kafka 文件存储机制
文章目录
- 1. 思考四个问题:
- 1.1 topic中partition存储分布:
- 1.2 partiton中文件存储方式:
- 1.3 partiton中segment文件存储结构:
- 1.4 在partition中如何通过offset查找message:
- 2. kafka日志存储参数配置
- Topic是逻辑上的概念,而partition是物理上的概念
- 每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。
- Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下(不需要先查出来数据,直接往最后追加,也是kafka可以高效读写的原因之一),Kafka采取了分片和索引机制,将每个partition分为多个segment。(segment默认大小为1GB)
- 每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号,例如:first-0。
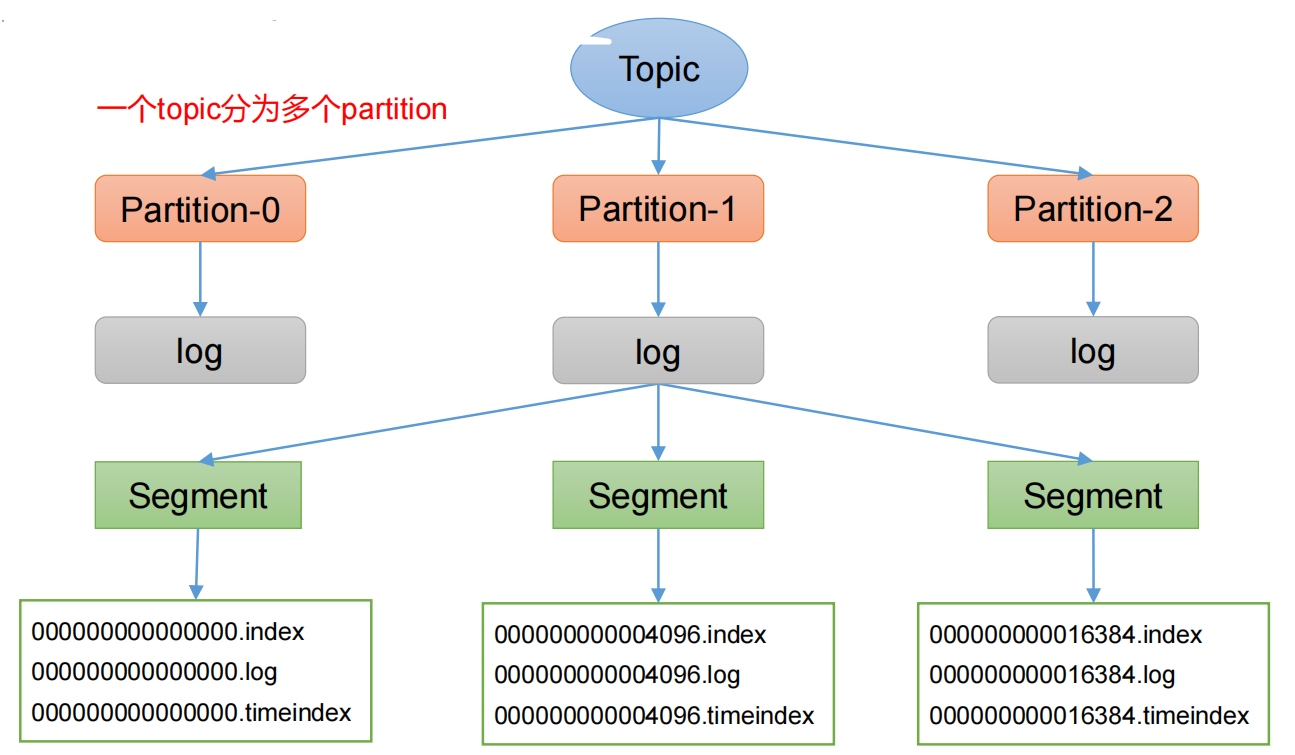
1. 思考四个问题:
- topic中partition存储分布
- partiton中文件存储方式
- partiton中segment文件存储结构
- 在partition中如何通过offset查找message
1.1 topic中partition存储分布:
- 在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
- 每个partition下面有多个segment。
1.2 partiton中文件存储方式:
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
1.3 partiton中segment文件存储结构:
- segment file由segment索引文件、数据文件2部分组成,这两个文件一一对应,后缀是”.index”和“.log”,分别表示为segment索引文件、数据文件
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。

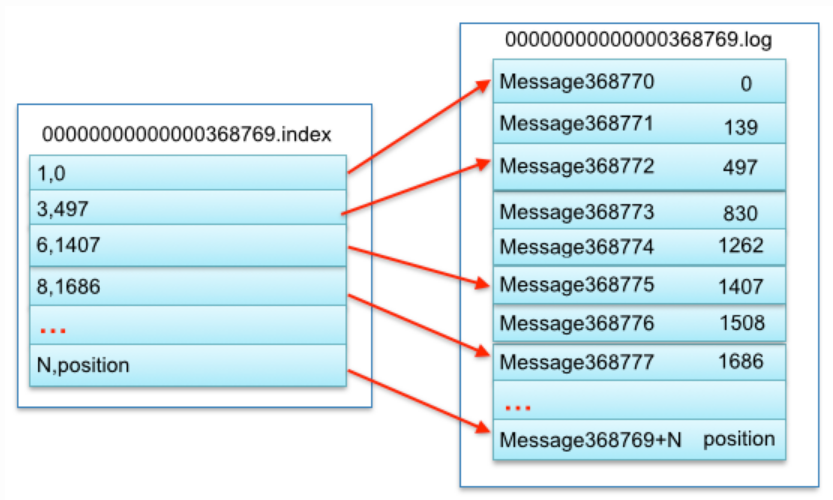
1.4 在partition中如何通过offset查找message:
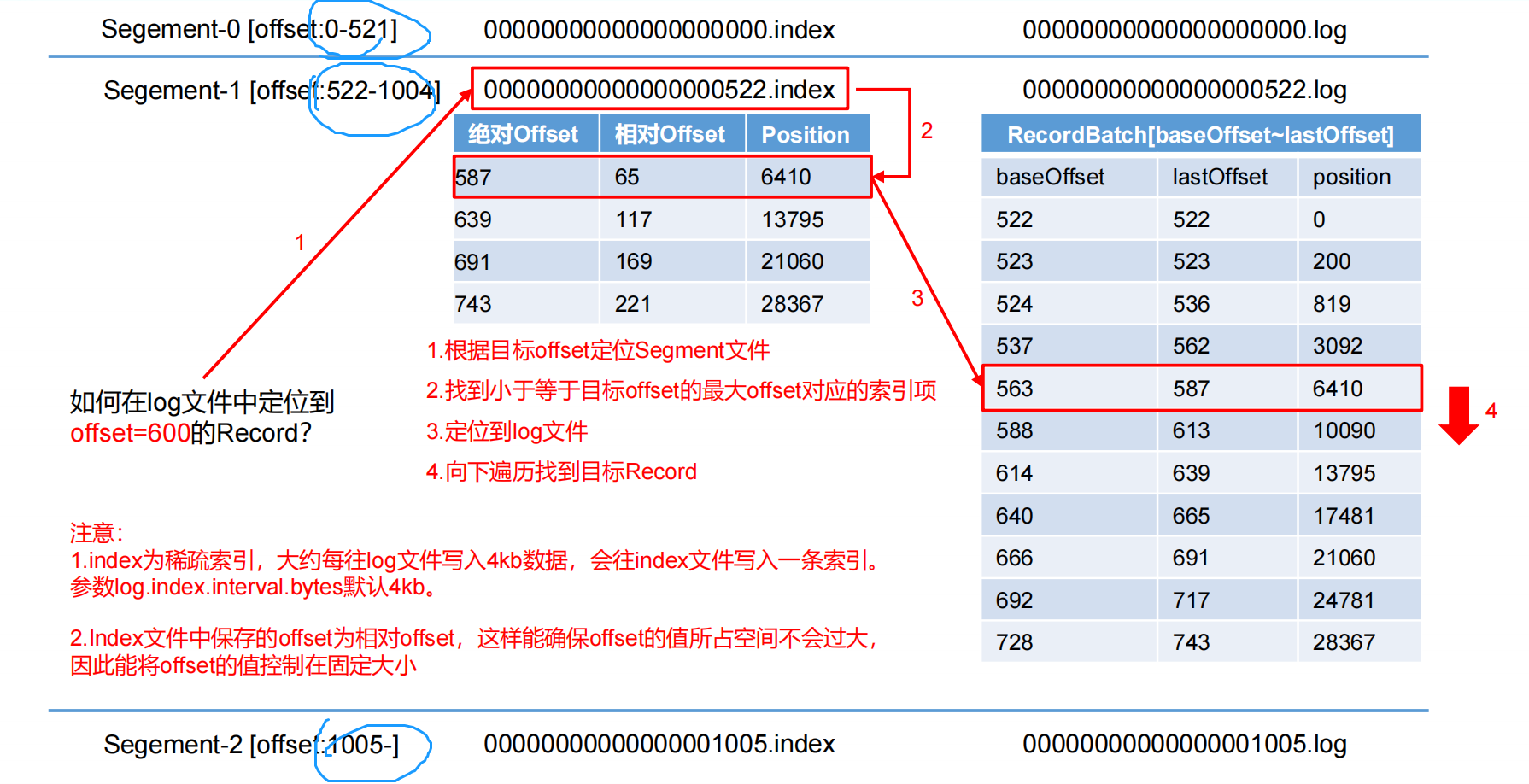
- segment的索引文件命令规则:起始偏移量(offset)为0.后续每个segment文件名为上一个segment文件最后一条消息的offset值,所以,第二个文件00000000000000000522.index的文件名是上一个log中最大偏移量+1(521+1=522),其他后续文件依次类推,只要根据offset 二分查找 文件列表,就可以快速定位到具体文件。 当offset=600时定位到00000000000000000522.index|log,用index文件名上的数字+相对offset计算log文件中数据存在的位置,522+65=587,522+117=639,587 < 600 < 639,所以Offset=600的数据在position=6410的位置往下顺扫。
segment index file采取稀疏索引存储方式,不会为每条数据创建索引,大大的减少索了引文件大小。
2. kafka日志存储参数配置
| 参数 | 描述 |
|---|---|
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G。 |
| log.index.interval.bytes | 稀疏索引间存储数据的大小,默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |