linux系统kubernetes的pod的状态
pod的状态
- pod状态
- Pending
- Running
- Succeeded
- Failed
- Unknown
- CrashLoopBackOff
- ImagePullBackOff
- Terminating
- Evicted
- OOMKilled
- ContainerCreating
- Completed
- 实现机制
- 共享网络
- 共享存储
- 资源限制
- 创建pod数据流
- 节点选择器
- 亲和性
- 污点和污点容忍
pod状态
Pending
Pod 已被 Kubernetes 系统接受,但有一个或多个容器镜像尚未创建。
Pod 等待被调度到一个节点上。
网络配置等前期准备工作正在进行中。
Running
Running Pod 已经被调度到一个节点上,并且所有的容器都已创建。
至少有一个容器正在运行,或者正在启动或重启。
Succeeded
Pod 中的所有容器都正常运行完毕,并已经退出。
这通常适用于一次性或批处理作业。
Failed
Pod 中至少有一个容器以非零状态退出。
表明容器启动失败或运行中出现错误。
Unknown
由于某种原因,Pod的状态无法确定。
通常是与Pod通信出现问题,如节点故障。
CrashLoopBackOff
表明 Pod 中的一个或多个容器尝试启动后失败,正在尝试重启。
这可能是由于应用程序错误、配置问题等引起的。
ImagePullBackOff
Pod无法拉取一个或多个容器镜像。
可能是因为镜像不存在,或者与容器注册中心的认证问题。
Terminating
当 Pod 被标记为删除并开始终止过程时,会进入此状态。 这个状态意味着 Kubernetes 正在停止 Pod 中的所有容器。
Evicted
当节点上的资源(如内存或磁盘空间)不足时,Pod可能会被驱逐。
驱逐行为是 Kubernetes 为了保护节点稳定性而自动执行的操作。
OOMKilled
如果 Pod 中的容器使用超出其分配的内存限制,它可能会被系统的 Out-Of-Memory (OOM) killer 终止。 这通常表明容器配置的内存限制过低或应用程序内存泄露。
ContainerCreating
当 Kubernetes 正在创建 Pod 中的容器时,Pod 会处于此状态。
这可能涉及到拉取容器镜像、创建容器等操作。
Completed
这是一个非常用状态,表明 Pod 中的所有容器都已成功完成其任务并且正常退出。
这通常用于有限期或批处理任务。
实现机制
共享网络
容器用docker创建,本身之间相互隔离
namespace:命名空间
group:组
共享网络的前提条件
容器在同一个ns里面
共享网络的机制
通过pause容器,把其他业务容器加入到pause容器里面,让所有的业务容器在同一个名称空间中,可以实现网络共享
共享存储
pod持久化数据
日志数据
业务数据
持久化存储:数据卷:Volumn
共享存储:引入数据卷的概念,使用数据卷进行持久化存储
资源限制
资源限制本身也是由docker做到的,而不是pod
pod的资源限制对pod的调用产生影响
根据request找到足够的node节点进行调度
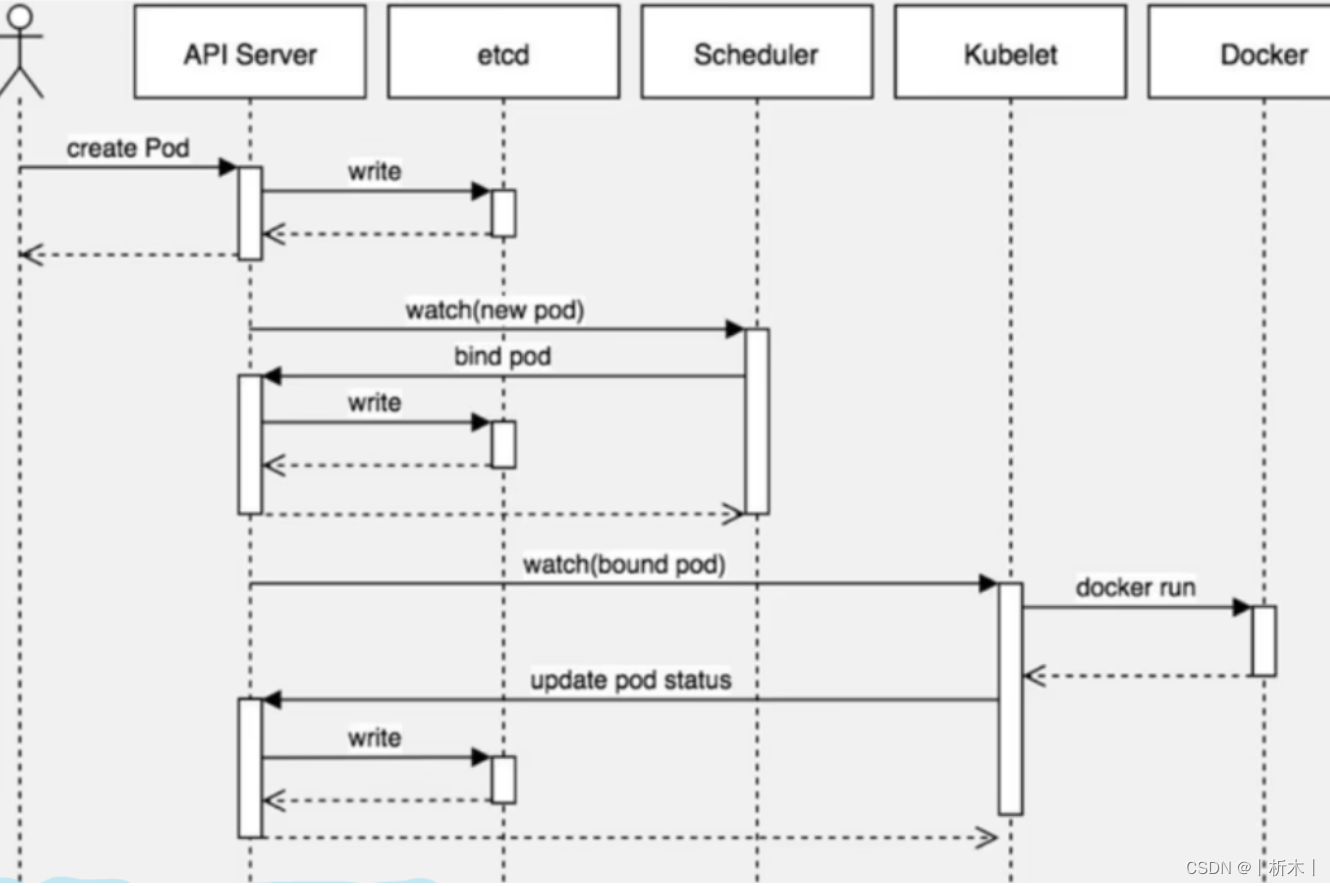
创建pod数据流
master节点
create pod==》api server==》etcd
scheduler==》api server==》etcd ==》调度算法,把pod调度到某个node节点上
调度算法:
预选:输入所有节点,过滤掉不符合创建pod请求的节点
优选:输入时预选后的节点,根据优选策略进行排名,选择排名最高的node节点进项创建pod,
优选策略:比如负载最小的node,资源最富裕的node
node节点
kubelet==》api server==》读取etcd拿到分配给当前节点pod==》docker创建容器
======================================================
kubectl向kubernetes集群api server发起一个create pod请求
kubernetes集群api server接收到pod创建请求后,生成一个包含创建信息的yaml
apiserver将刚才的yaml信息写入etcd数据库
scheduler查看kubernetes api,判断:pod.spec.Node==null,若为null,表示这个Pod请求是新来的,需要创建;因此先进行调度计算,找到最适合的node。并更新数据库
node节点上的Kubelet通过监听数据库更新,发现有新的任务与自己的node编号匹配,则进行任务创建
======================================================
kubectl发起创建Pod请求
用户通过kubectl create命令(或其他等效方式)向Kubernetes API Server发起一个创建Pod的请求。这个请求包含了Pod的定义,通常是一个YAML或JSON格式的文件
API Server接收请求并处理
Kubernetes API Server接收到创建Pod的请求后,会对请求进行验证和授权检查
API Server不会直接创建Pod,而是将这个请求转化为一个内部表示(如一个含有Pod创建信息的YAML格式的对象)
写入Etcd数据库
API Server将这个Pod对象的信息写入到Etcd数据库。Etcd作为Kubernetes的数据存储,保存了集群的状态和配置
Scheduler进行调度
Kubernetes Scheduler持续监视API Server,检查新的或未被调度的Pod
当Scheduler发现一个新的Pod(pod.spec.Node == null表示这个Pod还没有被调度到任何节点),它将根据资源需求、亲和性规则、污点和容忍度等因素选择一个合适的节点
一旦选择了节点,Scheduler将更新该Pod的信息,指定其运行在选择的节点上,并将这个更新写回到Etcd
Kubelet监听并创建Pod
每个节点上的Kubelet进程持续监视Etcd,查找分配给自己节点的新任务
当Kubelet发现有新的Pod分配到它所在的节点,它会根据Pod定义开始创建和启动Pod中的容器
Kubelet调用容器运行时(如Docker)来实际启动容器,并设置必要的网络和存储配置
Pod状态更新和汇报
在Pod创建过程中,Kubelet将Pod的状态更新回API Server。这些状态信息包括Pod是否成功启动,运行中的容器等
API Server更新Etcd中的状态信息,确保集群状态的一致性
节点选择器
节点选择器标签影响pod的调度
首先对节点创建标签
起标签的命令:
kubectl label node <node-name> <label-key>=<label-value>
<node-name> 是要标记的节点名称
<label-key> 是标签的键
<label-value> 是标签的值。
kubectl label node node1 env_role=prod
nodeSelector:
节点选择器:可以指定node的标签,查看标签指令:
nodeName:
节点名称: 可以指定node的名称进行调度
kubectl get node --show-labels
亲和性
节点的亲和性影响pod调度
节点亲和性标签:nodeAffinty和之前nodeSelector基本一样,根据节点上标签约束来决定pod调度到那些节点
pod的亲和性和反亲和性是处理pod与pod之间的关系。
pod亲和性主要是想把pod和某个依赖的pod放在一起,以实现pod的标签进行标记,并将pod标签一样的几个pod部署到同一个节点上。
pod反亲和性主要想把pod和某个pod分开。
pod的亲和性和反亲和性都有硬亲和和软亲和之分:
硬亲和性:约束条件必须满足
软亲和性:尝试满足,不保证满足
支持常用的操作符号
In
NotIn
Exists
Gt
Lt
DoesNotExists
污点和污点容忍
影响pod调度
污点和污点容忍
1.
基本介绍
nodeSelector和nodeAffinity
pod调度到某些节点,pod属性,调度的时候实现
Taint:污点,节点不做普通的分配调度,是节点属性
2.应用场景
专用节点:
配置特定硬件节点
基于Taint驱逐
3.具体演示
1)查看当前节点污点情况:kubetcl describe node 当前节点名称 | grep Taint
污点值有三个
NoSchedule:一定不被调度
PreferNoSchedule:尽量不被调度
NoExecute:不会调度,还会驱逐Node已有的pod
2)为节点添加污点
kubetcl taint node [节点名称] key=value:污点值
3)为节点删除污点
kubetcl taint node [节点名称] key=value:污点值-
4.污点容忍
污点容忍yaml文件修改