Fink CDC数据同步(二)MySQL数据同步
1 开启binlog日志

2 数据准备
use bigdata;
drop table if exists user;
CREATE TABLE `user`(
`id` INTEGER NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL DEFAULT '',
`birth` VARCHAR(20) NOT NULL DEFAULT '',
`gender` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`id`)
);
ALTER TABLE user AUTO_INCREMENT = 1001;
insert into user values(default , '东契奇' , '1995-01-01' , '男');
insert into user values(default , '斯蒂芬' , '1996-12-21' , '男');
insert into user values(default , '里奥梅西' , '1993-05-10' , '男');
insert into user values(default , '凯里欧文' , '1994-08-06' , '男');
insert into user values(default , '张淋艳' , '1997-12-01' , '女');
insert into user values(default , '王珊珊' , '1995-03-01' , '女');
insert into user values(default , '唐佳丽' , '1994-07-01' , '女');
insert into user values(default , '杨力维' , '1995-10-20' , '女');
select * from user;3 jar包依赖
在flink/lib目录下添加依赖:
flink-sql-connector-mysql-cdc-2.3.0.jar
下载地址:
Central Repository: com/ververica/flink-sql-connector-mysql-cdc
4 启动sql-client
# 启动服务
/opt/flink/flink-1.16.2/bin/start-cluster.sh
# 启动sql-client
/opt/flink/flink-1.16.2/bin/sql-client.sh
设置模式
set sql-client.execution.result-mode = tableau;设置checkpont
set execution.checkpointing.interval=30sec;建mysql的映射表
CREATE TABLE if not exists mysql_user (
id STRING,
name STRING,
birth STRING,
gender STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector'= 'mysql-cdc',
'hostname'= '192.168.0.1',
'port'= '3306',
'username'= 'user',
'password'='password',
'server-time-zone'= 'Asia/Shanghai',
'debezium.snapshot.mode'='initial',
'database-name'= 'bigdata1',
'table-name'= 'user'
); 执行查询语句,会生成一个flink job任务
select * from mysql_user; 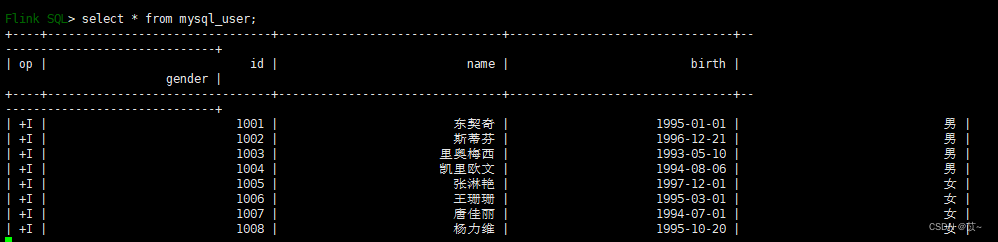
5 常用参数表
| 参数名 | 必填 | 默认值 | 类型 | 参数描述 |
| connector | 是 | 无 | String | 指定connector,这里填 mysql-cdc |
| hostname | 是 | 无 | String | MySql server 的主机名或者 IP 地址 |
| username | 是 | 无 | String | 连接 MySQL 数据库的用户名 |
| password | 是 | 无 | String | 连接 MySQL 数据库的密码 |
| database-name | 是 | 无 | String | 需要监控的数据库名,支持正则表达式 |
| table-name | 是 | 无 | String | 需要监控的表名,支持正则表达式 |
| port | 是 | 3306 | Integer | MySQL 服务的端口号 |
| server-id | 否 | 无 | Integer | 当开启scan.incremental.snapshot.enabled时,建议指定server-id;server-id 可以是单个值,如5400; 也可以提供数值范围,如5400-5408 |
| scan.incremental.snapshot.enabled | 否 | TRUE | Boolean | 增量快照是读取表快照的新机制;和旧的快照读相比有以下优点:1. 并行读取 2. 支持checkpoint 3. 不需要锁表;当需要并行读取时,server-id需要设置数值范围,如5400-5408 |
| scan.incremental.snapshot.chunk.size | 否 | 8096 | Integer | 表快照的块大小 |
| scan.snapshot.fetch.size | 否 | 1024 | Integer | 每次读表接受的最大值 |
| scan.startup.mode | 否 | initial | String | MySQL CDC 启动模式,有效值:initial 和 latest-offset |
| connect.timeout | 否 | 30s | Duration | connector 连接 MySQL 服务的最长等待超时时间 |
| connect.max-retries | 否 | 3 | Integer | connector 创建 MySQL 连接的重试次数 |
| connection.pool.size | 否 | 20 | Integer | 连接池的大小 |
系列文章
Fink CDC数据同步(一)环境部署![]() https://blog.csdn.net/weixin_44586883/article/details/136017355?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44586883/article/details/136017355?spm=1001.2014.3001.5502
Fink CDC数据同步(二)MySQL数据同步![]() https://blog.csdn.net/weixin_44586883/article/details/136017472?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136017472?spm=1001.2014.3001.5501
Fink CDC数据同步(三)Flink集成Hive![]() https://blog.csdn.net/weixin_44586883/article/details/136017571?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136017571?spm=1001.2014.3001.5501
Fink CDC数据同步(四)Mysql数据同步到Kafka![]() https://blog.csdn.net/weixin_44586883/article/details/136023747?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136023747?spm=1001.2014.3001.5501
Fink CDC数据同步(五)Kafka数据同步Hive![]() https://blog.csdn.net/weixin_44586883/article/details/136023837?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_44586883/article/details/136023837?spm=1001.2014.3001.5501
Fink CDC数据同步(六)数据入湖Hudi![]() https://blog.csdn.net/weixin_44586883/article/details/136023939?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44586883/article/details/136023939?spm=1001.2014.3001.5502