transformer剪枝论文汇总
文章目录
- NN Pruning
- 摘要
- 实验
- 大模型剪枝
- LLM-Pruner
- SparseGPT
- LTP
- VTP
- Width & Depth Pruning
- Patch Slimming
- DynamicViT
- SPViT
- DynamicBERT
- ViT Slimming
- FastFormers
- NViT
- UVC
- Post-training pruning
NN Pruning
《Block Pruning For Faster Transformers》
《为更快的transformer进行块修剪》
摘要
预训练提高了模型在分类和生成任务的精度,但缺点是成本较高,性能慢;
剪枝是一种减少模型大小的有效方法;
论文引入了块剪枝方法,为了得到小且快的模型。通过将任意大小的块剪枝集成到运动剪枝微调范式中;
实验在分类和生成任务,得到剪枝后的模型2.4x更快,74%更小的BERT在SQuAD v1,F1仅下降1%,与其他蒸馏模型相比速度更快,与其他剪枝模型相比模型更小。
实验


论文地址
github地址1
github地址2
FFN剪枝 attention heads剪枝
大模型剪枝
LLM-Pruner
《LLM-Pruner: On the Structural Pruning of Large Language Models》
《LLM-Pruner: 大语言模型结构化剪枝》
github地址
SparseGPT
《SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot》
《SparseGPT:大规模语言模型可以一次精确剪枝》
github地址
LTP
《Learned Token Pruning for Transformers》
《transformer的Token修剪学习》
github地址
VTP
《Vision Transformer Pruning》
稀疏 剪枝 finetune
剪维度,Dimension Pruning
Width & Depth Pruning
《Width & Depth Pruning for Vision Transformers》
剪维度,剪深度
Patch Slimming
《 Patch Slimming for Efficient Vision Transformers》
《高效视觉transformer的块瘦身》
剪patch
DynamicViT
《DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification》
《DynamicViT:具有动态Token稀疏化的高效视觉transformer》
github地址
token 剪枝: 在MSA和MLP后面添加一个轻量化的注意力模块来动态的识别不重要的patch
SPViT
《Pruning Self-attentions into Convolutional Layers in Single Path》
《在Single Path中将自注意力剪枝成卷积层》
github地址
核心思想是nas,过预训练好的nsa的权重来初始化得到对应卷积的权重,达到一种权重共享的方法
DynamicBERT
《DynaBERT: Dynamic BERT with Adaptive Width and Depth》
《DynaBERT: 具有自适应宽度和深度的动态BERT》
github地址
深度 和宽度 剪枝;
训练时,对宽度和深度进行裁剪,训练不同的子网络
推理时,根据速度需要直接裁剪,用裁剪后的子网络进行预测
ViT Slimming
《Vision Transformer Slimming: Multi-Dimension Searching in continuous optimization space》
《视觉Transformer瘦身:连续优化空间中的多维搜索》
github地址
只需训练 / 搜索一次,就可以通过排序 mask 得到无数个子网络
FastFormers
《FastFormers: Highly Efficient Transformer Models
for Natural Language Understanding》
github 地址
step1:蒸馏
step2:剪枝
step3: 量化
NViT
《NViT: Vision Transformer Compression and Parameter Redistribution》
(2021)
剪枝规则分为三步:
- 确定剪枝的空间
- 通过建立全局重要性分数ranking,迭代地进行全局结构剪枝。
- 观察剪枝后网络结构的维度变化趋势,进行参数重分配,得到最终的NViT
UVC
《UNIFIED VISUAL TRANSFORMER COMPRESSION》
《统一视觉transformer压缩》
github地址
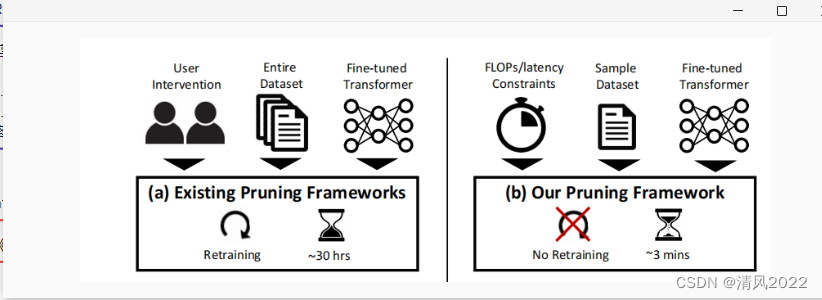
Post-training pruning
《A Fast Post-Training Pruning Framework for Transformers》
《transformer 快速后训练剪枝框架》
github地址