【Linux】详谈进程优先级进程调度与切换
一、进程优先级
1.1、为什么要有优先级
进程要访问某种资源,进程通过一定的方式排队,确认享受资源的优先顺序。计算机中资源过少,所以进程访问某种资源时需要排队。
1.2、优先级的具体表示
进程的优先级其实就是PCB中的一个整形变量(int PRI)。Linux中进程的默认优先级是80,这个默认优先级是可以被修改的。Linux中优先级的范围是[60,99]。数字越小,进程优先级越高。Linux系统允许用户调整优先级,但是不能直接让你修改PRI的值,而是修改nice值。nice值不是进程的优先级,而是优先级的修正数据。PRI值每次在重新设置的时候都是从80开始。
对进程优先级设置范围,本质是防止常规进程很难享受到资源的情况,为了防止产生进程饥饿问题。任何的分时操作系统,在进程调度上,都要进行较为公平的调度。
二、进程的调度与切换
进程被加载到CPU上运行的时候,并不是必须一口气把代码跑完,现代操作系统,都是基于时间片轮转执行的。
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高 效完成任务,更合理竞争相关资源,便具有了优先级。
独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰。
并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行。
并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为 并发。
2.1进程的切换
进程在运行的时候,会产生大量的临时数据,这些临时数据会保存在CPU对应的寄存器中。当一个进程在CPU上的一个时间片跑完时,CPU上寄存器中的数据都会被保存在进程的PCB中(保护上下文)。CPU内部的所有临时数据,我们叫做进程的硬件上下文。所有的保存都是为了恢复,所有的恢复都是为了在上次的运行位置继续运行。当进程被二次调度时,将曾经保存的硬件上下文进行恢复,放到CPU上再次运行。
虽然寄存器数据放在了一个共享的CPU设备里面,但是所有的数据,其实都是被进程私有的。CPU内某一时刻的数据只属于一个进程。
2.2进程的调度
CPU实现进程调度的算法需要考虑优先级,饥饿问题以及效率问题。CPU的运行队列中有一个queue的task_struct结构体指针数组,该数组的100到139下标正好对应了进程60到99的四十个优先级,比如说有一个优先级为60的进程要被CPU调度了,CPU就会将其链入queue数组的100号下标中(类似于哈希表的结构),每一个队列都对应一个特定的优先级。这样,CPU在调度的时候就可以根据进程的优先级由高到低地调度进程了。如下图所示:
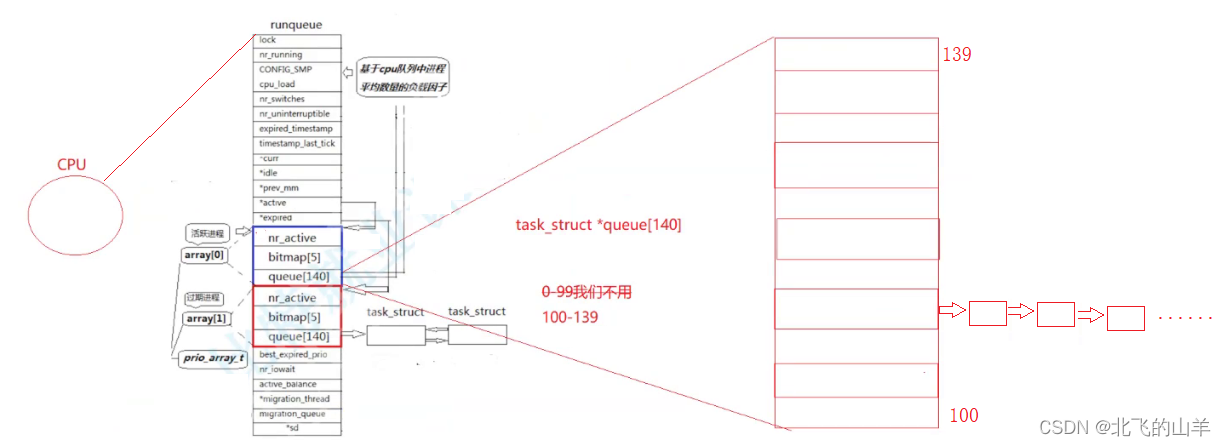
在图中我们可以看到一个bitmap[5]的数组,该数组每个元素的类型为int,也就是说该数组一共可以表示成160个比特位,比特位的位置表示哪一个队列,比特位的值表示该队列是否为空。所以CPU检测哪一个队列中是否有进程就变成了检测对应的比特位是否为零。 这样就可以解决进程判断进程优先级以及效率问题。
从图中我们还可以看到,蓝色方框和红色方框里的内容是一样的。这其实就涉及到活跃队列和过期队列的概念了。在图上还有两个指针,active指针和expried指针,这两个指针分别指向运行队列和过期队列。当CPU在运行一个活跃队列里面的进程时,可能会不断地有新进程产生,这时CPU会把新产生的进程插入到过期队列中(当一个进程的时间片到了它也会被链入过期队列中),等待活跃队列中的进程都执行完了,交换active指针和expried指针的值,就相当于活跃队列和过期队列互换了,而CPU永远只会执行活跃队列里的进程,所以这种方法可以有效地解决进程饥饿问题。