CARLA Drone: 首个实现从不同空中视角进行单目3D目标检测,并提供数据集
CARLA Drone: 首个实现从不同空中视角进行单目3D目标检测,并提供数据集
Abstract
现有的单目3D检测技术存在一个严重的限制。它们通常只能在有限的基准测试集上表现良好,要么在自车视角表现出色,要么在交通摄像机视角表现出色,但很少能同时在两者上表现良好。为了促进这一领域的进展,本文倡导对3D检测框架进行不同相机视角的扩展评估。我们提出了两个关键贡献。首先,我们引入了CARLA无人机数据集CDrone。该数据集模拟了无人机视角,大大增加了现有基准测试集中相机视角的多样性。尽管它是合成数据,但CDrone代表了一种真实的挑战。为证明这一点,我们确认了现有技术难以同时在CDrone和一个真实世界的3D无人机数据集上表现出色。其次,我们开发了一种名为GroundMix的有效数据增强管道。其独特之处在于使用地面来创建训练图像的3D一致性增强。GroundMix显著提升了一种轻量级单阶段检测器的检测准确性。在我们扩展的评估中,我们达到了与之前最先进技术相当或显著更高的平均精度,且适用于所有测试数据集。
项目地址:https://deepscenario.github.io/CDrone/
Introduction
检测交通参与者对提高道路安全和开发可靠的自动驾驶汽车至关重要。而从单幅图像中检测3D物体尤其具有挑战性。然而,以往的单目3D目标检测研究主要集中在自车视角,这仅提供了对交通的有限视角。通过利用广泛可用的监控摄像头,甚至无人机搭载的摄像头,可以获得更全面的理解,这些都可以在图1中体现出来。这些交通场景中的视角多样性为3D目标检测带来了独特的技术挑战。不出所料,当前的最先进技术往往仅能在特定视角下表现良好,而难以对其他相机视角进行准确预测。
为解决上述局限性,我们的工作提供了两个贡献。首先,我们设计了一个包含三类相机视角的综合基准测试集:自车视角、交通监控视角和无人机视角(参见图1)。该基准测试集的目标是对单目3D检测方法进行不同相机视角下的“压力测试”。这与之前仅关注单一视角检测的工作形成对比。自车和监控视角的数据可以从现有数据集(如Waymo和Rope3D)中轻松获取。然而,交通场景的真实世界无人机图像非常稀缺。因此,我们利用CARLA模拟器生成了一个带有精确3D注释的合成无人机数据集CDrone。为了支持CDrone的研究价值,我们展示了在内部真实世界无人机数据集和合成CDrone上的实验结果的一致性。
作为我们的第二个贡献,也是朝着单目3D目标检测器多功能性迈出的一步,我们开发了一种有效的数据增强管道——GroundMix。它将一致性正则化的常见技术(如缩放、2D-3D一致性旋转以及MixUp)扩展到了单目3D检测任务。GroundMix的关键新组件利用了地面平面方程,从而实现了3D感知的图像编辑。具体来说,它将挖掘出的困难对象样本放置在估计的地面平面上,从而呈现出越来越复杂的训练场景。
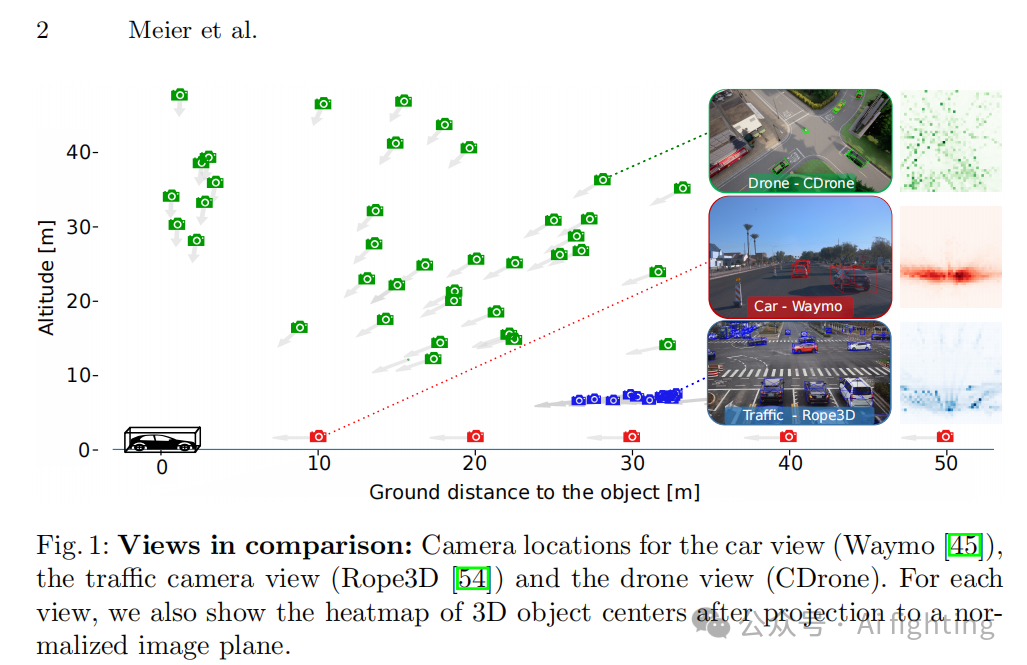
3. CDrone:一个新颖的无人机视角数据集
现有的无人机数据集主要提供2D标注,并且缺乏关键的3D边界框信息。这些局限性限制了从无人机视角开发和准确评估单目3D目标检测算法的研究工作。为弥补这一空白,我们引入了CARLA无人机数据集,简称CDrone。CDrone提供了全面的3D边界框标注。
数据生成与标注
一个用于3D目标检测的大规模、多样化的数据集CDrone的创建过程和特点如下:
渲染技术:为了实现更逼真的渲染效果,选择了CARLA模拟器,并在史诗级渲染模式下创建了多样化的户外场景。
数据生成选择:选择了CARLA而非AirSim进行数据生成,原因是在AirSim中获取3D边界框标注较为困难。
仿真环境:CDrone仿真环境包含42个地点,覆盖了城市和乡村景观。
场景录制:每个场景包含265辆车辆,以每秒12.5帧和1920x1080像素的分辨率,捕获了900张图像,包括夜间、白天、黎明和雨天场景。
场景内容:每个场景展示了户外驾驶场景,包括街道、交叉路口和其他交通元素。
无人机视角:无人机的高度范围从6.9米到60.6米,确保了目标检测器和地面真实边界框之间的准确重叠。视角角度从几乎垂直到几乎与地面共面,具有广泛的多样性。
物体深度:数据集保持了11.0米的最小物体深度,这增加了检测远距离物体的难度,使得任务更具挑战性。
数据集统计:CDrone数据集包含大量的不同类型对象,如汽车、卡车、摩托车、自行车、公交车和行人,并被划分为训练、验证和测试地点,分别对应不同数量的图像。
数据集划分:数据集被划分为24个训练地点,9个验证地点和9个测试地点,每个地点分别有不同数量的图像。
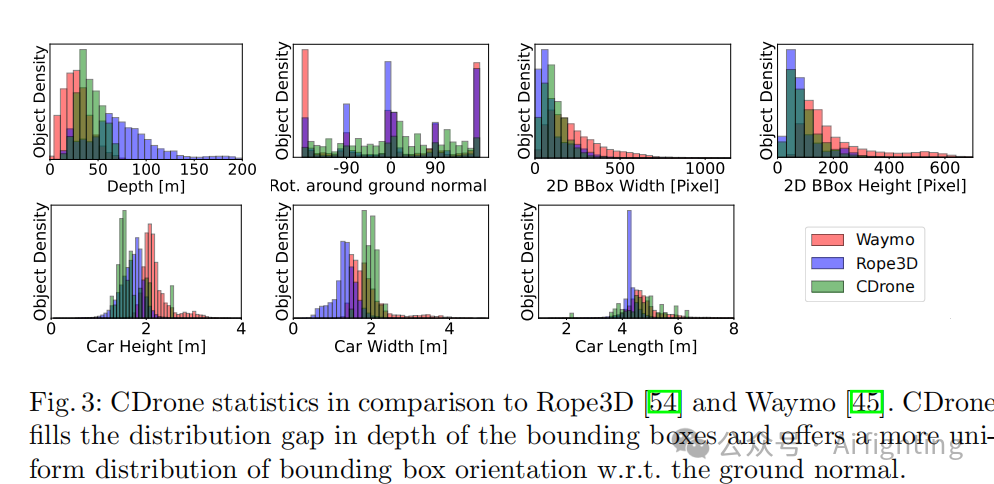
在图3中,我们将CDrone的数据统计与我们基准测试中使用的其他数据集进行了比较。首先,CDrone填补了Waymo和Rope3D深度分布模式之间的空白。CDrone中的3D边界框往往集中在距离相机较远的地方,但在大约80米处被限制住。需要注意的是,Rope3D中的交通视角允许看到更远的深度值。然而,与KITTI类似,Rope3D评估协议排除了高度低于25像素的远处物体。相比之下,CDrone评估考虑了所有可见物体。其次,与Waymo和Rope3D相比,CDrone的旋转分布更均匀,这突显了在无人机数据中旋转估计的挑战性。第三,物体通常具有较小的度量高度但较大的度量宽度。此外,与Waymo和Rope3D相比,物体长度分布具有更大的方差。这些特性使得物体尺寸的准确估计在评估中变得更加重要。
我们发布的标注格式与OMNI3D保持一致。我们通过将3D角点投影到图像上并在图像边界处截断它们来计算2D边界框。我们还为每个物体提供了跟踪ID,以便在未来的工作中促进联合跟踪与检测。
评估指标
按照既定的3D检测基准,本文采用广泛使用的平均精度(AP)作为CDrone的评估指标。考虑到较高的最小物体深度,在IoU阈值为0.5(APIoU=0.5)的情况下报告AP。与之前只评估围绕相机y轴旋转的基准不同,本文评估了类似于OMNI3D评估协议的3自由度旋转。
4. 从不同视角检测3D物体
4.1 问题陈述
单目3D目标检测涉及从RGB图像中提取特征,以确定每个物体的类别和三维边界框。设I表示具有内在参数K ∈ R^3×3的RGB图像,B(I) = {B1, …, Bn}表示I中包含的物体的真实3D边界框。每个边界框Bi由其相对于相机中心的位置(xi, yi, zi) ∈ R^3、尺寸(wi, hi, li) ∈ R^3、自中心旋转矩阵Ri ∈ SO(3)和物体类别ci ∈ N(例如“汽车”,“行人”)来参数化。训练样本由M个元组(Ij, Kj, B(Ij))M_j=1组成,本文的目标是逼近B(·)。
4.2 预测SO(3)旋转
出于实际考虑,我们使用轻量级的MonoCon单阶段3D目标检测器作为基线。与CenterNet类似,MonoCon通过类热图检测物体,使其适合实时自动驾驶应用。这与更昂贵且报告不稳定的Cube R-CNN形成对比。MonoCon只预测围绕相机y轴的旋转,假设其他旋转角度与相机的角度一致。这限制了MonoCon在没有提供地面平面方程的情况下进行完整的3D方向预测,从而限制了其对不同相机视角的泛化能力。本文通过预测6个值并通过Gram-Schmidt正交化将其转换为旋转矩阵来扩展MonoCon以预测完整的3D旋转。本文将标注转换为相对于相机的Lie群SO(3)表示,并在训练期间使用allocentric方向,在推理期间恢复到egocentric格式。
4.3 GroundMix:在地面平面上增强数据
为了提高MonoCon的检测精度,引入了GroundMix,一种新颖的数据增强管道。图4展示了该管道的概述。关键思想很简单:将物体贴片放置在物理上合理的地面平面位置上,这一假设仅在训练期间可用。
A. 拟合地面平面 采样位置 在自动驾驶的背景下,物体往往位于一个公共的地面平面上。基于这一假设,我们首先使用最小二乘法估计来拟合这个平面,需要三个物体。由于大多数数据集满足这一标准(Waymo: 79.5%,Rope3D: 98.5%,CDrone: 96.8%),我们在至少存在三个物体时执行贴片粘贴。尽管我们可以使用单个物体的底部角点,但使用三个不同的物体可以提高估计的鲁棒性。平面方程和物体标注允许我们通过随机采样像素并将其反投影到地面平面上来采样候选3D目标位置。
B. 硬采样 / D. 贴片缓冲区 在拟合地面平面后,我们对粘贴对象进行了难例挖掘。虽然我们可以从这个列表中均匀地进行采样,但我们发现了一种更有效的方法:在训练期间我们对难例进行过采样。我们使用直接归因于对象的所有损失项(例如深度损失、尺寸损失、旋转损失)来衡量每个对象贴片的难度。在粘贴时,我们从最具挑战性的20%案例中进行选择。随着训练的进行,最初困难的对象变得容易,从而使算法能够专注于越来越具挑战性的样本。
C.软粘贴 理想情况下,我们希望以真实感的方式粘贴图像补丁。然而,我们观察到两个障碍。首先,目标图像与源图像之间的焦距可能不同。其次,目标位置在深度方面可能与源位置有所不同。考虑到这些挑战,我们通过公式
![]()
来重新缩放补丁,其中和 分别表示前一张图像和当前图像的深度,和分别表示源图像和目标图像的焦距。此外,我们希望避免源图像和目标图像之间出现明显的边界。因此,我们使用 MixUp 方法从边界到中心线性增加补丁的不透明度。为了增加检测难度,我们还在中心区域应用了 MixUp ,不透明度范围为 80%-100%。
4.4 具有3D一致性的2D数据增强
我们利用了常规的2D图像增强策略,同时特别注意调整对应的3D边界框注释以保持一致性。具体来说,我们应用虚拟深度以实现尺度增强,并在相机内部参数变化的情况下对齐焦距。为了适应无人机视角的广泛变化,我们在训练过程中采用了2D-3D一致的旋转增强,以增强视角的多样性。这涉及在相机 z 轴范围内 [−π, π] 旋转场景。考虑到在宽屏图像中靠近90°或270°的旋转可能导致边界物体消失,我们通过在图像中心附近采样旋转来引入多样性。此外,我们通过用重新投影的3D框替换紧密的2D边界框来确保2D/3D一致性。
Experiment
5.1 主要结果
我们在四个具有不同摄像机视角的数据集上评估了我们的增强管道 GroundMix。我们的主要目标是提高交通摄像机和新颖的无人机视角下的检测精度,同时在研究较多的汽车视角场景中保持竞争力的检测精度。
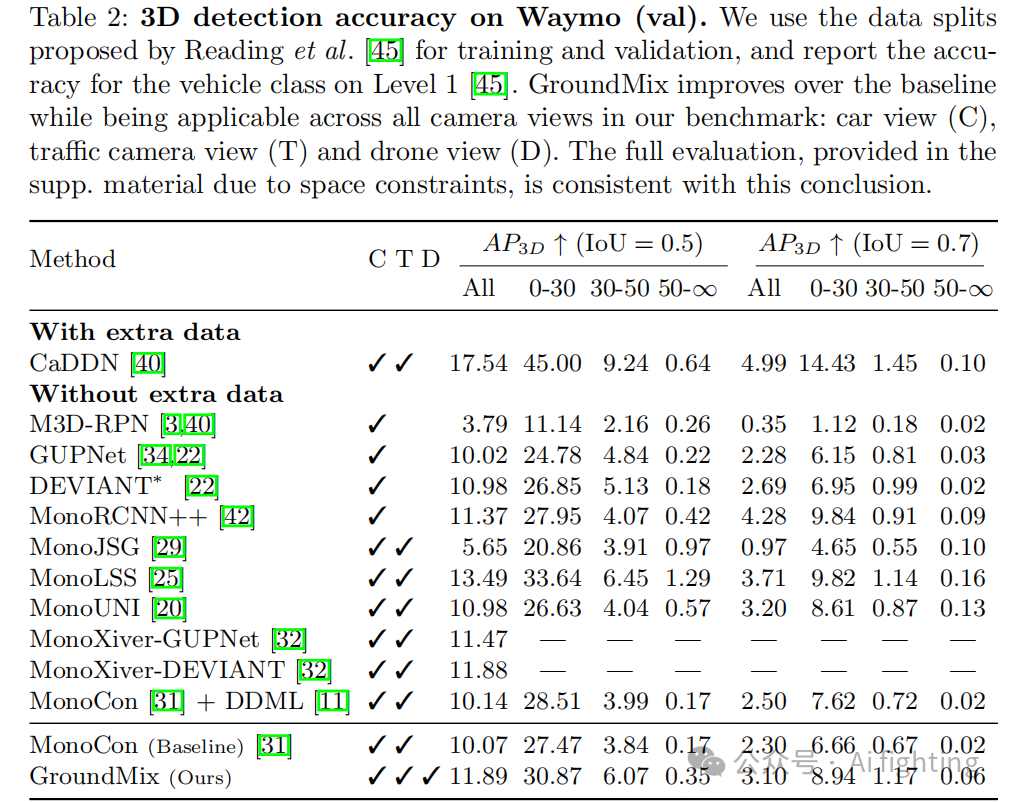
我们使用 Waymo 正面图像,并应用分割方法,使用 52,386 张训练图像和 39,844 张测试图像,并报告车辆的 AP 表现。表 2 展示了评估结果。
在表3中展示了评估结果。GroundMix 在所有现有基于图像的方法中展示了卓越的检测性能,也显著提升了我们基线的表现。我们估计了完整的3D旋转,这使得我们的方法完全独立于 Rope3D 提供的地面平面方程。我们的方法在汽车类别上设定了新的最先进检测准确度。在所有情况下,我们也超越了专门针对交通摄像机视角的 BEVHeight 和 CoBEV 方法。
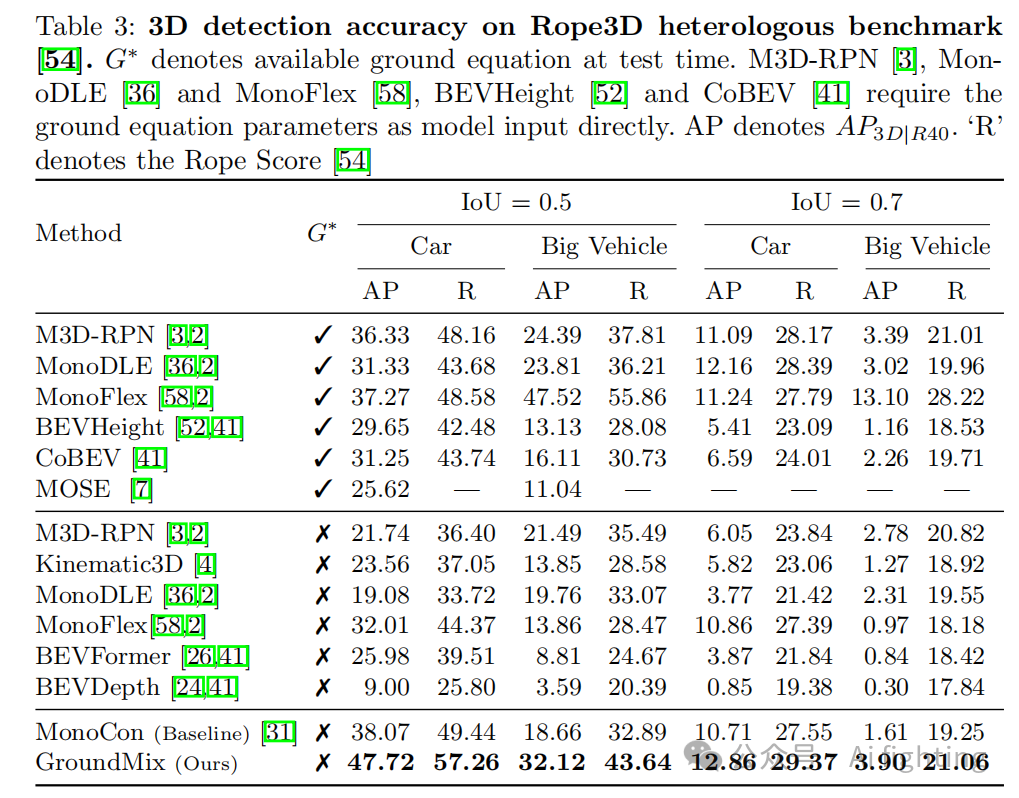
表4报告了在无人机视角场景下的结果,该场景以多样化的摄像机视角而著称。

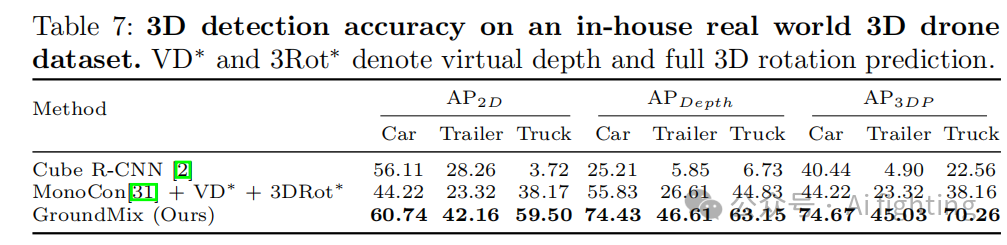
表7中展示了评估结果。由于数据集包含不同焦距的图像,并且不提供地面平面,我们将 MonoCon 的单角度预测扩展到 SO(3) 并利用虚拟深度。在这里,我们提出的方法与基线 MonoCon的唯一区别是增强管道。GroundMix 显示出优于我们基线和 OMNI3D的表现,证明了我们的增强管道的有效性,并支持了从合成 CDrone 数据集中得出的结论。
结论
文章的贡献如下:
1.扩展了标准评估协议到多个相机视角,引入了一个新的基于无人机的合成数据集CDrone。2.进一步设计了一种有效的训练策略,该策略利用了一个新的数据增强管道GroundMix。通过展示GroundMix中增强技术的互补性,我们显著提高了基线检测器的检测准确性,并在我们的多视角基准测试集上大幅超越了最先进技术。
引用文章:
CARLA Drone: Monocular 3D Object Detection
from a Different Perspective
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术,关注我,一起学习自动驾驶感知技术。