【剧前爆米花--爪哇岛寻宝】java--线程不安全的原因及解决方法
作者:困了电视剧
专栏:《JavaEE初阶》
文章分布:这是关于线程安全相关的文章,在该文章中,我梳理了造成线程不安全的原因和使线程变安全的方法,希望对你有所帮助!

目录
线程的安全问题
什么是线程安全
线程不安全的原因
修改共享数据
原子性
可见性
代码顺序性
线程安全问题的解决
synchronized关键字
互斥
可重入
volatile关键字
线程的安全问题
我们在单线程的情况下,一般不会遇到线程的安全问题,但当我们进行多线程的编程时,多线程之间的并发并行机制,以及线程之间对CPU资源的抢占都会可能导致我们得到一些意料之外的结果。
什么是线程安全
想给出一个线程安全的确切定义是复杂的,但我们可以这样认为:如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线 程安全的。
线程不安全的原因
修改共享数据
这一点可以分为三个小类:
1.抢占式执行(根本原因)
2.多个线程修改同一个变量
1)一个线程修改一个变量安全
2)多个线程读取同一个变量安全
3)多个线程修改不同的变量安全
3.修改操作不是原子的
举个栗子:
class Counter{
public int count = 0;
public void add(){
count++;
}
}
public class ThreadDemo2 {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Thread t1 = new Thread( ()->{
for ( int i=0;i<10000;i++ ){
counter.add();
}
});
Thread t2 = new Thread( ()->{
for ( int i=0;i<10000;i++ ){
counter.add();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}现在有这样的一段代码,我想要实现的功能就是设置两个线程,让每一个线程都做累加count一万次的功能,按照我们的逻辑来思考,最后主线程在两个线程执行完后输出的count值应该是两万,这是我们在单线程中的思维。但结果确实如此吗?

我们可以看到结果并不是两万,而是一个我们意料之外的数字,并且随着我们每次运行,这个结果都不同,这是为什么?
这就需要从计算机的底层来进行剖析了,我们在代码中执行“count++”这一句代码时,反应到计算机内部大致就是:
计算机先通过load指令将count的值从内存中取出来存到寄存器当中,然后再通过运算逻辑部件对寄存器中的count进行加一操作,完成后,再将寄存器中的值放回到内存中保存

在分析上大概是这种,我们的理想情况是t1线程执行完后,再执行t2线程,然后t2线程完整的执行完后在执行t1线程,但是在真实的计算机内部并不是这样的,由于线程的并发执行,这就导致一个count++代码可能并没有执行完就切换到另一个线程去了,这就导致了很多种不确定的情况,比如这种:
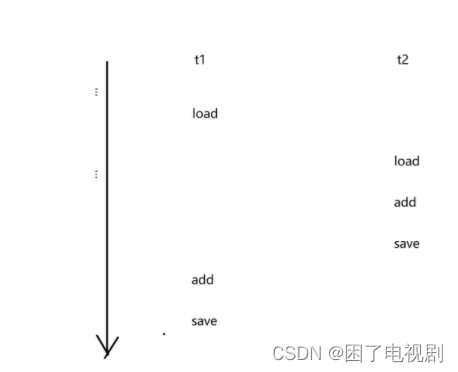
当出现这种情况的时候就会发现,虽然我们的count++执行了两次,但最后保存到内存中时,只会保存执行一次的结果,还有很多种其他的情况,这些情况有的会影响结果有的不会,在这种混乱的状况下,我们根本无法得到一个准确的值,更别说我们想要的值了。
原子性
这个原子性和之前的事物的原子性类似,都是表示一种不能分的概念。
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证, A 进入房间之后,还没有出来;B 是不是也可以进入房间,打断 A 在房间里的隐私。这个就是不具备原子性的。那我们应该如何解决这个问题呢?是不是只要给房间加一把锁, A 进去就把门锁上,其他人是不是就进不来了。这样就保证了这段代码的原子性了。
和上述举得count的例子一样,我们要想解决这类问题必须要让我们进行的操作具备一种原子性,即不执行完不能进行其他的操作。
可见性
可见性指 , 一个线程对共享变量值的修改,能够及时地被其他线程看到 .
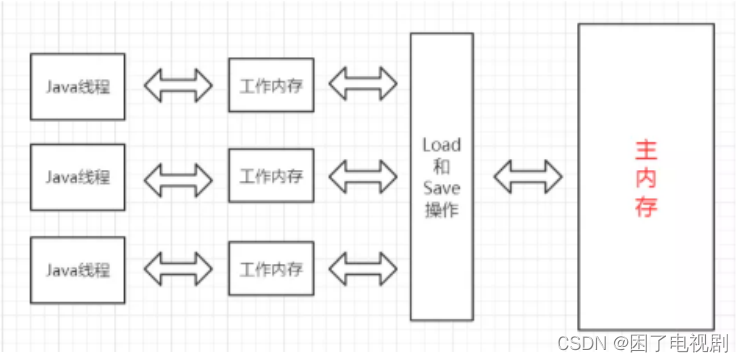
线程之间的共享变量存在 主内存 (Main Memory).每一个线程都有自己的 " 工作内存 " (Working Memory) .当线程要读取一个共享变量的时候 , 会先把变量从主内存拷贝到工作内存 , 再从工作内存读取数据 .当线程要修改一个共享变量的时候 , 也会先修改工作内存中的副本 , 再同步回主内存 .
这里的主内存就是硬件角度的内存,而这里的工作内存就是寄存器,这里的代码不安全具体体现在,主内存对数据的修改无法及时的更新,举个栗子:
线程1需要对a进行修改,线程2也需要a这个数据,假设a的大小是10,然后进行修改后变成了20,由于工作内存的速度远远大于主内存的读写速度,所以此时修改后的20并不会及时地传入主内存中,于是在这期间线程2取得值还是10,这就造成了错误,也就是线程不安全。
代码顺序性
代码的顺序性比较复杂,这里通过一个栗子来进行解释:
比如说我现在需要干三件事。1.去前台拿钥匙。2.完成一个试卷。3.去前台拿一盒粉笔。
如果 我们是单线程,那么计算机会自动的帮我们进行优化,即不按123的顺序执行而是按132的顺序执行,这样我们就会节约一次去前台的时间,而如果我们是多线程,当我们不按顺序执行,未执行2而执行了3这样就可能会造成一些问题,比如在完成两个任务的时间后其他线程需要进行批改试卷,而此时这个线程的试卷还没开始写...
这就造成了线程安全的问题。
线程安全问题的解决
synchronized关键字
互斥
synchronized 会起到互斥效果 , 某个线程执行到某个对象的 synchronized 中时 , 其他线程如果也执行到同一个对象 synchronized 就会 阻塞等待 .进入 synchronized 修饰的代码块 , 相当于 加锁退出 synchronized 修饰的代码块 , 相当于 解锁
理解 " 阻塞等待 ".针对每一把锁 , 操作系统内部都维护了一个等待队列 . 当这个锁被某个线程占有的时候 , 其他线程尝试进行加锁, 就加不上了 , 就会阻塞等待 , 一直等到之前的线程解锁之后 , 由操作系统唤醒一个新的线程, 再来获取到这个锁。
换个角度思考,加上锁的代码块就是让这个代码块具有原子性,即对于这个代码块来说,必须要等当前线程执行完代码段内的操作其他线程才能执行,对于这个代码块中的内容cpu只能串行执行。
这时候可能有人会问了,这和join有什么区别?
这是个好问题,首先最重要的一点是,初心不一样:synchronized通过给代码段上锁,赋予一段操作原子性,然后当这段代码执行结束时,其他被synchronized修饰的代码段再通过锁竞争进行执行,其本质是为了保证线程安全,而join则是完全等待另一个线程执行完,可能是另一个线程有当前线程需要的内容等等,总之不是为了线程安全考虑。
其次对于线程的并发而言,synchronized只是将那一段代码块进行上锁,即串行,其他需要执行的依然会并发执行,而join则是让整个线程进行等待,效率比上锁更慢。
可重入
volatile关键字
volatile 修饰的变量 , 能够保证 " 内存可见性 "。代码在写入 volatile 修饰的变量的时候 ,->改变线程工作内存中 volatile 变量副本的值->将改变后的副本的值从工作内存刷新到主内存代码在读取 volatile 修饰的变量的时候 ,->从主内存中读取 volatile 变量的最新值到线程的工作内存中->从工作内存中读取 volatile变量的副本
归根结底,volatile关键字修饰的变量就是,让其每次读写都强制访问主内存,而不仅仅是工作内存,这样虽然降低了运行的效率,但是却也避免了代码可见性相关的问题,是线程安全。
举个栗子:
public class ThreadDemo2 {
public static int flag = 0;
public static void main(String[] args) {
Thread t1 = new Thread( ()->{
while (flag == 0){
//空循环
}
System.out.println("结束");
});
Thread t2 = new Thread( ()->{
Scanner reader = new Scanner(System.in);
System.out.println("输入flag");
flag = reader.nextInt();
});
t1.start();
t2.start();
}
}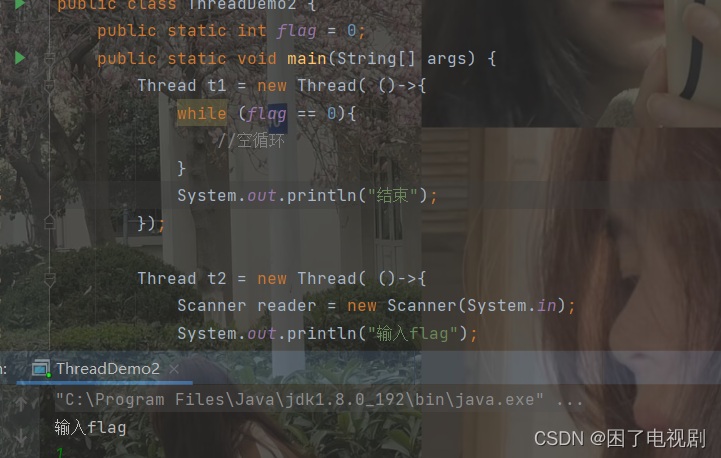
对于这段代码会发现,当我输入0时,t1线程并没有结束,这是为什么?
原因是,由于在t1的循环中我的是空循环,所以while()中的判断语句的执行时间远远大于循环体的执行时间,计算机为了提高效率就会进行优化,他不在每次都从主内存中读取flag而是直接读取工作内存中flag的副本以此来加快速度,所以只要我们加上volatile修饰就好。
以上就是本篇博客的全部内容,如有疏漏还请指正!