【附代码】NumPy加速库NumExpr(大数据)
文章目录
- 相关文献
- 测试电脑配置
- 数组加减乘除
- 数组乘方
- Pandas加减乘除
- 总结
作者:小猪快跑
基础数学&计算数学,从事优化领域5年+,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法
如有错误,欢迎指正。如有更好的算法,也欢迎交流!!!——@小猪快跑
相关文献
- NumExpr Documentation Reference — numexpr 2.8.5.dev1 documentation
测试电脑配置
博主三千元电脑的渣渣配置:
CPU model: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics, instruction set [SSE2|AVX|AVX2|AVX512]
Thread count: 8 physical cores, 16 logical processors, using up to 16 threads
数组加减乘除
我们计算 2 * a + 3 * b,发现在数据量较大时候,NumExpr明显快于NumPy
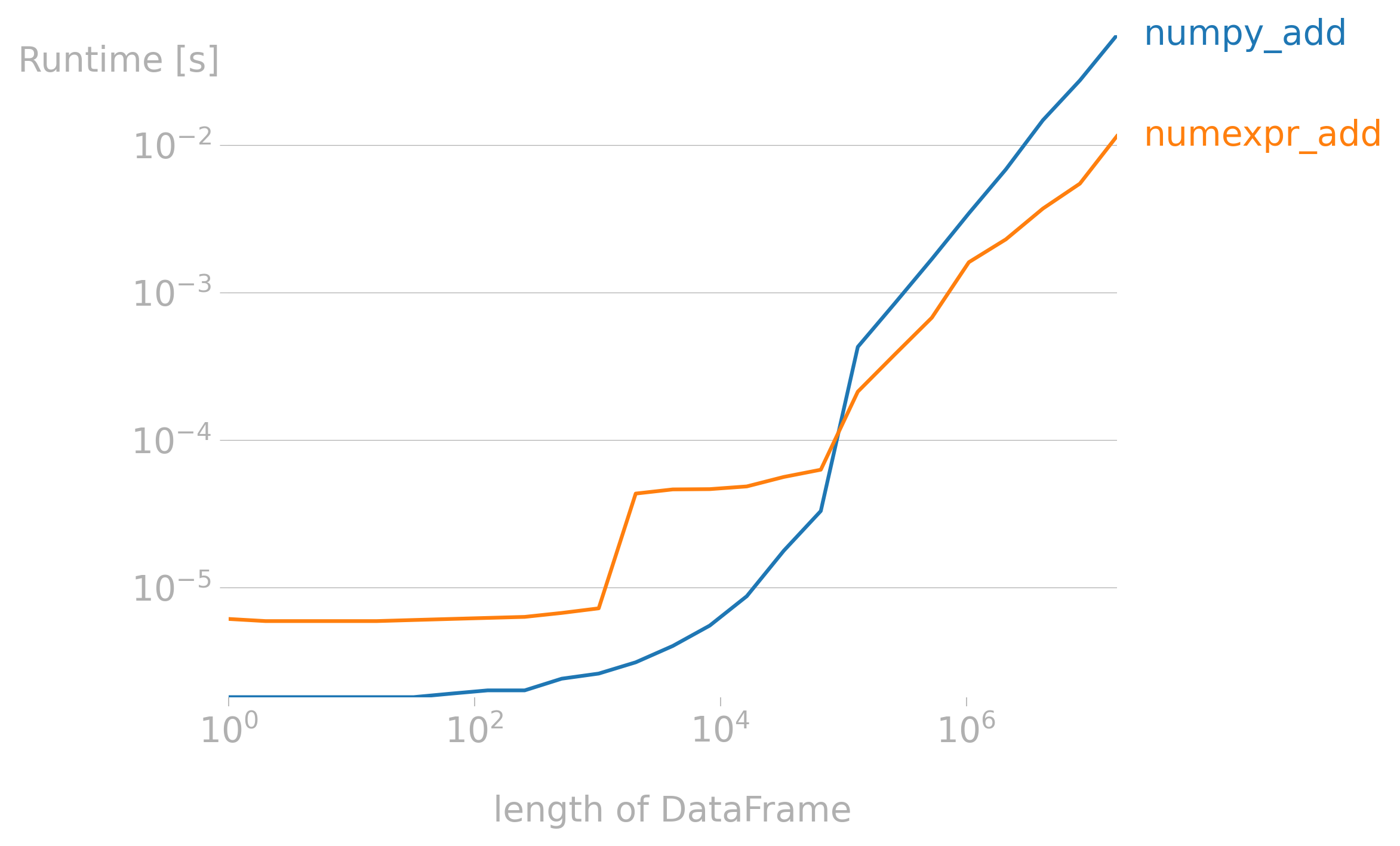
import perfplot
from matplotlib import pyplot as plt
import numpy as np
import numexpr as ne
def numpy_add(a, b):
return 2 * a + 3 * b
def numexpr_add(a, b):
return ne.evaluate("2 * a + 3 * b")
if __name__ == '__main__':
b = perfplot.bench(
setup=lambda n: (np.random.rand(n), np.random.rand(n)),
kernels=[
numpy_add,
numexpr_add,
],
n_range=[2 ** k for k in range(25)],
xlabel="length of DataFrame",
)
plt.figure(dpi=300)
b.save(f"arr_add.png")
b.show()
数组乘方
我们计算 2 * a + b ** 10,发现在数据量较大时候,NumExpr明显快于NumPy
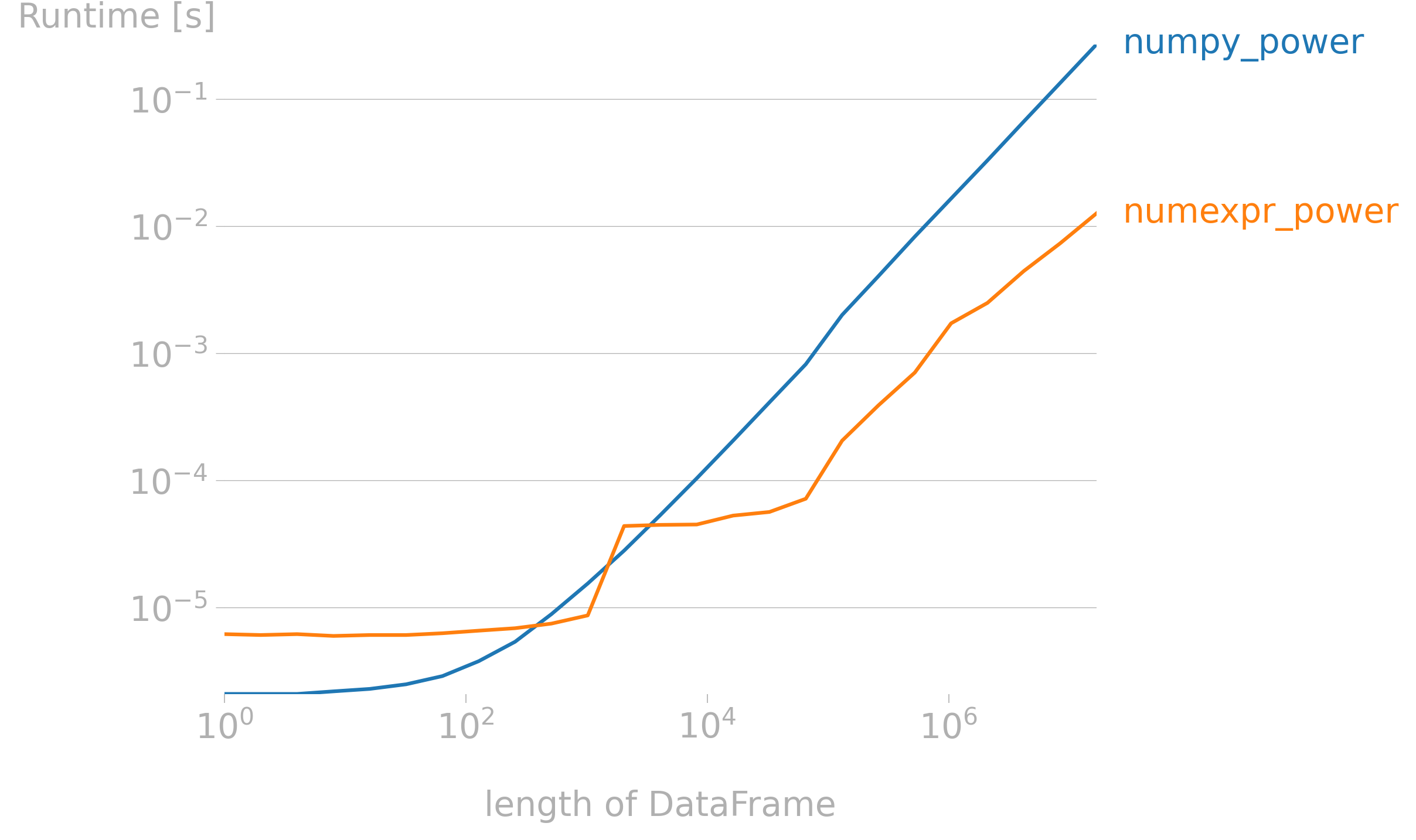
import perfplot
from matplotlib import pyplot as plt
import numpy as np
import numexpr as ne
def numpy_power(a, b):
return 2 * a + b ** 10
def numexpr_power(a, b):
return ne.evaluate("2 * a + b ** 10")
if __name__ == '__main__':
b = perfplot.bench(
setup=lambda n: (np.random.rand(n), np.random.rand(n)),
kernels=[
numpy_power,
numexpr_power,
],
n_range=[2 ** k for k in range(25)],
xlabel="length of DataFrame",
)
plt.figure(dpi=300)
b.save(f"arr_power.png")
b.show()
Pandas加减乘除
我们计算 (a + b) / (c - 1),发现在数据量较大时候,NumExpr明显快于Pandas
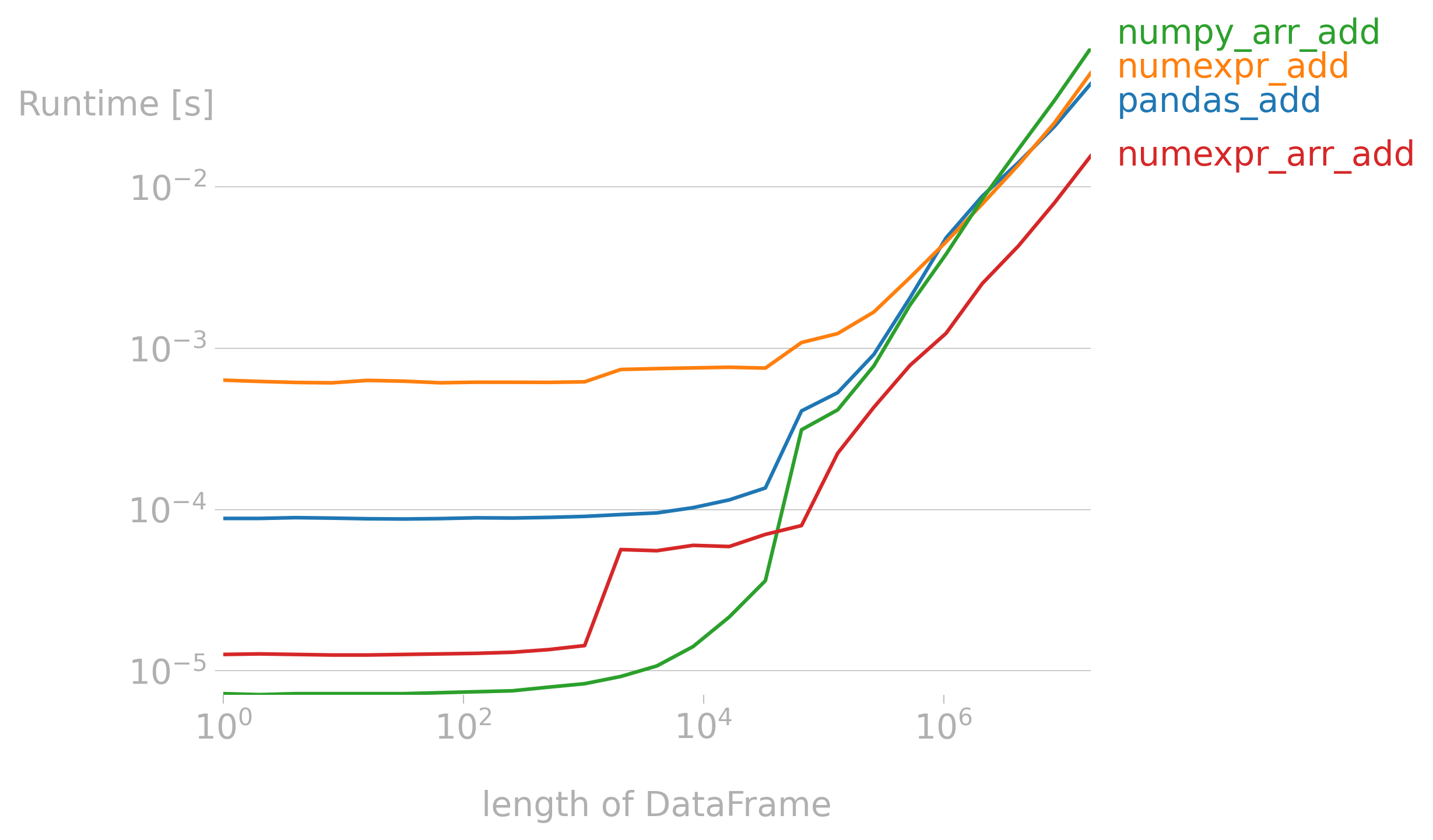
import pandas as pd
import perfplot
from matplotlib import pyplot as plt
from numpy.random._examples.cffi.extending import rng
import numexpr as ne
def pandas_add(df):
return (df['A'] + df['B']) / (df['C'] - 1)
def numexpr_add(df):
return df.eval('(A + B) / (C - 1)')
def numpy_arr_add(df):
a = df['A'].values
b = df['B'].values
c = df['C'].values
return (a + b) / (c - 1)
def numexpr_arr_add(df):
a = df['A'].values
b = df['B'].values
c = df['C'].values
return ne.evaluate("(a + b) / (c - 1)")
if __name__ == '__main__':
b = perfplot.bench(
setup=lambda n: pd.DataFrame(rng.random((n, 3)), columns=['A', 'B', 'C']),
kernels=[
pandas_add,
numexpr_add,
numpy_arr_add,
numexpr_arr_add,
],
n_range=[2 ** k for k in range(25)],
xlabel="length of DataFrame",
)
plt.figure(dpi=300)
b.save(f"pandas_add.png")
b.show()
总结
总体来说在大数据下会有多倍的性能提升。但我们也容易观察到,就算10e8量级的数据,进行一次运算的时间也不超过1秒。一般计算次数多,数据量大,对速度有要求的场景下可以使用。