Redis持久化、主从与哨兵架构详解
Redis持久化、主从与哨兵架构详解
Redis持久化
RDB快照(snapshot)
在默认情况下,Redis将内存数据库快照保存进名字为dump.rdb的二进制文件中
可以对redsi进行设置,让他在N秒内数据集至少有M个改动了,这一条件被满足的时候,自动保存一次数据集
比如说,以下设置会让Redis在满足60秒内至少有1000个键被改动这一条件执行时,自动保存一次
save 60 1000 //关闭RDB 只需要将所有的save保存策略注释掉就即可
还可以手动生成RDB快照,进入redis客户端,执行命令Save或者gbsave可以生成dump.rdb文件,每次命令都将会执行将所有的redis内存快照到新的rdb文件中,并覆盖原有的rdb文件。
写时复制
bgsave的写时复制(COW)机制
Redis借助操作系统提供的写时复制技术(Copy-On-Write,COW),在生成快照的同时依旧可以正常处理写命令,简单来说,bgsave子进行是由主线程fork生成的,可以共享线程中的所有数据,bgsave子线程运行后,开始读取主线程的内存数据,并且将数据写入RDB文件,此时如果主线程对这些数据也是读操作,那么主线程和bgsave线程是互不影响的,但是如果主线程是修改数据,那么那块数据就会被复制一份,生成该数据的副本,然后bgsave子进程会把这个副本数据写入EDB文件,而这个过程中,主线程仍然可以修改原来的数据
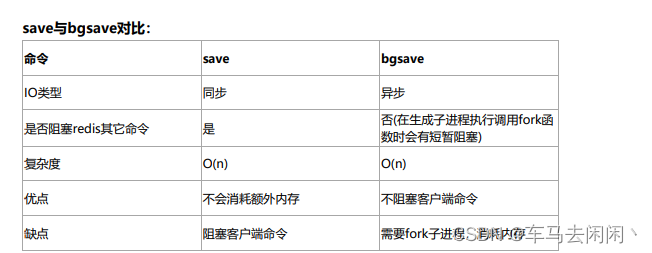
配置自动生成RDB文件后台使用的是bgsave
AOF持久化(Append-only file)
快照功能并不是非常耐久,如果redis因为没写原因而造成故障停机,那么服务器将丢失最近写入,且仍未保存到快照中的那些数据,从1.1版本开始,Redis增加了一种完全耐久的持久化方式,AOF持久化,将修改的每一条指令记录到文件appendonly.aof文件中,(先写入os cache,每隔一段时间fsync到磁盘)
比如执行命令 “set zhuge 666”, aof文件会记录如下数据
1 *3
2 $3
3 set
4 $5
5 zhuge
6 $3
7 666
这是一种resp协议格式数据,星号后面的数字代表命令有多少个参数,$号后面的数字代表这个参数有几
个字符
注意,如果执行带过期时间的set命令,aof文件里记录的是并不是执行的原始命令,而是记录key过期的
时间戳
比如执行“set tuling 888 ex 1000”,对应aof文件里记录如下
1 *3
2 $3
3 set
4 $6
5 tuling
6 $3
7 888
8 *3
9 $9
10 PEXPIREAT
11 $6
12 tuling
13 $13
14 1604249786301
可以通过配置文件 来打开AOF功能
# appendonly yes
从现在开始,每当执行Redis执行一个改变数据集命令时(set等),这个命令就会被追加到AOF文件的末尾,这样的话,当redis重新启动的时候,程序就可以通过重新执行AOF文件中的命令,来达到重建数据集的目的
Redis配置多久fsync到磁盘一次
1 appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
2 appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
3 appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
AOF重写
AOf里面有太多没用的指令,所有AOF会定期根据内存的最新数据,来生成aof文件,
例如
1 127.0.0.1:6379> incr readcount
2 (integer) 1
3 127.0.0.1:6379> incr readcount
4 (integer) 2
5 127.0.0.1:6379> incr readcount
6 (integer) 3
7 127.0.0.1:6379> incr readcount
8 (integer) 4
9 127.0.0.1:6379> incr readcount
10 (integer) 5
重写后AOF文件里变成
1 *3
2 $3
3 SET
4 $2
5 readcount
6 $1
7 5
如下两个配置可以控制AOF自动重写频率
1 # auto‐aof‐rewrite‐min‐size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就
很快,重写的意义不大
2 # auto‐aof‐rewrite‐percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
当然AOF还可以手动重写,进入redis客户端执行命令bgrewriteaof重写AOF 注意,AOF重写redis会fork出一个子进程去做(与bgsave命令类似),不会对redis正常命令处理有太多 影响
RDB和AOF的区别
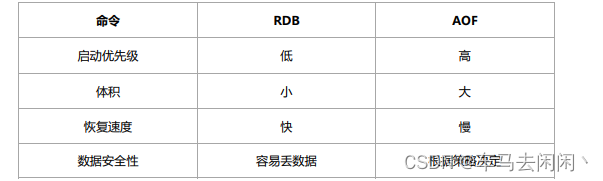
生产环境都可以启用,redis启动时如果既有rdb文件又有aof文件,则优先选择AOF文件进行数据恢复,因为aof文件一般来说更安全
混合持久化
重启Redis是,我们很少使用RDB文件进行恢复,因为会丢失大量数据,我们通常使用AOF文件重放,但是重放AOF文件要比RDB慢,这样在Redis实例很大的情况下,启动需要花费很长时间,Redis4.0为了解决这个问题,带来了一个新的持久化方式-混合持久化
开启方法
必须提前开始aof
# aof-use-rdb-preamble yes
如果开启混合持久化,那AOF在重写的时候,就不是单纯的将内存数据转换为RESP命令写入AOF文件了,而是将重写这一刻之前的内存都做RDB文件快照处理,并且将RDB快照内容,和增量的AOF修改内存的命令存储在一起,都写入新的AOF文件,新的文件一开始不叫appendonly。aof,等重写完成之后才会进行改动,覆盖原有的aof文件,完成新旧两个aof文件的替换。
于是在redis重启的时候,可以先加载rdb的内容,在重放增量aof日志就可以完全替代之前的aof全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如图
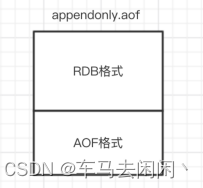
Redis备份策略
- 写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48 小时的备份
- 每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份
- 每次copy备份的时候,都把太旧的备份给删了
- 每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
Redis主从架构
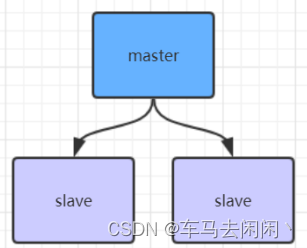
redis主从架构搭建,配置从节点步骤
1、复制一份redis.conf文件
2、将相关配置修改为如下值:
port 6380
pidfile /var/run/redis_6380.pid # 把pid进程号写入pidfile配置的文件
logfile "6380.log"
dir /usr/local/redis‐5.0.3/data/6380 # 指定数据存放目录
# 需要注释掉bind
# bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通
过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
3、配置主从复制
replicaof 192.168.0.60 6379 # 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof
replica‐read‐only yes # 配置从节点只读
4、启动从节点
redis‐server redis.conf
5、连接从节点
redis‐cli ‐p 6380
6、测试在6379实例上写数据,6380实例是否能及时同步新修改数据
7、可以自己再配置一个6381的从节点
Redsi主从复制原理
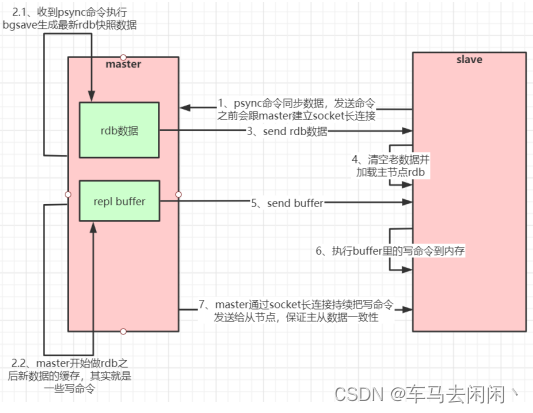
如果你为Master配置了一个slave,不管这个slave是否是第一次连接上Master,他都会发送一个psync命令给master请求复制数据。master收到psync命令后,会在后台进行数据持久化,通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,他会把这些可能修改数据集的请求缓存在内存中,当持久化进行完成,master会将这份rdb数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后在加载到内存中,然后,master再将之前缓存在内存中的命令发送给slave。
当master与slave之前的连接由于某些原因而断开,slave会自动重连master,如果master收到了多个slave并发连接请求,他只会进行一次持久化,而不是一个连接一次,再把持久化的数据发给多个并发连接的slave。
主从复制流程图
数据部分复制
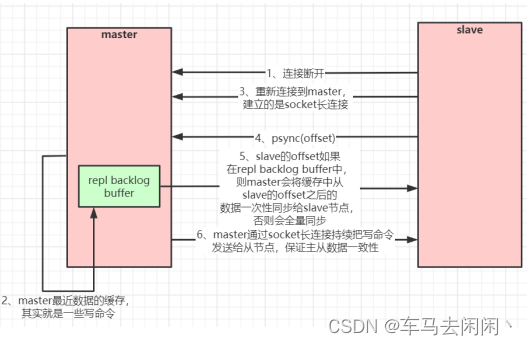
当master和slave断开重连后,一般都会对整份数据进行复制,但是从2.8之后,redis改用可以支持部分数据复制的命令psync去master同步数据,slave与master呢能够在网络断开重连后只进行部分数据复制(断点续传)
master会在其内存中船舰一个复制数据用的缓存队列,缓存最近一段时间的护具,master和他所有的slave都维护了复制数据下表offset和master的进程ID,因此当网络断开后,slave会请求msater继续及逆行未完成的复制,从所记录的数据下标开始,如果master进程id变化了,或者从节点数据下表offset太旧,已经不再master的缓存队列里了,那么将会进行一次全量数据的复制。
主从复制(部分数据,断点续传流程图)
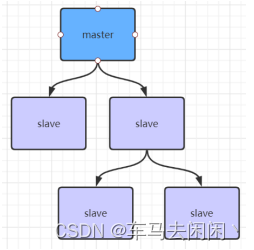
如果有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做如 下架构,让部分从节点与从节点(与主节点同步)同步数据
Redis哨兵高可用架构
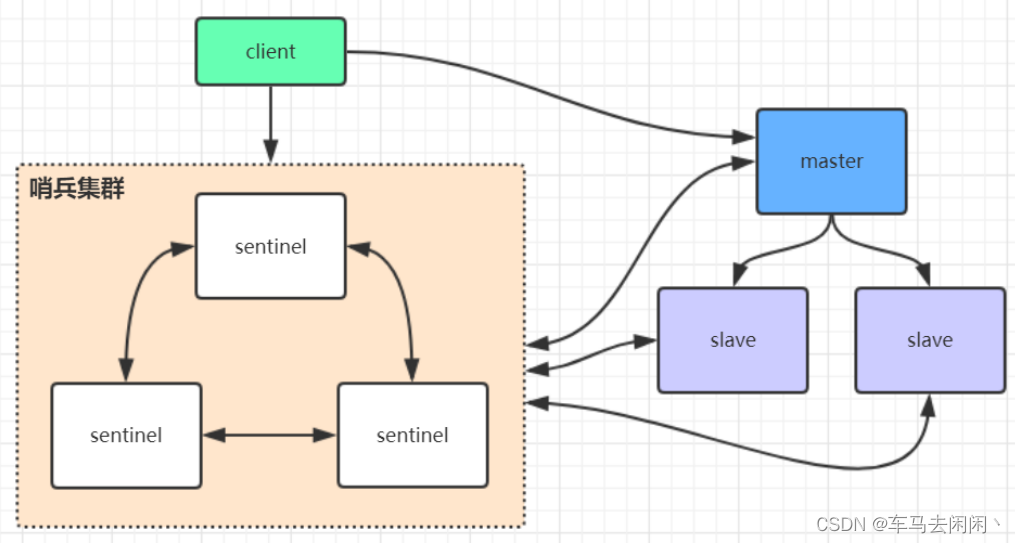
sentinel哨兵是特殊的redis服务,不提供读写服务,只要用来监控redis实力节点。
哨兵结构下client段第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次通过sentinel代理访问redis的主节点,当redis的主节点放生变化,哨兵会第一时间感知到,并且将新的redis主节点通知给client端,(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
1、复制一份sentinel.conf文件
cp sentinel.conf sentinel‐26379.conf
2、将相关配置修改为如下值:
port 26379
daemonize yes
pidfile "/var/run/redis‐sentinel‐26379.pid"
logfile "26379.log"
dir "/usr/local/redis‐5.0.3/data"
# sentinel monitor <master‐redis‐name> <master‐redis‐ip> <master‐redis‐port> <quorum>
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 +
1),master才算真正失效
sentinel monitor mymaster 192.168.0.60 6379 2 # mymaster这个名字随便取,客户端访问时会用
到
3、启动sentinel哨兵实例
src/redis‐sentinel sentinel‐26379.conf
4、查看sentinel的info信息
src/redis‐cli ‐p 26379
127.0.0.1:26379>info
可以看到Sentinel的info里已经识别出了redis的主从
5、可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改
sentinel集群都启动完毕后,会将哨兵集群的元数据信息写入所有sentinel的配置文件里去(追加在文件的 最下面),我们查看下如下配置文件sentinel-26379.conf,如下所示:
sentinel known‐replica mymaster 192.168.0.60 6380 #代表redis主节点的从节点信息
sentinel known‐replica mymaster 192.168.0.60 6381 #代表redis主节点的从节点信息
sentinel known‐sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c569
35760f #代表感知到的其它哨兵节点
sentinel known‐sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8
bd5ca6 #代表感知到的其它哨兵节点
同时还会修改sentinel文件里之前配置的mymaster对应的6379端口,改为6380
sentinel monitor mymaster 192.168.0.60 6380 2
当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点 加入集群
哨兵的Jedis连接代码:
public class JedisSentinelTest {
public static void main(String[] args) throws IOException {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(20);
config.setMaxIdle(10);
config.setMinIdle(5);
String masterName = "mymaster";
Set<String> sentinels = new HashSet<String>();
sentinels.add(new HostAndPort("192.168.0.60",26379).toString());
sentinels.add(new HostAndPort("192.168.0.60",26380).toString());
sentinels.add(new HostAndPort("192.168.0.60",26381).toString());
//JedisSentinelPool其实本质跟JedisPool类似,都是与redis主节点建立的连接池
//JedisSentinelPool并不是说与sentinel建立的连接池,而是通过sentinel发现redis主节点并与其
建立连接
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinels, co
nfig, 3000, null);
Jedis jedis = null;
try {
jedis = jedisSentinelPool.getResource();
System.out.println(jedis.set("sentinel", "zhuge"));
System.out.println(jedis.get("sentinel"));
} catch (Exception e) {
e.printStackTrace();
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null)
jedis.close();
}
}
}
哨兵的Spring Boot整合Redis连接代码见示例项目:redis-sentinel-cluster 1、引入相关依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring‐boot‐starter‐data‐redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons‐pool2</artifactId>
</dependency>
springboot项目核心配置:
server:
port: 8080
spring:
redis:
database: 0
timeout: 3000
sentinel: #哨兵模式
master: mymaster #主服务器所在集群名称
nodes: 192.168.0.60:26379,192.168.0.60:26380,192.168.0.60:26381
lettuce:
pool:
max‐idle: 50
min‐idle: 10
max‐active: 100
max‐wait: 1000
访问代码
@RestController
public class IndexController {
private static final Logger logger = LoggerFactory.getLogger(IndexController.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 测试节点挂了哨兵重新选举新的master节点,客户端是否能动态感知到
* 新的master选举出来后,哨兵会把消息发布出去,客户端实际上是实现了一个消息监听机制,
* 当哨兵把新master的消息发布出去,客户端会立马感知到新master的信息,从而动态切换访问的maste
rip
*
* @throws InterruptedException
*/
@RequestMapping("/test_sentinel")
public void testSentinel() throws InterruptedException {
int i = 1;
while (true){
try {
stringRedisTemplate.opsForValue().set("zhuge"+i, i+"");
System.out.println("设置key:"+ "zhuge" + i);
i++;
Thread.sleep(1000);
}catch (Exception e){
logger.error("错误:", e);
}
}
}
}
StringRedisTemplate与RedisTemplate详解 spring 封装了 RedisTemplate 对象来进行对redis的各种操作,它支持所有的 redis 原生的 api。在 RedisTemplate中提供了几个常用的接口方法的使用,分别是:
private ValueOperations<K, V> valueOps;
private HashOperations<K, V> hashOps;
private ListOperations<K, V> listOps;
private SetOperations<K, V> setOps;
private ZSetOperations<K, V> zSetOps;
RedisTemplate中定义了对5种数据结构操作
1 redisTemplate.opsForValue();//操作字符串
2 redisTemplate.opsForHash();//操作hash
3 redisTemplate.opsForList();//操作list
4 redisTemplate.opsForSet();//操作set
5 redisTemplate.opsForZSet();//操作有序set
StringRedisTemplate继承自RedisTemplate,也一样拥有上面这些操作。 StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存 的。 RedisTemplate默认采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。
Redis客户端命令对应的RedisTemplate中的方法列表:



