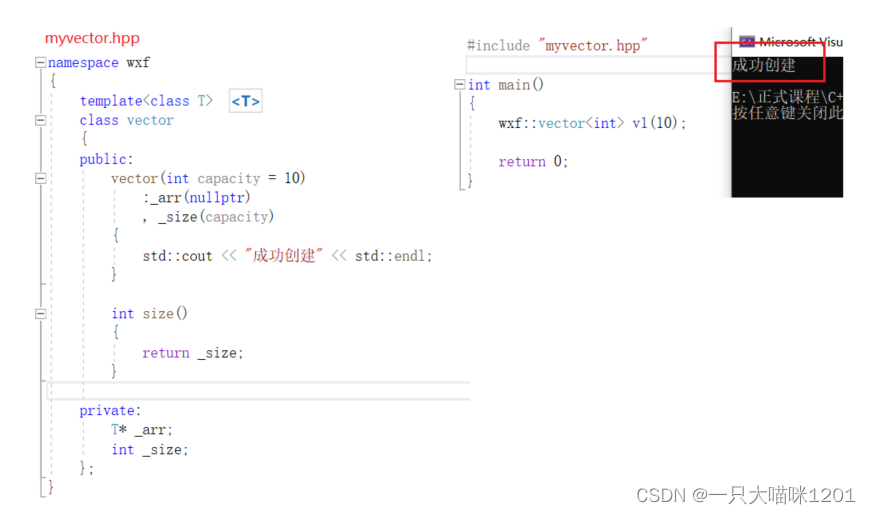
此时同样创建成功,而且和我们之前写类模板的方式一样,用起来和看起来都很舒服。
强烈不建议使用声明和定义分离的方式,要使用.hpp的方式。
📕总结
优点:
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生。
- 增强了代码的灵活性。
缺点:
- 模板会导致代码膨胀问题,也会导致编译时间变长。
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误。
以上便是模板进阶的全部内容,未涉及到的细节,在后面使用到的时候再详细介绍。