这一次,吃了Redis的亏,也败给了GPT
关注【离心计划】,一起离开地球表面


背景
组内有一个系统中有一个延迟任务的需求,关于延迟任务常见的做法有时间轮、延迟MQ还有Redis Zset等方案,关于时间轮,这边小苏有一个大学时候做的demo:
https://github.com/JAYqq/GoDelayTasks
该系统采用的是zset的方案,在系统稳定运行了三年多后,这周出现了一个大面积故障,背后的原因居然是zscan的问题,我们今天就简单复盘一下这次的故障,好好盘一盘zset。

zset实现延时任务队列
关于zset的底层数据结构和基本操作,在之前的文章就已经阐述过了,简单来说就是底层由ziplist组织,超过一定阈值(默认128)就改为由skiplist:
【专栏】基础篇03| Redis 花样的数据结构
最常见的延迟任务就是下单,某宝中我们下单未支付后,会倒计时一段时间,到点后订单自动释放;还有完成订单后,超过一定时间就会自动签收。这些都是延迟任务,在zset中,我们将业务类型作为key、订单ID作为member、下单时间+延迟时间作为score,这样的一个zset结构,我们配合zrangeByScore(0,currentTime),就能获取到当前时间应该过期的任务了,简单操作如下:
127.0.0.1:6379> zadd order 100 111
(integer) 1
127.0.0.1:6379> zadd order 120 112
(integer) 1
127.0.0.1:6379> zadd order 140 113
(integer) 1
127.0.0.1:6379> zadd order 170 114
(integer) 1
127.0.0.1:6379> zrangebyscore order 0 130
1) "111"
2) "112"zrangeByScore在异步线程定时执行就行了,这是延时任务的主动释放。而在组内应用的系统中,还有一个监听消息的机制,当接收到消息后需要取出sessionId,将zset中对应的session元素删除,这边就需要扫描zset所有元素,便用到了zscan命令。
zscan
zscan是一个增量命令,它在官网的定义如下:

所谓增量就是不会一次全部,而是返回一定数量的元素,也就是上面指定的count,然后返回cursor表示扫描到的位置,只要这个cursor不为0就表示扫描没有结束,这就是增量命令最重要的表现形式。
然而,这是我们对增量的理解,但是zset狗在对于元素数量比较少的时候,也就是底层以ziplist组织的时候,会忽视count,一次返回所有元素;而当以skiplist组织的时候,才会返回count个,如果没有传count,默认10个。这也是此次组内系统故障的根因,同事在用zscan的时候并没有传count,但是元素数量超过了128个,导致只扫描了10个后就停止了,代码也没有继续从返回的cursor扫描,导致了zset中存在大量的元素未被删除,被延迟任务队列监控线程通过zrangeByScore扫描到,错误地认为这些元素超时而返回了错误的系统信息。
从源码上看,也可以看出一些端倪


这边看确实默认值是10,但是直到我看到:

当是skiplist的时候,count会默认变成两倍,但是在我的电脑上并没有这个现象,可能是版本差异,但是我找了之前的release描述,没有找到相关的信息,这个问题因为我太饿了就查不下去了(其实是懒

),有读者知道的可以后台私信,感谢~
zset-max-ziplist-entries 3127.0.0.1:6379> object encoding order
"ziplist"
127.0.0.1:6379> zscan order 0 match "order*" count 5
1) "0"
2) 1) "order-111"
2) "100"
3) "order-112"
4) "110"
5) "order-113"
6) "120"
7) "order-114"
8) "130"
9) "order-115"
10) "140"
11) "order-116"
12) "150"
13) "order-118"
14) "170"
15) "order-119"
16) "180"
17) "order-120"
18) "190"
19) "order-121"
20) "200"
21) "order-122"
22) "210"
23) "order-123"
24) "220"127.0.0.1:6379> zadd order 230 order-124
(integer) 1
127.0.0.1:6379> object encoding order
"skiplist"127.0.0.1:6379> zscan order 0
1) "5"
2) 1) "order-123"
2) "220"
3) "order-116"
4) "150"
5) "order-118"
6) "170"
7) "order-124"
8) "230"
9) "order-121"
10) "200"
11) "order-114"
12) "130"
13) "order-120"
14) "190"
15) "order-115"
16) "140"
17) "order-111"
18) "100"
19) "order-122"
20) "210"发现确实只返回了10个,并且cursor是5,表示并没有结束,至此我们复现了系统的问题,现象也是一致的。
解决方案
方案一:传一个很大的count
方案二:zrange扫描全部,代码内做筛选
方案三:循环zscan,直到cursor为0
业务方案:zrangeByScore扫描到后继续保底
复盘
故障从监控预警到定位问题时间较长,原因在于开发人员并没有直接定位到zscan的问题,并且这部分命令是作为lua脚本执行,调试困难。
流程上看,这种问题无法通过单测发现,确实需要开发人员本身对所用技术的深刻了解,任何流程规则只能降低问题发生概率。
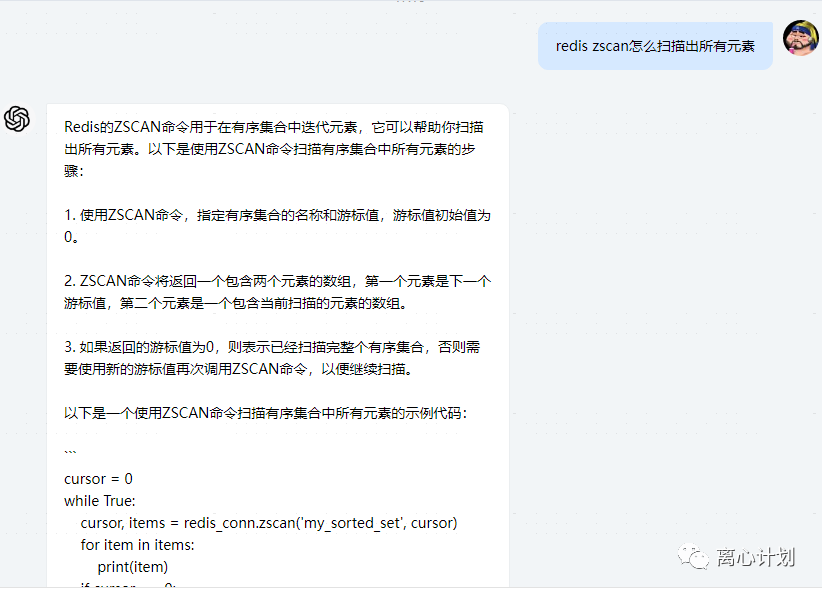
最后,gpt给出的答案确实是生产方案
周末快乐,分享一句最近看到的诗
“欲买桂花同载酒,终不似,少年游”
