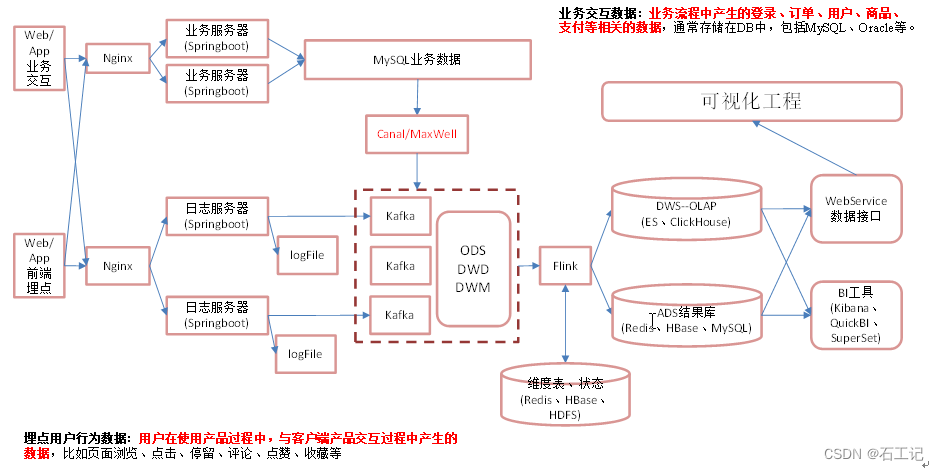
大数据模型、离线架构、实时架构
一.大数据模型
8种常见的大数据分析模型:1、留存分析模型;2、漏斗分析模型;3、全行为路径分析;4、热图分析模型;5、事件分析模型;6、用户分群模型;7、用户分析模型;8、黏性分析模型。
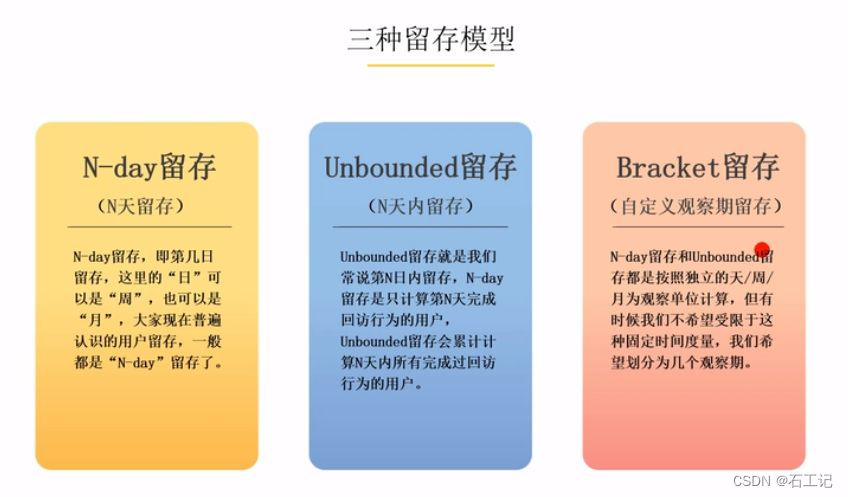
1、留存分析模型
留存分析模型是一种用来分析用户参与情况/活跃程度的分析模型,考察进行初始行为的用户中,有多少人会进行后续行为,这是用来衡量产品对用户价值高低的重要方法。
2、漏斗分析模型
漏斗分析是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型。运营人员可以通过观察不同属性的用户群体(如新注册用户与老客户、不同渠道来源的客户)各环节转化率,各流程步骤转化率的差异对比,了解转化率最高的用户群体,分析漏斗合理性,并针对转化率异常环节进行调整。
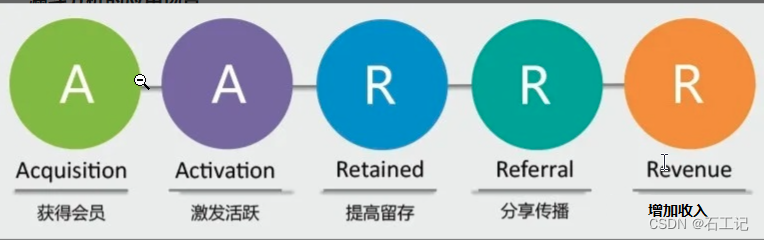
2.1 AARRR
从用户增长各阶段入手,包括Acquisition用户获取,Activation用户激活,Retention用户留存,Revenue用户产生收入,Refer自传播。改模型主要应用于互联网行业
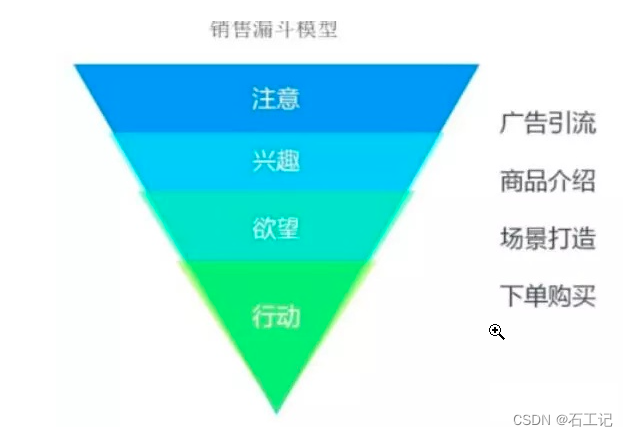
2.2 销售漏斗模型
一般用于页面结构和内容较为复杂的业务,从用户内容消费和流量走向的角度,宏观层面用于回答用户消费什么内容,微观层面则用于分析影响用户消费的问题是什么。主要流程是从广告引流—商品介绍—场景打造—下单购买
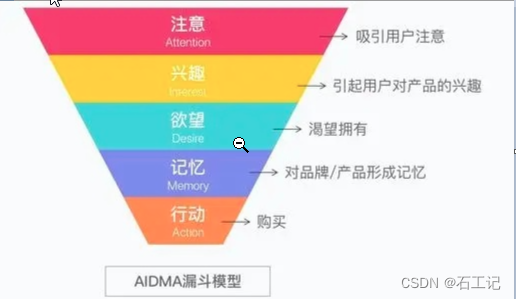
2.3 AIDMA模型
主要的流程是注意 → 兴趣 → 欲望 → 记忆 → 行动(购买),适用于品牌营销
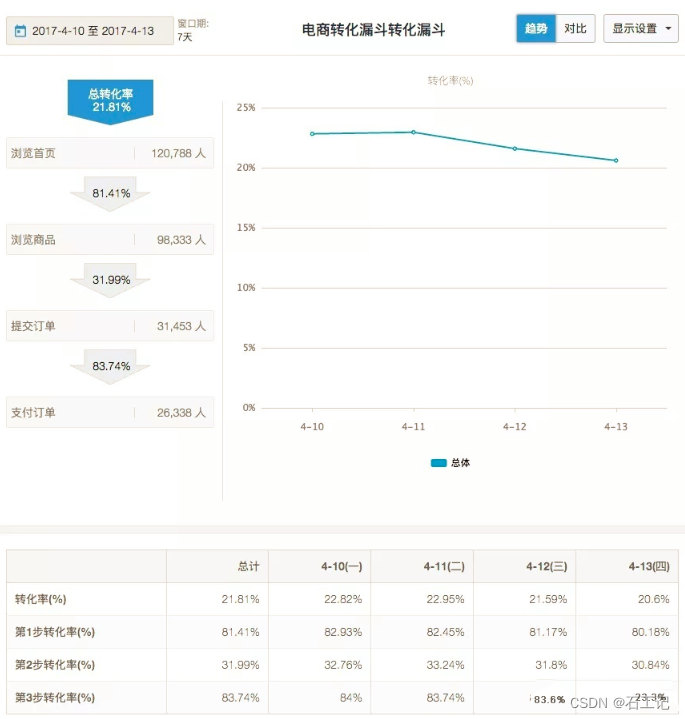
2.3 电商漏斗模型:
典型的用户购买行为由以下连续的行为构成:浏览首页—浏览商品—提交订单—支付订单。
当我们期望观察各步骤间及总体转化率,可按以下步骤进行:
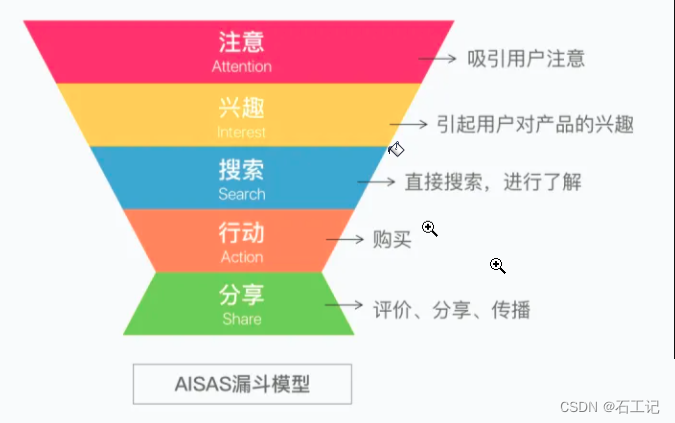
2.4 AISAS模型::主要的流程是注意-兴趣-搜索-行动-分享,在AIDMA模型的基础上增加了用户反馈的环节
3、全行为路径分析
全行为路径分析是互联网产品特有的一类数据分析方法,它主要根据每位用户在APP或网站中的行为事件,分析用户在APP或网站中各个模块的流转规律与特点,挖掘用户的访问或浏览模式,进而实现一些特定的业务用途,如对提升APP核心模块的到达率、提取出特定用户群体的主流路径与刻画用户浏览特征,优化与提升APP的产品设计等。

4、热图分析模型
热图分析模型,其实就是指页面点击分析,与一般热力图不同的是,页面点击分析主要应用于用户行为分析领域,分析用户在网站显示页面(比如官网首页)的点击行为、浏览次数、浏览时长等,以及页面区域中不同元素的点击情况,包括首页各元素点击率、元素聚焦度、页面浏览次数和人数以及页面内各个可点击元素的百分比等等。
5、事件分析模型
事件分析模型是针对用户行为的分析模型之一,也是用户行为数据分析的核心和基础。用户在产品上的行为我们定义为事件,它是用户行为的一个专业描述,用户在产品上的所有获得的程序反馈都可以抽象为事件进行采集。
6、用户分群模型
产品运营一段时间和投方推广一段时间后,随着用户的留存和新增,用户数量越来越多,那么我们就需要对用户进行精细化运营,用户分群能帮助企业更加了解用户,分析用户的属性特征、以及用户的行为特征,可以帮助运营人员更好地对比多个用户群的数据,找到产品问题背后的原因,并有效改进优化方向。
7、用户分析模型
用户分析模型是基础的分析模型。使用DataFocus数据分析工具,打通CRM数据、历史数据、业务数据以及第三方数据,通过查看用户数量在注册时间上的变化趋势、查看用户按省份的分布情况等等,丰富用户画像维度。将所有维度分析放到同一个可视化大屏中,通过联动、钻取功能,动态化实时查看数据变动,让用户行为洞察粒度更细致。
8、黏性分析模型
黏性分析是在留存分析的基础上,对一些用户指标进行深化,除了一些常用的留存指标外,黏性分析能够从更多维度了解产品或者某功能黏住用户的能力情况,更全面地了解用户如何使用产品,新增什么样的功能可以提升用户留存下来的欲望,不同用户群体之间存在什么样的差异,不同用户对新增的功能有何看法。
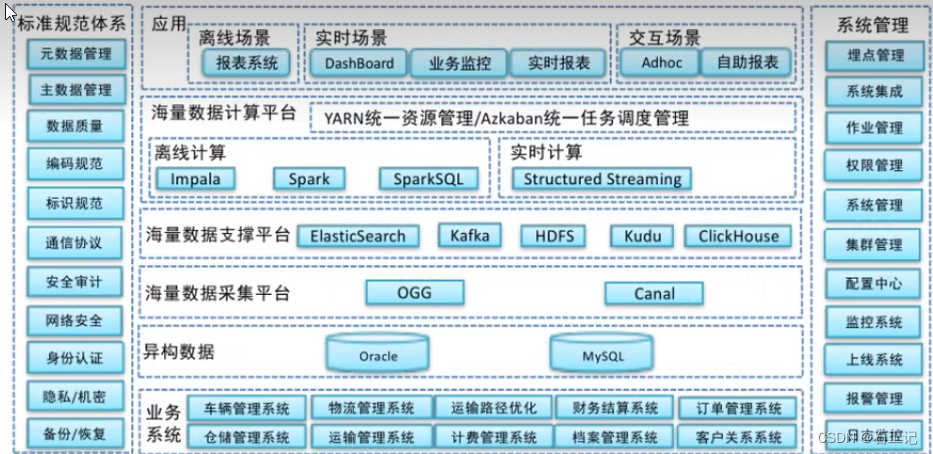
二、逻辑架构图
1.总架构图
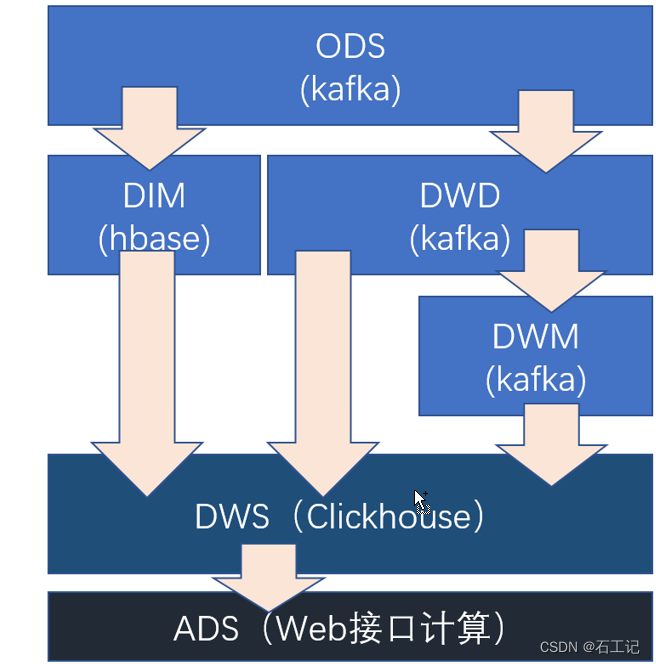
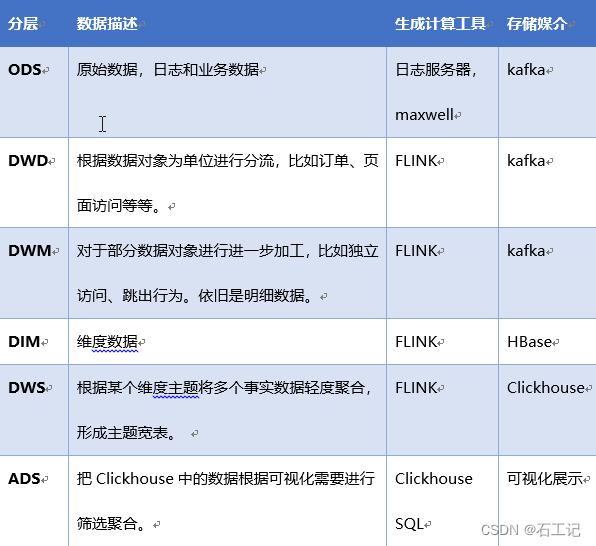
2.案例:亿级的物流大数据逻辑架构图
数据流转图
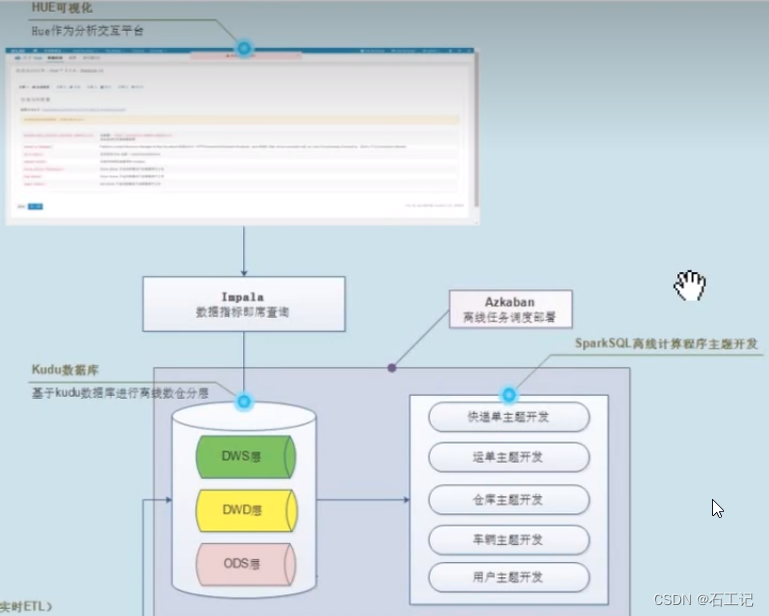
三.离线架构
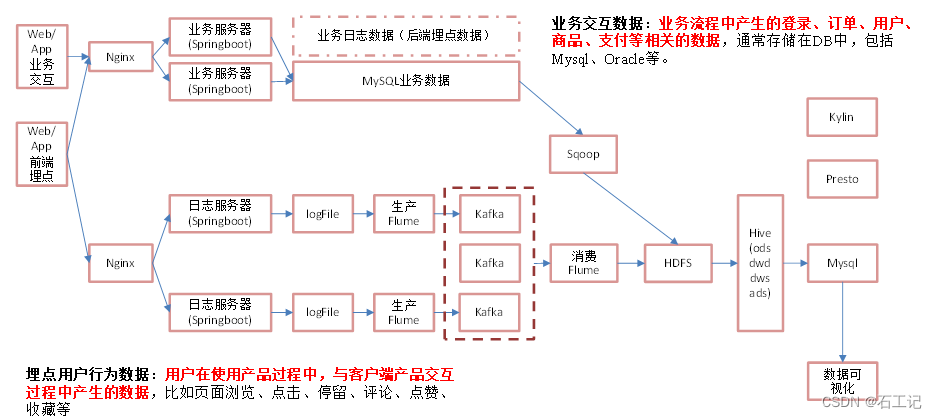
四、.实时架构
五、选型
1.架构选型
针对每个项目来说,要清楚一点,技术框架选择(为什么选择)。
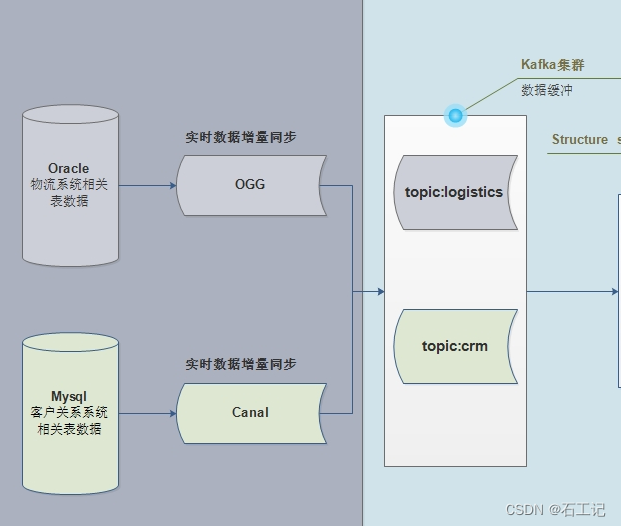
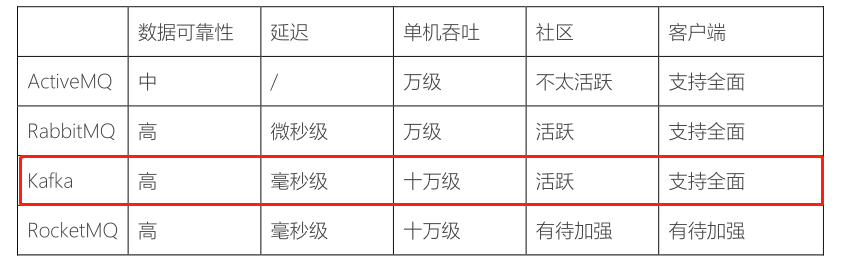
- 1)、流式处理平台:采用Kafka作为消息传输中间介质 在大数据领域中,主要是实时数据分析,实时数据ETL转换等等,基本上都是从Kafka消费数据。
- 2)、分布式计算平台:分布式计算采用Spark生态 在大数据分析中,可以使用Spark解决问题,就不要考虑Flink框架。
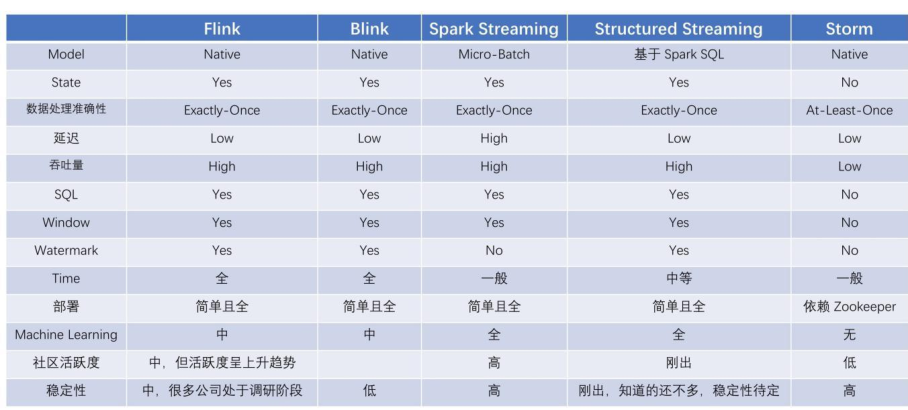
本项目使用Structured Streaming开发实时部分,同时离线计算使用到SparkSQL,而Spark的生态相对于Flink更加成熟,因此采用Spark开发。
为什么不使用SparkStreaming进行实时数据ETL转换存储呢??而是使用StructuredStreaming...
- 3)、海量数据存储
- ETL后的数据存储到Kudu中,供实时、准实时查询、分析 Kudu数据库,提供HBase数据库:随机读写数据;提供HDFS文件系统功能:批量快速加载数据

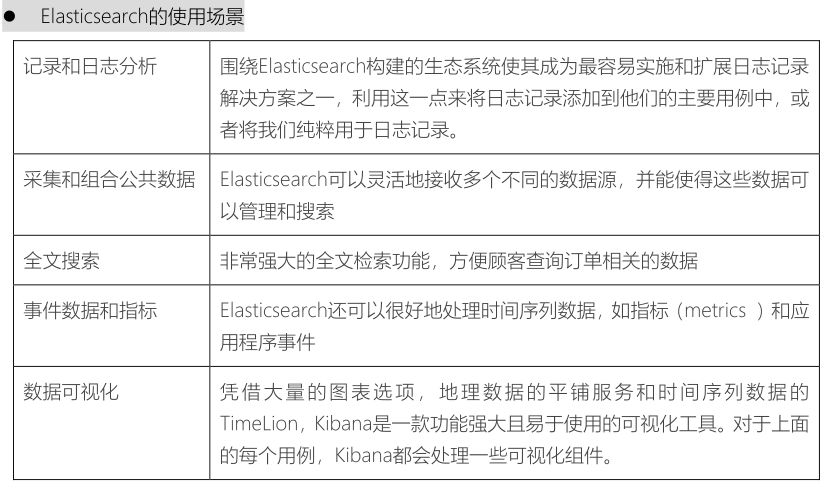
- Elastic Search作为单据数据的存储介质,供顾客查询订单信息
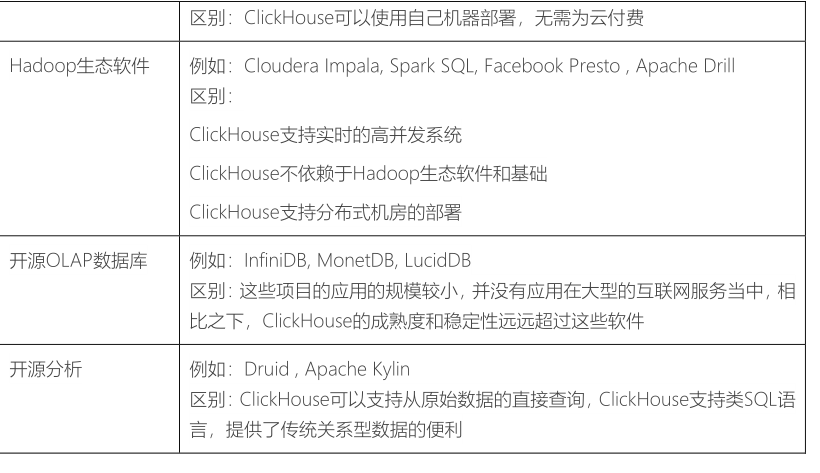
框架软件版本:主要基于
CDH 6.2.1版本(版本较新),将来编写简历时,此版本不可用 使用CM安装CDH,采集单机部署,提供node2.itcast.cn虚拟机上,全部安装完毕,无需到操作。

新框架:Kudu和Impala都属于CDH产品,由于都是Cloudera公司开发的框架。
2.服务器选型
- 1)、框架版本选型

- 2)、服务器选型
不差钱,金融相关公司,使用物理机最好。

- 3)、集群规模
数据量:物流项目来说,核心数据【快递单】和【运单】等相关数据

- 4)、集群资源如下图所示
在实际项目,服务器来说,系统盘(安装操作系统)和数据盘(存储数据)时分开的,

- 5)、人员配置参考

- 6)、开发周期
