提示工程玩转 ChatGPT
Prompt engineering is the skill of the future.
目录:
1. 简介 (Introduction)
2. 提示指南 (Prompt Guidelines)
2.1 指令要清晰明确
2.2 给模型时间思考
3. 迭代提示 (Iterative Prompt)
3.1 迭代过程
3.2 案例展示
4. 文本概括 (Text Summarization)
4.1 单文本概括
4.2 多文本概括
5. 文本推断 (Text Inference)
5.1 情感分类
5.2 情感识别
5.3 名称提取
5.4 多项任务
5.5 主题推断
6. 文本转换 (Text Transformation)
6.1 文本翻译
6.2 语言纠正
6.3 语气调整
6.4 格式转换
6.5 综合案例
7. 文本扩充 (Text Expansion)
7.1 定制客户邮件
7.2 使用温度参数
8. 总结 (Conclusion)
1
简介
大语言模型 (large language model, LLM) 已经逐渐进入了人们的生活,而 ChatGPT 就是目前最火的 LLM。对非技术人员要使用 LLM,其实不需要了解 LLM 背后的原理和实现,而只需要知道如何写一个好的提示 (prompt)。提示越清晰明确得到的答案就越有价值,提示工程是未来需要掌握的技能。
本文是学习 Andrew Ng 的 DeepLearning.AI 和 OpenAI 合办的《ChatGPT Prompt Engineering for Developers》课程,课程链接为:https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/。
本文结构如下。第二节提出写提示的两大原则 (principles),即要清晰明确又要给模型时间思考,但写的第一个提示通常差强人意,第三节会列出迭代提示 (iterative prompt) 的过程直到写出一个好的提示。第四到七节分别从文本概括 (summarize)、文本推断 (infer)、文本转换 (transform)、文本扩充 (expand) 来展示 ChatGPT 的应用。最后第八节做总结。
使用 ChatGPT 除了从 OpenAI 官网上注册账号使用,也可在 SignalPlus Trading Tool (https://t.signalplus.com/) 上注册账号并使用,进入主界面点击 +Add a Widget,选取 ChatGPT 即可,如下面视频所示。
2
提示指南
本节列出编写指示的两大原则,并且给出相关的具体策略。两大原则是:
指令要清晰明确 (write clear and specific instructions)
给模型时间思考 (give the model time to “think”)
2.1
指令要清晰明确
为了能引导模型输出你想要的答案,你给出的指令要尽可能的清晰和明确。注意,清晰指令不等于简短指令,很多情况下,长指令能更清晰的提供上下文背景,这会使得模型输出更详细更相关。
策略一:使用分隔符使其能够清晰的指代输入的不同部分,分隔符可以是:```, """, < >, <tag></tag> 等。
除了以上分隔符,可以使用任何明显的标点符号将提示中的特定文本部分与剩余部分分开,在中文中分隔符还可以是引号 “”。这么做是为了让模型明确知道这是一个单独标记。
下例给出一段话并要求 ChatGPT 来概括,在该示例中我们使用引号 “” 来作为分隔符。提示的内容如下:

注意:提示的内容用以上 Python 的代码形式写出来是为了能更清晰的看出内容,比如用了 \ 来分句便于阅读,在 text 和 prompt 用 f-string 是为了把文本和提示分隔开,注意 “{text}” 两边的引号就是分割符。
但是在 SignalPlus Trading Tool 里,我们不能用上面代码形式输入,只能输入一整个字符串。有的时候字符串太长不便于阅读,这时候就可以参考上看 Python 代码里的字符串,因为两者的功能是一样的,只不过一个便于阅读但不能输入到对话框里,一个不便于阅读但需要输入到对话框里。在 SignalPlus Trading Tool 的运行结果如下:
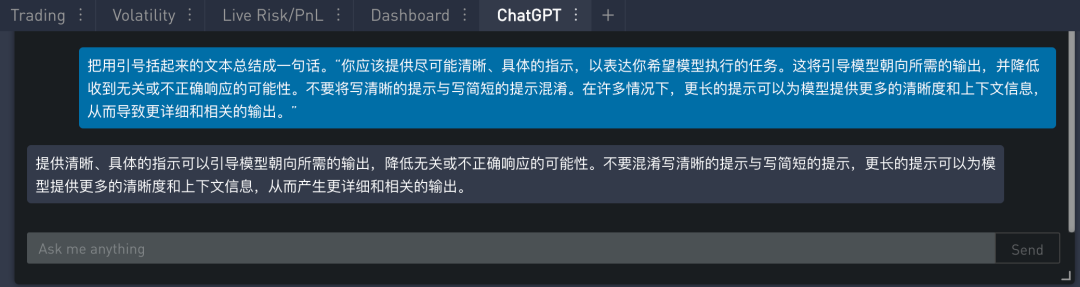
策略二:让输出结构化,比如以 JSON 或 HTML 等数据格式。
该策略主要目的是让模型输出更容易被解析,像 JSON 可以很容易在 Python 中读取,而 HTML 也很容易以网页形式展示。
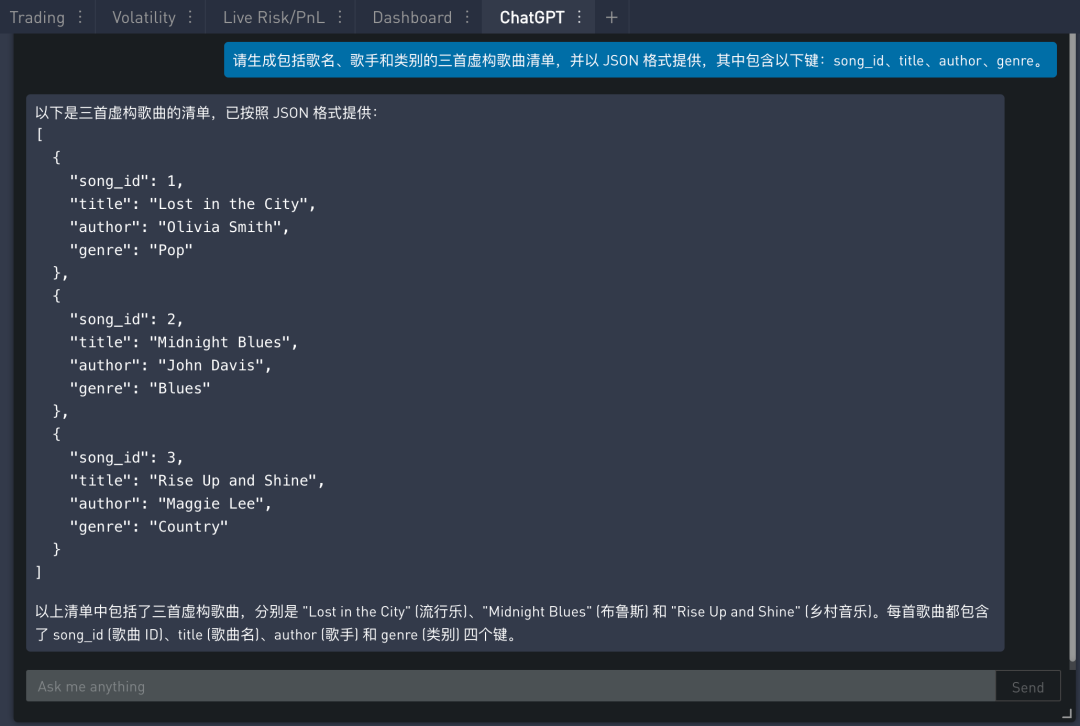
下例要求 ChatGPT 生成三首歌的标题、作者和类别,并以 JSON 的格式返回,为便于解析,我们指定了 JSON 的键包括 song_id, title, author, genre。提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
策略三:要求模型检查是否满足条件。
每个任务都有一定的假设。我么可以告诉模型先检查这些假设,如果做出任务的假设不满足,指示并停止执行。
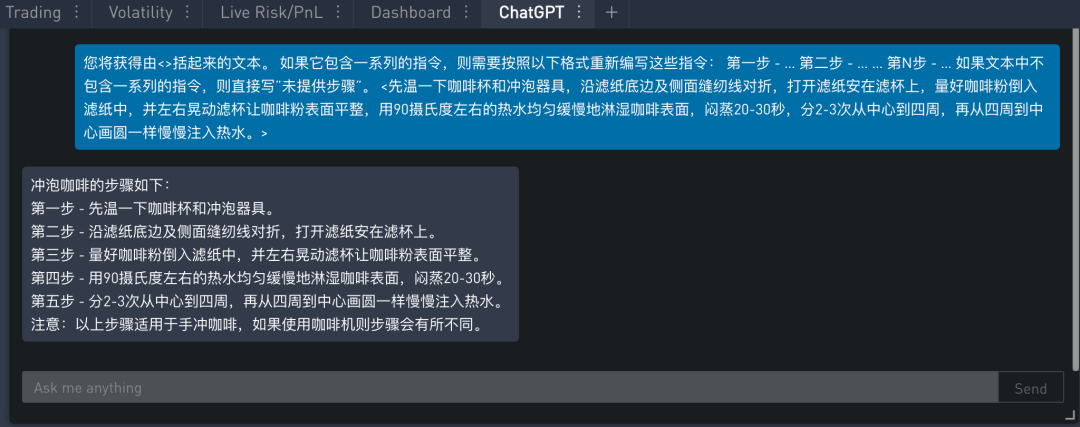
在下面两例中,我们将分别给模型两段文本,分别是“冲咖啡的步骤”和“介绍新加坡天气”的文本。我们将要求模型判断其是否包含一系列指令:
如果包含则按照给定格式重新编写指令
如果不包含则回答未提供步骤
包含一系列指令的“冲咖啡的步骤”的文本,提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
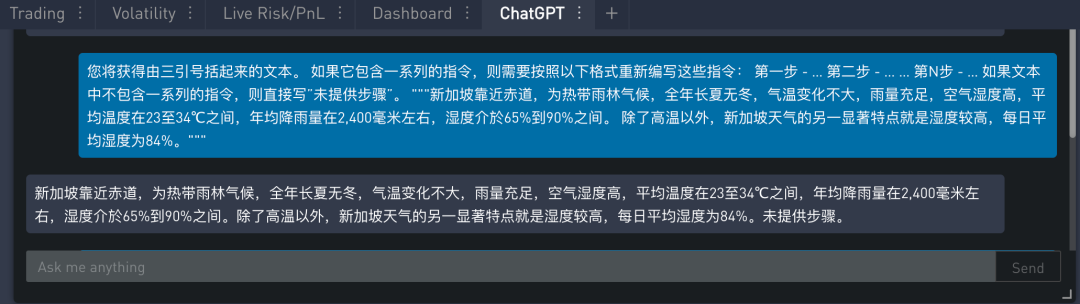
不包含一系列指令的“介绍新加坡天气”的文本,提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
策略四:提供少量示例。
在要求模型执行任务之前,提供它少量能成功的执行任务的示例。
在下例中,我们告诉模型其任务是以一致的风格回答问题。这个风格就是“废话文学”风格,比如
<我> 能力越大
<他> 能力越大,能力就越大
<我> 听君一席话
提示的内容如下:
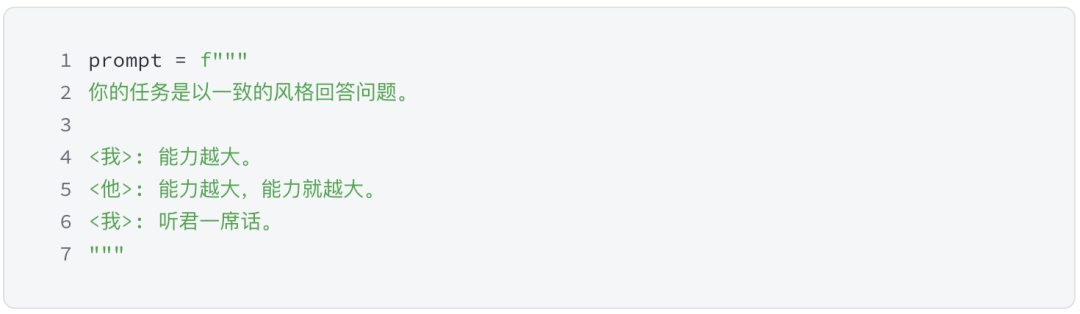
在 SignalPlus Trading Tool 里的运行结果如下:

令人惊奇的是,ChatGPT 通过第一个问和答似乎“领会”到用说废话的方式回答,说了“如听一席话”。关于之后的那一段话“请问有关于股票、...,我会尽力为您提供最好的答案”,可能我们在原有 ChatGPT 问答机制上加了一些额外的内容。
2.2
给模型时间思考
和人一样,很多时候模型在较短时间内会给出错误答案,特别是对于那些在得到答案之前需要进行一系列推理的问题。因此在这种情况下,我们可以给模型一点时间来思考,即便花费了更多计算资源,但给出正确答案的几率会大大增高。
策略一:指定完成任务所需步骤。
接下来我们将通过给定一个复杂任务,给出完成该任务的一系列步骤,来展示这一策略的效果。首先描述了杰克和吉尔的故事,并给出一个指令。该指令是执行以下操作:
用一句话概括三个反引号 ``` 限定的文本
将摘要翻译成法语
在法语摘要中列出每个名称
输出包含以下键的 JSON 对象:法语摘要和名称数
提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
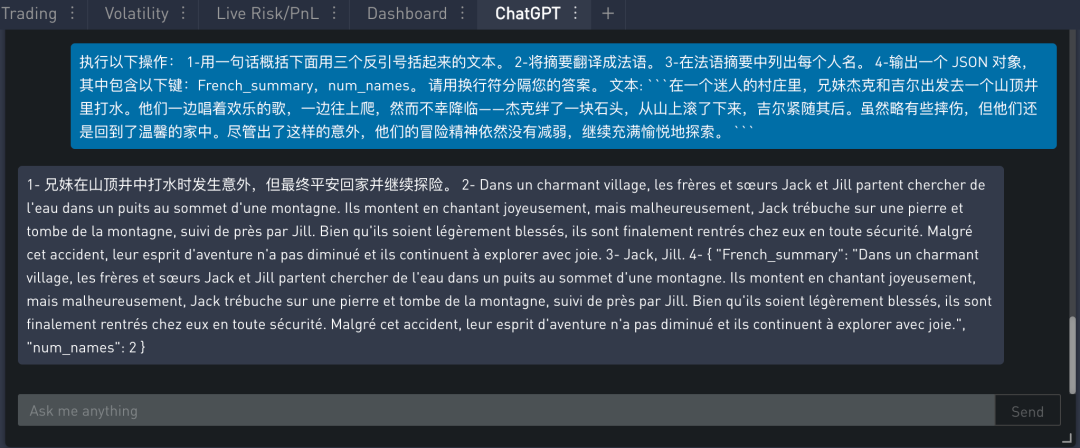
从上面答案来看,ChatGPT 完成的非常出色,这一套做了四个任务:1. 概括,2. 翻译,3. 专名识别,4. 按特定格式输出。
策略二:指导模型在下结论前先给出自己的解法。
有时候在指导模型在做决策之前要给出自己解法时,会得到更好的结果。
在下例中给出一个问题和一个学生的解答,然后让模型判断学生解答是否正确。提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
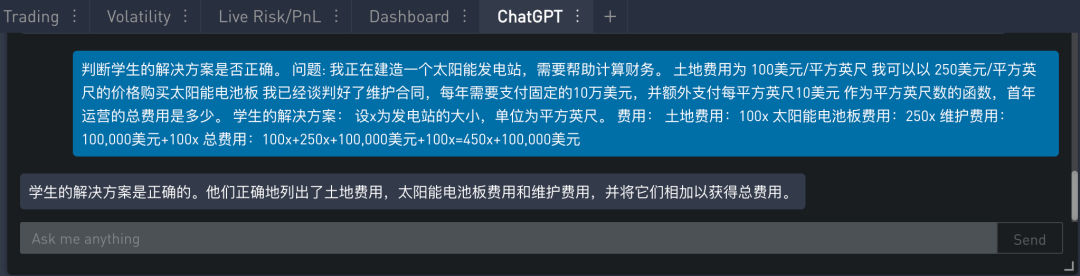
模型判断学生答案是正确的,但是学生算错了,维护费用包括固定支付 10 万美元和额外支付每平方英尺 10 美元,但是模型给出的表达式是:
维护费用:100,000美元 + 100x
正确的表达式应该是:
维护费用:100,000美元 + 10x
提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
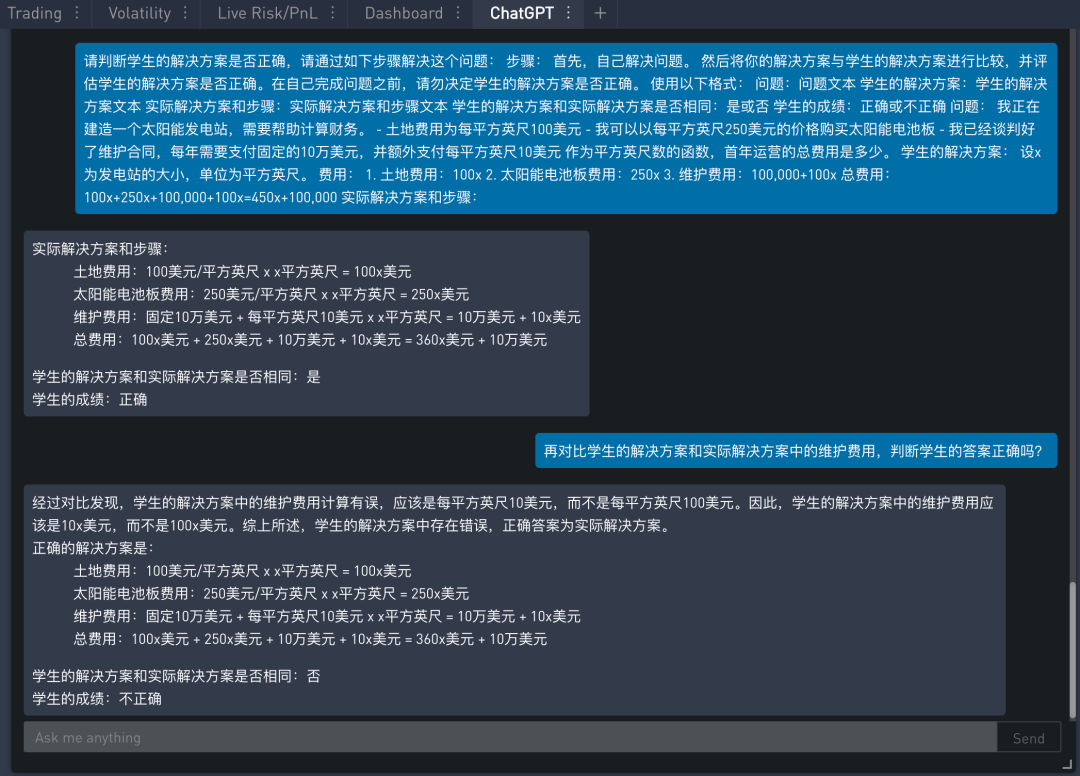
不难发现模型给出的实际解决方案已经将维护费用改成了 100,000美元 + 10x,因此是正确的,但是在判断学生的解决方案和自己的解决方案时犯了错误,明明不相同回答却相同。这时可以再追加一问,重点是让模型把注意力放在维护费用上,最终模型终于在“层层逼问”下给出了正确的答案。
2.3
虚假知识
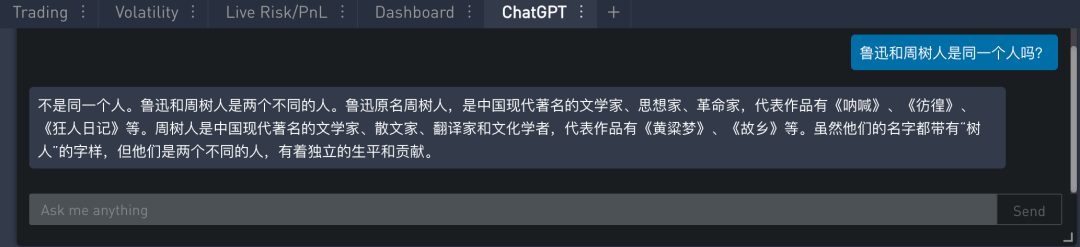
模型偶尔会生成一些看似真实但实际是编造的知识,即一本正经的胡说八道。这是因为模型在训练中没有完全吸收可用信息,因此不知道自己知识的边界只能尝试去编造,这种事实性错误一般统称为幻觉 (hallucination)。该术语最早用于图像合成等领域,后来才沿用至自然语言生成任务,指模型生成自然流畅,语法正确但实际上毫无意义且包含虚假信息即事实错误的文本,以假乱真,就像人产生的幻觉一样。
在下例中,我们鲁迅和周树人是同一个人么。模型回答鲁迅的部分是正确的,而回答周树人的部分就是在胡说八道,最后还“有理有据”的得出鲁迅和周树人不是同一个人的结论。在 SignalPlus Trading Tool 里的运行结果如下:
3
提示迭代
3.1
迭代过程
Andrew Ng 在他的机器学习课程中展示过一张关于“机器学习模型开发流程”的图表,其实该流程是一个迭代过程:
先有一个想法 (idea)
编写代码 (code) 实现想法
根据实验 (experiment) 结果判断想法是否行得通,在此基础上进行学习和总结,从而产生新的想法,并保持这个迭代过程。
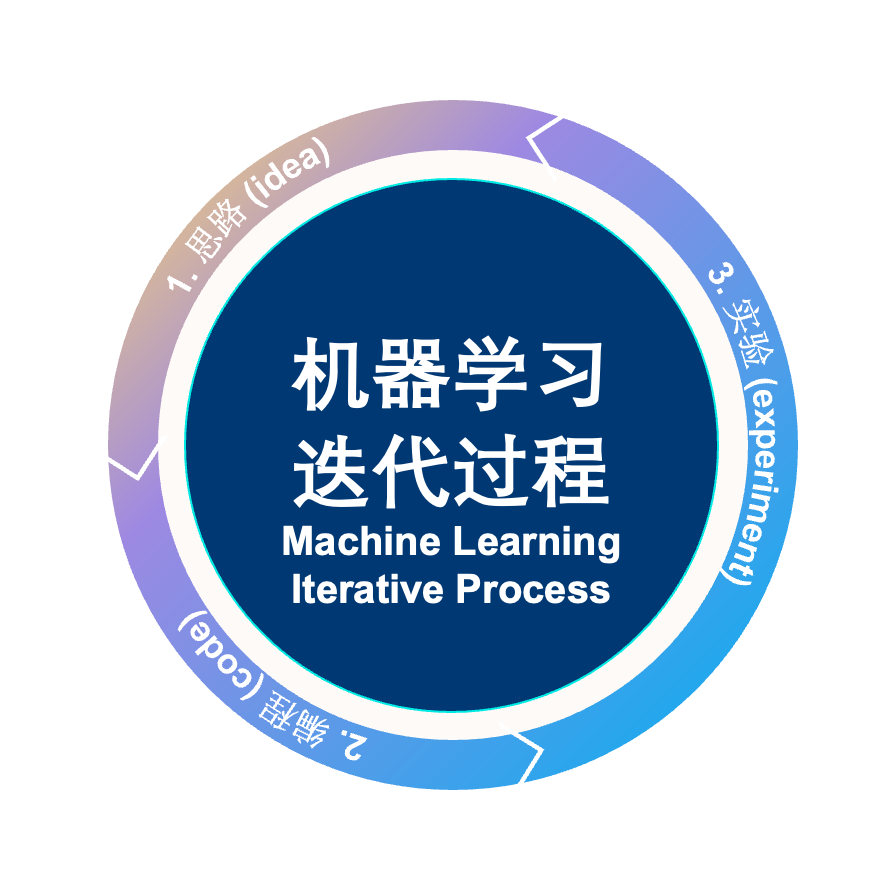
那么利用提示来使用 LLM 开发应用程序时,这个迭代过程和上面非常相似:
先有一个想法 (idea)
编写提示 (prompt) 实现想法
根据实验 (experiment) 结果来看效果,如果效果不好,反思是不是因为指令不够明确或者是否给了模型足够时间思考,以便改进指令,并保持这个迭代过程。

3.2
案例展示
提示的内容如下:

在 SignalPlus Trading Tool 里的运行结果如下:
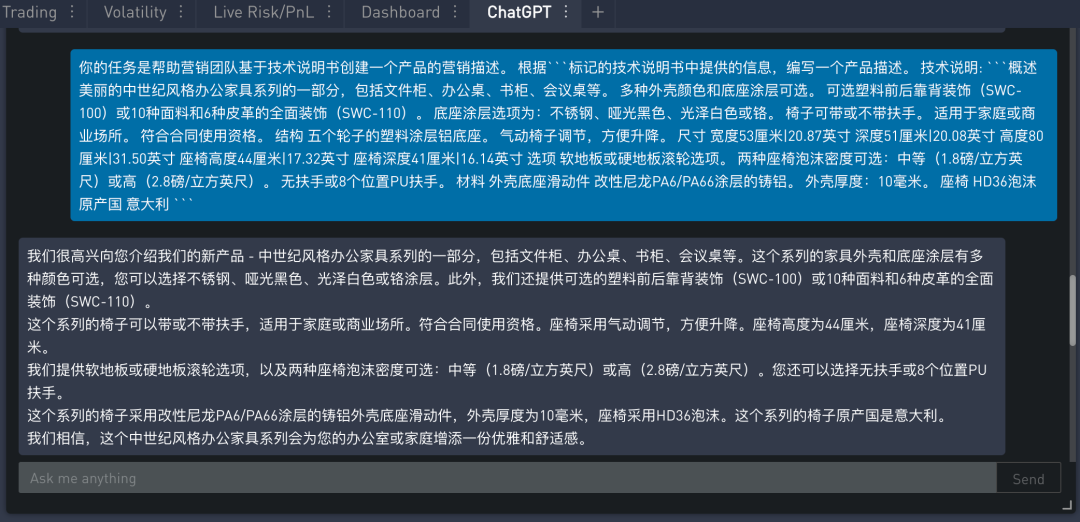
问题一:生成文本太长
ChatGPT 给出的答案还可以,看起来像是一个产品描述,但是有些过长了。这是可以加一个提示,比如“最多 100 个中文词” 来限制生成的文本长度。
修改过的提示的内容如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
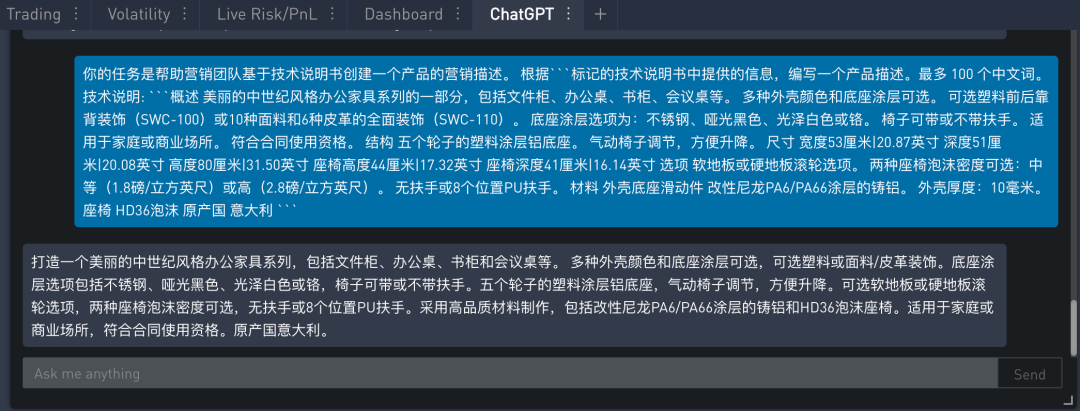
从上面结果可看出,文本已经短了很多,但基本意思都还在。
问题二:文本关注在错误的细节上
如果这个产品描述不是面向消费者,而是面向零售商,那应该怎么修改提示呢?一般零售商更关心椅子的技术性质和用的材料。那么我们修改提示使得它专注于受众群体。
修改过的提示的内容如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
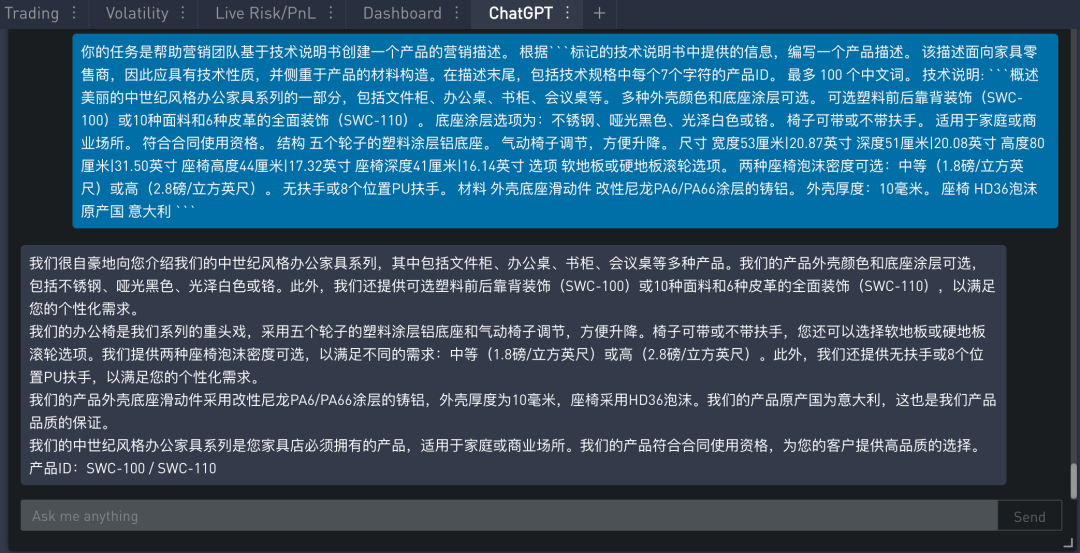
从上面结果可看出,这次文本着重椅子的性质和用材,而且在最后也正确的附上两个产品 ID,美中不足的是,整段比较长,字数超过了限制的 100 个中文词。
问题三:产品特征需要用表格来展示
在抽取信息之后,如果需要以表格形式展示,比如指定表格的列、表名和格式,还要求它将所有内容格式化为可以在网页使用的 HTML。
修改过的提示的内容如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
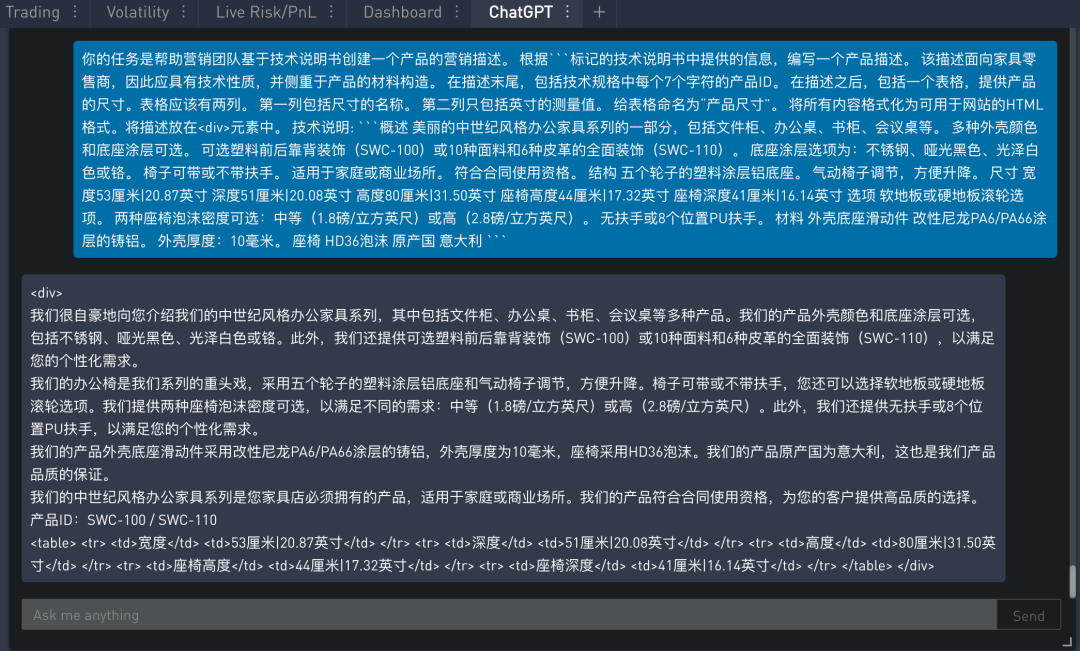
不难发现模型生成一段 HTML 语言,比如有 <div></div> 和 <table></table> 这样的元素。用 IPython.display 将模型产出转换成网页形式。


从上面结果可看出,模型成功的生成的表格,而且里面的数据、特征和单位都是准确的。但是似乎漏掉了这句提示的要求:表格命名为“产品尺寸”。
以上示例许多人都会遇到,首先提示应该保持清晰明确,然后给模型一点时间思考,此外首次编写提示后看看模型产出,然后逐步迭代完善提示,以得到自己想要的结果。很多成功的提示都是通过这种迭代过程得到的。
4
文本概括
现在是信息爆炸的时代,没有人有足够的时间去阅读想要了解的东西,这时可以利用 ChatGPT 帮助我们概括文本。
4.1
单文本概括
这里我们拿亚马逊上买的刘易斯写《Flash Boys》书评为例。
对于电商平台来说,网上的商品评论太多了,如果有一个工具帮我们去概括海量冗长的评论,去洞悉客户的喜好,这样可以使的平台和商家提供更好的服务。从网上摘取的一条书评如下:

要求一:限制文本长度
书评有些长,可以限制它在 30 个词之内。提示如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
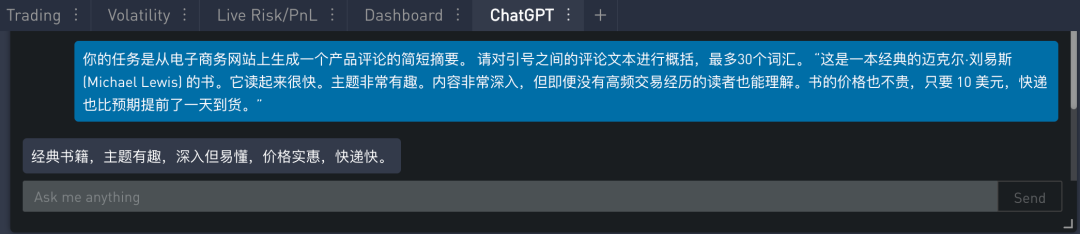
要求二:侧重关键角度
针对不同业务对文本的侧重点会不同。比如商家更关心价格质量,而物流更关心运输时效,这样我们可以修改提示,来体现不同的侧重点。
对于商家,侧重价格质量的提示如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
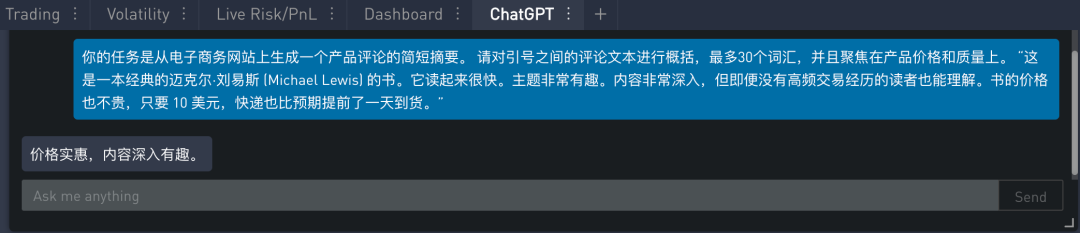
从上面结果可以看出,“价格实惠”指的是价格,“内容深入有趣”指的是质量。
对于物流,侧重运输时效的提示如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
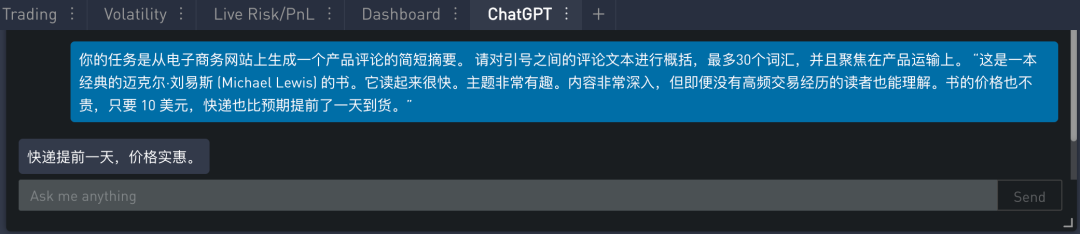
从上面结果可以看出,“快递提前一天”指的是运输时效。
要求三:提取而非概括
上面在给出侧重运输时效时给出的答案还有其他的内容,如“价格实惠”这些不相关的信息。如果只想提取某一角度的信息,我们可以要求模型只做“文本提取 (extract)”而不是“文本概括 (summarize)”。
修改后的提示如下 (黄色高亮显示):

在 SignalPlus Trading Tool 里的运行结果如下:
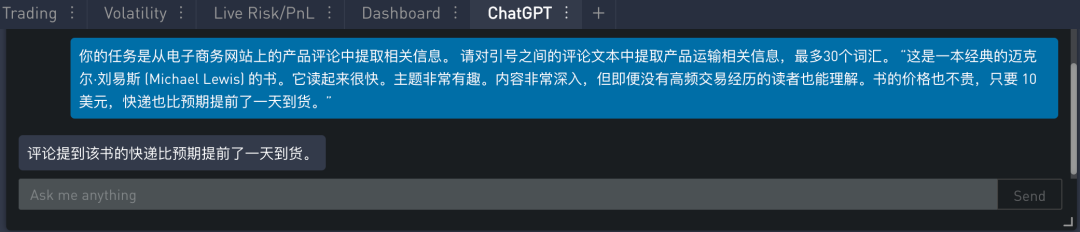
可以看出,这时答案已经过滤掉价格相关的信息,只保留运输相关的信息。
4.2
多文本概括
在实际工作中,往往有海量的评论文本。以下我们用一个基于 for 循环调用“文本概括”工具并依次打印的示例。由于要自动遍历 for 循环内容并对此操作,因此不能利用聊天框来实现,只能编写程序来实现。这里用到 openAI 开发的 get_completion() 函数。

输出结果如下:

5
文本推断
除了前一节介绍的概括本文,LLM 还能推断文本,包括理解情感、提取实体和主题推断等。在传统机器学习模型中,我们需要数据和标签、训练模型和部署模型。这样做可以做到推断文本的效果,但是整套流程需要很多工作。LLM 一个特点是,完成众多任务只需要编写一个好的提示,而不需要进行大量的工作。
5.1
情感分类
我们仍用上节用到的刘易斯写《Flash Boys》书评为例。
首先编写一个用于情感分类的提示:

在 SignalPlus Trading Tool 里的运行结果如下:
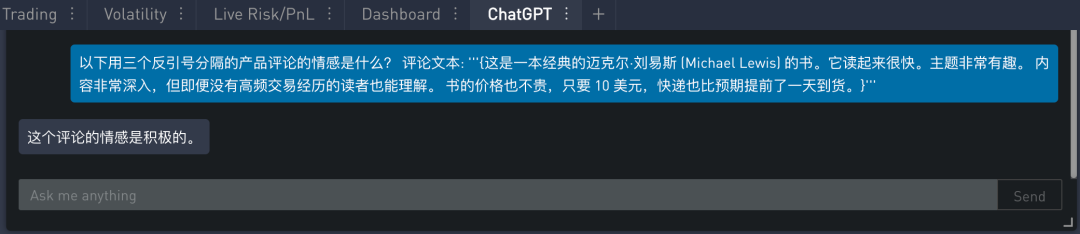
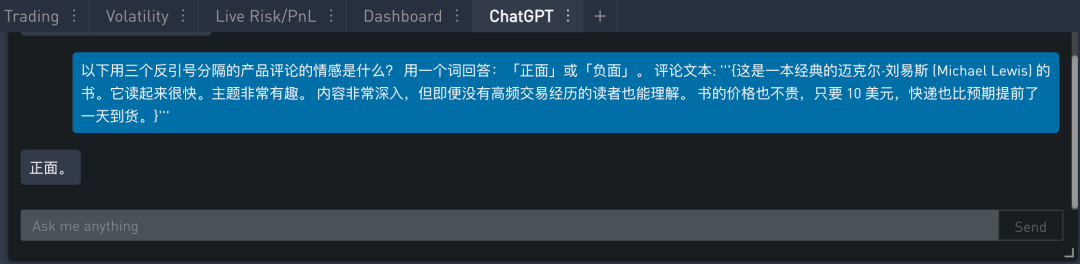
如果想要给出更简洁的答案,可在上面的指示添加另一个指令,以一个单词 “正面” 或 “负面” 的形式给出答案。这样就只会打印出 “正面” 这个单词,这使得文本更容易接受这个输出并进行处理。修改过的提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:
5.2
情感识别
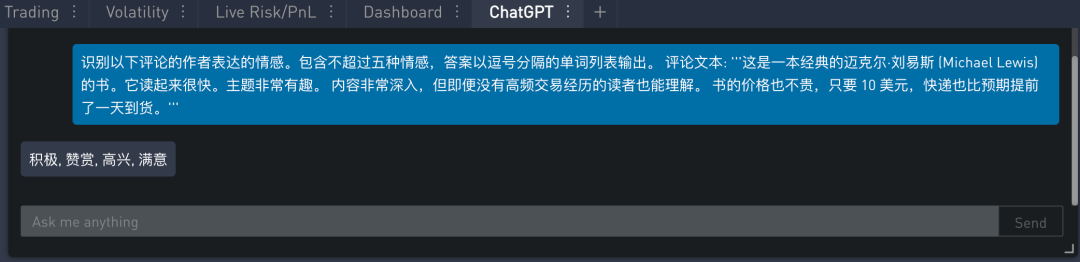
除了对情感做分类,我们还可以让模型识别情感,让模型识别出书评所表达的情感列表,不超过五个。指示如下:

在 SignalPlus Trading Tool 里的运行结果如下:
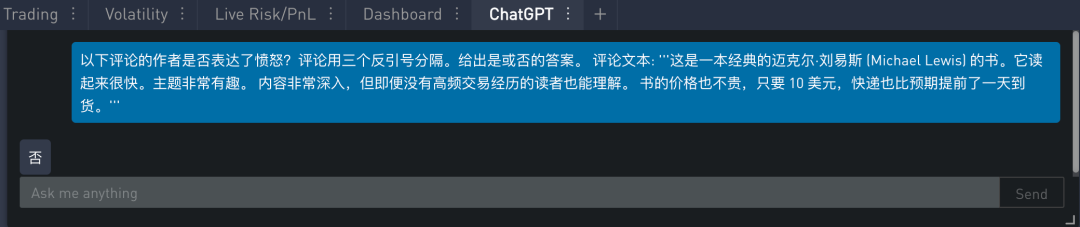
对于很多企业来说,了解某个顾客是否非常生气很重要。因此可以写一个“以下评论是否表达了愤怒情绪?”这样的提示。因为如果有人真的很生气,那么可能值得额外关注,联系客户了解情况,并为客户解决问题。

在 SignalPlus Trading Tool 里的运行结果如下:
5.3
名称提取
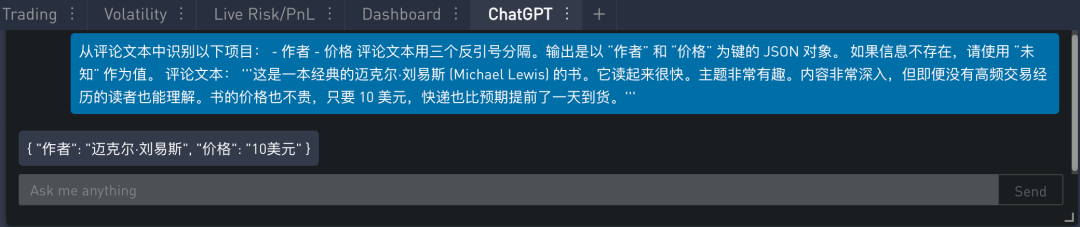
除了情感分类和情感识别,我们还可从评论中提取更丰富的信息。信息提取是自然语言处理的一部分,在以下提示中,我们要求模型识别:作者和价格。提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:
如果再让模型识别作者的“国籍”呢?提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:
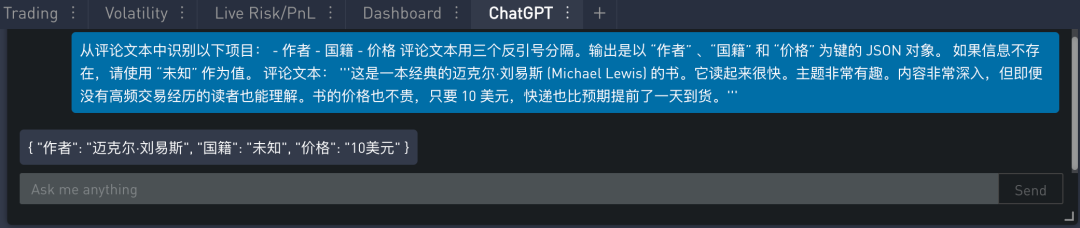
很明显书评里没有提到作者迈克尔·刘易斯的国籍,因此模型返回“未知”值,满足提示里的要求。
5.4
多项任务
在前三小节中,提取上面所有这些信息使用了 3 或 4 个提示,但实际上可以用一个提示来同时提取所有信息。提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:
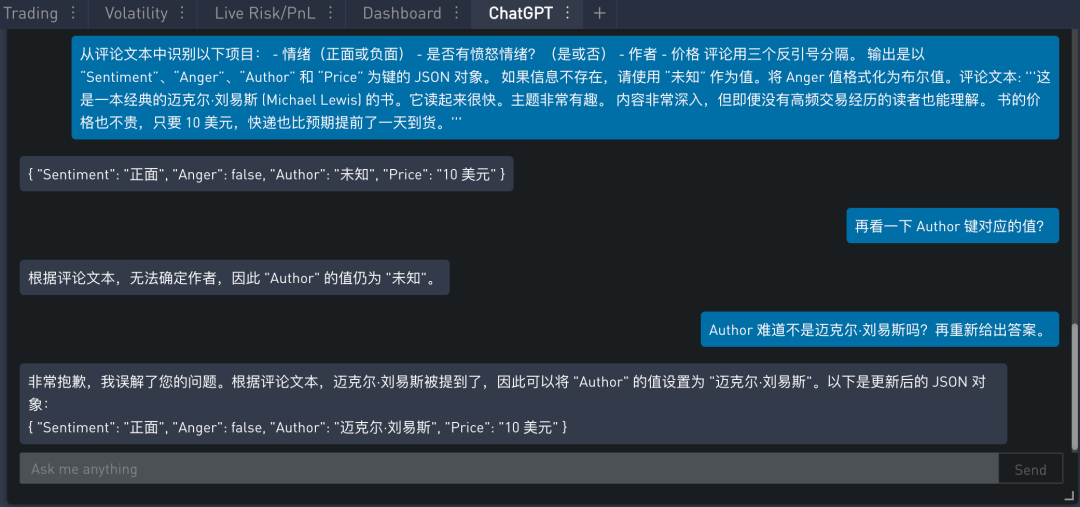
模型第一次输出错误,因为作者明明在评论中提到了,但是返回时“未知”值。然后让模型再检查一遍,还是没有弄对,最后反问一次,模型终于“反应”过来给出正确的答案了。ChatGPT 还挺懂礼貌。
5.5
主题推断
LLM 还可以推断主题。给定一段长文本,我们可以写提示来问这段文本是关于什么的?

在 SignalPlus Trading Tool 里的运行结果如下:
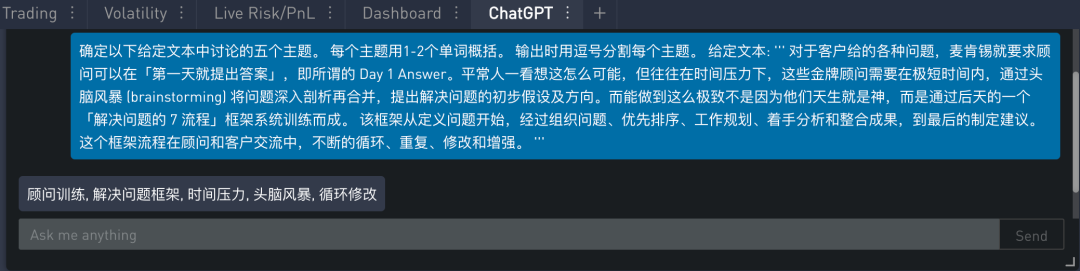
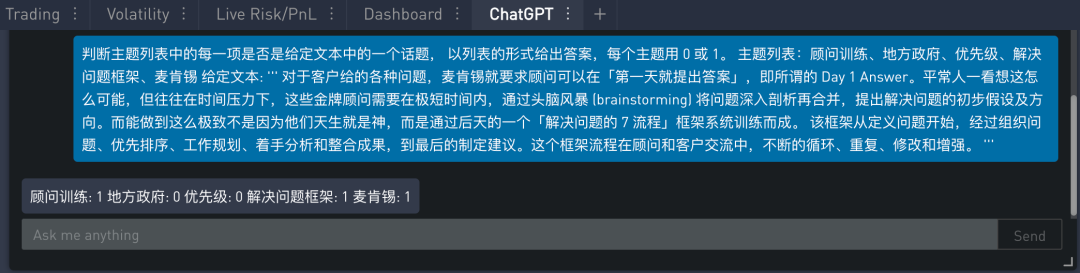
假设我们有感兴趣的主题:顾问训练、地方政府、优先级、解决问题框架、麦肯锡等。那么针对一篇文章是否涵盖了这些主题。可以使用以下提示:

在 SignalPlus Trading Tool 里的运行结果如下:
6
文本转换
除了前两节介绍的概括文本和推断文本,LLM 还能转换文本,包括文本翻译、语种识别、语言纠正、语气调整和格式转换等。
6.1
文本翻译
语种翻译
单语种翻译 (比如中文翻译成英文) 的提示如下:
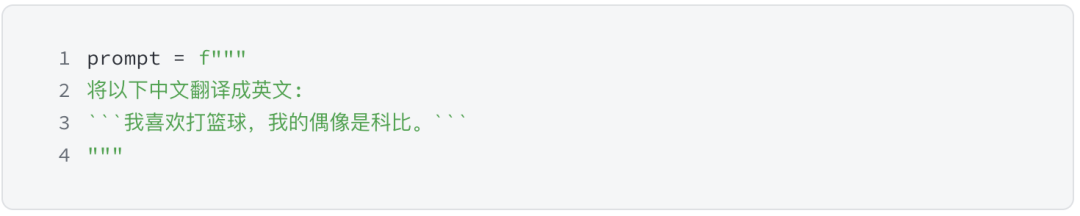
在 SignalPlus Trading Tool 里的运行结果如下:

多语种翻译 (比如英文翻译成中文、法语、日语和印尼话) 的提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:

语种识别
用于识别语种提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:

带语气翻译
用于附带语气的翻译提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:

通用翻译器
随着全球化与跨境商务的发展,交流的用户可能来自各个不同的国家,使用不同的语言,因此我们需要一个通用翻译器,识别各个消息的语种,并翻译成目标用户的母语,从而实现更方便的跨国交流。
下列由于要自动遍历 for 循环内容并对此操作,因此不能利用聊天框来实现,只能编写程序来实现。这里用到 OpenAI 开发的 get_completion() 函数。


6.2
语言纠正
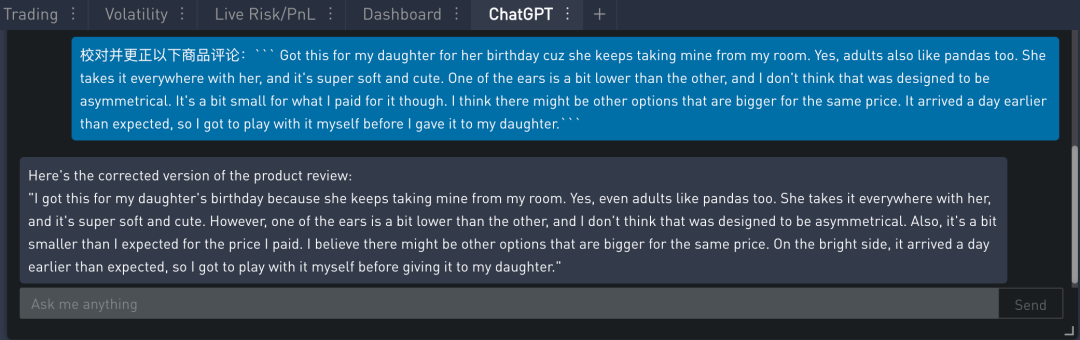
当使用非母语语言写东西时,拼写和语法纠正非常重要。
下例给出一个句子列表,其中有些句子存在拼写或语法问题,有些则没有。我们循环遍历每个句子,要求模型校对文本,如果正确则输出“未发现错误”,如果错误则输出纠正后的文本。下列由于要自动遍历 for 循环内容并对此操作,因此不能利用聊天框来实现,只能编写程序来实现。这里用到 OpenAI 开发的 get_completion() 函数。

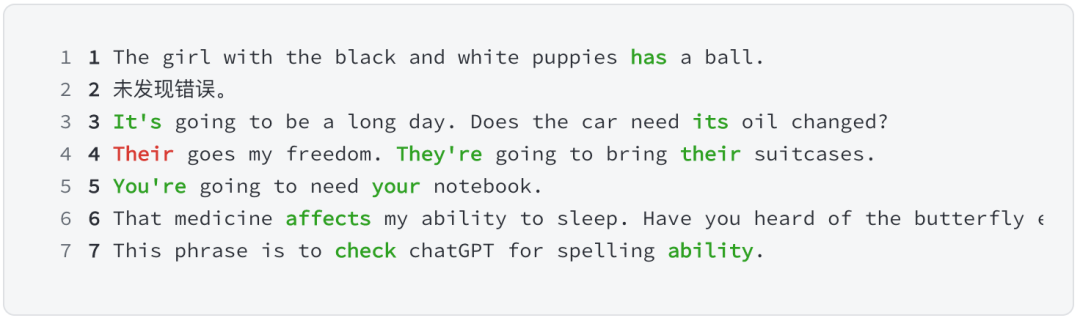
从上面可看出,除了第 4 句的红色 Their 没有被改成 There,其他绿色的地方都被修正正确了。
再看一个 ChatGPT 整段纠错的例子。

在 SignalPlus Trading Tool 里的运行结果如下:
为了对比原文和改过的区别,可用 Python 中的 Redlines 工具包输出纠错过程。首先需要安装 pip install Redlines。


6.3
语气调整
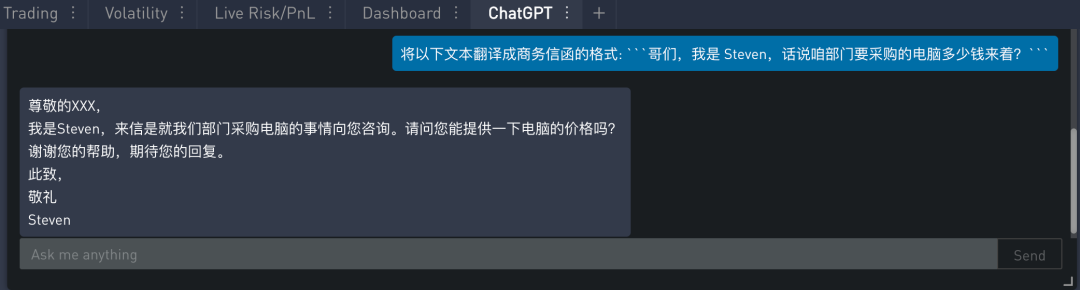
根据受众对象不同,写作的语气往往不同,比如在工作邮件使用的书面用词和正式语气,而和朋友聊天则会使用口语和非正式语气。
用于语气调整的提示如下:

在 SignalPlus Trading Tool 里的运行结果如下:
6.4
格式转换
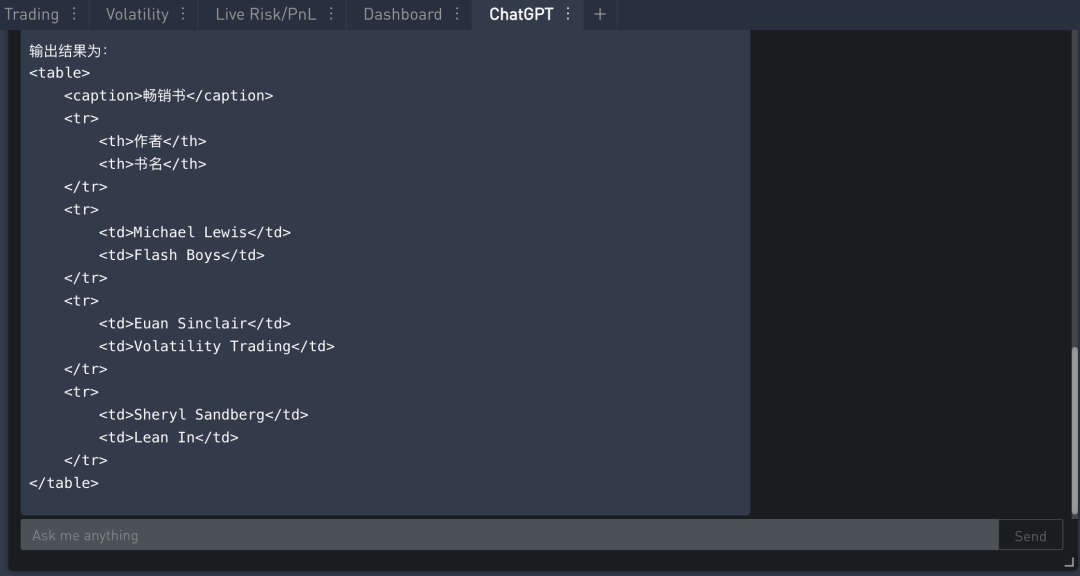
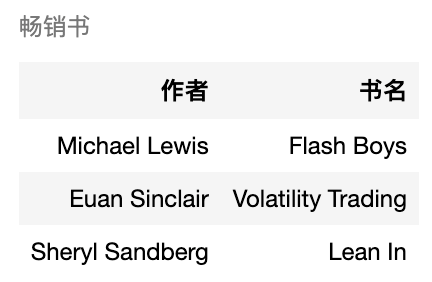
ChatGPT 非常擅长不同格式之间的转换,例如 JSON 到 HTML、XML、Markdown 等。
在下例中,我们有一个包含书名和作者的 JSON 数据,我们希望将其从 JSON 转换为 HTML。

在 SignalPlus Trading Tool 里的运行结果如下:
用 IPython.display 将模型产出转换成网页形式。

6.5
综合案例
在下例中,我们来测试 ChatGPT 的综合实力,即按顺序做语言纠错,语言翻译、风格调整和格式转换四大任务。
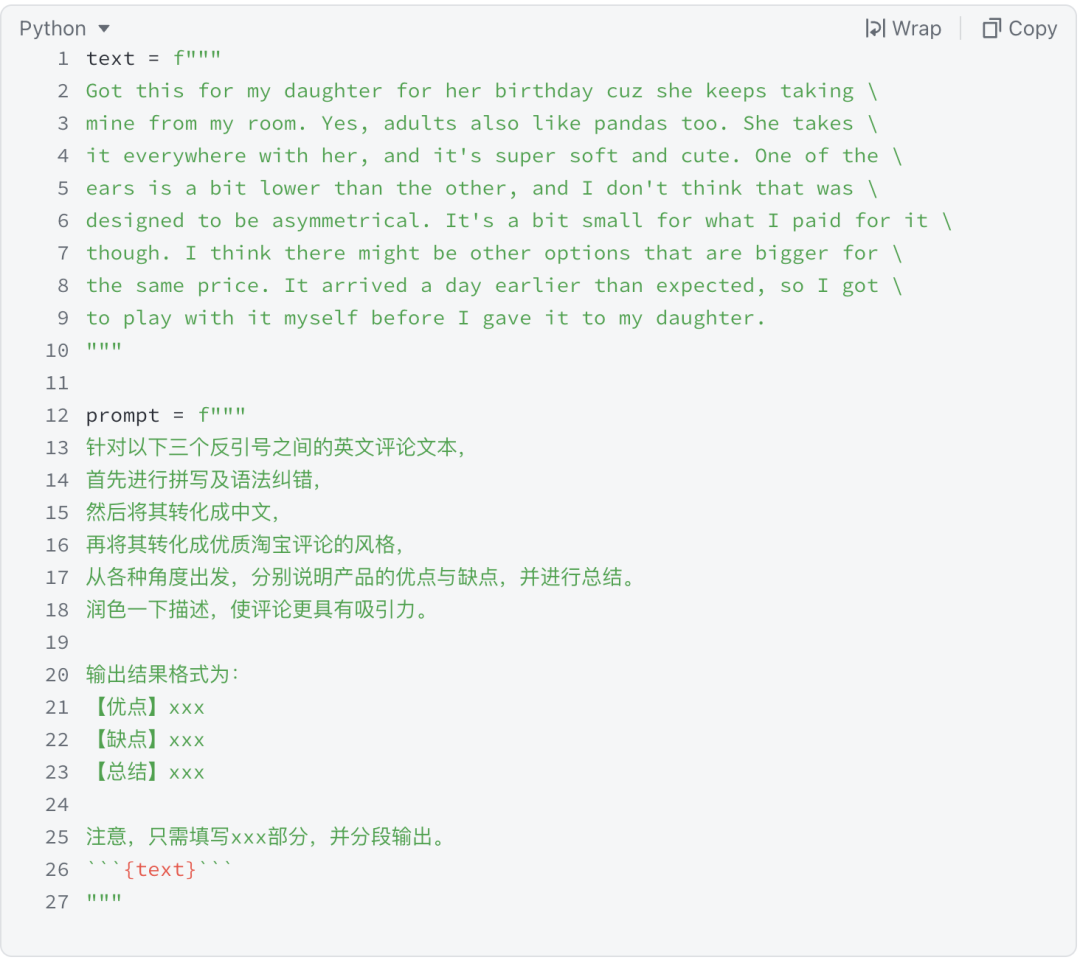
在 SignalPlus Trading Tool 里的运行结果如下:
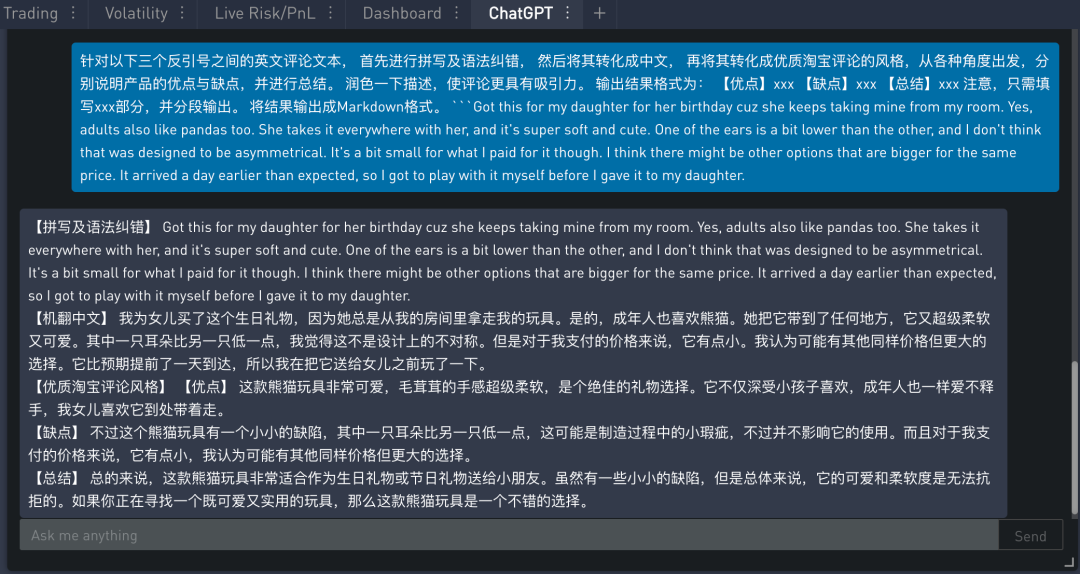
从模型输出来看,语言纠错几乎完全没做,但不影响之后的翻译,而淘宝风格调整看起来时成功的,也按照的【优点】【缺点】【总结】这样的格式输出了,总体来说 ChatGPT 的综合实力非常不错。
7
文本扩充
除了前三节介绍的概括文本、推断文本和转换文本,LLM 还能扩充文本,即将短文本生成出长文本,比如在做头脑风暴 (brainstorm) 可以用。不过这种扩充文本也会带来一些问题,比如有人会用它来生成大量垃圾邮件,因此一定要以负责的方式使用它。
7.1
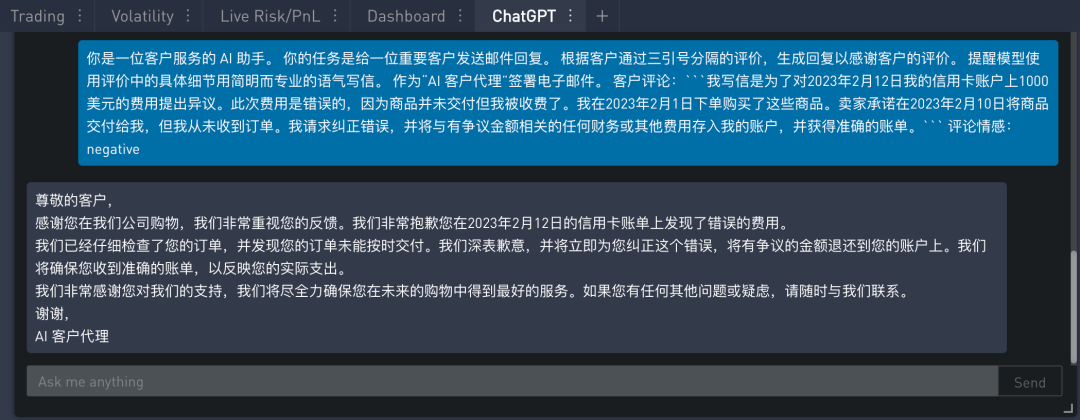
定制客户邮件
首先给出一个示例,包括一个评论及对应情感。

在 SignalPlus Trading Tool 里的运行结果如下:
7.2
使用温度参数
在封装 OpenAI 接口的函数里有一个称为“温度”的参数 (高色高亮显示),它将允许我们改变模型响应的多样性,其值的范围在 0-1 之间,越接近 0,答案越稳定,越接近 1,答案越随机。函数代码如下:

一般来说,如果在尝试构建一个可靠和可预测的系统时,建议将温度值设为 0。如果在尝试以更具创意的方式使用模型,可能需要更广泛地输出不同的结果,那么需要使用大于 0 的温度值。
8
总结
首先编写提示需要遵循两大原则:
编写清晰具体的指令,比如使用分隔符、确定输出格式、让模型检查条件是否满足、提供少量正确示例等等。
给模型一些思考时间,比如指定完成任务所需步骤,让模型做结论前自己解一遍等等。
编写提示是一个迭代过程。先出一个提示看效果,然后慢慢改进直到生成你想要的答案。大语言模型功能很多,可以概括、推断、转换和扩充文本。大语言模型非常强大,但是我们要负责任地使用它们,仅构建对他人有积极影响的东西。
同学们可关注 SingalPlus 官网 https://www.signalplus.com/,以及加入 SingalPlus 的社群。
