【Linux】从零开始认识进程 — 前篇

我从来不相信什么懒洋洋的自由。我向往的自由是通过勤奋和努力实现的更广阔的人生。。——山本耀司
从零开始认识进程
- 1 认识冯诺依曼体系
- 2 操作系统
- 3 进程
- 3.1 什么是进程???
- 3.2 进程管理
- PCB
- 3.3 Linux中的进程
- 深入理解
- 3.4 进程创建
- 总结
- 送给大家一句话:
- Thanks♪(・ω・)ノ谢谢阅读!!!
- 下一篇文章见!!!
1 认识冯诺依曼体系
学习进程,我们需要对计算机操作系统 有一个初步的了解,也就是经典的冯诺依曼体系:
计算机的逻辑结构。冯·诺依曼从逻辑入手,他的逻辑设计具有以下特点:
(1)将电路、逻辑两种设计进行分离,给计算机建立创造最佳条件;
(2)将个人神经系统、计算机结合在一起,提出全新理念,即生物计算机。
符合人们的一般认知:
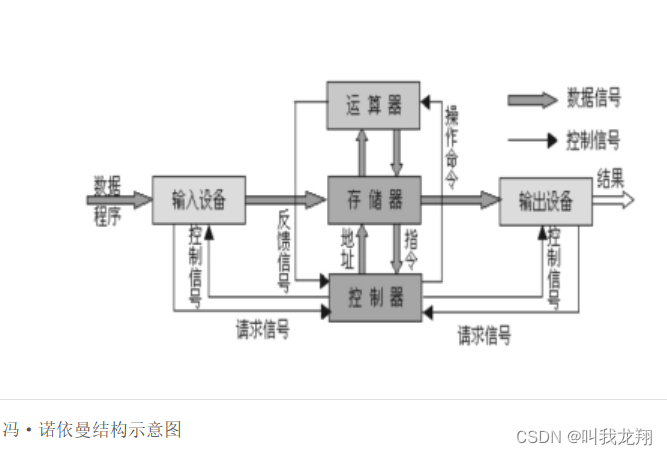
我们所认识的计算机,都是有一个个的硬件组件组成
- 输入单元:包括键盘, 鼠标,扫描仪, 写板等
- 中央处理器(CPU):含有运算器和控制器等
- 输出单元:显示器,打印机等
关于冯诺依曼体系结构,必须强调几点:
- 这里的存储器指的是内存
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)外设(输入或输出设备)
- 要输入或者输出数据,也只能写入内存或者从内存中读取。
- 一句话,所有设备都只能直接和内存打交道。
对冯诺依曼的理解,不能停留在概念上,要深入到对软件数据流理解上
了解冯诺依曼体系结构,接下来我们来认识操作系统
2 操作系统
操作系统可以理解为硬件和用户层面之间的一个软件。让用户通过操作系统可以来对硬件进行访问。那为什么不让用户直接操作硬件呢?打个比方:
我们把银行抽象为一台电脑,银行的金库是我们的硬盘,而我们想要去银行取钱或存钱(获取数据/存入数据),那你说如果我们每个人都可以进入到金库自行行动,(相信大家都是有道德感的人,会如实操作),但群众中里肯定有坏人,假如他存1000元,却报告存了10000元,那银行系统就要崩溃了。所以才会有银行柜台(相当于操作系统提供的接口)让我们可以正常进行操作,不会发生恶性事件
操作系统是必然存在的在整个计算机软硬件架构中,操作系统的定位是: 一款纯正的“搞管理”的软件
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:
内核(进程管理,内存管理,文件管理,驱动管理)其他程序(例如函数库, shell程序等等)
设计OS的目的:
- 与硬件交互,管理所有的软硬件资源
- 为用户程序(应用程序)提供一个良好的执行环境
这里通过一个图示,供大家学习使用:
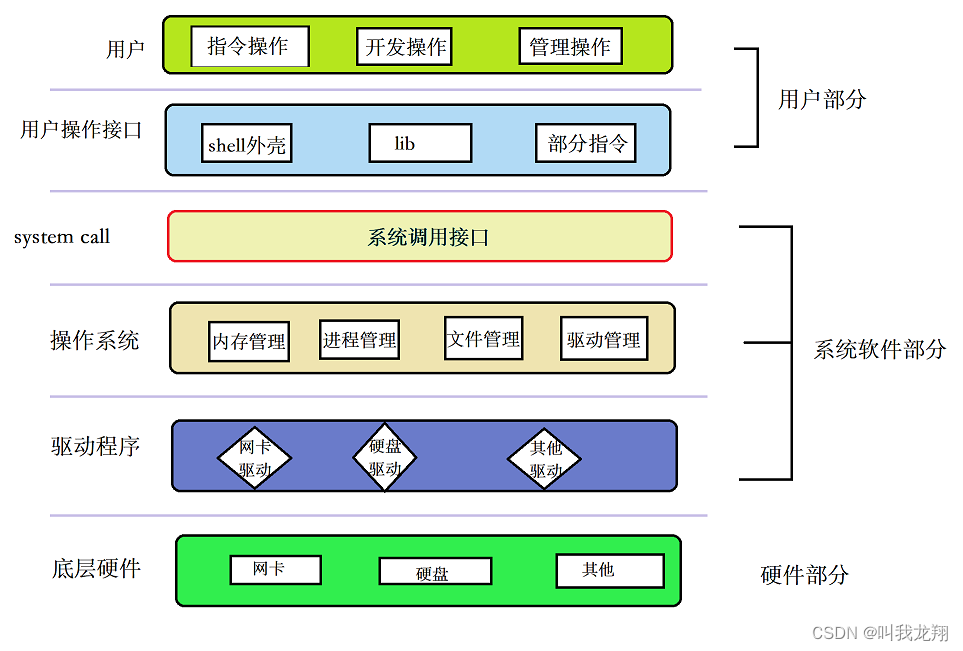
系统调用和库函数概念:
- 在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
- 系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库(lib),有了库,就很有利于更上层用户或者开发者进行二次开发。
这里也可以解释为什么有些代码不具有跨平台性了:
因为直接访问的操作系统的调用接口与平台紧密相关。平台不同(操作系统不同)那系统调用接口,返回值等大概率不同,所以不具有跨平台性
c/c++ 具有跨平台性
接下来我们来学习进程!
3 进程
3.1 什么是进程???
相信大家一定对这个词充满陌生(不管你陌不陌生,反正我第一眼看是不理解什么是进程,太抽象了),但实际上,我们每天都在接触进程(除非你不玩手机,不用电脑)。那我们就俩看看电脑的进程是怎样的吧:
非常简单,我们打开任任务管理器,看见的都是正在进行的进程
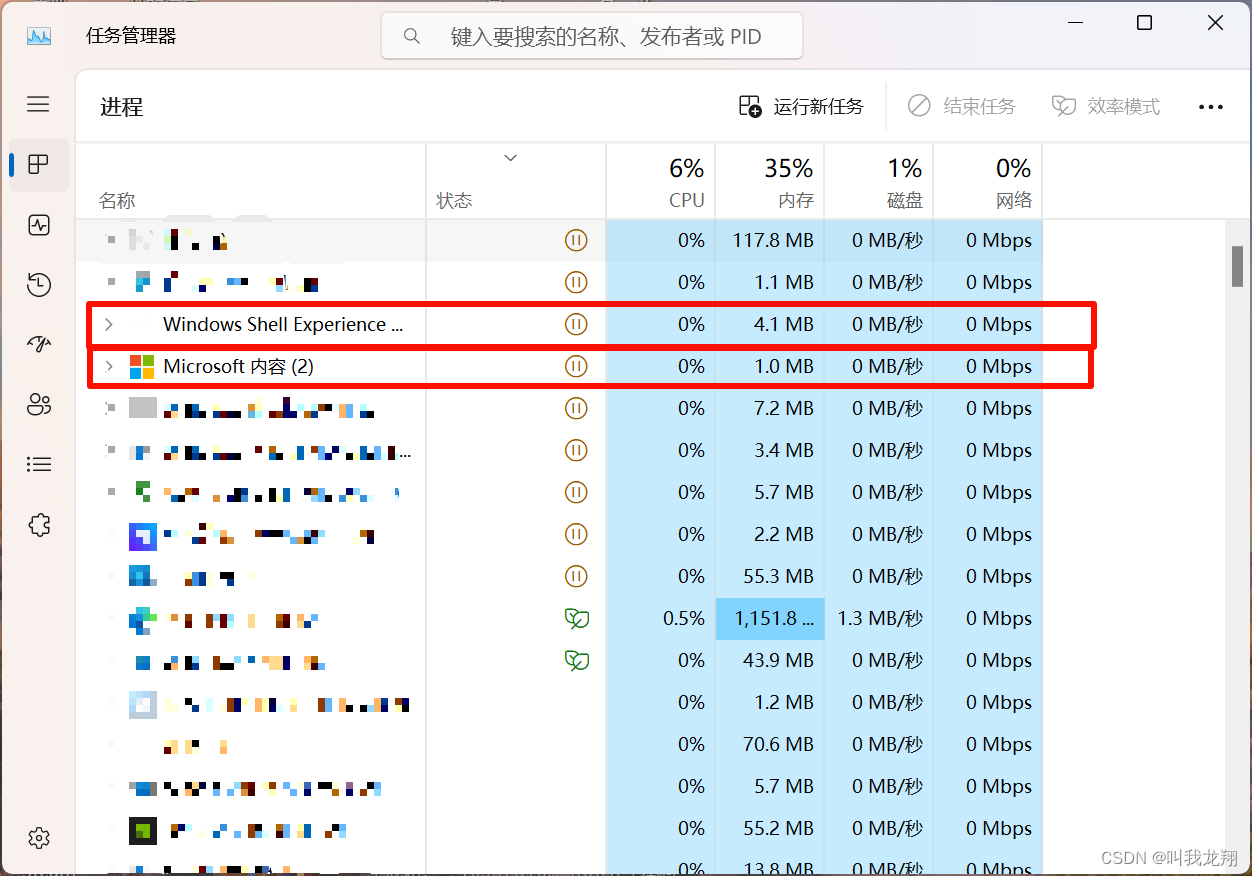
这都是正在进行的进程,所以进程并不高深,是十分常见。
基本概念:
- 课本概念:程序的一个执行实例,正在执行的程序等
- 内核观点:担当分配系统资源(CPU时间,内存)的实体
我们也同任务管理器看到,进程是可以同时存在非常多的
3.2 进程管理
我们知道了进程是什么,那接下来我们来聊聊进程是如何进行管理的吧
进程是通过PCB来进行描述和管理的
进程 = PCB + 自己的数据和代码
PCB
PCB 实质上是一种结构体,里面包含该进程的信息,和下一进程的地址:类似如下结构
struct PCB{
//所有属性
//指向下一个进程
struct PCB* next;
//内存指针
//储存对应数据,代码等
//....
}
一个进程一定要有一个PCB。
那为什么要有PCB呢???:因为操作系统(os)要对进程进行管理!!!
3.3 Linux中的进程
每个操作系统都有自己对应的PCB模块,那我们来看一下linux 的PCB是什么样子:
struct task_struct{
//Liunx 进程控制模块
}
在linux里,通过链表进行的PCB管理 ,同时使用队列里选择任务进行运算。即:
- 在队列里取出任务
- 找到任务对应的PCB
- 通过PCB调用对应数据进行CPU运算。
调度运行进程,本质就是让进程控制块task_struct进行排队!!!
在根据进程的概念我们可以理解linux的进程为:
进程 = 内核task_ struct结构体 + 程序的代码和数据
深入理解
现在我们来进入到linux中来看看进程的Task_struct本身内部的属性都有哪些???
现在,linux 启动!!!
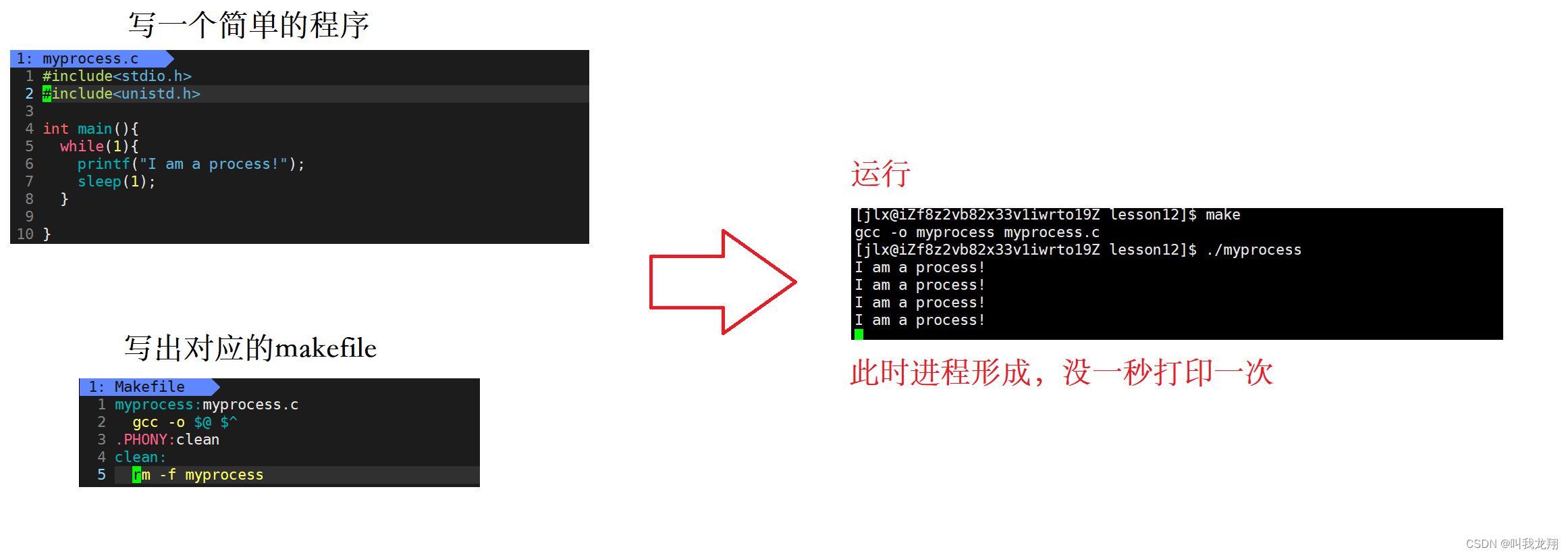
. / 的本质就是让系统创建进程并运行 (此外每个指令也是一个可执行程序)
我们自己写的代码形成的可执行程序 == 系统命令 == 可执行程序。
在Linux 中大部分的执行操作本质都是运行进程!!!
现在我们再来看看Linux中的“任务管理器”,让我们一起来看看然后才能查看进程
ps ajx 可以查看我们的进程,为了方便演示我们使用grep 来进行一下筛选:
ps ajx | grep myprogress
 在下面的 grep -…也是我们的进程,因为每次grep查找 都会形成进程 因而就会出现两个进程。
在下面的 grep -…也是我们的进程,因为每次grep查找 都会形成进程 因而就会出现两个进程。
接下来我们来认识一下具体属性:
我们使用ps ajx | head -1(即只打印第一行)
然后怎么查看对应信息呢???光看到这一行也无法理解
使用指令 && 指令 即可:

这样我们成功打印出来进程信息,我们来认识一下:
- PID : 每一个进程都要有自己的唯一标识符,叫做进程PID
那么我们能不能通过可执行程序自己查到我们的PID呢?(这样就省去ps命令了)。
当然可以!!!
pid 储存在 struct task_struct 中,而struct task_struct 是内核数据结构,用户不能轻易访问(上面有讲到为什么不能访问),那么如何才能获取呢???当然是使用系统提供给我们的接口了
pid_t getpid() 就是这样的接口。我们把接口加入到我们的代码中试试。
(getppid () 是返回父进程 )
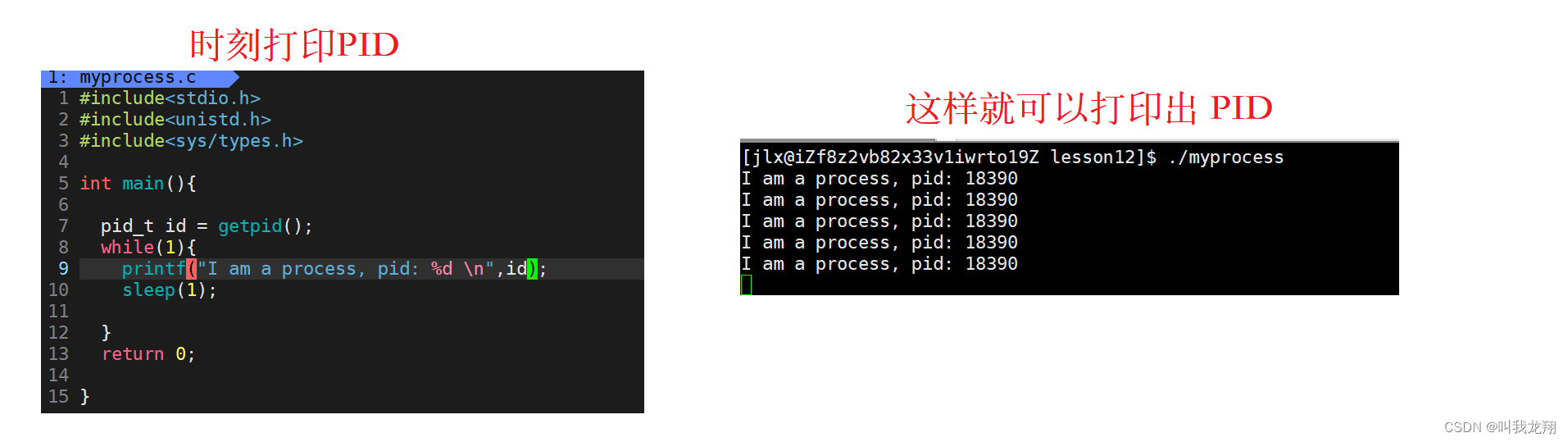
我们验证一下,PID是否正确:

显然 pid 的打印是正确的!!!
我们可以成功进行进程了,那么有没有方法可以结束进程呢???
当然有了!
kill -9 pid 就可以干掉想要结束的进程了,(kill是不是非常霸气!!!,起码把微软的结束进程霸气多了)
我们来尝试一下:可以看到我们成功kill 掉了正在进行的进程!

记住:
- Ctrl + C 就是在用户层面终止进程,kill -9 pid 可以用来直接杀掉进程!!!
3.4 进程创建
首先来解释一下父进程,ppid 是父进程的ID
pid_t getppid()返回父进程的ID,而子进程是由父进程创建的,这里只做了解。
下面演示一下如何获取父进程的ID:
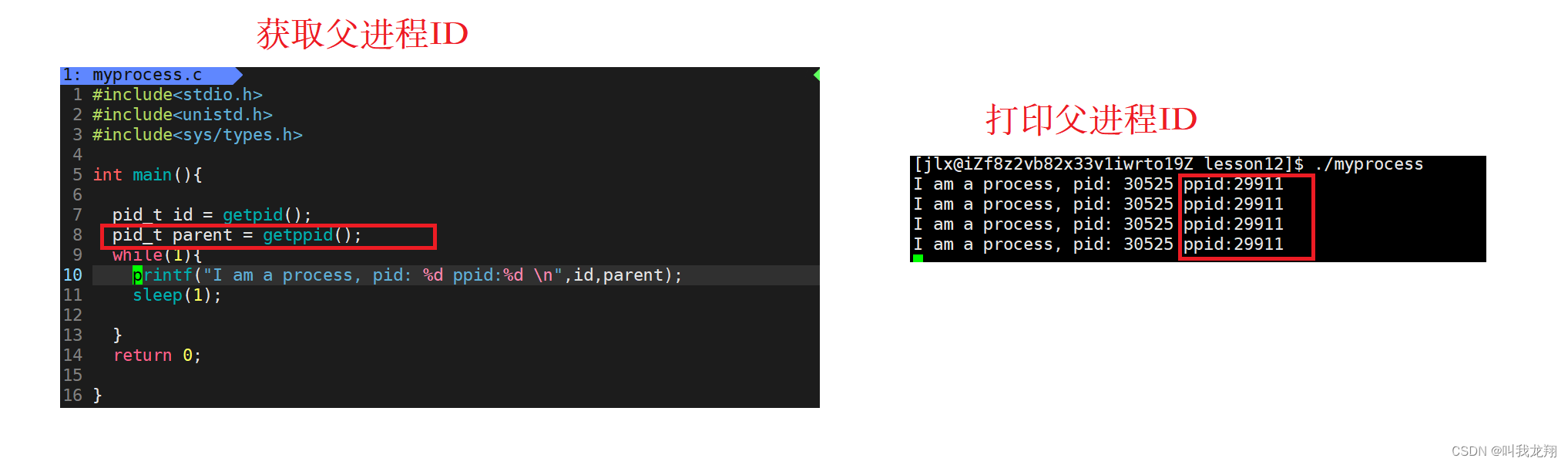
这样我们就获取到了父进程ID。
当我们多次运行时,每次进程PID都是不同的,但是父进程ID是相同的(每次运行 PID 不同是正常的)
那我们追溯一下这个父进程到底是谁
同样使用grep差找到该进程

可以看到的 父进程是bash,什么是bash???可以先理解为命令行解释器。目前还没有深入探讨的能力
接下来我们来尝试是否可以手动实现创建子进程
首先来认识一下 fork函数
fork() (可以通过运行 man fork 认识fork)
- fork有两个返回值
- 父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
- 创建一个进程,本质是系统中多一个进程,多一个进程,就是多一个内核task_struct
- 父进程的代码和数据是从磁盘加载来的,子进程的代码和数据会默认进程父进程的代码和数据
为什么要创建子进程呢:因为我们想要通过子进程与父进程执行不一样的代码,在特殊情况下可以提高运行效率。
接下来我们来认识一下fork()函数的返回值,因为他两个返回值(与以往的认识函数不一样)。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4
5 int main(){
6
7 printf("process is running ,only me! pid: %d \n",getpid() );
8 fork();
9 pid_t id = fork();
10
11 if(id == -1) return 1;
12 else if(id == 0){
13 //child
14 while(1)
15 {
16 printf("id : %d I am child process,pid: %d, ppid: %d\n",id,getpid(),getppid());
17 sleep(1);
18
19 }
20 }
21 else{
22 //parent
23 while(1){
25 printf("id : %d I am parent process,pid: %d, ppid: %d\n",id,getpid(),getppid());
26 sleep(2);
27 }
28
29 }
30
31 }
简单写一下测试程序,来看效果:
可以看出是成功运行出子进程和父进程

刚才的代码,在9 行 fork()之后,子进程和父进程是共享的,因为我们进行了判断,所以子进程与父进程会执行不一样的代码,在之前学习的语法中,if 与 else 的代码不可能一起运行,这是因为之前学习的都是单进程,在多进程中可以做到,即使这样,那也也有很多疑问:
- 同一个 id 为什么可以即等于零 又 不等于于零???
- fork()两个返回值是怎么回事???
问题1 涉及虚拟地址空间,我目前还没有了解。
那我们来看fork函数(由OS提供),在代码执行的过程中,子进程就已经存在了,可以被调度了。
在任何操作系统中,进程一定要做到:进程具有独立性 ,PCB = 内核数据结构task_struct +代码与数据(只读)
那么如何查看该进程使用了哪些数据和代码呢???
使用ls /proc/pid -d就可以查到该进程的数据:

我们详细展开即可查看:
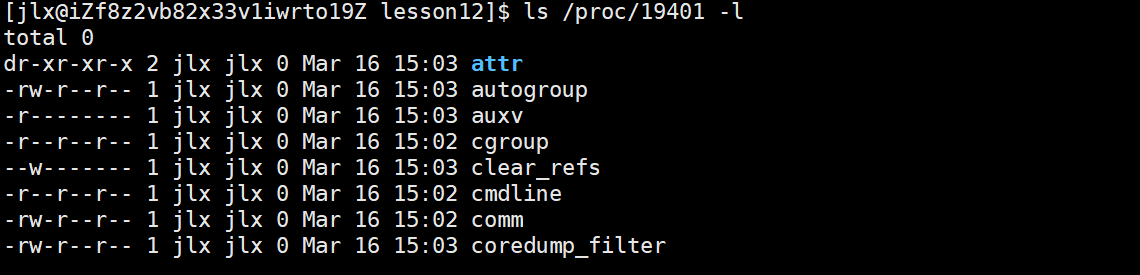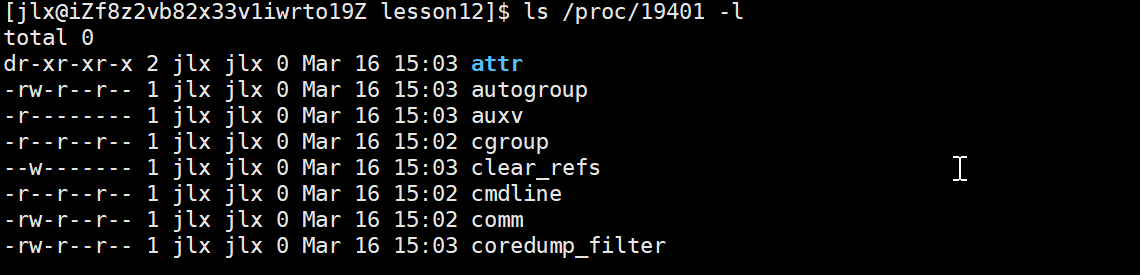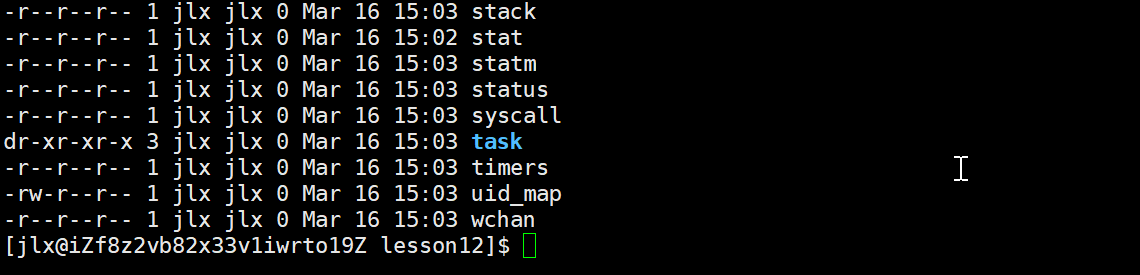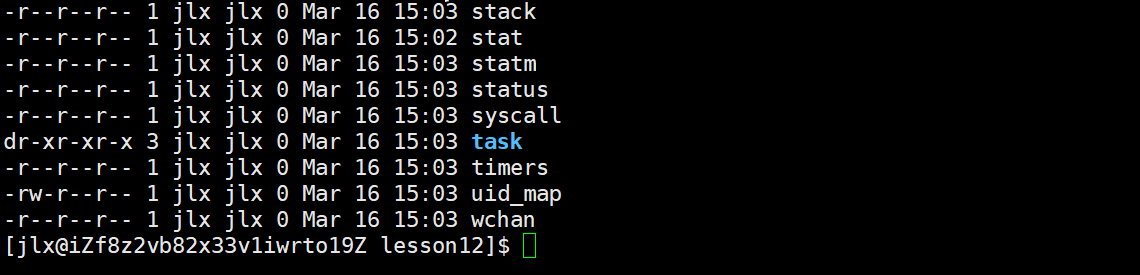
其中的exe 指向 是从什么路径下的文件加载的可执行程序。
在进程结束之后对应路径也会被销毁。
总结
- 进程 = 内核task_ struct结构体 + 程序的代码和数据
ps ajx可以查看我们的进程,为了方便演示我们使用grep来进行一下筛选:ps ajx | grep myprogress- PID : 每一个进程都要有自己的唯一标识符,叫做进程PID
pid_t getpid()获取pid- 当我们多次运行时,每次进程PID都是不同的,但是父进程ID是相同的(每次运行 PID 不同是正常的)
fork()有两个返回值,父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝),创建一个进程,本质是系统中多一个进程,多一个进程,就是多一个内核task_struct ,父进程的代码和数据是从磁盘加载来的,子进程的代码和数据会默认进程父进程的代码和数据
送给大家一句话:
我从来不相信什么懒洋洋的自由。我向往的自由是通过勤奋和努力实现的更广阔的人生。。——山本耀司