基于计算机视觉的图书推荐应用【AI编程实录】
我相信这篇文章的许多读者都有一个“抽屉”,里面装满了未完成的很酷的业余项目。由于AI每天都在帮助我的团队编写代码,我决定试一试,看看它能让我在一个我最喜欢的业余项目中走多远,最好是用最少的代码编写。
由于我对它能走多远感到非常惊讶,我决定写下我的经历,并检查“无代码人工智能编程”能走多远的极限以及实际的局限性。这篇文章(实际上是这个系列)将描述这段旅程。
1、简介
我酝酿这个想法已经很多年了——一个只需拍照就能推荐书籍的应用程序。正如所说,我通常忙于客户项目。但在最新AI工具的帮助下,我决定试一试。事情并不总是一帆风顺的——计算机视觉和文本识别给我带来了一些意外。但令我惊讶的是,我设法以比我预期快得多的速度得到了一个好的原型。即使在你不是专家的领域,人工智能也能帮助将想法变成现实,这真是太神奇了。这段旅程既令人谦卑又令人兴奋,我迫不及待地想看看它会带来什么。
宣传语如下:“想象一下,你走进一家书店,你真的想买一本书,但买哪一本呢?此外,可能还有一张打折的桌子,周围散落着许多书,等着你选择一本或多本,但同样,选哪一本呢?我希望有一个应用程序可以解决这个问题,而不是无助地四处寻找。进入 Book Shazam:拍一张这个场景的照片,然后获得书籍的个性化评分。”
那么为什么是现在呢?在我们公司 Shibumi AI,我们已经使用 LLM 很长一段时间了,大约从 2021 年 API 发布开始。我们还利用 Copilot 完成各种编程任务。当然,我们使用 Web UI 本身来编写文本、总结文本等等。偶尔,我们会尝试在 Web 应用程序中编写代码(无论是 ChatGPT 还是 Claude)。
直到最近,结果都不是特别令人印象深刻。但最近,特别是自 Claude Sonnet 3.5 发布以来,我们感觉到可以使用此工具创建真正的软件项目,尽管很简单。我们到处尝试(也看到其他人这样做)浏览器扩展、简单的应用程序等。因此,我决定是时候站出来构建一个稍微复杂一点的产品了。这一系列帖子记录了这个过程。
此外,最近一直在讨论非开发人员是否以及何时能够使用 AI 创建成熟的应用程序或产品。在这个项目期间,我牢记这个讨论并尝试:
- 不要触碰代码,或者至少尽可能少地触碰
- 特别注意那些对我这个技术人员来说可能很容易,但对非开发人员来说却有点挑战性甚至非常具有挑战性的任务。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
2、规划项目
总体而言,这不是一个超级难的项目,但它有挑战性。此外,作为一名数据科学家,我更擅长 Python 和 ML 模型,而 JavaScript 和 UX 则较弱。但 LLM,尤其是 Claude,让我感觉范围缩小了。所以让我们开始吧。
首先,让我们稍微分解一下产品——我们需要构建:
- 用户界面
- 计算机视觉(检测和 OCR)系统
- 推荐引擎
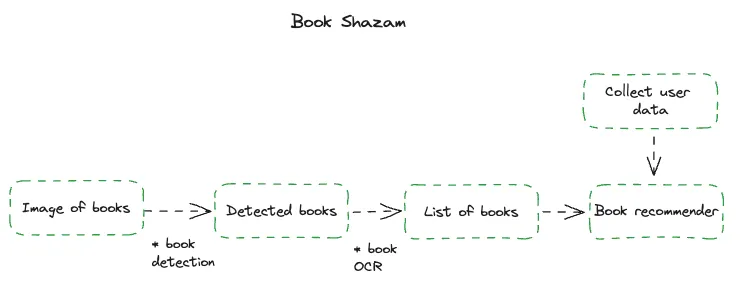
显然,实施先进而酷炫的解决方案(例如尖端的推荐器和 OCR)很诱人,但我们将采用简单的产品方法。
任何新手产品经理都会为你画出类似这样的图:
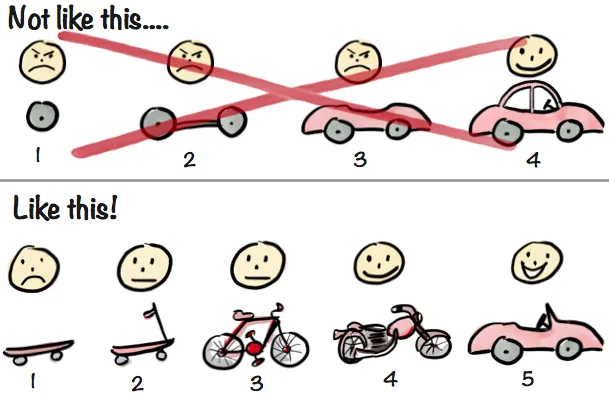
这个草图通常意味着从开发的早期阶段开始,你就应该有一个可行的解决方案。换句话说,你不应该在最终的 1.0 版本准备好并发布之前对其进行开发,因为在整个期间你不会得到任何用户反馈。你应该做的是从一个丑陋的简单工作解决方案和 MVP(最小可行产品)开始,并在每个阶段根据用户反馈逐步改进它。我们将采用这种方法。
因此,我们将这样完成我们的任务:
计算机视觉系统:具有简单的用户界面,这将是应用程序的支柱。我们希望具有上传图像、检测书籍、识别其名称(OCR — 光学字符识别)和单击它们的功能。我们将让 Claude 处理所有事情。
推荐引擎:目前最简单的推荐引擎就是“询问 LLM”。我们需要处理冷启动问题(没有新用户的数据),因此我们可以简单地要求用户输入他们最近阅读并喜欢的几本书(我知道这很基本)。我们将在下一篇文章中处理这个问题
UX:在拥有一个“可运行”的系统后,我们将优化用户体验:
- 使设计看起来更美观、更现代
- 使流程更友好、更流畅。
更多功能:
- 为了使这个应用程序更具功能性,我们将添加一个登录系统,让用户可以多次使用该应用程序。
- 最终,我们将把应用程序部署到云端,让用户可以访问它。
- 超出本系列的范围,我们可以为应用程序添加更多功能,例如对不在图像中的书籍进行评级等等。
3、流程—书籍检测
让我们首先讨论使用 LLM 进行开发的一般方法:如前所述,Claude 的能力将我们带到了 LLM 开发的 0.2 版。0.1 版本是 GPT4(和 4o),它主要返回有时有效的代码,并且每个任务都需要进行几次迭代。
在 Claude 中,情况会好一些:代码版本会作为工件保存,你可以管理一种对话(有时包括编辑模型消息以进行错误的转变)。
Claude 还包括“预览”功能,允许在编辑器本身中运行简单的脚本。这似乎是一个小功能,但在我看来,对于非开发人员来说至关重要。我们不会在本演练中使用它。
当你要求 Claude 编写代码时,应该:
- 非常具体。
- 清楚地写出所有必需的功能。
- 不要写得太长。
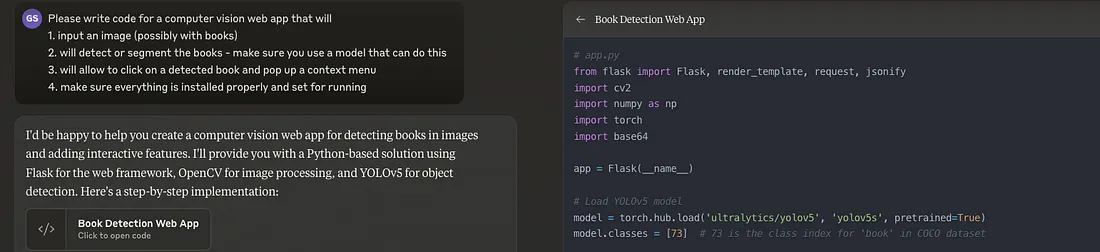
所以我要求以下内容:

请注意,这是使用 LLM 执行编程任务的良好做法:
- 如果模型在某个部分严重失败,您可以使用相关部分的“强化”编辑请求(如您在“确保”中看到的 - 根据我在计算机视觉任务中的经验,模型经常变得懒惰并选择无法真正处理任务的模型。)
- 另外,请注意,我给了模型选择技术的自由 - 它可以选择 JavaScript 或其其中一种风格(例如 React)......实际上,它选择了 Flask - 这极大地影响了整个架构 - 而不是在浏览器中运行整个模块,我们将在这里拥有一个服务器/客户端系统。这种选择有利有弊。但是,由于我们计划在应用程序中使用 LLM,因此目前将密钥保留在服务器上会更容易。此外,我对 Python 感觉更舒服,所以我现在不会抱怨。但我们以后可能会想要一个仅限客户端的应用程序。
为了测试目的,我们将配备一张测试图像:

Claude 有一个漂亮的用户界面,左侧是文本,右侧是代码(“工件”)。它以 Python、HTML 和 Javascript 格式返回输出,但将代码存储在一个文件中,并在注释中指出 — 我应该手动将它们分开 — .py 和 .HTML。
此外,Claude 还为代码添加了清晰的说明和解释,这可能对使用代码和更好地理解代码都非常有帮助。如果你想边构建边学习,这是一个非常有用的工具。
将文件放到位后,我按照 Claude 的说明运行了 python app.py,得到了以下结果应用:

应用的第一个打开屏幕
非常丑陋,但现在我们正在尝试让它工作,设计将在稍后完成。
文件上传和图书检测工作正常 - 除 2 本外,所有图书均能被检测到。但有一个错误 - 单击一本书不会执行任何操作。

检测结果
由于我们正在与 Claude 交谈,我可以简要地记录下故障,Claude 将尝试修复该错误:

Claude 重写了 HTML 代码,现在它可以工作了,请参见下面的“获取信息”弹出窗口。

现在剩下的就是在弹出窗口中填充内容——稍后再添加书名和评分。我会让 Claude 插入一个 OCR 组件:

Claude 选择使用 Tesseract — 带有 Python 包的最通用 OCR 工具。它不是最好的工具,但它是最新的并且随着时间的推移不断改进,所以我们来试一试:


显然,如上所示,Tesseract 不起作用。在大多数书中,它都找不到任何东西,在一些书中它检测到一些乱码,只有在一本书中它检测到文本(不是最清晰的文本),这让我认为它出现了某种故障。
所以让我们再给它一两次机会。

于是Claude对代码做了一些改进,但是效果仍然不太好。

我认为我们可以进一步改进 Tesseract,而且对于所谓的“野外文本”有更好的包装,但是我们目前想要快速行动,所以有时给 Claude 指明正确的方向是件好事:让我们使用非常好的 Google vision API。

Claude 遵从命令,用 Google Vision 替换了 Tesseract 代码,剩下的就是从 Google 复杂的界面获取服务帐户密钥。这项任务对于非开发人员来说可能有点困难,但 Claude 会在这里提供说明。将一切准备就绪后,OCR 就可以正常工作了:

这并不难,而且让我们完成了项目的重要部分,让我们庆祝一下吧!
4、分析
但是,等等,让我们想一想。我们渴望继续前进并完成 MVP。但是,既然应用程序的这么重要部分已经准备就绪,让我们(在庆祝的同时)思考一下实际将其产品化还缺少什么(除了我们之前讨论过的推荐器和用户体验)
- 计算机视觉优化
- 架构和部署
4.1 计算机视觉
我们这里有两个任务:
- 检测
- OCR
我们以一种黑客的方式用一张图片推进,并见证了以下结果(见上面的检测结果图片):
- 检测到 17 本书(真阳性)
- 2 本书未检测到(假阴性)
- 2 个假阳性
未检测到的书籍应该得到处理。让我们看看 Claude 做了什么。
查看代码,Claude 为我们选择了经典的 Yolo5 模型,该模型在 COCO 数据集上进行了预训练,并“突出显示”了书籍类别,幸运的是,该类别包含在数据集中。

但是,它也选择了“S”模型,这意味着模型很小。
我们可以:
- 用更大的模型替换模型(不用想)
- 用 Yolo v8(一种具有更高准确度的较新模型)替换模型
- 用专门针对书籍进行训练的模型替换模型(需要输入一些详细的结果表)
- 自己微调模型(需要我们撸起袖子)
从快速实验来看,将 Yolo-small 更改为 Yolo-medium 确实可以改善结果。
为了真正获得详尽的结果,我们需要收集更多图像作为测试集。假设约 100 张,在不同设置和光照条件下 - 但这超出了本文的范围。
这种计算机视觉优化是 Shibumi 的专长之一。
4.2 架构和部署
此应用程序目前仅在我的机器上运行。为了使用户可以使用它,我们需要做一些基础工作:
- 使用更好的服务功能包装应用程序(例如 gunicorn、docker)
- 优化服务时间和流程:目前,代码似乎为每个 API 调用实例化模型,这不是最理想的。我们需要优化此流程以使我们能够为多个用户提供服务
这些项目和其他项目对于将此类应用程序从 MVP 阶段转变为完整工作的应用程序至关重要,这也是我们在 Shibumi 中主要做的事情。我们将在稍后阶段处理它。
5、结束语
正如所说,我们似乎处于“使用 LLM 编程”的 0.2 阶段。我们正在探索其功能和局限性。
主要限制之一是编程中的一些小而烦人的事情——在代码中插入一些密钥(正如我们在 Google API 的服务帐户 jey 中看到的那样)、设置服务器和修复一个小错误。
作为开发人员,解决这些问题是我们工作的一部分。但对于非开发人员来说,这些可能是严重的阻碍。在 0.3 版或更高版本中,有多少这样的事情会消失?有多少将通过外部工具(例如 Replit 或 Cursor)解决?很难知道。但我们专注于我们现在拥有的东西。
现在就这些。在下一部分中,我们将添加推荐系统。
原文链接:用AI编程的实践记录 - BimAnt