Golang 学习(二)进阶使用
二、进阶使用
性能提升——协程
GoRoutine
go f();
- 一个 Go 线程上,可以起多个协程(有独立的栈空间、共享程序堆空间、调度由用户控制)
- 主线程是一个物理线程,直接作用在 cpu 上的。是重量级的,非常耗费 cpu 资源。
- 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。

CSP并发模型
Java、C++、或者Python,他们线程间通信都是通过共享内存的方式来进行的。非常典型的方式就是,在访问共享数据(例如数组、Map、或者某个结构体或对象)的时候,通过锁来访问
Go:不要以共享内存的方式来通信,相反,要通过通信来共享内存
- goroutine 是Go语言中并发的执行单位
- channel是Go语言中各个并发结构体(goroutine)之前的通信机制
底层原理——MPG模型:
-
M指的是Machine,代表OS线程。它是由OS管理的执行线程,其工作方式与标准POSIX线程非常相似。在运行时代码中,它被称为M for machine。
-
P代表着处理器(processor),它的主要用途就是用来执行goroutine的,一个P代表执行一个go代码片段的基础(上下文环境),所以它也维护了一个可运行的goroutine队列,和自由的goroutine队列,里面存储了所有需要它来执行的goroutine。
-
G指的是Goroutine,代表一个goroutine。它包括堆栈,指令指针和其他对调度goroutine很重要的信息。
-
Seched代表着一个调度器,它维护有存储空闲的M队列和空闲的P队列,可运行的G队列,自由的G队列(全局runqueue)以及调度器的一些状态信息等。
操作系统会在物理处理器上调度线程来运行,而 Go 语言的运行时会在逻辑处理器上调度goroutine来运行。
p默认cpu内核数,M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,
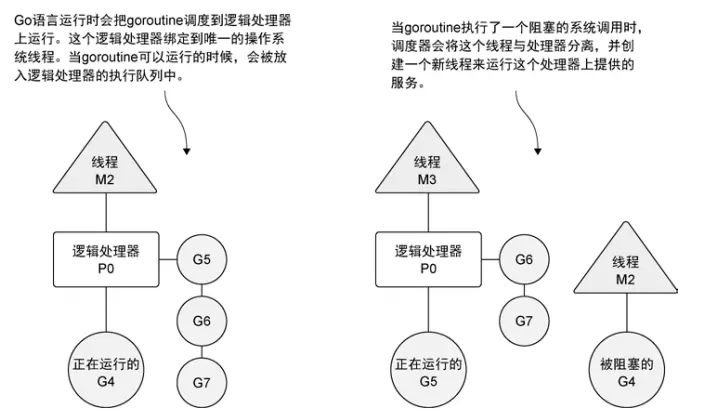
创建一个 goroutine 并准备运行,这个 goroutine 就会被放到调度器的全局运行队列中。之后,调度器就将这些队列中的 goroutine 分配给一个逻辑处理器,并放到这个逻辑处理器对应的本地运行队列中,本地运行队列中的 goroutine 会一直等待直到自己被分配的逻辑处理器执行。
当goroutine 需要执行一个阻塞的系统调用,如打开一个文件,线程和 goroutine 会从逻辑处理器上分离,该线程会继续阻塞,等待系统调用的返回。与此同时,这个逻辑处理器就失去了用来运行的线程。所以,调度器会创建一个新线程,并将其绑定到该逻辑处理器上。之后,调度器会从本地运行队列里选择另一个 goroutine 来运行。一旦被阻塞的系统调用执行完成并返回,对应的 goroutine 会放回到本地运行队列,而之前的线程会保存好,以便之后可以继续使用。
go的协程是非抢占式的,由协程主动交出控制权,也就是说,上面在发生IO操作时,并不是调度器强制切换执行其他的协程,而是当前协程交出了控制权,调度器才去执行其他协程。我们列举一下goroutine可能切换的点:
动态获取信息——反射
- 反射可以在运行时动态获取变量的各种信息, 比如变量的类型(type),类别(kind)
- 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)
- 通过反射,可以修改变量的值,可以调用关联的方法。
Type和Value:Kind是一个大的分类,比如定义了一个Person类,它的Kind就是struct 而Type的名称是Person,其中Value: 为go值提供了反射接口。
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
}
func test(i interface{}){
//获取指针指向的真正的数值Value
valueOfI := reflect.ValueOf(i).Elem()
//获取对应的Type这个是用来获取属性方法的
typeOfI := valueOfI.Type()
//判断是否是struct
if typeOfI.Kind()!=reflect.Struct{
fmt.Println("except struct")
return
}
//获取属性的数量
numField := typeOfI.NumField()
//遍历属性,找到特定的属性进行操作
for i:=0;i< numField;i++{
//获得属性的StructField,次方法不同于Value中的Filed(这个返回的是Field)
field := typeOfI.Field(i)
//获取属性名称
fieldName := field.Name
fmt.Println(fieldName)
//找到名为Name的属性进行修改值
if fieldName=="Name"{
//改变他的值为jack
valueOfI.Field(i).SetString("jack")
}
}
}
func main() {
stu:=Student{Name:"susan",Age:58}
test(&stu)
fmt.Println(stu.Name)
}
IO多路复用——select机制
select {
case <-chan1:
fmt.Println("chan1 ready.")
case <-chan2:
fmt.Println("chan2 ready.")
default:
fmt.Println("default")
}
每个线程或者进程都先到注册到相应的可接受 channel,然后阻塞,当注册的线程和进程准备好数据后,channel会得到相应的数据。
- 2)如果某个case中的channel已经ready,则执行相应的语句并退出select流程,否则:有default会走default然后退出select,没有default,select将阻塞直至channel ready;
- 3)每个 case 语句仅能处理一个管道,要么读要么写。
- 4)多个 case 语句的执行顺序是随机的。
- 5)存在 default 语句,select 将不会阻塞,但是存在 default 会影响性能。
- case后面不一定是读channel,也可以写channel,只要是对channel的操作就可以;空的select语句将被阻塞,直至panic;
使用场景:
2.1 超时控制
func (n *node) waitForConnectPkt() {
select {
case <-n.connected:
log.Println("接收到连接包")
case <-time.After(time.Second * 5):
log.Println("接收连接包超时")
n.conn.Close()
}
}
2.2 无阻塞获取值
func (w *wantConn) waiting() bool {
select {
case <-w.ready:
return false
default:
return true
}
}
2.3 类事件驱动循环
func (n *node) heartbeatDetect() {
for {
select {
case <-n.heartbeat:
// 收到心跳信号则退出select等待下一次心跳
break
case <-time.After(time.Second*3):
// 心跳超时,关闭连接
n.conn.Close()
return
}
}
}
延迟函数——defer
每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单连表,保存在 gotoutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果。
- 延迟函数执行按照后进先出的顺序执行,即先出现的 defer 最后执行。
- 延迟函数可能操作主函数的返回值。
- 申请资源后立即使用 defer 关闭资源是个好习惯。
上下文控制——Context
Go 的 Context 的数据结构包含 Deadline,Done,Err,Value,Deadline
- Deadline 方法返回一个 time.Time,表示当前 Context 应该结束的时间
- Done 方法当 Context 被取消或者超时时候返回的一个 close 的 channel,告诉给 context 相关的函数要停止当前工作然后返回了
- Err 表示 context 被取消的原因
- Value 方法表示 context 实现共享数据存储的地方,是协程安全的
应用:1:上下文控制,2:多个 goroutine 之间的数据交互等,3:超时控制:到某个时间点超时,过多久超时。
互斥锁——Mutex
1)正常模式
- 当前的mutex只有一个goruntine来获取,那么没有竞争,直接返回。
- 新的goruntine进来,如果当前mutex已经被获取了,则该goruntine进入一个先入先出的waiter队列,在mutex被释放后,waiter按照先进先出的方式获取锁。该goruntine会处于自旋状态(不挂起,继续占有cpu)。
- 新的goruntine进来,mutex处于空闲状态,将参与竞争。新来的 goroutine 有先天的优势,它们正在 CPU 中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的 waiter 可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果 waiter 获取不到锁的时间超过阈值 1 毫秒,那么,这个 Mutex 就进入到了饥饿模式。
2)饥饿模式
在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin(自旋),它会乖乖地加入到等待队列的尾部。 如果拥有 Mutex 的 waiter 发现下面两种情况的其中之一,它就会把这个 Mutex 转换成正常模式:
- 此 waiter 已经是队列中的最后一个 waiter 了,没有其它的等待锁的 goroutine 了;
- 此 waiter 的等待时间小于 1 毫秒。
问题
-
是否可以对Golang中的map元素取地址?
不可以,因为
map的元素可能会因为新元素的添加或者map的扩容而被移动,所以直接获取map元素的地址可能会引用到错误的元素。 -
Golang 调用函数传入结构体时,应该传值还是指针?
- 结构体的大小:如果结构体非常大,使用指针传递会更有效率,因为这样只会复制指针值(一般是8字节),而不是复制整个结构体。如果结构体小,值传递和指针传递的性能差异可能可以忽略不计。
- 是否需要修改原始结构体:如果你需要在函数中修改原始结构体,你应该使用指针传递。如果你使用值传递,函数会接收结构体的一个副本,你在函数中对结构体的修改不会影响到原始的结构体。
-
单引号,双引号,反引号的区别?
单引号,表示byte类型或rune类型,对应 uint8和int32类型,默认是 rune 类型。byte用来强调数据是raw data,而不是数字;而rune用来表示Unicode的code point。双引号,才是字符串,实际上是字符数组。可以用索引号访问某字节,也可以用len()函数来获取字符串所占的字节长度。反引号,表示字符串字面量,但不支持任何转义序列。字面量 raw literal string 的意思是,你定义时写的啥样,它就啥样,你有换行,它就换行。你写转义字符,它也就展示转义字符。
-
怎么控制并发数量?
有缓冲通道
func main() { count := 10 // 最大支持并发 sum := 100 // 任务总数 wg := sync.WaitGroup{} //控制主协程等待所有子协程执行完之后再退出。 c := make(chan struct{}, count) // 控制任务并发的chan defer close(c) for i:=0; i<sum;i++{ wg.Add(1) c <- struct{}{} // 作用类似于waitgroup.Add(1) go func(j int) { defer wg.Done() fmt.Println(j) <- c // 执行完毕,释放资源 }(i) } wg.Wait() }第三方协程池
import ( "log" "time" "github.com/Jeffail/tunny" ) func main() { pool := tunny.NewFunc(10, func(i interface{}) interface{} { log.Println(i) time.Sleep(time.Second) return nil }) defer pool.Close() for i := 0; i < 500; i++ { go pool.Process(i) } time.Sleep(time.Second * 4) }