机器学习----特征缩放
目录
一、什么是特征缩放:
二、为什么要进行特征缩放?
三、如何进行特征缩放:
1、归一化:
2、均值归一化:
3、标准化(数据需要符合正态分布):
一、什么是特征缩放:
通俗来讲就是将原本由于数据规范化的单位,导致所训练的数据集中各种数据的无单位数值差距较大,而我们通过归一化处理等方式使得数据范围均稳定在一个较小区间的过程。
二、为什么要进行特征缩放?
我看了许多文章,就好比我们常常会由于其过于突出的一面而片面理解某个事物一样,对于值大的一方,我们会不知觉地倾向过去。对于这个点我们最好还是从一个等高线图来进行理解:
以吴恩达老师的例子来说明,假设其购房:
| 总平方米:300平~2000平 | 房间数量:1间~5间 |
同时我们假设b = 50,对于其2000平米,5个房间的房子,其正常的价格为50万:
那么我们带入列表中两组不同的w1和w2,可以发现,其数值较大的因素:总平方*50 + 房间*0.1求得的值约为10万元,而另一组则大约为50万元。
我们可以发现:我们更希望一个数值越小的,其对应的系数应该越大,那这与梯度下降有什么关系呢?
我们这是便从等高线图中来理解:

这个是其对应的 的等高线图,那么我们可以看看梯度下降需要走到其中最小点的话,他可能会怎么走:
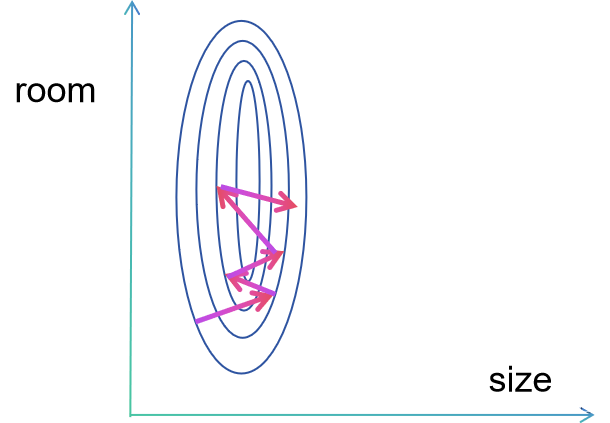
由于size对应的轴范围太短,room对应的轴由过于长,要想通过梯度下降得到一能满足条件的最小值可能就会出现这种状况,导致其收敛减慢。 这便是为什么我们需要进行特征缩放,而如果图中并非椭圆而是圆形,其效果就是最好的情况。

同时我们也可以结合欧氏距离进行理解。
三、如何进行特征缩放:
1、归一化:
其对应的取值区间为[0,1],当然也有更加灵活的形式:
其对应的取值区间为[a,b],一般来说,a,b的值不要过大也不要过小,其 [-5 , 5] 都是适合的。
2、均值归一化:
3、标准化(数据需要符合正态分布):
其中分母对应x的标准差,其实这个式子就是正态分布的标准化的公式: