超分之SwinIR
- SwinIR: Image restoration using Swin Transformer
- SwinIR: 使用Swin Transformer 进行图像恢复
- Liang J, Cao J, Sun G, et al.
- Proceedings of the IEEE/CVF international conference on computer vision. 2021: 1833-1844.
摘要
- 首先,介绍了Image restoration的含义
- 图像恢复是一个长期存在的low-level问题,旨在从低质量图像(例如,缩小的、有噪声的和压缩的图像)恢复高质量图像。
- 接着,指出目前SR技术的sota模型都是基于卷积神经网络,而很少使用Transformer(虽热Transformer在high-level任务上实现了sota)。
- 然后,提出了本文的sota模型
- SwinIR—一种基于 Swin Transformer 的baseline模型
- SwinIR由三部分组成:浅层特征提取、深层特征提取、高质量特征重建。
- 其中,深层特征提取模块由多个residual Swin Transformer blocks (RSTB)构成,而每个RSTB都有多个Swin Transformer和残差连接。
- 最后,作者将SwinIR用于图像恢复的三个表征性问题的实验:
- 图像超分辨率(包括经典、轻量级和真实世界图像超分辨率)
- 图像去噪(包括灰度和彩色图像去噪)
- JPEG压缩伪影减少
- 结论,SwinIR实现了SOTA,并行模型的参数总数大大减少。
1. 引言
- 首先,介绍了图像恢复技术的含义,以及CNN是此技术的主流框架;虽然CNN比传统技术性能更高,但是CNN作为backbone有两个基本问题。
- 图像和卷积核之间的交互是与内容无关的(content-independent)。使用相同的卷积核恢复不同的图像区域可能不是最好的选择。
- 在局部处理的原则下,卷积对于长距离依赖建模并不有效。
- 接着,针对CNN的问题,引出了Transformer的定义,虽然对于一些high-level任务(如分类、检测)有良好的性能,但是对于low-level任务(图像恢复)仍然会有一些问题
- 用于图像恢复的ViT通常将输入图像划分为固定大小(例如 48×48)的块,并独立处理每个块。这种策略不可避免地会产生两个缺点:
- 边界像素不能利用块之外的相邻像素来进行图像恢复。
- 恢复的图像可能会在每个补丁周围引入边界伪影。(虽然这个问题可以通过补丁重叠(patch overlapping)来缓解,但它会带来额外的计算负担。)
- 然后,指出最近的Swin Transformer有很大的前景,因为它集成了CNN和Transformer的优由势。
- 由于局部注意力机制,它具有CNN处理大尺寸图像的优势。
- 可以通过移位窗口方案对远距离依赖建模,它具有Transformer的优势。
- 最后,提出了本文的SwinIR模型,以及说明了本模型的优势,实现了SOTA
- SwinIR:一种基于Swin Transformer 的图像恢复模型
- SwinIR由三部分组成:浅层特征提取、深层特征提取、高质量特征重建模块。
- 浅层特征提取模块:
- 使用卷积层提取浅层特征,提取的浅层特征也直接传输到重建模块以保留低频信息。
- 深层特征提取模块:
- 主要由多个residual Swin Transformer blocks (RSTB)构成,每个RSTB利用多个Swin Transformer层进行局部注意力和跨窗口交互。
- 此外在块的末尾添加了一个卷积层,来进行特征增强,并使用残差连接来为特征融合提供捷径(shortcut)。
- 高质量特征重建模块:
- 在重建模块中融合浅层和深层特征,以实现高质量的图像重建。
- 相对于CNN的IR技术,SwinIR有几个优点:
- 图像内容和注意力权重之间基于内容的(content-based)交互。(可以理解为空间变换的卷积)
- 通过移位窗口机制实现长距离依赖建模。
- 能够使用更少的参数来获得更高的性能。
2. 相关工作
2.1 图像恢复(Image Restoration)
- 相较于传统的图像恢复技术(列举了几个),基于CNN的IR技术性能更好。
- CNN_IR经常从大规模配对数据集中学习低质量和高质量图像之间的映射。
- CNN_IR技术性都是通过使用更复杂的神经网络架构设计(残差块、密集块、其他)
- 还有一些利用了CNN框架内的注意力机制(通道注意力、非局部注意力、自适应patch aggregation)
2.2 视觉Transformer(Vision Transformer, ViT)
- 用于NLP的的Transformer在high-level的计算机视觉任务中很受欢迎(图像分类、目标检测、分割、人群计数)
- ViT通过探索不同区域之间的全局相互作用来学习关注重要的图像区域。
- ViT也被引入到low-level的IR任务中(IPT(依赖于大量参数)、VSR-Transformer(用自注意力机制在视频SR中实现更好的特征融合,但图像特征仍然从CNN中提取))
- 但是IPT和VSR-Transformer都是patch-wise的attention,所以不适用于IR技术。
- 此外,一项并行工作提出了一种基于Swin Transformer 的U形架构。
3. 方法论
![![[Pasted image 20240315120526.png]]](https://img-blog.csdnimg.cn/direct/14e67d38d03445408a493056b08e0e46.png)
3.1 网络结构
![![[Pasted image 20240315135235.png]]](https://img-blog.csdnimg.cn/direct/93cf301783a64c4185fbe876ecdbf351.png)
如上图所示,SwinIR由3个模块构成:浅层特征提取、深层特征提取、高质量特征重建。(对于IR的三个表征性任务使用相同的特征提取模块,使用不同的重建模块)
-
浅层特征提取模块:
F 0 = H S F ( I L Q ) ( 1 ) F_0 = H_{SF}(I_{LQ}) \ \ \ (1) F0=HSF(ILQ) (1)
其中: -
I L Q ∈ R H × W × C i n I_{LQ}\in R^{H×W×C_{in}} ILQ∈RH×W×Cin:输入的低质量图像(low-quality),
-
H S F ( ⋅ ) H_{SF}(·) HSF(⋅):浅层特征提取函数,3×3的卷积层。
-
F 0 ∈ R H × W × C F_0\in R^{H×W×C} F0∈RH×W×C:提取的浅层特征。
-
使用卷积层提取浅层特征的优势:
- 卷积层很擅长早期的视觉处理,导致更稳定的优化和更好的结果,它还提供了一种将输入图像空间映射到更高维特征空间的简单方法。
-
深层特征提取模块:
F D F = H D F ( F 0 ) ( 2 ) F_{DF} = H_{DF}(F_0)\ \ \ \ (2) FDF=HDF(F0) (2)
其中: -
F D F ∈ R H × W × C F_{DF}\in R^{H×W×C} FDF∈RH×W×C:提取的深层特征。
-
H D F ( ⋅ ) H_{DF}(·) HDF(⋅):深层特征提取函数,包含K个residual Swin Transformer blocks(RSTB)和1个3×3的卷积层。
具体地:
F i = H R S T B i ( F i − 1 ) , i = 1 , 2 , . . . , K , F D F = H C O N V ( F K ) ( 3 ) \begin{align} F_i = H_{RSTB_i}(F_{i-1}), i = 1, 2, ..., K,\\ F_{DF} = H_{CONV}(F_K) \end{align}\ \ \ \ \ \ \ \ (3) Fi=HRSTBi(Fi−1),i=1,2,...,K,FDF=HCONV(FK) (3)
其中: -
F 1 , F 2 , . . . , F K F_1, F_2, ..., F_K F1,F2,...,FK:中间层特征
-
H R S T B ( ⋅ ) H_RSTB(·) HRSTB(⋅):第i个RSTB
-
H C O N V ( ⋅ ) H_{CONV}(·) HCONV(⋅):最后一个卷积层。
-
在深层特征提取的最后使用卷积层的优势:
- 可以将卷积运算的归纳偏差带入基于Transformer的网络中,为后期浅层和深层特征的聚合打下更好的基础。
-
图像重建模块:
-
SR任务(需要上采样操作):
I R H Q = H R E C ( F 0 + F D F ) ( 4 ) I_{RHQ} = H_{REC}(F_0 + F_{DF}) \ \ \ \ (4) IRHQ=HREC(F0+FDF) (4)
其中:- R R H Q R_{RHQ} RRHQ:重建的高质量图像(high-quality)。
- F 0 ∈ R H × W × C F_0\in R^{H×W×C} F0∈RH×W×C:提取的浅层特征。
- F D F ∈ R H × W × C F_{DF}\in R^{H×W×C} FDF∈RH×W×C:提取的深层特征。
- H R E C H_{REC} HREC:重建模块函数, 这里使用亚像素卷积(sub-pixel convolution)
- 这里:
- 浅层特征主要包含低频信息,深层特征侧重于恢复丢失的高频信息,通过长跳跃连接,SwinIR可以将低频信息直接传输到重建模块,这可以帮助深度特征提取模块专注于高频信息并稳定训练。
-
图像去噪和JPEF压缩伪影减少任务(不需要上采样操作):
I R H Q = H S w i n I R ( I L Q ) + I L Q ( 5 ) I_{RHQ} = H_{SwinIR}(I_{LQ}) + I_{LQ}\ \ \ \ (5) IRHQ=HSwinIR(ILQ)+ILQ (5)
其中:
- H S w i n I R H_{SwinIR} HSwinIR:深层特征提取中SwinIR的函数。 -
损失函数:
l = ∣ ∣ I R H Q − I H Q ∣ ∣ 1 ( 6 ) l = ||I_{RHQ} - I_{HQ}||_1\ \ \ \ \ (6) l=∣∣IRHQ−IHQ∣∣1 (6)
其中: -
I R H Q I_{RHQ} IRHQ:将低质量图像 I L Q I_{LQ} ILQ作为SwinIR的输入得到的重建高质量图像。
-
I H Q I_{HQ} IHQ:LQ图像对应的GT图像(ground-truth)。
对于经典(classical)和轻量级(lightweight)图像SR: -
损失函数仅使用公式(6)中的==L1损失==,来显示设计的SwinIR网络的有效性。
对于真实世界(real-world)图像SR: -
损失函数使用==像素损失+GAN损失+感知损失(pixel_loss+GAN_loss+perceptual_loss)==,来提高视觉质量。
**对于图像去噪和JPEF压缩伪影减少任务: -
损失函数使用==Charbonnier loss==:
l = ∣ ∣ I R H Q − I H Q ∣ ∣ 2 + ϵ 2 ( 7 ) l = \sqrt{||I_{RHQ} - I_{HQ}||^2 + \epsilon^2}\ \ \ \ (7) l=∣∣IRHQ−IHQ∣∣2+ϵ2 (7)
其中: -
ϵ \epsilon ϵ:是一个常数,这里为 1 0 − 3 10^{-3} 10−3。
3.2 Residual Swin Transformer Block(RSTB)
![![[Pasted image 20240315143654.png]]](https://img-blog.csdnimg.cn/direct/2de224eded2d42cea822682d9efbee75.png)
如上图所示,RSTB是具有SwinTransformer layers(STL)和卷积层的残差块
首先,计算经过L个STL的中间特征:
F
i
,
j
=
H
S
T
L
i
,
j
(
F
i
,
j
−
1
)
,
j
=
1
,
2
,
.
.
.
,
L
(
8
)
F_{i,j} = H_{STL_{i, j}}(F_{i, j-1}), j = 1, 2, ..., L \ \ \ \ (8)
Fi,j=HSTLi,j(Fi,j−1),j=1,2,...,L (8)
其中:
- F i , 0 F_{i, 0} Fi,0:第i个RSTB的输入特征
- F i , 1 , F i , 2 , . . . , F i , L F_{i, 1}, F_{i, 2},...,F_{i, L} Fi,1,Fi,2,...,Fi,L:L个RSTB中,每个RSTB提取到的中间特征。
-
H
S
T
L
i
,
j
(
⋅
)
H_{STL_{i,j}}(·)
HSTLi,j(⋅):第i个RSTB中的第j个Swin Transformer 层(STL).
然后,在残差连接之前,添加一个卷积层:
F i , o u t = H c o n v i ( F i , L ) + F i , 0 ( 9 ) F_{i, out} = H{conv_i}(F_{i, L}) + F_{i, 0}\ \ \ (9) Fi,out=Hconvi(Fi,L)+Fi,0 (9)
其中: - F i , o u t F_{i, out} Fi,out:第i个RSTN的输出特征。
-
H
C
O
N
V
i
(
⋅
)
H_{CONV_i}(·)
HCONVi(⋅):第i个RSTB的卷积层。
这样RSTB设计有两个优势:- 虽然 Transformer 可以被视为空间变化卷积的具体实例,但具有空间不变滤波器的卷积层可以增强 SwinIR 的平移等方差(translational equivariance)。
- 残差连接提供了从不同块到重建模块的identity-based连接,允许聚合不同级别的特征。
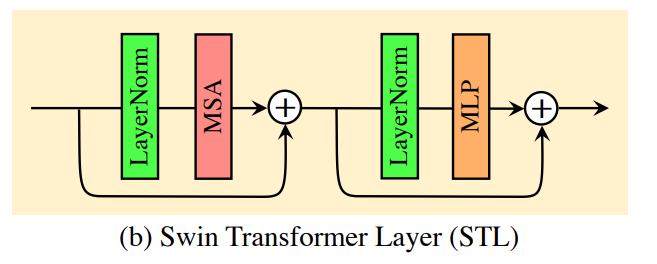
如上图所示,Swin Transforemr layer(STL)是基于原始的Transforemer层的标准多头自注意力,主要区别在于局部注意力和移动窗口机制。
Swin transformer的原理如下:
- 给定大小为H×W×C的输入图像,Swin transforemr首先通过将输入图像划分为不重叠的M×M的局部窗口,其形状为
W
H
M
2
×
M
2
×
C
\frac{WH}{M^2}×M^2×C
M2WH×M2×C(这里
W
H
M
2
\frac{WH}{M^2}
M2WH是局部窗口的数量)。 然后它分别计算每个窗口的标准自注意力(即局部注意力),对于局部窗口特征
X
∈
R
M
2
×
C
X\in R^{M^2×C}
X∈RM2×C,quary(Q),key(K),value(V)的计算如下:
Q = X P Q , K = X P K , V = X P V ( 10 ) Q = XP_Q, \ \ K=XP_K,\ \ V=XP_V \ \ (10) Q=XPQ, K=XPK, V=XPV (10) - 其中:
- P Q , P k , P V P_Q, P_k, P_V PQ,Pk,PV:是在不同窗口之间共享的投影矩阵。
- Q , K , V ∈ R M 2 × d Q, K ,V \in R^{M^2×d} Q,K,V∈RM2×d:一般来说,X[M, M, C]与Q/K/V[M, M, d]做矩阵乘法运算。
- 局部窗口的自注意力机制为:
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T / d + B ) V ( 11 ) Attention(Q, K, V) = SoftMax(QK^T/\sqrt d + B)V \ \ \ \ (11) Attention(Q,K,V)=SoftMax(QKT/d+B)V (11) - 其中 :
- B:可学习的相对位置编码
- 并且使用h个头并行执行h次注意力函数,然后concatnate,进行多头自注意力(MSA))。然后,MLP由两个之间具有GELU非线性的全连接层组成,用于进一步的特征转换。在MSA和MLP之前添加了层归一化(LN),并且两个模块都使用了残差连接。
X = M S A ( L N ( X ) ) + X , X = M L P ( L N ( X ) ) + X , ( 12 ) \begin{align} X = MSA(LN(X))+X, \\ X = MLP(LN(X))+X, \end{align}\ \ \ \ \ \ \\ \ (12) X=MSA(LN(X))+X,X=MLP(LN(X))+X, (12)
然而, 当不同层的分区固定时,局部窗口之间不存在连接。因此交替使用常规的和移位窗口来实现跨窗口连接。
(其中,移位窗口分区意味着分区之前将特征移位( ⌊ M 2 ⌋ , ⌊ M 2 ⌋ \lfloor \frac{M}{2}\rfloor, \lfloor \frac{M}{2}\rfloor ⌊2M⌋,⌊2M⌋)个像素)
4. 实验
4.1 实验设置
对于任务:经典图像SR,真实世界图像SR,图像去噪,JPEG压缩伪影减少
- RSTB个数、STL个数、窗口尺寸,通道数,注意力头数:6, 6, 8, 180, 6
特别地,对于JPEG压缩伪影减少 - 窗口尺寸为7×7的效果要好于8×8(有可能时因为JPEG编码使用的8×8的图像分区)
对于轻量级图像SR - RSTB个数,通道数量改为:4, 60
还提出了一个SwinIR的plus版:SwinIR+(使用集成策略测试)
4.2 消融实验
对于经典图像SR任务
- 训练集:DIV2K(x2)
- 测试集:Manga109
-
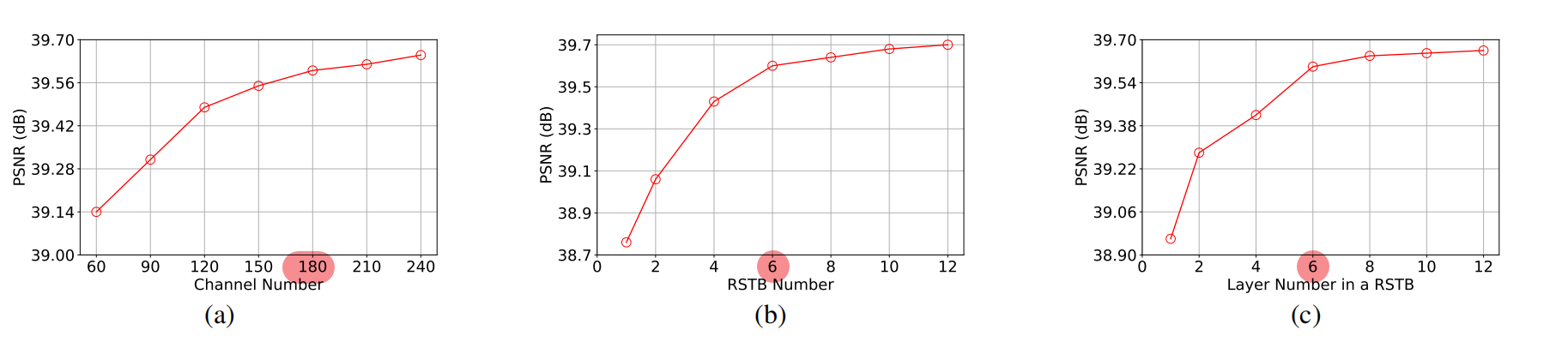
对于通道数,RSTB个数,STL个数:
- PSNR与三个超参数正相关,
- 鉴于模型参数的balance,通道数,RSTB个数,STL个数: 180,6,6。
-
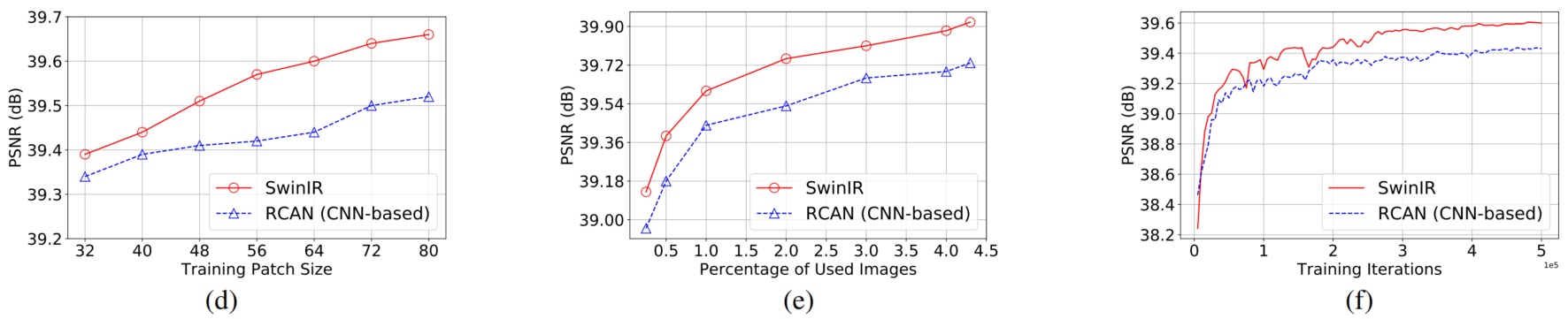
对于patch size,训练集的数量,迭代次数:
- pacth:相较于基于CNN的RCAN模型,SwinIR在任何patch size上都表现更好,并且patch size越大,PSNR的增益越高。
- 训练集的数量:当百分比大于 100%(800 张图像)时,将使用来自 Flickr2K 的额外图像进行训练,有两个观察结果。
- SwinIR 的性能随着训练图像数量的增加而提高。
- 与 IPT 中基于 Transformer 的模型严重依赖大量训练数据的观察不同,SwinIR 使用相同的训练数据比基于 CNN 的模型取得了更好的结果,即使数据集很小(即 25%, 200 张图片)。
- 迭代次数:SwinIR比RCAN收敛的更快更好。(与之前的结论矛盾:基于 Transformer 的模型经常会出现模型收敛缓慢的问题。)
-
对于RSTB中残差连接和卷积层的影响:
- RSTB中的残差连接很重要,能提高模型的PSNR。
- 使用1×1卷积带来的改进很少。(可能是因为它无法像 3×3 卷积那样提取局部邻近信息)
- 虽然使用三个3×3卷积层可以减少参数数量,但性能略有下降。

4.3 图像SR结果
传统图像SR
- 相较于基于CNN的SR技术(DBPN,RCAN,RRDB,SAN,IGNN,HAN,NLSA)和基于Transformer的SR技术(使用大量参数的IPT),实现了SOTA。
- 当使用更大的数据集(DIV2K+Flickr2k)训练,SwinIR的性能进一步大幅提升。
- 相对于基于CNN的SOTA模型(15.4 - 44.3M),SwinIR的参数更少(11.8M)。
- SwinIR可以恢复高频细节并减轻模糊伪影,从而产生清晰自然的边缘。 (基于CNN的方法大多会产生模糊的图像甚至不正确的伪影;IPT虽然可以生成更好的图像,但它会出现图像失真和边界伪影的问题。)
轻量级图像SR
- 小尺寸的SwinIR与轻量级的SOTA模型(CARN,FALSR-A,IMDN,LAPAR-A,LatticeNet)相比,实现了SOTA。
- 并且SwinIR架构对于图像恢复非常高效。
真实世界图像SR(用于现实世界的SR技术应用)
- 与BSRGAN:用于真实世界图像SR的实用退化模型
- 使用与BSRGAN相同的退化模型来训练SwinIR。以获得LQ图像。
- 与RealSR、BSRGAN、Real-ESRGAN相比,SwinIR 生成具有清晰锐利边缘的视觉上令人愉悦的图像,(而其他比较方法可能会出现令人不满意的伪影)
- SwinIR进一步提出了一个大型模型并在更大的数据集上对其进行训练,实验表明,它可以处理更复杂的损坏,并且在真实图像上获得比当前模型更好的性能。

4.4 在JPEG压缩伪影减少的结果
- 这里之前的技术都是基于CNN的模型
- 与之前最好的模型DRUNet相比,SwinIR只有11.5M参数,而DRUNet是一个大型模型,有32.7M参数
![![[Pasted image 20240317180949.png]]](https://img-blog.csdnimg.cn/direct/d00e84edda25433fa2942e98ce67ca31.png)
4.5 在图像去噪的结果
- 分别对于灰度噪声和颜色噪声去噪,均实现了SOTA。
- SwinIR可以消除严重的噪声损坏并保留高频图像细节,从而产生更清晰的边缘和更自然的纹理。(相比之下,其他方法要么过于平滑,要么过于锐利,并且无法恢复丰富的纹理。)
![![[Pasted image 20240317181019.png]]](https://img-blog.csdnimg.cn/direct/60752eaa4c884622905eef85fae7cd6b.png)
5. 结论
- 本文提出了一种基于 Swin Transformer 的图像恢复模型 SwinIR。
- 该模型由浅层特征提取、深层特征提取和HR重建模块三部分组成。
- 特别是,我们使用一堆residual Swin Transformer blocks(RSTB)进行深度特征提取;
- 每个 RSTB 由 Swin Transformer 层、卷积层和残差连接组成。
- 通过大量实验,SwinIR 在三种代表性图像恢复任务和六种不同设置上实现了最先进的性能:经典图像 SR、轻量级图像 SR、真实世界图像 SR、灰度图像去噪、彩色图像去噪和 JPEG 压缩伪影减少,这证明了所提出的 SwinIR 的有效性和普遍性。
- SwinIR模型扩展到其他恢复任务,例如图像去模糊和去雨。