如何保存缓存和MySQL的双写一致呢?

如何保存缓存和MySQL的双写一致呢?

所谓的双写一致指的是,在同时使用缓存(如Redis)和数据库(如MySQL)的场景下,确保数据在缓存和数据库中的更新操作保持一致。当对数据进行修改的时候,无论是先修改缓存还是先修改数据库,最终都要保证两者的数据状态一致。
保持一致的方案一般有四种:
1.先修改数据库,再修改缓存
2.先修改缓存,再修改数据库
3.先修改数据库,再删除缓存
4.先删除缓存,再修改数据库
前三种解决方案,有一个问题,也就是当第一次操作执行完成之后,第二步未执行的情况下,就会导致数据库和缓存不一致的问题,比如第一步执行完了,然后系统掉电了,那么一致性问题就会显现出来了。
然而,第四种解决方案,在第一步执行完了,如果掉电了,最起码数据库和缓存都没执行成功呢,数据都不是最新的呢,从数据一致性的层面来讲,确实一致了,但是第四种还有如下问题:
1.业务完整性:第一步完成了,但是掉电或者死机了,第二步没执行。
2.并发保存后缓存旧值问题:比如以下情况
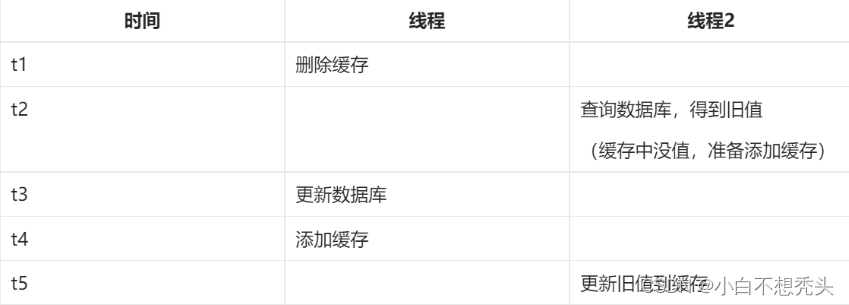
所以最好的解决办法就是:
先删除缓存,再修改数据库,并且组合上消息队列(针对问题1)和延迟双删(针对问题2)
为啥使用消息队列呢?
消息确认机制允许接收消息的程序(消费者)在完成消息处理之后明确地告知消息队列系统:“我已经处理了这条消息。”这个确认过程是至关重要的,因为它让消息队列系统知道该消息是否已被成功消费。如果消费者在处理消息过程中发生故障(如掉电或重启),消息队列会根据消费者是否已确认消息来决定下一步的行动:
如果消息未被确认,消息队列系统将认为该消息尚未被完全处理,因此在消费者恢复后会再次传送该消息进行处理。
如果消息已被确认,消息队列系统则会从队列中移除该消息,因为它的任务已经完成。
这种机制确保了业务流程的完整性,即使在发生故障的情况下,业务流程也能在系统恢复后继续执行未完成的部分。这就是为什么消息队列广泛用于分布式系统中保证数据处理的可靠性和一致性,特别是在需要保障数据不丢失的情况下
为啥使用延迟双删呢?
延迟双删指的就是删除两次缓存,流程如下
1.删除缓存:此步骤为了避免获取到旧缓存中的旧数据
2.更新数据库:删除之后就先更新数据库
PS:前两步就是上面的逻辑(先删除缓存,再修改数据库)
3.延迟一会再删除缓存:此步骤是为了避免上面因为并发问题导致保存旧值的情况发生,所以会延迟一段时间之后再进行删除操作。这样即使有并发问题,也能最大限度的解决保存旧值的情况,因为是延迟之后删除的,所以即使是因为并发问题保存了旧值,但是延迟一段时间之后,旧值就会被删除,那么这样就自然而然的保证了数据库和缓存的最终一致性。
4.更新缓存(可选):在某些情况下,第二次删除之后,你可能会选择立即更新缓存。这通常是为了确保缓存中的数据尽可能的保持最新。但这不是必须的,因为缓存可以在下次有需要时通过正常的缓存加载策略被再次填充。
PS:如果这时候你更新缓存了,那么如果再有多线程并发的情况,这时候数据库已经是新值了,所以就不会再有缓存旧值的情况了。