大模型|基础_word2vec
文章目录
- Word2Vec
- 词袋模型CBOW Continuous Bag-of-Words
- Continuous Skip-Gram
- 存在的问题
- 解决方案
- 其他技巧
Word2Vec
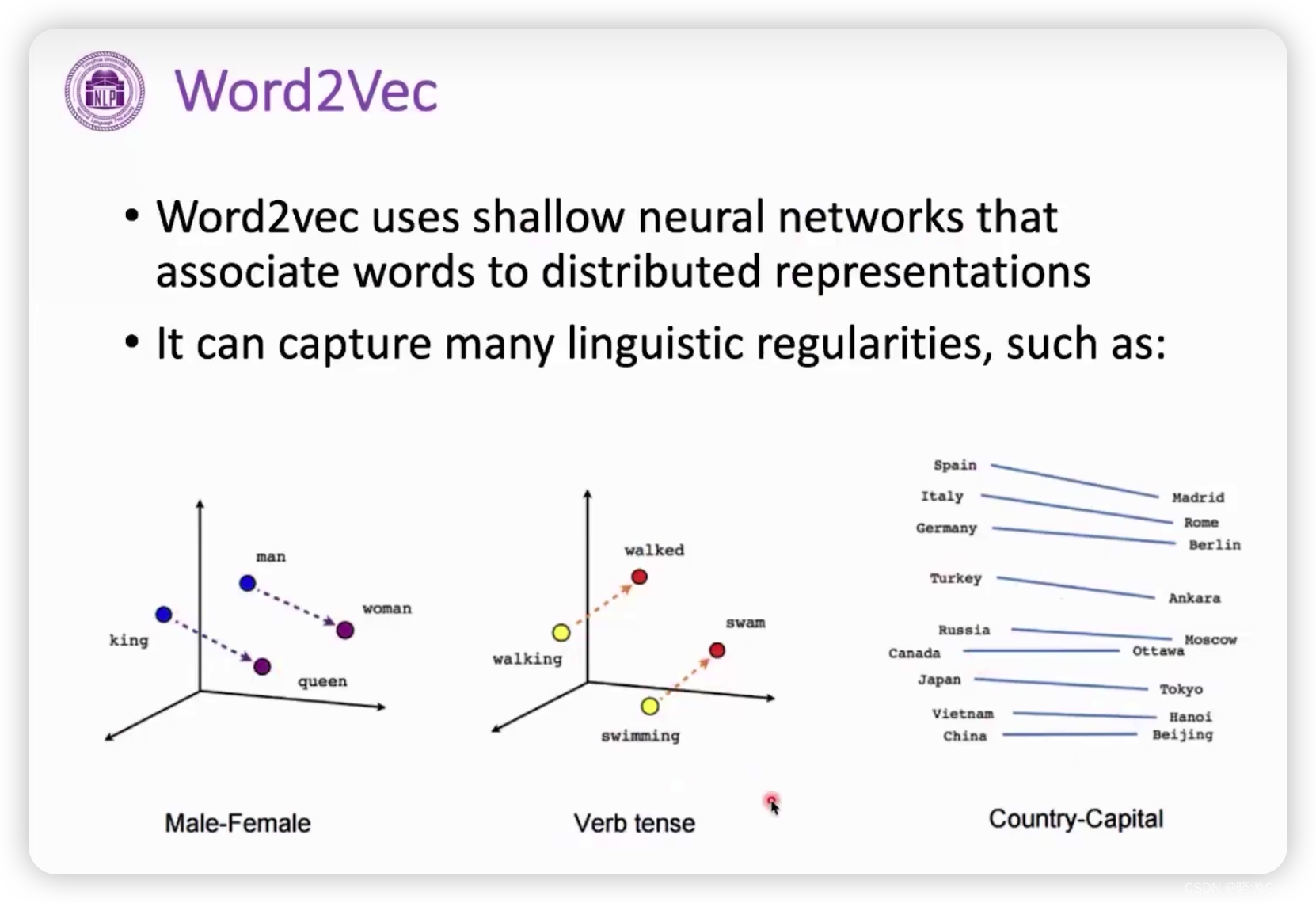
将词转化为向量后,会发现king和queen的差别与man和woman的差别是类似的,而在几何空间上,这样的差别将会以平行的关系进行表达。
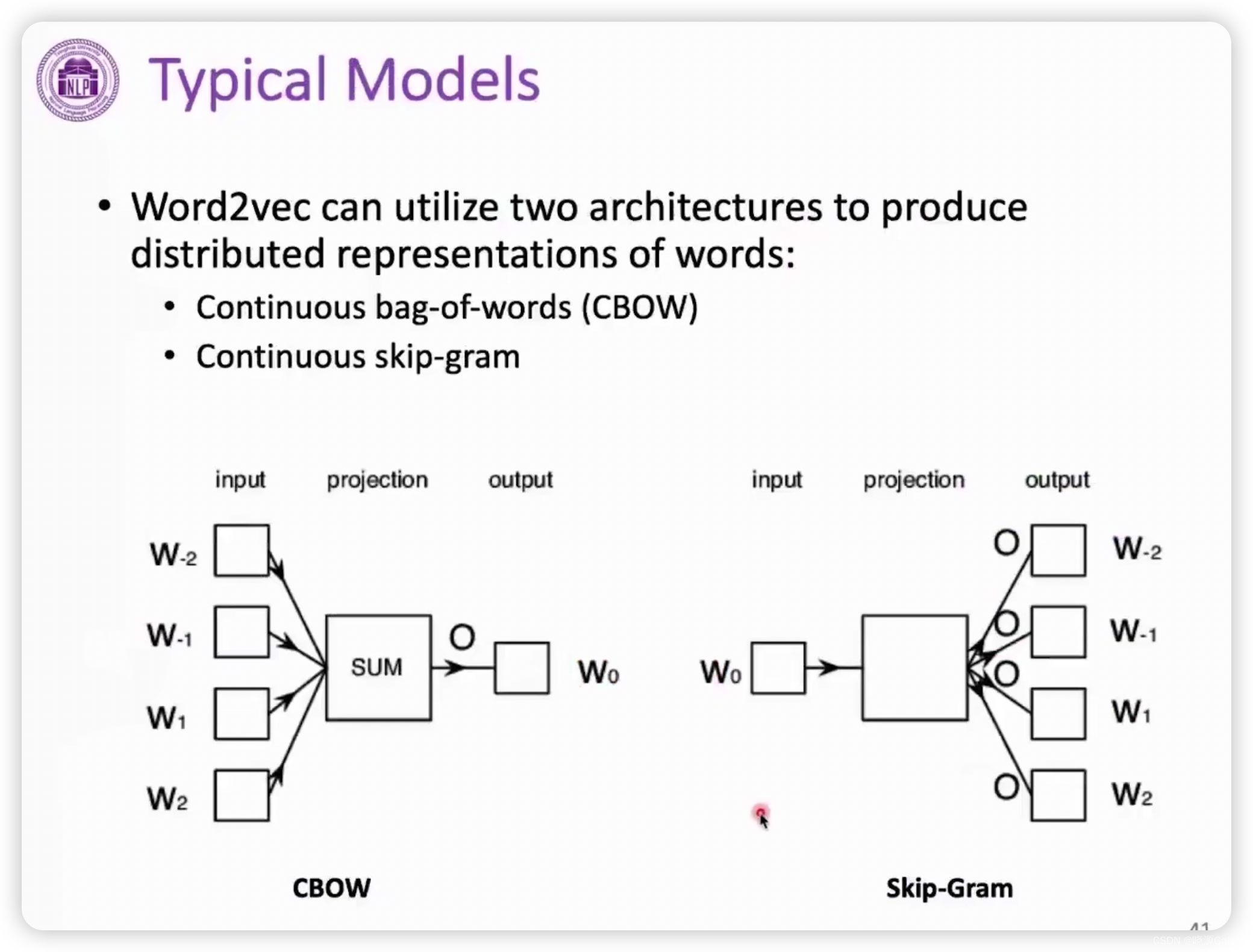
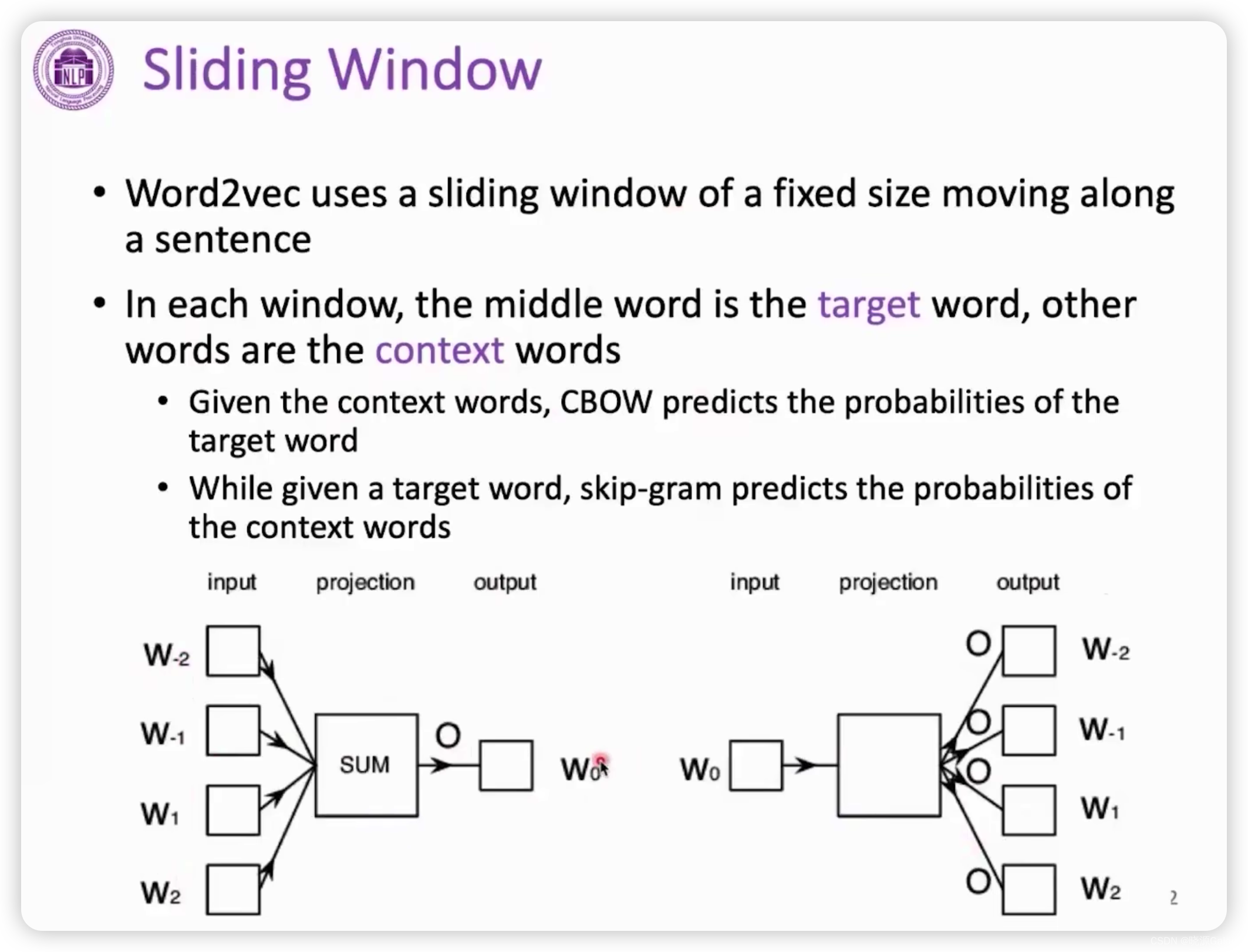
会使用滑动窗口的机制。

滑动窗口内会有一个target目标词(上图蓝色部分),滑动窗口其他部分就是context word上下文,可见,这个上下文大小受限于滑动窗口的大小。
词袋模型CBOW Continuous Bag-of-Words

通过上下文context预测目标词target。
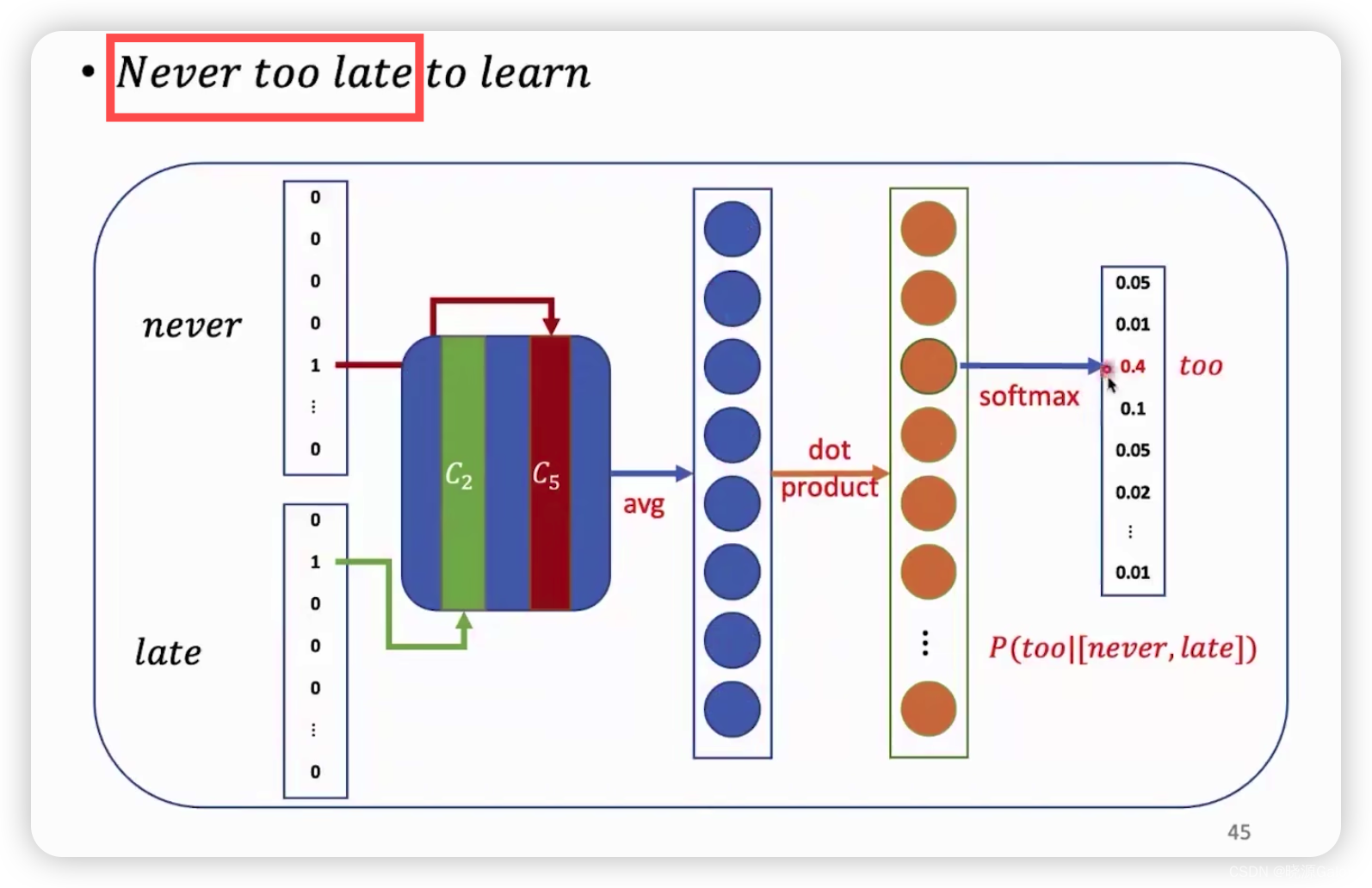
比如通过Never和late去预测出too来,先通过one-hot编码来对Never和late进行编码,并且借编码结果分别找到对应的词向量,然后将never和late的词向量去取平均,在和词库里面的每个词的词向量去做点积(点积能够反映向量的相似性)处理,然后将各个点积的结果,然后用softmax将其转化成概率,概率最大者,即为推理出来的结果。
(不是很懂,为什么还要对已知的词进行预测,可能是为了训练模型,来提高下一次,窗口框住相同的词,能够迸出target)
Continuous Skip-Gram
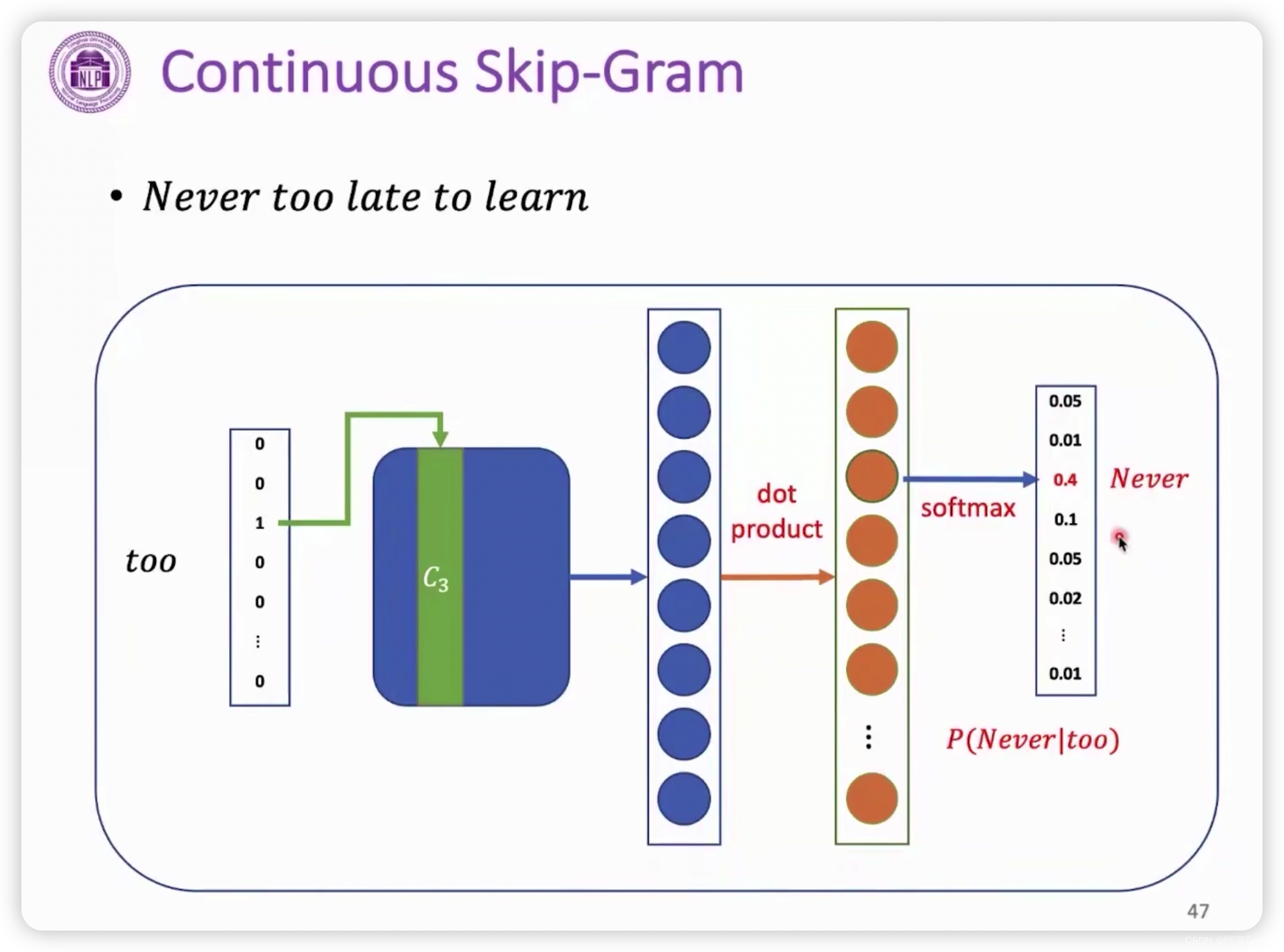
使用目标词target来反向预测上下文context。

需要注意的是,上下文单词有可能是有多的,而target只有一个,用target去预测一组上下文单词是比较困难的(可能把组当成是一个元素,存储空间太大了),于是预测的目标还是将一组单词进行拆分。
存在的问题

内容过多导致反向传播和梯度下降的执行过程所耗费的时间相对大。
解决方案
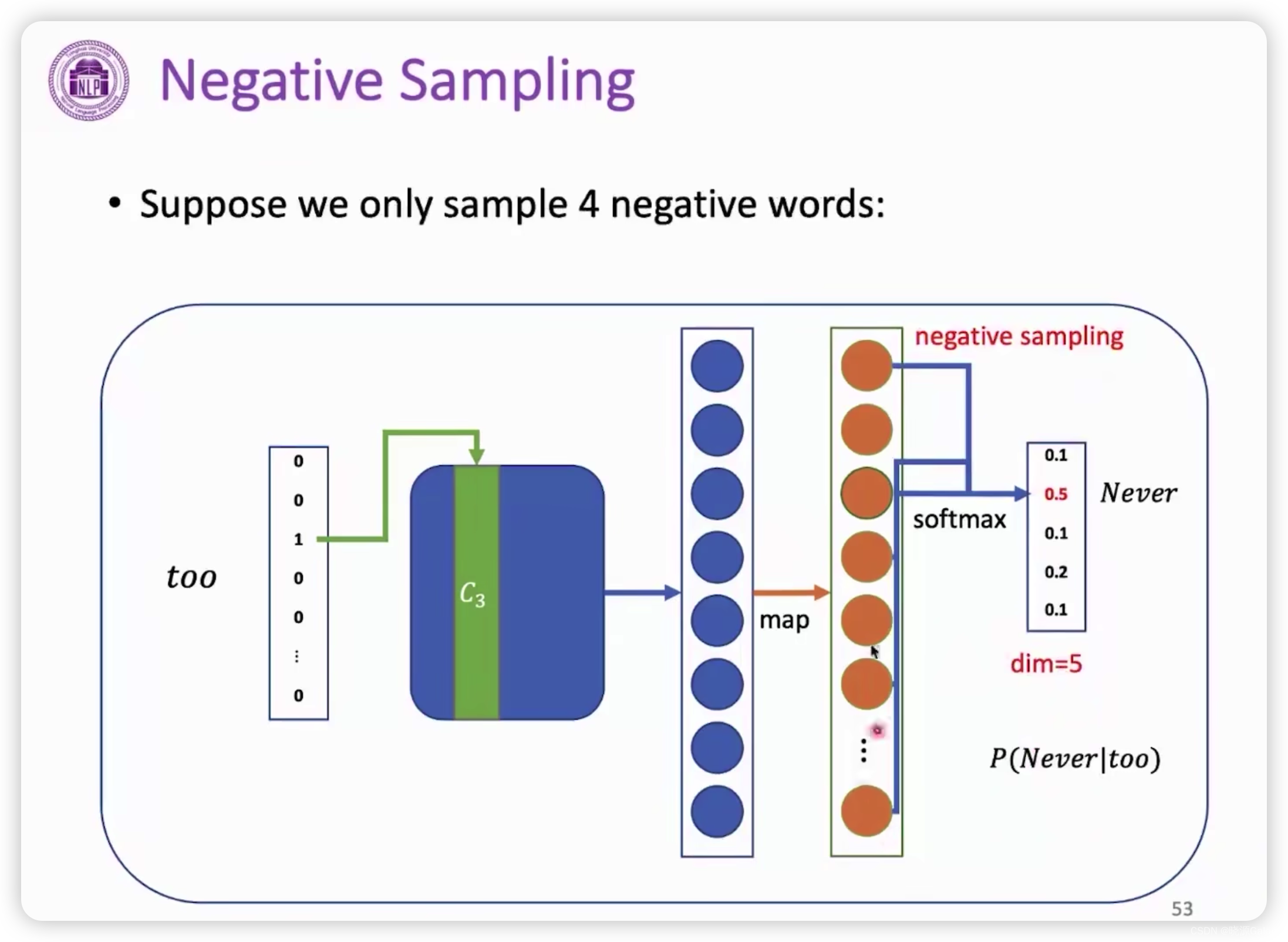
使用分层softmax和负采样。
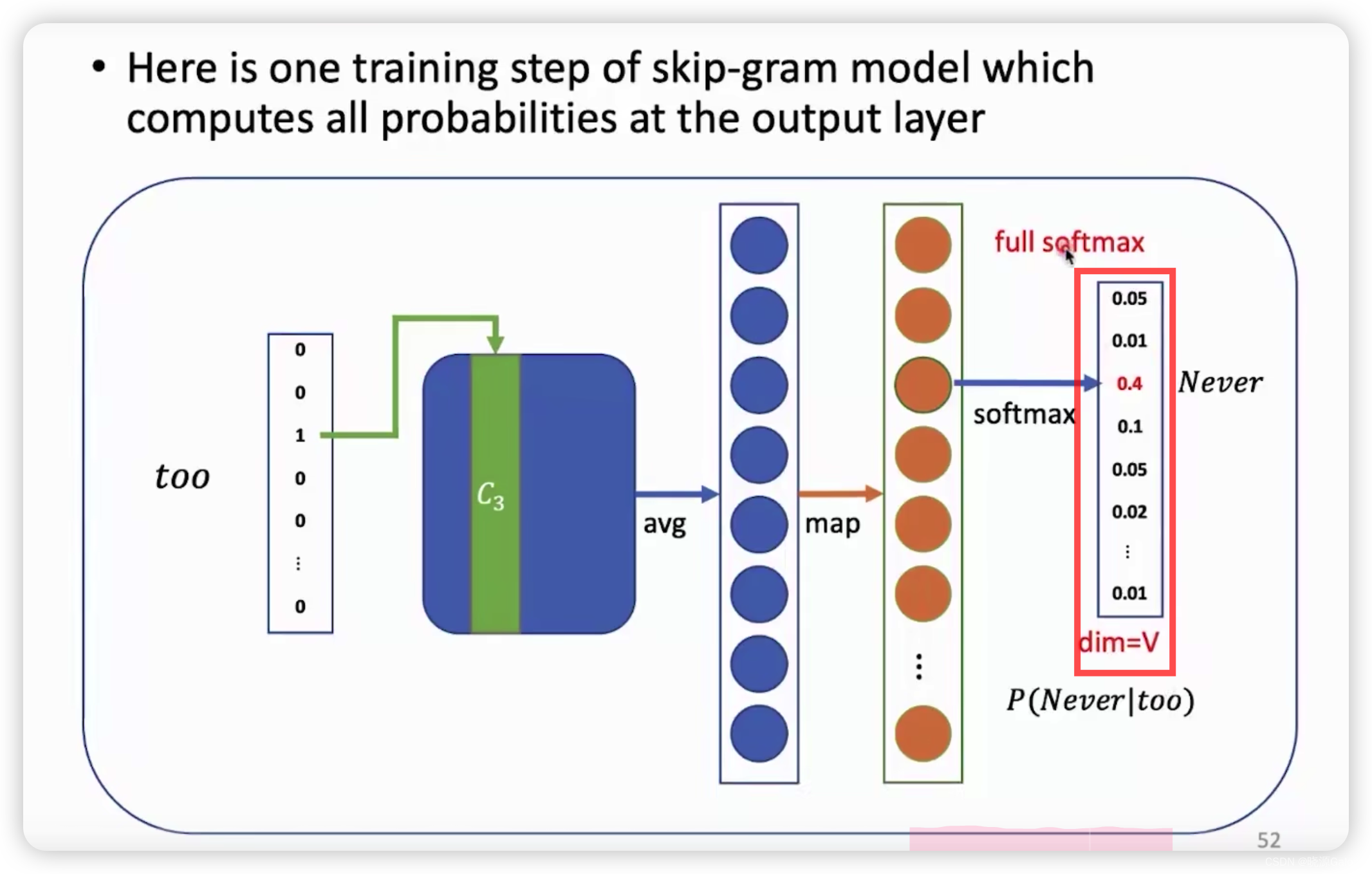
负采样前
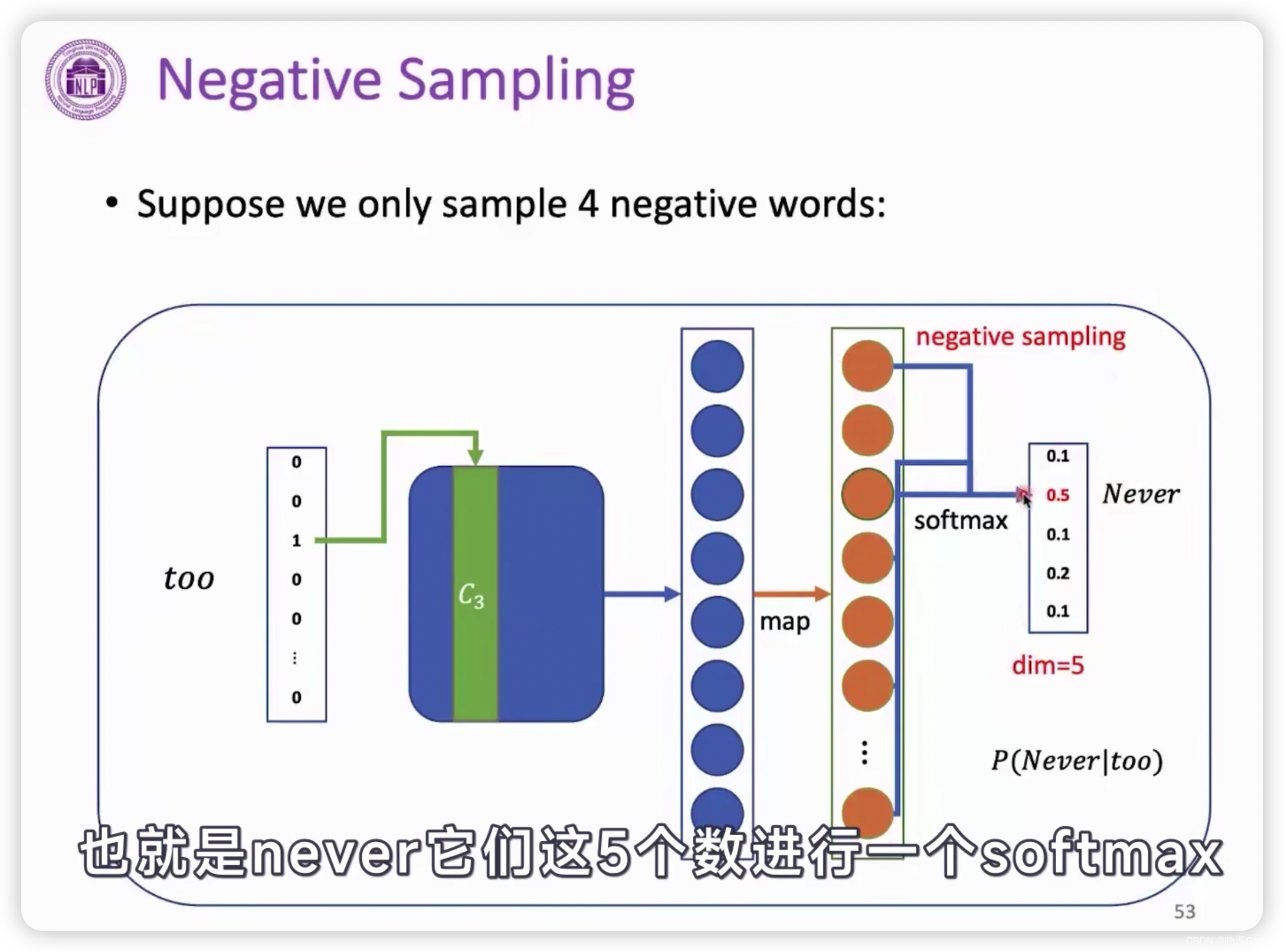
负采样后
由此观察,dim从V降成了5
其他技巧

f代表频次,f(w)即w这个词出现的次数。
而按次数去区分词,可以将词分为高频词和罕见词。
罕见词相比高频词能够蕴含更多的含义。
比如说“的”,“了”等助词只能在结构上起到完善的作用。
而罕见词往往能够带来更多的意义和区分度,更具有信息价值,所以可以通过上述这个可通过t来调节的式子来提前删去高频词。
