使用R语言fifer包进行分层采样
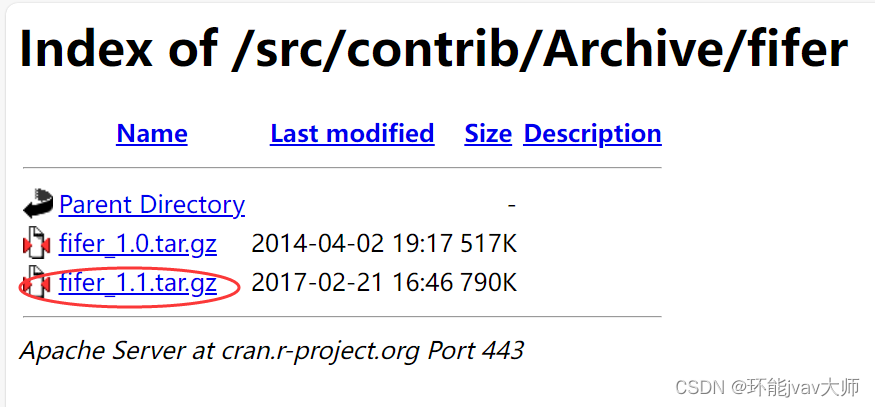
使用R语言fifer包中的stratified()函数用来进行分层采样非常方便,但fifer包已经从CRAN存储库中删除,需要从存档中下载可用的历史版本,下载链接:Index of /src/contrib/Archive/fifer (r-project.org)![]() https://cran.r-project.org/src/contrib/Archive/fifer/
https://cran.r-project.org/src/contrib/Archive/fifer/
随后下载devtools包用以辅助安装和管理R包:
install.packages("devtools")devtools包安装完成,然后将fifer包解压并放到R语言安装路径中的library文件夹里,随后在终端输入以下代码并修改成自己的安装路径:
devtools::install_local("C:/Program Files/R/R-4.3.2/library/fifer",force = TRUE)随后使用R自带的iris数据集进行测试:
iris.df <- data.frame(iris)
#建立iris的子集检索,并进行随机采样
sample.index <- sample(1:nrow(iris.df), nrow(iris) * 0.75,
replace = FALSE)
#把replace设置为FALSE,这样就不会重复抽取到该列数据
在Environment栏及终端查看irisa数据与随机抽选出来的数据:
> head(iris[sample.index, ])
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
146 6.7 3.0 5.2 2.3 virginica
56 5.7 2.8 4.5 1.3 versicolor
131 7.4 2.8 6.1 1.9 virginica
65 5.6 2.9 3.6 1.3 versicolor
71 5.9 3.2 4.8 1.8 versicolor
16 5.7 4.4 1.5 0.4 setosa查看iris数据集的数据分布情况:
> summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50 使用stratified()函数进行分层采样,针对iris数据集中方差最小的特征Sepal.Width和Petal.Width,选取70%采样:
> summary(stratified(iris, c("Sepal.Width", "Petal.Width"), 0.7))
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.400 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.250 Median :1.300
Mean :5.861 Mean :3.053 Mean :3.804 Mean :1.222
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.125 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :37
versicolor:38
virginica :41 最后编写函数,按照给定的随机初始数字依次选择每个第n行,用以系统采样:
> sys.sample = function(N, n) {
+ k = ceiling(N/n)
+ r = sample(1:k, 1)
+ sys.samp = seq(r, r+k*(n-1), k)
+ }
#Windows环境下的RStudio终端可以使用Shift+Enter换行
> systematic.index <- sys.sample(nrow(iris), nrow(iris) * 0.75)
> summary(iris[systematic.index, ])
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.200 Min. :1.10 Min. :0.10
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.55 1st Qu.:0.35
Median :5.700 Median :3.000 Median :4.20 Median :1.30
Mean :5.847 Mean :3.051 Mean :3.74 Mean :1.18
3rd Qu.:6.400 3rd Qu.:3.250 3rd Qu.:5.10 3rd Qu.:1.80
Max. :7.900 Max. :4.400 Max. :6.70 Max. :2.50
NA's :37 NA's :37 NA's :37 NA's :37
Species
setosa :25
versicolor:25
virginica :25
NA's :37