Java 集合、迭代器
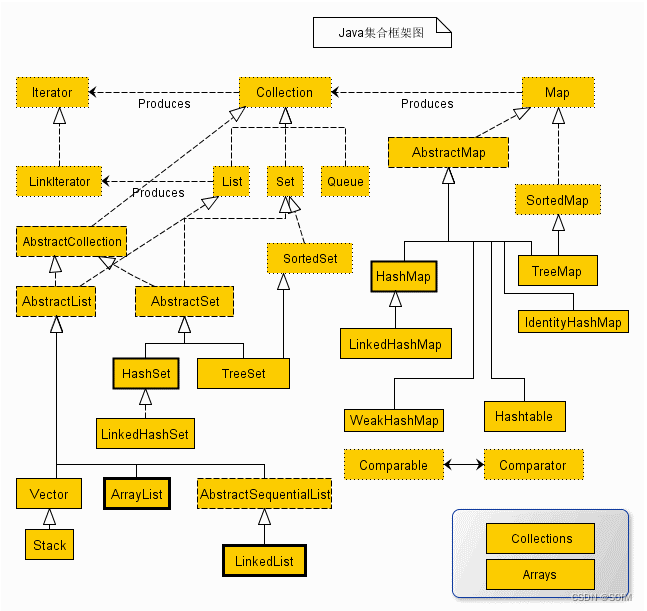
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
| 序号 | 接口描述 |
| 1 | Collection Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。 Collection 接口存储一组不唯一,无序的对象。 |
| 2 | List List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。 List 接口存储一组不唯一,有序(插入顺序)的对象。 |
| 3 | Set Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。 Set 接口存储一组唯一,无序的对象。 |
| 4 | SortedSet 继承于Set保存有序的集合。 |
| 5 | Map Map 接口存储一组键值对象,提供key(键)到value(值)的映射。 |
| 6 | Map.Entry 描述在一个Map中的一个元素(键/值对)。是一个 Map 的内部接口。 |
| 7 | SortedMap 继承于 Map,使 Key 保持在升序排列。 |
| 8 | Enumeration 这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器取代。 |
常用集合:
Collection :
-List 接口:元素按进入先后有序保存,可重复,插入删除会引起其他元素位置改变
-----LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
-----ArrayList 底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
-----Vector 底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
------------Stack 是Vector类的实现类
-Set 接口: 仅接收一次,无序不可重复,并做内部排序,插入和删除不会引起元素位置改变
-----HashSet 使用hash表(数组)存储元素
------------LinkedHashSet 链表维护元素的插入次序
-----TreeSet 底层实现为二叉树,元素排好序Map :
-----Hashtable 接口实现类, 同步, 线程安全
-----HashMap 接口实现类 ,无同步, 线程不安全
------------LinkedHashMap 双向链表和哈希表实现
------------WeakHashMap
-----TreeMap 红黑树对所有的key进行排序
-----IdentifyHashMap
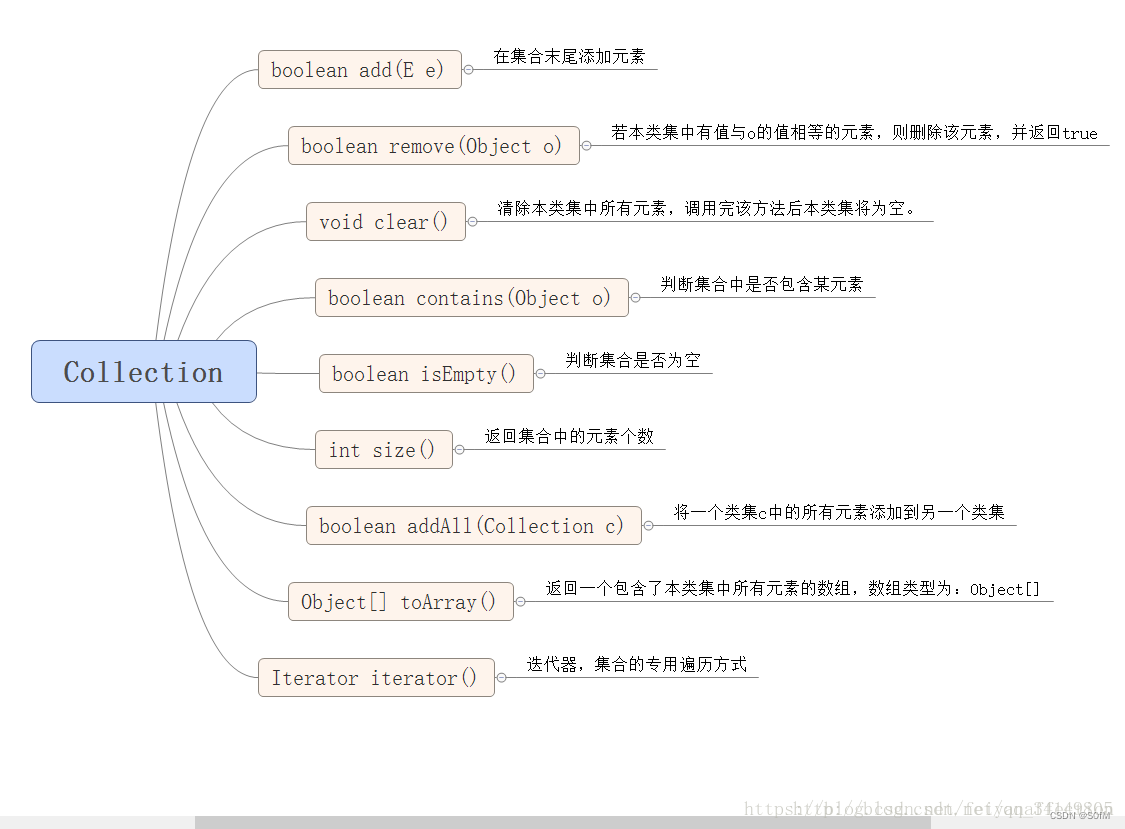
一、Collection

1.1 Java List
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
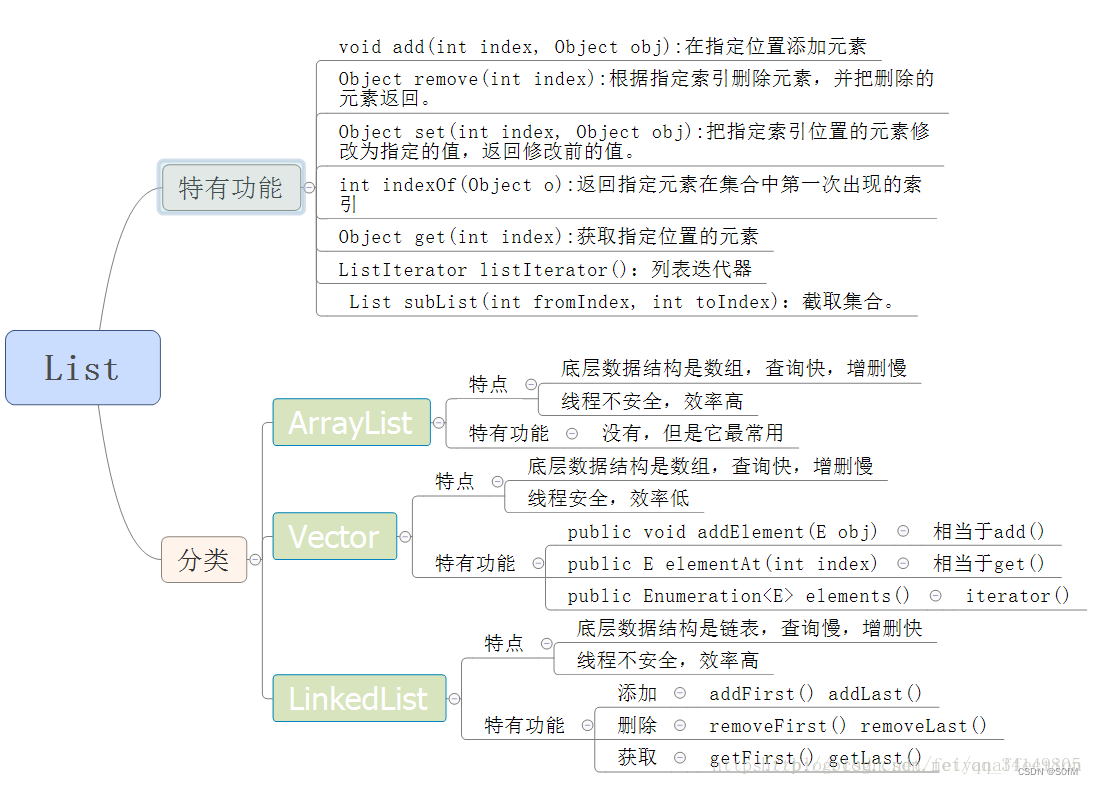
1.1.1 ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
import java.util.*;
public class RunoobTest {
public static void main(String[] args) {
ArrayList<String> sites = new ArrayList<String>();
sites.add("Google");
sites.add("Runoob"); //1、添加:元素到sites对象中
sites.set(0,"Yahu"); //2、第一个参数为索引位置,第二个为要修改的值、
sites.remove(1); //3、删除第2个元素
System.out.println(sites.size()); //4、输出对象长度
for (int i = 0; i < sites.size(); i++) { //5、for循环迭代输出
System.out.println(sites.get(i));
}
for (String i : sites) { //6、for-each循环迭代输出
System.out.println(i);
}
ArrayList<Integer> li=new ArrayList<>(); //7、存放整数元素
Collections.sort(sites); //8、Collections类中sort() 方法可以对字符或数字列表进行排序排序
System.out.println(sites);
}
}常规方法:
| 方法 | 描述 (arraylist对象:arr) |
| add() | 将元素插入到指定位置的 arraylist 中 |
| addAll() | 添加集合中的所有元素到 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist ArrayList<String> arrs = (ArrayList<String>)arr.clone(); |
| contains() | 判断元素是否在 arraylist |
| get() | 通过索引值获取 arraylist 中的元素 |
| indexOf() | 返回 arraylist 中元素的索引值 |
| removeAll() | 删除存在于指定集合中的 arraylist里的所有元素 |
| remove() | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList() | 截取部分 arraylist 的元素 sites.subList(1, 3);//截取第一个和第二个元素 |
| set() | 替换 arraylist 中指定索引的元素 |
| sort() | 对 arraylist 元素进行排序 |
| toArray() | 将 arraylist 转换为数组 |
| toString() | 将 arraylist 转换为字符串 |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 int position = arr.lastIndexOf("YL"); |
| ensureCapacity() | 设置指定容量大小的 arraylist lastIndexOf() 返回指定元素在 arraylist 中最后一次出现的位置 |
| retainAll() | 保留 arraylist 中在指定集合中也存在的那些元素 arr.retainAll(arr2); |
| containsAll() | 查看 arraylist 是否包含指定集合中的所有元素 boolean result = arr.containsAll(arr2); |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 arr.trimToSize(); |
| removeRange() | 删除 arraylist 中指定索引之间存在的元素 arr.removeRange(1, 3); |
| replaceAll() | 将给定的操作内容替换掉数组中每一个元素 arr.replaceAll(e -> e.toUpperCase()); |
| removeIf() | 删除所有满足特定条件的 arraylist 元素 arr.removeIf(e -> e.contains("Tao")); |
| forEach() | 遍历 arraylist 中每一个元素并执行特定操作 :将ArrayList对象的表达式作为 forEach() 方法的参数传入,lambda 表达式将动态数组中的每个元素乘以 10,然后输出结果 arr.forEach((e) -> { |
实例:
import java.util.*;
//遍历ArrayList
public class Test{
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HA");
//第一种遍历:使用 For-Each 遍历 List
for (String str : list) { //也可以改写for(int i=0;i<list.size();i++) 这种形式
System.out.println(str);
}
//第二种遍历:把链表变为数组相关的内容进行遍历
String[] strArray=new String[list.size()];
list.toArray(strArray);
for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历:使用迭代器进行相关遍历
Iterator<String> ite=list.iterator();
while(ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
}
}
//[Hello,World,HA]1.1.2 LinkedList
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
// 引入 LinkedList 类
import java.util.LinkedList;
public class RunoobTest {
public static void main(String[] args) {
LinkedList<String> sites = new LinkedList<String>();
sites.add("Google");//1、添加元素
sites.add("Runoob");
//2、使用 addFirst() 在头部添加元素
sites.addFirst("BaiDu");
//3、尾部添加
sites.addLast("Wiki");
//4、使用 removeFirst() 移除头部元素
sites.removeFirst();
//5、使用 removeLast() 移除尾部元素
sites.removeLast();
//6、使用 getFirst() 获取头部元素
System.out.println(sites.getFirst());
//7、使用 getLast() 获取尾部元素
System.out.println(sites.getLast());
//9、迭代获取元素
for (int size = sites.size(), i = 0; i < size; i++) {
System.out.println(sites.get(i));
}
//10、for-each 迭代
for (String i : sites) {
System.out.println(i);
}
//11、foreach遍历方式
sites.forEach(ites->{
System.out.println(ites);
});
System.out.println(sites);
}
}| 方法 | 描述 |
|---|---|
| public boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public void add(int index, E element) | 向指定位置插入元素。 |
| public boolean addAll(Collection c) | 将一个集合的所有元素添加到链表后面,返回是否成功,成功为 true,失败为 false。 |
| public boolean addAll(int index, Collection c) | 将一个集合的所有元素添加到链表的指定位置后面,返回是否成功,成功为 true,失败为 false。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public void clear() | 清空链表。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E poll() | 删除并返回第一个元素。 |
| public E remove() | 删除并返回第一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E get(int index) | 返回指定位置的元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
| public int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| public int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| public E peek() | 返回第一个元素。 |
| public E element() | 返回第一个元素。 |
| public E peekFirst() | 返回头部元素。 |
| public E peekLast() | 返回尾部元素。 |
| public E set(int index, E element) | 设置指定位置的元素。 |
| public Object clone() | 克隆该列表。 |
| public Iterator descendingIterator() | 返回倒序迭代器。 |
| public int size() | 返回链表元素个数。 |
| public ListIterator listIterator(int index) | 返回从指定位置开始到末尾的迭代器。 |
| public Object[] toArray() | 返回一个由链表元素组成的数组。 |
| public T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
使用较少,类比ArrayList,不举例。
1.1.3 Vector
Vector是一种老的动态数组,是线程同步的,效率很低,一般不使用。
1.2 Java Set
1.2.1 HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。HashSet 允许有 null 值,是无序的,即不会记录插入的顺序。HashSet 非线程安全, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的,在多线程访问时必须显式同步对 HashSet 的并发访问。
// 引入 HashSet 类
import java.util.HashSet;
public class RunoobTest {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Runoob");
sites.add("Taobao");
sites.add("Zhihu");
sites.add("Runoob"); //1、重复的元素不会被添加
System.out.println(sites.contains("Taobao"));//2、判断元素是否存在于集合当中
sites.remove("Taobao"); //3、删除元素,删除成功返回 true,否则为 false
sites.clear();//4、清除全部
for (String i : sites) { //5、for-each 迭代
System.out.println(i);
}
/*6、注意:Set无序,无法使用元素下标输出元素遍历集合
for (int size = sites.size(), i = 0; i < size; i++)*/
//7、foreach遍历方式
sites.forEach(ites->{
System.out.println(ites);
});
System.out.println(sites);
}
}1.2.2 LinkedHashSet
底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
1.2.3 TreeSet
底层数据结构采用二叉树来实现,元素唯一且已经排好序。
二、Map
2.1 Java Map
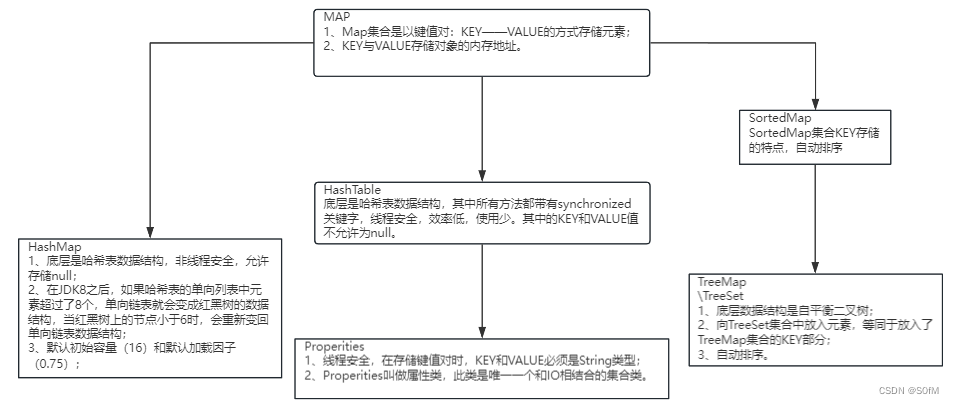
2.1.1 HashMap
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashMap 是无序的,即不会记录插入的顺序。HashMap 的 key 与 value 类型可以相同也可以不同,可以是字符串(String)类型的 key 和 value,也可以是整型(Integer)的 key 和字符串(String)类型的 value。HashMap 中的元素是对象,一些常见的基本类型可以使用它的包装类。
// 引入 HashMap 类
import java.util.HashMap;
public class RunoobTest {
public static void main(String[] args) {
//1、创建 HashMap 对象 Sites
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
Sites.put(1, "Google");
Sites.put(2, "Runoob");
Sites.put(3, "Taobao");
Sites.put(4, "Zhihu");
System.out.println(Sites);
//2、输出元素{1=Google, 2=Runoob, 3=Taobao, 4=Zhihu}
System.out.println(Sites.get(3));//输出Taobao
for (Integer i : Sites.keySet()) {
System.out.println("key: " + i + " value: " + Sites.get(i));
}
//3、返回所有 value 值
for(String value: Sites.values()) {
//4、输出每一个value
System.out.print(value + ", ");
//5、使用Entry对象遍历
Map<String, Integer> map = new HashMap<>();
map. put("yly", 177);
map. put("yrc" ,176);
map. put("zcz" ,175);
Set<Map.Entry<String, Integer>> set = map.entrySet();
//for迭代遍历
for (Map.Entry<String, Integer> entry : set) {
System.out.println(entry.getKey()+entry.getValue());
}
}
}
}
}
| 方法 | 描述 /*HashMap<String, Integer> prices = new HashMap<>(); |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中,已存在的将会被替换 |
| putIfAbsent() | 如果 hashMap 中不存在指定的key键,则将指定的键/值对插入到 hashMap 中 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系 |
| replace() | 替换 hashMap 中指定的 key 对应的 value // 替换key为2的映射 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果 |
| get() | 获取指定 key 对应的 value |
| getOrDefault() | 获取指定 key 对应的 value,如果找不到 key ,则返回设置的默认值 // Not Found - 如果 HashMap 中没有该 key,则返回默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作 prices.forEach((key, value) -> { |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图 System.out.println("sites HashMap: " + sites); /*sites HashMap: {1=Google, 2=Runoob, 3=Taobao} |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图 |
| values() | 返回 hashMap 中存在的所有 value 值 |
| merge() | 添加键值对到 hashMap 中,如果原来有那就是更新键值对 int returnedValue = prices.merge("Shirt", 100, (oldValue, newValue) -> oldValue + newValue); |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 int newPrice = prices.compute("Shoes", (key, value) -> value - value * 10/100); /*HashMap: {Pant=150, Bag=300, Shoes=200} |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 int shoesPrice = prices.computeIfPresent("Shoes", (key, value) -> value + value * 10/100); /*HashMap: {Pant=150, Bag=300, Shoes=200} |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中 /*HashMap: {Pant=150, Bag=300, Shoes=200} |
2.1.2 HashTable(略)
2.1.1 TreeMap(略)
三、迭代器 (Iterator)
Java迭代器是 Java 集合框架中的一种机制,是一种用于遍历集合(如列表、集合和映射等)的接口。它提供了一种统一的方式来访问集合中的元素,而不需要了解底层集合的具体实现细节。迭代器不是一个集合,它是一种用于访问集合的方法。以下图示主要方法。
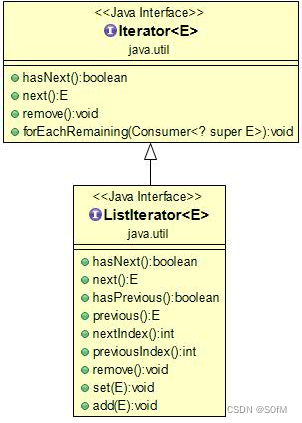
//主要是作为循环和遍历
import java.util.ArrayList;
import java.util.Iterator;
public class RunoobTest {
public static void main(String[] args) {
// 创建集合
ArrayList<Integer> sites = new ArrayList<Integer>();
sites.add("1");
sites.add("2");
sites.add("3");
sites.add("4");
// 获取迭代器
Iterator<Integer> it = sites.iterator();
// 输出集合中的第一个元素
System.out.println(it.next());//1
// 输出集合中的所有元素
while(it.hasNext()) {
System.out.print(it.next());
}//1 2 3 4
for(Integer i:sites){
System.out.print(i+" ");
}//1 2 3 4
while(it.hasNext()) {
Integer i = it.next();
if(i < 10) {
it.remove(); //删除小于 10 的元素
}
System.out.println(sites);//[]
}
/*注意:Java 迭代器是一种单向遍历机制,即只能从前往后遍历集合中的元素,不能往回遍历。同时,在使用迭代器遍历集合时,不能直接修改集合中的元素,而是需要使用迭代器的 remove() 方法来删除当前元素*/
}import java.util.ArrayList;
import java.util.Iterator;
public class Person(String name) {
private String name;
public void setName(String name){
this.name = name;}
public String getName(){
return name;}
}
public class test {
public static void main(String[] args) {
ArrayList<Person> array = new ArrayList<Person>();
Person p1 = new Person("Y");
Person p2 = new Person("L");
Person p3 = new Person("Y");
Person p4 = new Person("G");
array.add(p1);
array.add(p2);
array.add(p3);
array.add(p4);
Iterator<Person> iterator = array.iterator();
for (Person pp : array){
System.out.print(pp.getName());//Y L Y G
}
array.forEach(obj -> System.out.print(obj.getName()));//Y L Y G
for(Person p : array){
p.setName("B");
}
while(iterator.hasNext()){
System.out.print(iterator.next().getName()); //B B B B
}
}
}
参考资料:菜鸟教程 - 学的不仅是技术,更是梦想!
参考文献1:详解java集合,Collection,list,set,map汇总 - 知乎 (zhihu.com)
参考文献2:java集合超详解_java集合使用-CSDN博客
参考文献4:Java迭代器(iterator详解以及和for循环的区别)_java里迭代器能在for循环中使用么-CSDN博客