【图像分割】视觉大模型SEEM(Segment Everything Everywhere All at Once)原理解读
文章目录
- 摘要(效果)
- 二、前言
- 三、相关工作
- 四、method
- 4.1 多用途
- 4.2 组合性
- 4.3 交互式。
- 4.4 语义感知
- 五、实验
论文地址:https://arxiv.org/abs/2304.06718
测试代码:https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
来自:威斯康辛麦迪逊、微软、港科大等
摘要(效果)
随着交互式人工智能系统的需求增长,视觉方面的人-AI交互的综合研究也受到基于提示的LLM通用接口开发的启发,本文提出了SEEM,一个快速的、交互式的模型,用于在图像中一次性分割一切。
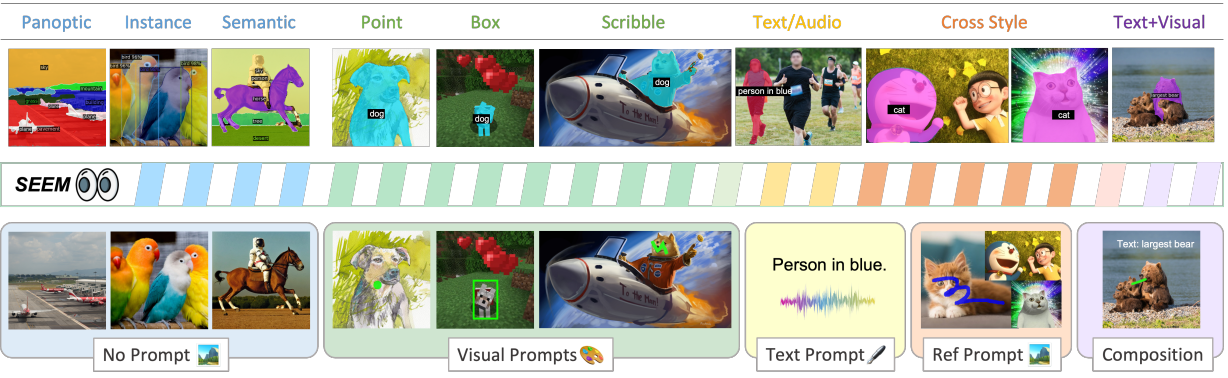
1.文本提示。通过用户输入的文本生成掩模,进行一键分割(SEEM可以适应卡通、电影和游戏领域中的各种类型的输入图像)。

2.图像提示。给一个擎天柱卡车的图,就能分割任何目标图像上的擎天柱

3.点击与涂鸦提示。SEEM通过对引用图像的简单点击,或涂鸦,就能够对目标图像上有相似语义的对象进行分割。
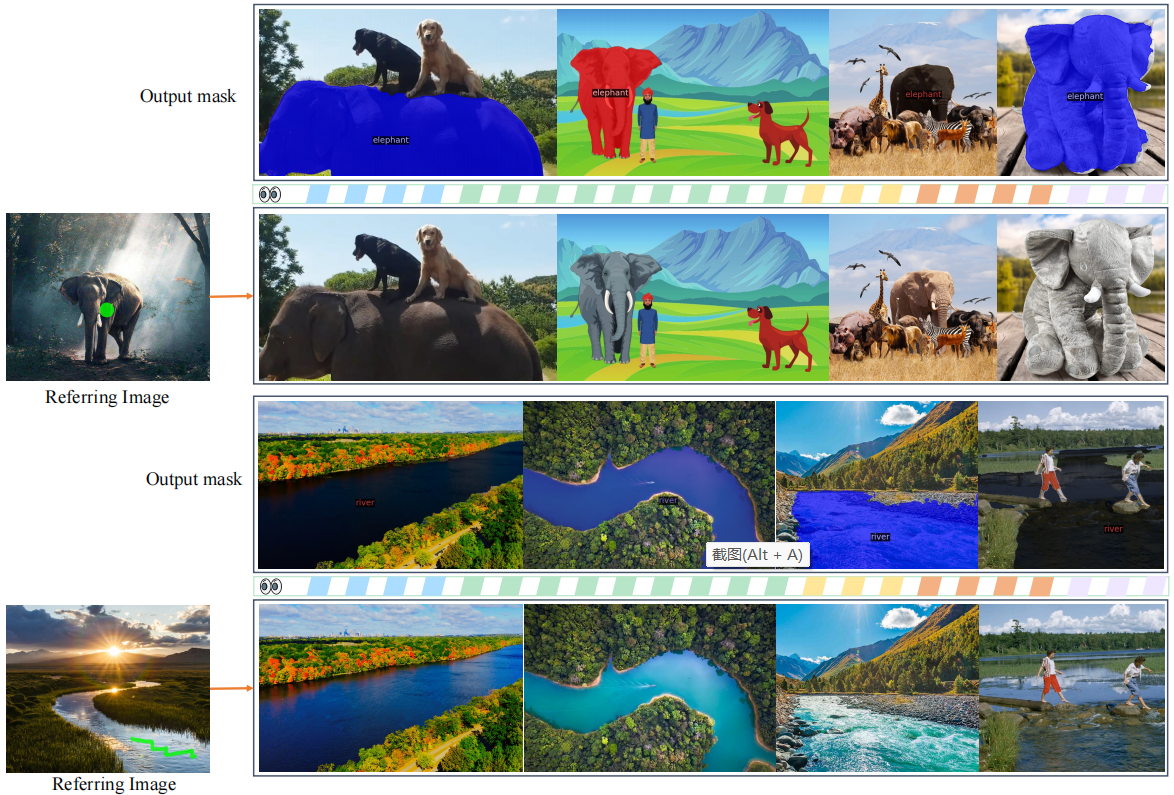
4.此外,SEEM非常了解空间关系。左上行斑马被涂鸦后,也会分割出最左边的斑马。

5.视频分割:


SEEM有四个需求:
1)通过引入 不同类型的通用提示引擎 ,包括点、框、涂鸦、掩码、文本和另一幅图像的参考区域;
2)通过 学习联合视觉-语义空间 进行视觉和文本提示,动态查询进行推理,如上图所示;
3)通过合并可学习的记忆提示,通过掩码引导的交叉注意保留对话历史信息;
4)使用文本编码器编码文本查询,并掩码标签进行开放词汇表分割。
当SEEM学会了在一个统一的表示空间中编写不同类型的提示时,它显示出了概括到看不见的用户意图的强大能力。SEEM可以有效地使用一个轻量级的提示解码器处理多轮交互。
二、前言
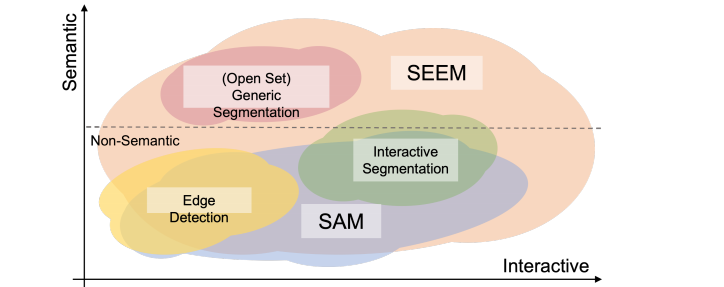
像ChatGPT 这样的大型语言模型(LLM)的成功显示了现代人工智能模型在与人类互动中的重要性。与人类互动的能力需要一个用户友好的界面,它可以接受尽可能多的人类输入,并产生人类很容易理解的反应。在NLP中,这种通用的交互界面已经出现并发展了一段时间,从早期的模型,如GPT和T5(Exploring the limits of transfer learning with a unified text-to-text transformer),到一些更先进的技术,如 prompt 和chain of thought。SAM支持多个提示。但是,下图所示的SAM只支持有限的交互类型,如点和盒子,并且不支持高级语义任务,因为它不输出语义标签(图中,SEEM在两种交互方法,如示例图像的参考区域和语义空间上都有更丰富的上下文)。
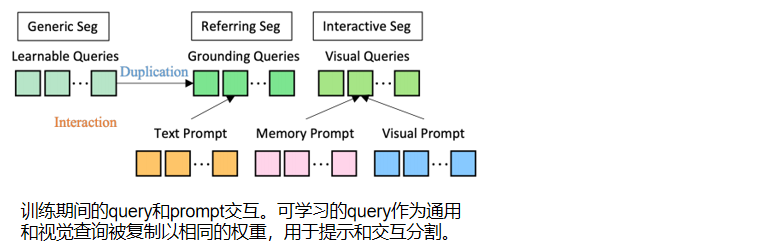
文章提倡一个通用的界面,用多模态提示来分割 everything!通用性:SEEM模型可以处理输入提示的任何组合(点、掩码、文本、方框,甚至另一个图像的参考区域,在相同的联合视觉-语义空间中形成提示),从而导致强大的组合性。交互性,我们进一步引入了内存提示来压缩之前的分割信息,然后与其他提示进行通信。对于语义感知,我们的模型为任何输出分割提供了一个开放集的语义。将所有5种不同类型的提示映射到联合视觉-语义空间,通过zero-shot 适应实现看不见的用户提示。通过对不同分割任务的训练,模型能够处理各种提示。
除了较强的泛化能力外,SEEM运行也很快。我们将提示作为解码器的输入。因此,当与人类进行多轮交互时,模型只需要在一开始就运行一次特征提取器。在每次迭代中,我们只需要使用新的提示再次运行轻量级解码器。在部署模型时,通常在服务器上运行繁重的特性提取器,并在用户的机器上运行相对轻量级的解码器,以减少多个远程调用中的网络延迟。
1.设计了一个统一的提示方案,可以将各种用户意图编码到一个联合的视觉-语义空间中,该空间具有通用性、组合性、交互性和语义意识等特性,导致对分割提示的 zero-shot 能力
2.将新设计的提示机制集成到一个用于所有分割任务的轻量级解码器中,构建了一个通用的交互式分割界面SEEM。
3.在许多分割任务上实验和可视化,包括闭集和开放集的全光分割、交互分割、参考分割和组合提示分割任务,证明了性能。
三、相关工作
闭集分割
通用分割技术包括几个子任务,包括实例分割、语义分割和全光分割,每个子任务都集中于不同的语义级别。例如,语义分割的目标是根据图像中对应的语义类来识别和标记图像中的每个像素。另一方面,实例分割涉及到将属于同一语义类的像素分组到单独的对象实例中。近年来,基于Transformer结构的(DETR)模型在分割任务方面取得了重大进展。然而,这些方法不能识别训练集中缺少的对象,这将模型限制在有限的词汇量大小内。
开放集分割
参考分割模型的目标是语言描述分割,这本质上是开放词汇表。然而,由于参考分割数据有限,训练后的模型往往在目标数据集上表现良好,但很难推断到实际应用中。最近,一些模型提出了许多开放词汇分割模型,它使用大型的预先训练的视觉语言模型,如CLIP,通过冻结或调整它们的权重来转移视觉语义知识。最近,X-Decoder提出了一种单一化的方法来处理各种分割和开放词汇分割的视觉语言任务。为了扩大词汇量的规模,OpenSeeD提出使用大量的检测数据和一种联合训练方法来改进分割。ODISE 利用了一个文本到图像的扩散模型作为开放词汇表分割的主干。
交互式分割
交互式分割是通过交互式地获取用户输入来分割对象。通常,交互类型可以采取各种形式,如点击、方框、多边形和涂鸦,其中基于点击的交互模型是最普遍的。SAM提出了一个在1100万张图像上训练的快速分割模型,显示了很强的zero shot 性能。它将用户交互作为一般分割的提示。但是SAM产生没有语义意义的分割。且提示的类型仅限于点、方框和文本。
四、method
SEEM采用了一种通用的编-解码器架构,在查询和提示之间具有复杂的交互,如下图(a),所示给定一个输入图像 I∈RH×W×3,一个图像编码器首先用于提取图像特征z,SEEM解码器基于查询输出的Omh(mask嵌入)和Och(类嵌入)与视觉、文本和内存提示 Pt,Pv,Pm的交互,从而预测掩码M和语义C。
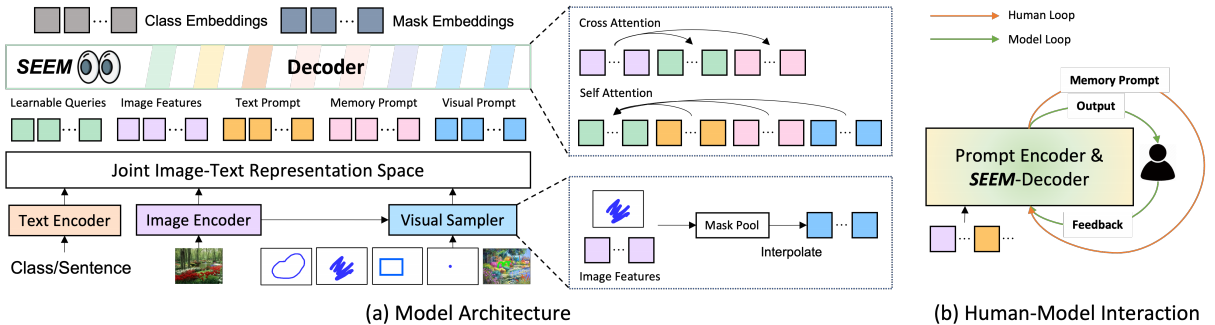
(a)左边是对该模型的概述。首先,特征 和 提示 由其相应的编码器或采样器编码到一个联合的视觉-语义空间。而可学习的查询则是随机初始化的。SEEM解码器将查询、特征和提示作为输入和输出,并将类和掩码嵌入用于掩码和语义预测。右边部分是SEEM解码器和视觉采样器的细节。(b)显示了多轮的交互作用。每一轮都包含一个人的循环和一个模型循环。在人循环中,人接收最后一次迭代的掩模输出,并通过视觉提示对下一轮解码的正或负反馈。在模型循环中,模型接收并更新内存提示,以便进行未来的预测。

4.1 多用途
在SEEM中,我们引入了视觉提示Pv来处理所有非文本输入,如点、框、涂鸦和另一个图像的参考区域。当文本提示无法识别正确的数据段时,这些非文本查询有助于消除用户意图的歧义。对于交互式分割,以前的工作要么将空间查询转换为掩码,并将它们输入图像主干,要么为每种输入类型(点、框)使用不同的提示编码器。第一种方法在应用中过于heavy,每个交互都要求图像通过特征提取器。第二种方法很难推广到不可见的提示中。为了解决这些限制,SEEM提出了一个视觉采样器(图3 (a)),将各种非文本查询转换为位于同一视觉嵌入空间中的视觉提示:
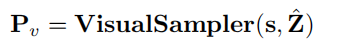
其中,
Z
^
\hat{Z}
Z^是从目标图像(即
Z
^
\hat{Z}
Z^=Z)或参考图像中提取的特征图,而s(方框、涂鸦、多边形)是用户指定的采样位置。我们首先通过点采样从图像特征中汇集相应的区域。 对于所有的视觉提示,最多从提示指定的区域均匀插值512个点特征向量。方法的另一个优点是,视觉提示自然与文本提示很好地对齐,模型通过全景分割和参考分割不断地学习一个共同的视觉-语义空间。
全景分割 Panoptic Segmentation :要求图像中的每个像素点都必须被分配给一个语义标签和一个实例id
参考分割 referring segmentation: 跨模态分割,给定一个语句描述,分割出图像对应的物体区域
4.2 组合性
在实践中,用户需要使用不同的或组合的输入类型来实现意图。常见模型训练中有两个问题。首先,训练数据通常只涵盖单一类型的交互(例如:空白、文本、视觉)。其次,使用视觉提示来统一所有非文本提示,并将它们与文本提示对齐,但其嵌入空间在本质上仍然不同。为了解决这个问题,我们建议用不同的输出来匹配不同类型的提示。考虑到视觉提示来自图像特征,而文本提示来自文本编码器,我们分别将视觉提示和文本提示与掩码嵌入Om h或类嵌入Oc h进行匹配,从而选择匹配的输出索引。
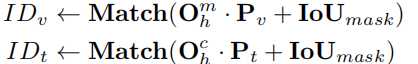
其中IoUmask是真实掩码和预测掩码之间的交并比。所提出的分离匹配方法优于在所有提示中只与Om h或Oc h匹配的方法。
经过训练,我们的模型熟悉所有提示类型,并支持多种组合方式,如没有提示,一种提示类型,或使用相同的模型和权重的视觉和文本提示。特别是,视觉提示和文本提示可以简单地连接并输入到SEEM解码器中,即使它从未接受过这样的训练。
4.3 交互式。
交互式分割通常不能在一次完成,需要多次交互进行细化,类似于ChatGPT这样的会话代理。SEEM提出了一种新的提示类型Pm,并使用它们将上一次迭代中的mask 知识传递给当前iter。此处没有引入额外的模块,只引入了一些内存提示,负责通过使用mask引导的交叉注意层来编码历史信息:
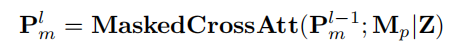
其中,Mp是上一个掩模,Z是图像特征图。因此,交叉注意只在前一个掩码指定的区域内生效。更新后的记忆提示Plm通过自注意力与其他提示进行交互,以传达当前一轮的历史信息。这种设计可以很容易地扩展到支持多个对象的同时分割。
4.4 语义感知
SEEM 以zero shot 的方式为各种提示组合的 mask 提供语义标签。因为视觉提示特征是在一个联合的视觉-语义空间中与文本特征对齐的。如下图所示,语义标签将通过Och(视觉查询的输出)和词汇表的文本嵌入直接计算。虽然我们没有训练任何针对交互式分割的语义标签,但计算出的对数对齐得很好,受益于联合的视觉-语义空间。
五、实验
数据集和设置 SEEM采用三种数据类型进行训练:全视分割、参考分割和交互分割。采用COCO2017 训练全景和交互分割,总共得到了10个7K的分割图像。对于参考分割,我们使用Ref-COCO、Ref-COCOg和RefCOCO+的组合来进行COCO图像注释。评估了所有的分割任务,包括通用分割(实例/全景/语义)、参考分割和交互式分割。
实施细节和评估指标。SEEM框架遵循X-Decoder框架,除了解码器部分(视觉骨干、语言骨干、编码器和seem解码器组成)。对于视觉骨干,我们使用FocalT [54]和DaViT-d3 (B) [9]。对于语言编码器,我们采用了一个UniCL或佛罗伦萨文本编码器[55,59]。分割任务的评估指标为PQ(全光学质量)用于全光分割,AP用于实例分割,mIoU的语义分割。对于交互式分割,通过自动将预测的分割与GT的分割进行比较,来模拟用户的点击。在一次点击图像生成预测的掩模后,下一次点击将被放置在分割误差最大的区域的中心。使用点击次数(NoC)度量来评估交互式分割性能,它度量实现某一IoU所需的点击次数,即85%和90%,分别表示为NoC@85和NoC@90。
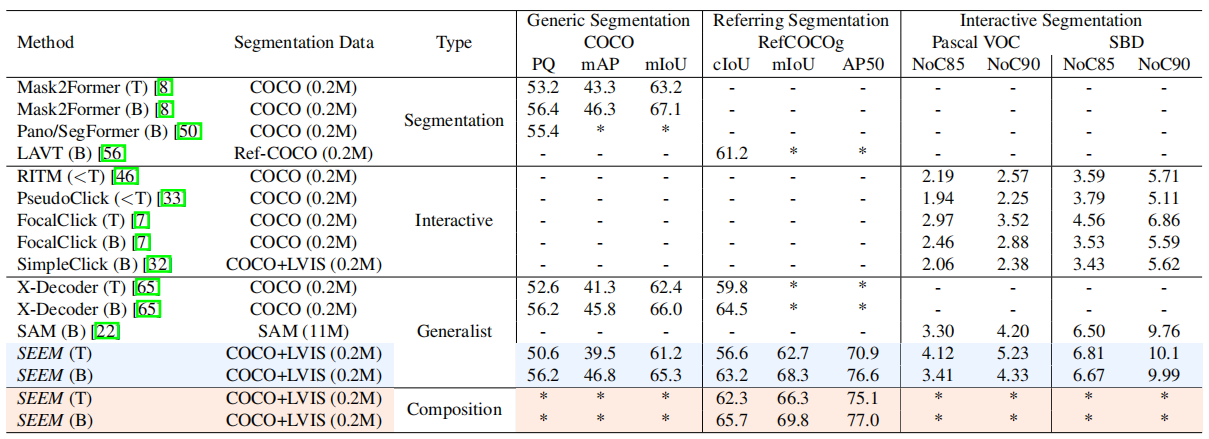
- 交互式分割
表1将SEEM与最先进的交互式分割模型进行了比较,获得了与RITM、SimpleClick等相当的性能,与使用比SEEM多×50个分割数据的SAM 相比非常相似。
-
一般分割
在所有分割任务上预先训练一套参数,我们直接评估其在一般分割数据集上的性能。 -
参照Referring 分割
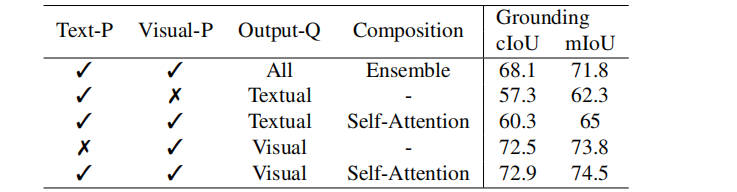
如下表所示,通过添加视觉组合提示,在微型模型的cIoU、mIoU和AP50指标下,参考分割性能得到了提高,分别为5.7、3.6和4.2点。该间隙在基础模型上进行了再训练,分别提高了2.5、1.5和0、4点。具体来说,这个数字是由类嵌入Och(outtut-q-文本)计算的。而当使用掩码嵌入Omh(Output-Q-Visual)计算边界时,边界甚至更大,如下表。此外,我们对一般组合(直接结合视觉和文本掩码的输出概率)进行基准测试。
4. 消融实验
当添加迭代和负视觉提示时,通用分割的性能略有下降。此外,如果我们从头开始训练模型,通用分割的性能下降更多。正如预期的那样,当从零开始训练时,参考分割性能下降。然而,当添加负面的视觉提示时,它会进一步减少。另一方面,在交互分割任务中添加迭代次数可以略微提高接地性能。通过添加迭代和负视觉提示,交互式分割性能逐渐提高,而从头开始训练令人惊讶地使Pascal VOC数据集的性能略有提高。
下表中,“Iter”表示多轮迭代分割。“negtive”表示在交互式分割过程中添加负点。

5. 定性结果
见摘要。