爬虫学习笔记-scrapy安装及第一个项目创建问题及解决措施
1.安装scrapy
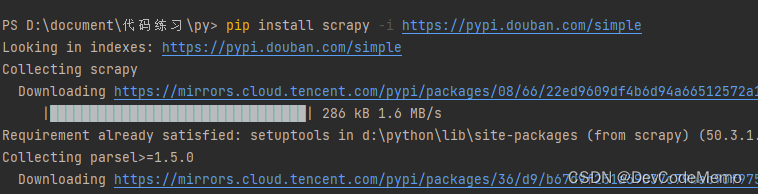
pycharm终端运行 pip install scrapy -i https://pypi.douban.com/simple
2.终端运行scrapy startproject scrapy_baidu,创建项目
问题1:lxml版本低导致无法找到

解决措施:更新或者重新安装lxml

3.项目创建成功

4.终端cd到项目的spiders文件夹下,cd scrapy_baidu\scrapy_baidu\spiders
创建爬虫文件名百度,域名scrapy genspider baidu www.baidu.com

5.爬虫文件创建成功打开,修改def parse,打印输出

6.运行爬虫文件,scrapy crawl baidu
问题2:attrs版本低

解决措施:重新安装

7.再次运行爬虫文件,scrapy crawl baidu
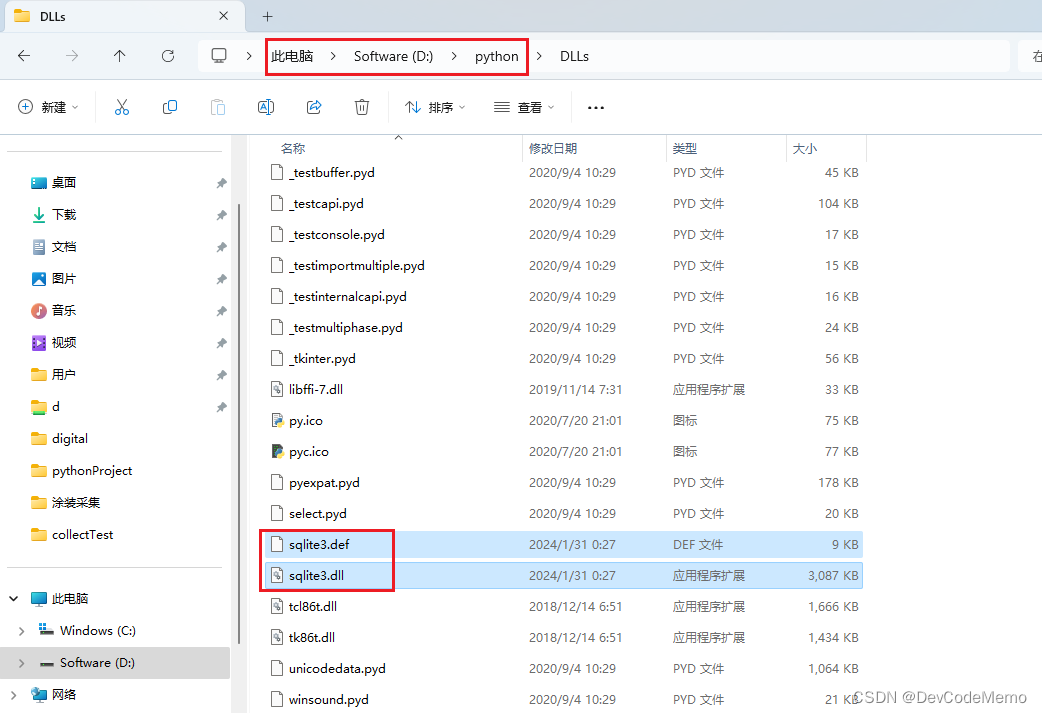
问题3:无法加载sqllite3
解决措施:下载sqllite dll文件,解压到python解释器对应DLLs文件夹下
https://www.sqlite.org/download.html

8.禁用robot协议
 9.再次执行后成功运行打印输出
9.再次执行后成功运行打印输出

10.注意:退出项目后,再次启动,需要cd到spiders目录下执行scrapy crawl baidu再启动项目