[Java][算法 哈希]Day 01---LeetCode 热题 100---01~03
LeetCode 热题 100---01~03 ------->哈希
第一题 两数之和

思路
最直接的理解就是 找出两个数的和等于目标数 这两个数可以相同 但是不能是同一个数字(从数组上理解就是内存上不是同一位置)
解法一:暴力法
暴力解万物 按照需求 我们需要将数组的任意不同位置的数两两相加 再去判断是否等于目标数target 那么很显然 利用for循环的嵌套 第一层for循环从头遍历到尾 表示第一个数字 ;第二个数从第一个数的后一位置开始遍历到尾部,表示第二个数字
因为题目中明确说明了每种输入只会对应一个答案 所以找到之后就可以直接返回了
那么对应的代码就是
class Solution {
public int[] twoSum(int[] nums, int target) {
int n = nums.length;
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (nums[i] + nums[j] == target) {
return new int[]{i, j};
}
}
}
return new int[0];
}
}时间复杂度为O(N^2)
 解法二:双指针法
解法二:双指针法
上述时间复杂度之所以高 是因为我们查找第二个数采用的也是循环 就导致了循环的嵌套,如果想降低时间复杂度,那么就需要降低第二个数的查找时间
其实这个思路也比较简单 就是我们先将数组进行排序 保证从小到大/从大到小排序(这里我们排从小到大),那么 我们就可以最开始从数组最左侧A和最右侧B的两个数据开始相加得到sum 如果sum>target 那么说明我们需要讲两个加数变小,已知一个加数A已经是最小 那么只能让B往前走一位从而减小数据(当然 如果倒数第二个数据和最后一个数据等大 自然得出来的结果还是会大于target 但是不妨碍我们继续判断),反之 如果sum<target 那么就需要增大加数,只有加数A能够增大 所以就需要将加数A向右移动一位,依此类推,直到找到数据
class Solution {
public int[] twoSum(int[] nums, int target) {
ArrayList<Integer> list=new ArrayList<>();
for (int num : nums) {
list.add(num);
}
int[] dest = Arrays.copyOf(nums, nums.length);
Arrays.sort(dest);
int slow=0;int fast=nums.length-1;
while(slow!=fast){
int sum=dest[slow]+dest[fast];
if(sum==target){
int i = list.indexOf(dest[slow]);
int j = list.lastIndexOf(dest[fast]);
return new int[]{i,j};
}else if(sum<target){
slow++;
}else if(sum>target){
fast--;
}
}
return new int[]{};
}
}可以看到 时间复杂度确实变小了 但是变化不多

解法三:哈希
这才是这个题目的出题本意 使用Hash来进行判断
同解法二,我们需要的是减少第二个数字的查询时间,我们可以将每个数存入Hash表中,然后通过target-A=B来得到B 然后判断在Hash表中是否存在B即可 因为Hash的缘故 第二个数据被查询的时间减少了
因为要找寻的是下表 我们利用Map数据结构 数据作为Key 下标作为Value 这样我们就可以通过key来找到下标
那么我们遍历一遍数组 作为第一个数A 然后通过containsKey(T Key)方法来判断是否存在第二个数据B 如果存在 就直接通过get方法获得B的下标返回即可
如果不存在 就将该数放到Map中 之所以先判断后放入 是防止先放入之后 会出现自己和自己相加等于target的情况
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> hashtable = new HashMap<Integer, Integer>();
for (int i = 0; i < nums.length; ++i) {
if (hashtable.containsKey(target - nums[i])) {
return new int[]{hashtable.get(target - nums[i]), i};
}
hashtable.put(nums[i], i);
}
return new int[0];
}
}

第二题 字母异位词分组

思路
首先 字母异位词就是指 对一个单词重新排列顺序后 得到一个新的单词 在这个题目中 可以理解为 给你一个字符串数组 判断该数组中哪些元素是由同一些字母组成的
例如示例一 eat 和 ate 和tea 三个元素都是由 a e t 组合而成 所以他们三个归为一个数组中
如此一来 我们只需要想办法 将各个方式组成的元素 用不重复方法标识出来即可
最好的方法就是统计字母次数
解法一:编码-分类
我们对每一个元素遍历 然后利用 每个单词-‘a’ 得到ASCII码差值 对应一个int[26] 数组arr中的每一个数据,简单理解就是a对应arr[0] b对应arr[1]......以此类推 最后 由相同的字母组成的单词所得到的arr数据肯定相同 然后我们将arr转化为字符串String 作为标识的key value采用List<String> 将同一类的单词都存入到这个Map<String,List<String>> map=new HashMap<>()中即可
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> endList=new ArrayList<>();//最终返回的List
Map<String,List<String>> map=new HashMap<>();
// 遍历整个字符串数组进行操作
for (String str : strs) {
String code=getCode(str); // 求出每个元素对应的code 作为标识key
// 判断该key是否存在 如果存在 就放到对应的List中 反之 如不存在 就创造一个新的key并new一个新List将该元素放入
if(map.get(code)!=null){
map.get(code).add(str);
}else{
map.put(code,new ArrayList<>());
map.get(code).add(str);
}
}
//最后遍历整个Map 将value取出来即可
map.forEach((x,y)->endList.add(y));
return endList;
}
public static String getCode(String str){
char[] charArray = str.toCharArray();
int [] arr=new int[26];
for (char c : charArray) {
arr[c-'a']++;
}
return Arrays.toString(arr);
}
}
解法二:排序
如果两个单词是属于字母异位词,那么两者的字母组成肯定是相同的,如果字母组成是相同的,那么两者对内部单词进行同样的排序方式得到的结果也肯定是一样的,所以,我们需要对每个元素单词内部进行排序,然后将结果一样的放到一起即可
其实这种方法和上述的编码分类思想差不多,解法一是我们利用字母数量进行一个编码,我们解法二其实就是将排序后的结果作为标识编码来进行区分
class Solution {
public static List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> endList=new ArrayList<>();
Map<String,List<String>> map=new HashMap<String, List<String>>();
for(String x:strs) {
char[] arr=x.toCharArray();
Arrays.sort(arr);
String end=new String(arr);
if(map.containsKey(end)) {
map.get(end).add(x);
}else {
map.put(end,new ArrayList<String>());
map.get(end).add(x);
}
}
map.forEach((x,y)->{endList.add(y);});
return endList;
}
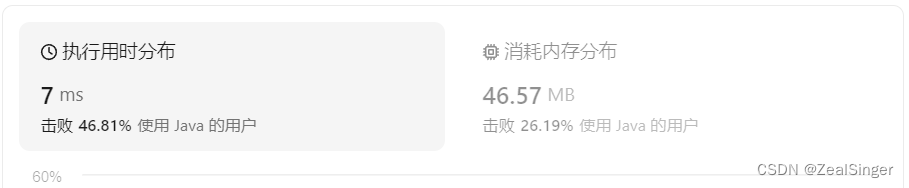
}
第三题 最长连续序列

思路
判断有无连续的序列,简单的方式就是遍历一遍,然后遍历每个数的时候,判断下一个数字是否等于前一个数字加一,等于的计数器+1,反之则归零
需要注意的是,需要考虑空数组,数组中存在相同元素的情况
解法一: 自己写的
我们自己的写法就是按照上述思路的遍历想法解题
class Solution {
public int longestConsecutive(int[] nums) {
if(nums.length==0) return 0; //空数组直接返回
LinkedHashSet<Integer> temp = new LinkedHashSet<>();
ArrayList<Integer> list=new ArrayList<>();
//我们需要set来去重 但是因为set本身是无序的 为了方便后续的比较后一位是否等于前一位加一
//就需要该集合是有序的 所以我们采用LinkedHashSet这种结构
for(int x=0;x<nums.length;x++){
temp.add(nums[x]);
}
//去重后用List存储 方便转数组
for (Integer i : temp) {
list.add(i);
}
Integer[] array = list.toArray(new Integer[0]);
int[] arr=new int[array.length];
for (int i = 0; i < array.length; i++) {
arr[i]=array[i];
}
int max=0;
int number=0;
Arrays.sort(arr);
for (int i = 1; i < arr.length; i++) {
//遍历数组 判断前一位和后一位是否连续 连续+1 反之归零
if(arr[i]==arr[i-1]+1){
number++;
}else{
if(number>max){
max=number;
}
number=0;
}
}
if(number>max){
max=number;
}
return max+1;
}
}可能会有疑问 为啥中间需要用List集合来转存一下 而不是直接Set集合temp转数组arr呢?其实也是可以的 对比两者 内存消耗和时间消耗其实差不多 temp直接转Array在某些特殊情况中会比List转Array是稍微多消耗一些资源的 所以哪怕第一段代码需要额外开销来转存到List中 但是单纯的开销空间来创造一个List和遍历集合消耗也不大
class Solution {
public int longestConsecutive(int[] nums) {
if(nums.length==0) return 0;
LinkedHashSet<Integer> temp = new LinkedHashSet<>();
for(int x=0;x<nums.length;x++){
temp.add(nums[x]);
}
Integer[] array = temp.toArray(new Integer[0]);
int[] arr=new int[array.length];
for (int i = 0; i < array.length; i++) {
arr[i]=array[i];
}
int max=0;
int number=0;
Arrays.sort(arr);
for (int i = 1; i < arr.length; i++) {
if(arr[i]==arr[i-1]+1){
number++;
}else{
if(number>max){
max=number;
}
number=0;
}
}
if(number>max){
max=number;
}
return max+1;
}
}
解法二:官方解法---Hash法
官方解法还是很巧妙的,我们采取遍历的方式来找,很容易重复遍历判断相同序列
由于我们要枚举的数 x 一定是在数组中不存在前驱数 x−1 的,不然按照上面的分析我们会从 x−1x-1x−1 开始尝试匹配,因此我们每次在哈希表中检查是否存在 x−1即能判断是否需要跳过了。
增加了判断跳过的逻辑之后,时间复杂度是多少呢?外层循环需要 O(n) 的时间复杂度,只有当一个数是连续序列的第一个数的情况下才会进入内层循环,然后在内层循环中匹配连续序列中的数,因此数组中的每个数只会进入内层循环一次。根据上述分析可知,总时间复杂度为 O(n)符合题目要求。
class Solution {
public int longestConsecutive(int[] nums) {
Set<Integer> num_set = new HashSet<Integer>();
for (int num : nums) {
num_set.add(num);
}
int longestStreak = 0;
for (int num : num_set) {
if (!num_set.contains(num - 1)) {
int currentNum = num;
int currentStreak = 1;
while (num_set.contains(currentNum + 1)) {
currentNum += 1;
currentStreak += 1;
}
longestStreak = Math.max(longestStreak, currentStreak);
}
}
return longestStreak;
}
}
