mysql 索引(为什么选择B+ Tree?)
索引实现原理
索引:排好序的数据结构
优点:降低I/O成本,CPU的资源消耗(数据持久化在磁盘中,每次查询都得与磁盘交互)
缺点:更新表效率变慢,(更新表数据,还要更新索引),占用空间
分类:主键索引,唯一索引,单值索引,组合索引
索引的数据结构
Hash表(舍弃:不适合范围查找和排序)
hash 是一维数组 + 二维链表:取模后进行存储
对于hash算法的CRUD来讲,时间复杂度为O(1)
但对于范围查询和排序来讲,时间复杂度又从最好变为O(n)
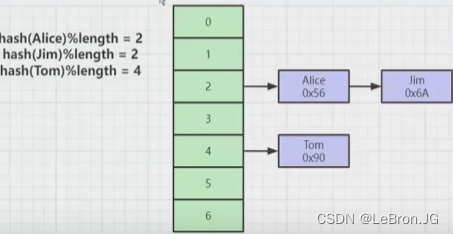
二叉树(舍弃:自增序列无效)
理想情况
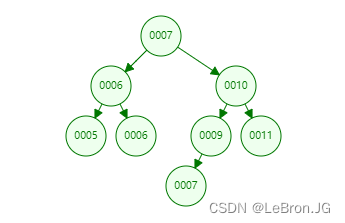
mysql不使用的原因:对于自增数据,树左倾或右倾形成链表,时间复杂度变回了O(n)
红黑树(舍弃:树会很高)
本质就是二叉树,相比较于二叉树,他有平衡功能(当一边高时,会自动更新根节点),又称为二叉平衡树
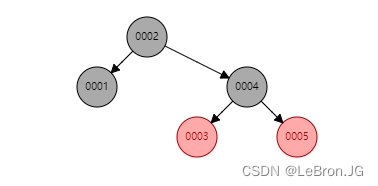
mysql 不使用原因:数据量大的时候,树会更高,查找到叶子节点效率也会慢,每层就是一次IO
B Tree(舍弃:每个节点存放数据,可以优化)
特点:在每个节点,放多个索引
优点:树就不会高,但每个节点都会存data数据,会占据很大的磁盘空间
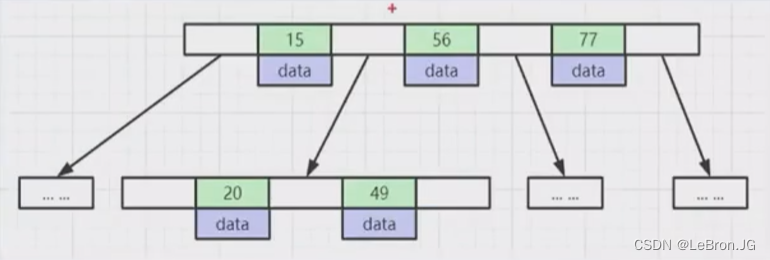
B+ Tree(mysql默认)
优点:
1.非叶子节点不储data,只存储索引,可以放更多的索引
2.叶子节点包含所有索引+data字段,由双向链表排成一行(更好的实现范围查找和排序)
3.叶子节点用指针连接,提高区间访问的性能
mysql 默认每个节点为16KB,
例如:若使用bigInt的主键,每个节点大概可放1170 个索引,若树高3层,则为1170*1170 *16 约为2000多万索引
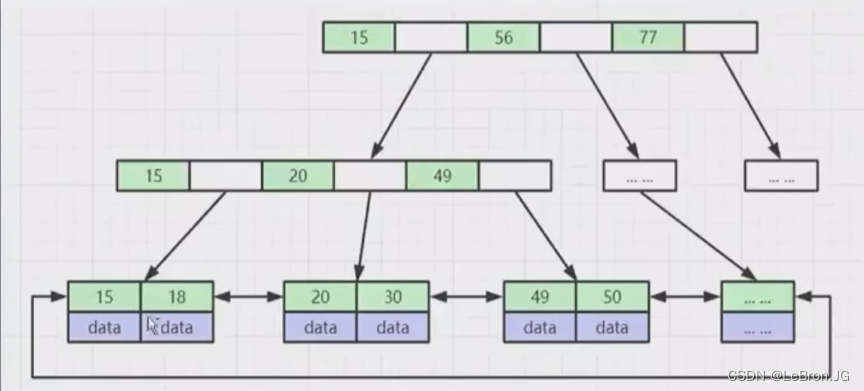
总结:(数据存叶子节点,双向链表)
BTree 和B+Tree都是多路搜索树,区别在于叶子节点和非叶子节点的处理。
1.BTree 每个节点都储存索引+数据,B+Tree 的非叶子节点只存储索引+指向叶子节点的指针,数据存到叶子节点,这样B+Tree 的非叶子节点就可以放更多的索引,树的层级也就降低了,这样查找更快,减少了磁盘IO。
2.B+Tree 的叶子节点都有指针相连接,形成双向链接表,这样在范围和排序时更快,而BTree 的叶子节点没有相连接,范围查找时还得向父节点查找。所以B+Tree 的范围查找和排序更好
数据结构训练网址
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html