虚拟化云管服务奥创的优化升级以及多集群下VPC网络实现
01
背景介绍
奥创(Ultron)是360内部虚拟化功能的云管服务, 通过封装虚拟化相关功能, 统一对外提供虚拟化openstack相关api等服务, 可以理解为openstack集群的一个统一网关服务,对内支撑平台HULK等平台,提供云计算相关功能。目前虚拟化提供的包括云主机,云硬盘,云网络,安全组,裸金属,负载均衡等功能均由奥创统一对外提供服务。但是随着功能的不断丰富、用户数量的增加,同时对极致的追求,诸多问题逐渐暴漏出来,对集群的性能、稳定性、维护性等各方面提出了新的挑战。
02
历史版本V1
由标题能够看出奥创是存在一个历史版本的,暂且叫v1 版本。v1 的服务以及组件如下:
组件 | 参数 | 用途及备注 |
|---|---|---|
python | 开发语言 | 基于python 2 |
rabbitmq | 消息队列 | 用于api和celery消息通信 |
mongodb | 数据库 | 持久化存储虚机等相关数据 |
celery | 任务处理 | 异步处理隔离机房的在线任务以及和openstack集群做数据同步 |
redis | 数据库 | 1. 存储openstack集群信息, 如A集群支持云盘, B集群支持本地盘等 2.缓存 openstack部分数据加速api查询 |
ultron | API处理以及任务处理 | API处理并处理非隔离机房网络下的任务 |
在开发运维过程中,遇到的相关问题:
持久化存储数据库使用了mongodb,mongodb本身为NOSQL,而非关系型数据库,在关联查询以及事务以及维护性等方面都不友好。
引入celery造成架构复杂,celery比较重,同时celery的任务使用多进程模式,资源消耗较大,有时有些不稳定。
redis 中hash了很多关于openstack集群的配置信息,利用hash做了很多关系型数据库所擅长的。
奥创集群不支持水平扩展,在openstack集群较多虚机较多时造成同步任务很慢甚至阻塞
....... 其他原因
03
新挑战
随着公司内云计算提供的功能越来越多,对性能等各要求也不断提高,面临如下相关的挑战:
虚拟化集群变多, 目前公司内有 40+套虚拟化集群,且混合多个版本的openstack集群。
虚拟化功能不断增多, 由以前仅有的云主机功能 逐步支持云硬盘,VPC网络,安全组,裸金属,负载均衡等
虚拟机数量以及计算节点数量增多, 目前已有 3W+ 的虚拟机,5k台计算节点。
虚拟机创建性能的要求,以前可能没有那么大并发,现在产品支持了可抢占,需要支持单次并发100台创建,并且要在1分钟内创建完
产品对标公有云,业务场景更加复杂,功能更丰富。
04
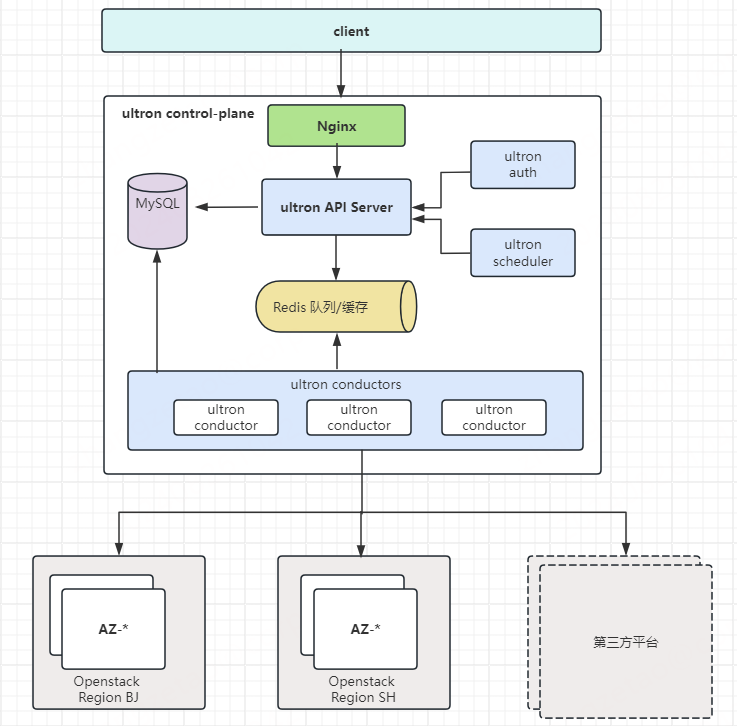
历史版本V2
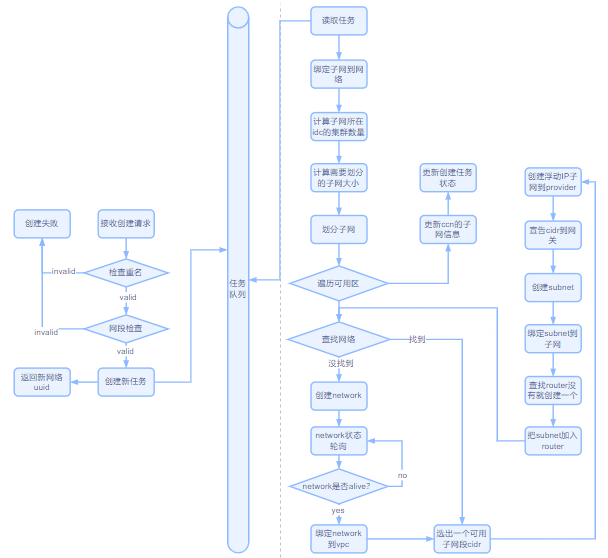
改进后新版本v2 基于go语言开发,go天然的并发优势,让架构更简单性能更好。同时将奥创组件拆分为api和conductor 角色,api只负责处理client的请求,请求校验完后将任务发到消息队列 redis ,conductor从消息队列中获取到任务后进行处理,角色之间职责清晰,同时数据库改为使用mysql,因为包括虚机,云盘,网络等存在很强的关联关系,一台虚机必然关联网络,安全组等,所以使用关系型数据库更加合适。Redis在集群中首先担任消息队列的角色,同时用于分布式锁以及数据缓存的使用。
具体服务以及组件如下:
设计 | 参数 | 用途及备注 |
|---|---|---|
开发语言 | go | 基于go 语言开发 |
消息队列 | redis | 1. 消息队列 2. 缓存临时数据 3. 分布式锁 |
数据库 | mysql | 持久化存储 |
API处理 | ultron-api | 只处理来自用户的api请求 , 对请求认证完后经调度模块调度后,将请求扔到消息队列中 |
任务处理 | ultron-conductor | 异步处理所有机房的在线请求以及定期和openstack集群做数据同步 |
架构图如下:
05
优化内容
如下罗列做的一些改进点:
改进1: 集群支持水平扩展
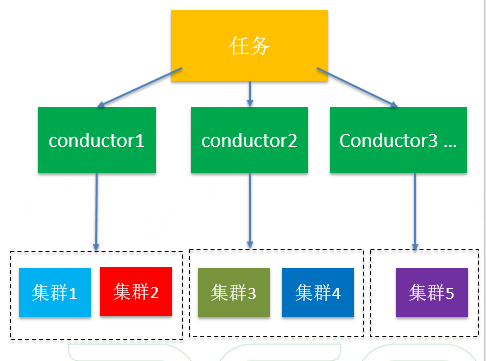
从性能考虑将奥创服务拆分为两个角色,api和conductor,api 负责接收处理http 请求,conductor负责消费任务,conductor负责与openstack以及公司内其他平台的交互工作。api和conductor之间角色清晰,通过消息队列解耦,两个组件都支持水平扩展,当有大量数据需要处理时可以考虑水平扩展。因为api 只处理HTTP请求,通过负载均衡自然可以实现水平扩展应对并发请求。conductor侧任务分为在线任务和离线任务,在线任务是用户请求的任务,离线任务是比如包括和openstack集群同步,以及数据分析等。conductor通过监听redis消息队列,在大量任务处理时可以考虑水平扩展应对。同时在处理离线任务时,通过将conductor进行分组,不同组处理不同openstack集群或者idc的任务,从而可以支持api和conductor的水平拓展。
改进2: 采用模块化单体设计
传统单体应用的危害大家都很清楚,出故障时犹如雪崩。由于奥创只服务公司内部没有那么大的量级,同时微服务自身架构复杂,依赖kubernetes,维护成本较高,所以从稳定性以及运维方面采用了模块化单体设计,通过docker-compose进行日常管理。
模块化单体架构的优点如下:
简单性 : 将应用服务按照功能拆分为多个小模块,相比较微服务庞大的架构而言,更易于理解和维护。
可维护性: 每个模块有自己的职责和功能,界限清晰,可以提高应用程序的可维护性。
可拓展性:每个模块只负责单独的功能,所以更容易拓展相应的功能。
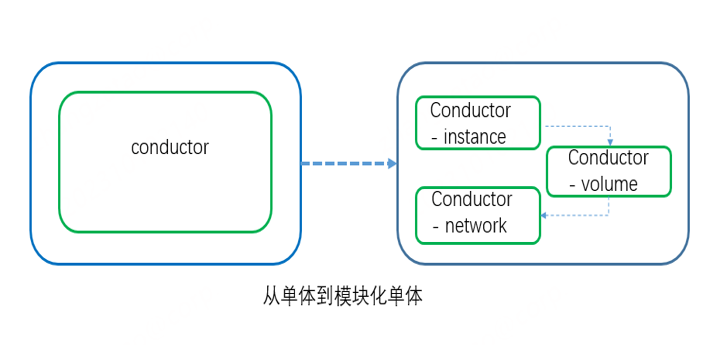
将奥创的api以及conductor按照不同的功能比如云主机,安全组,网络等功能拆分为不同的单体应用。
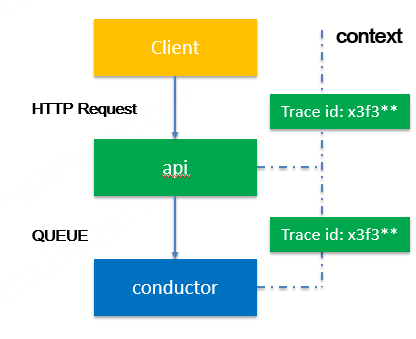
改进3: 引入trace id到日志中
随着api和conductor角色的加入,同时又拆分了模块化单体,组件的容器会变多,如果需要查询某时刻某工单的日志犹如大海捞针。通过引入trace id 将每次具体的请求标识一个唯一id,在整个任务处理的链路中,通过context 上下文传递到不同组件,每个组件的日志都标识该trace id,这样通过trace id就可以在系统中将整个调用路径串联起来。
改进4:奥创新vpc的实现
vpc网络结构:
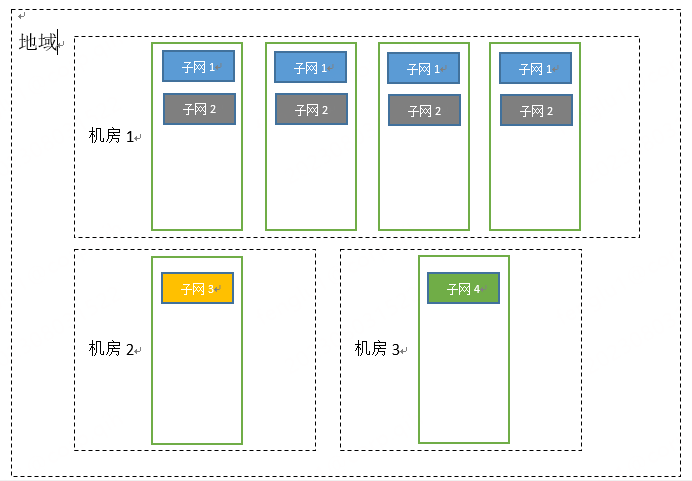
创建vpc分两步走:
1.现在某个区域,比如北京区创建一个vpc网络,这一步不会实质性的创建出网络实例,仅只是一个记录表示已经规划出一个网段空间了。因此不做着重说明
2.主要是第二步,创建vpc子网:
网段管理:
vpc的网段统一由hulk管理,根据具体用途和部门把11.0.0.0/8划分为多个掩码为/20的段,这也是每一个vpc的大小,一共包含4096个地址。
一个子网的地址范围是/22的段,包含1024个IP地址,所以一个vpc可以包含4个子网。每个子网都是在IDC内的,但是由于有的idc有多个openstack集群(一个openstack集群一个region),因此如果需要一个子网在所有可用区都能创建出虚机,就需要每个可用区都有该子网的网段。
由于我们目前一个IDC 下最多的有五个openstack 集群,为了都能覆盖到,我们把一个子网的/22的段划分为最多8个/25的小段。当前的划分原则:最大一个c,最少128个IP。
IP不足的补充问题:
多可用区的IP网段存在一个类似内存碎片的问题。
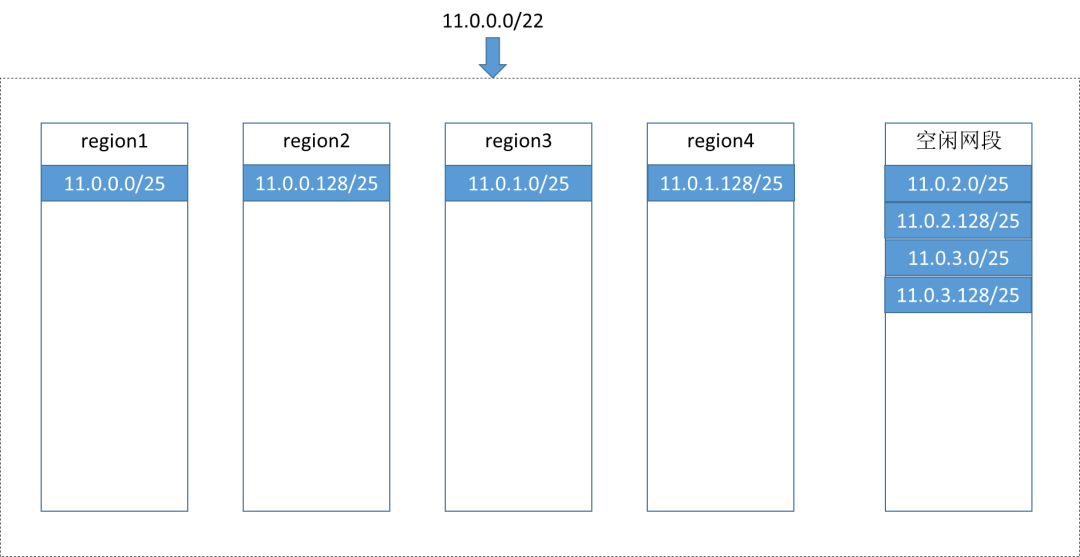
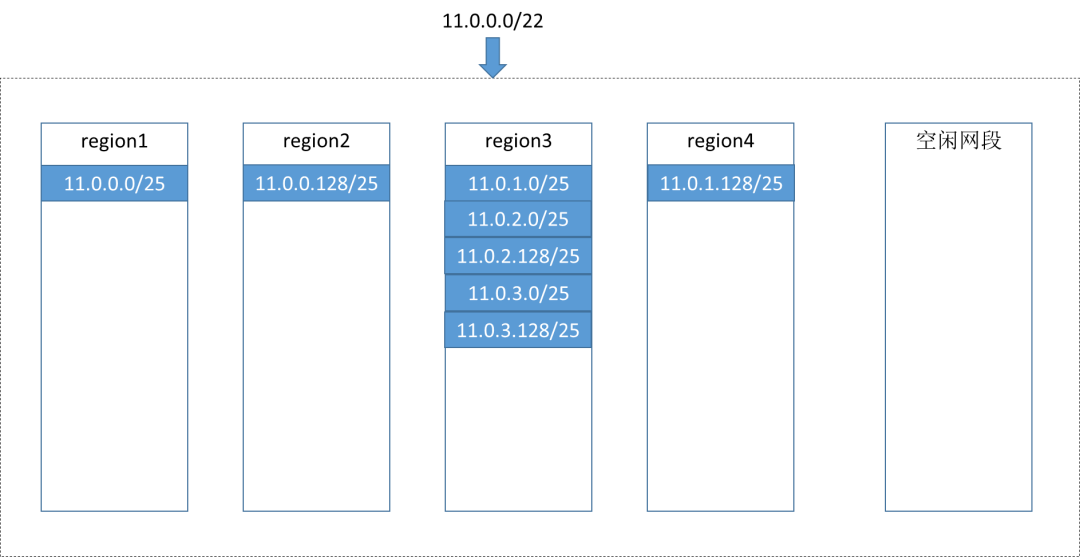
假如region3的计算资源比较充足,虚机创建就会一直选中region3,region3的IP很快就用完了,这种时候即使1,2,4仍然有很多剩余IP,因为region3已经没了,所以整个子网看上去也没有了
对于连空闲网段也没有了的情况:
原设计:附加网段
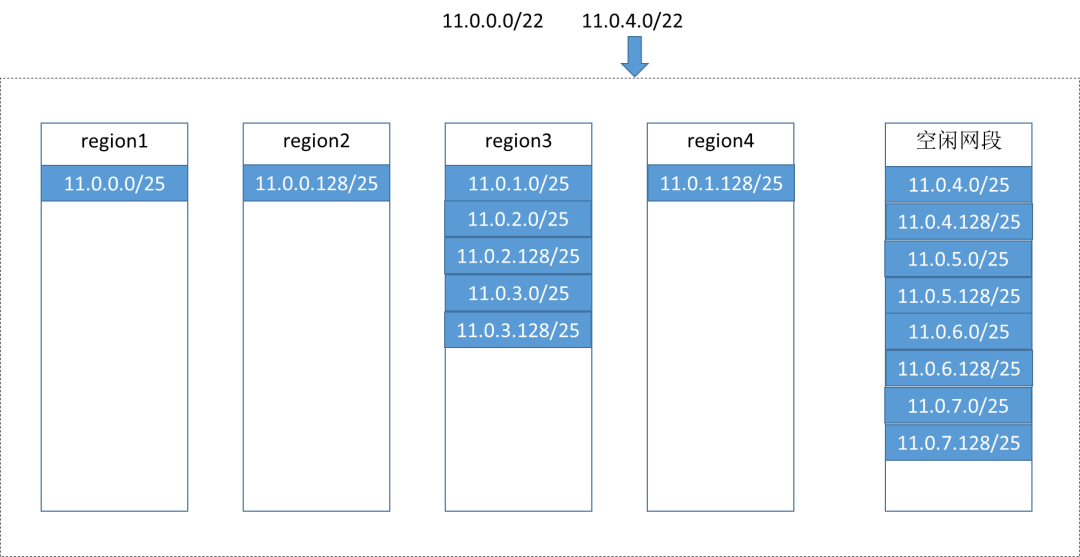
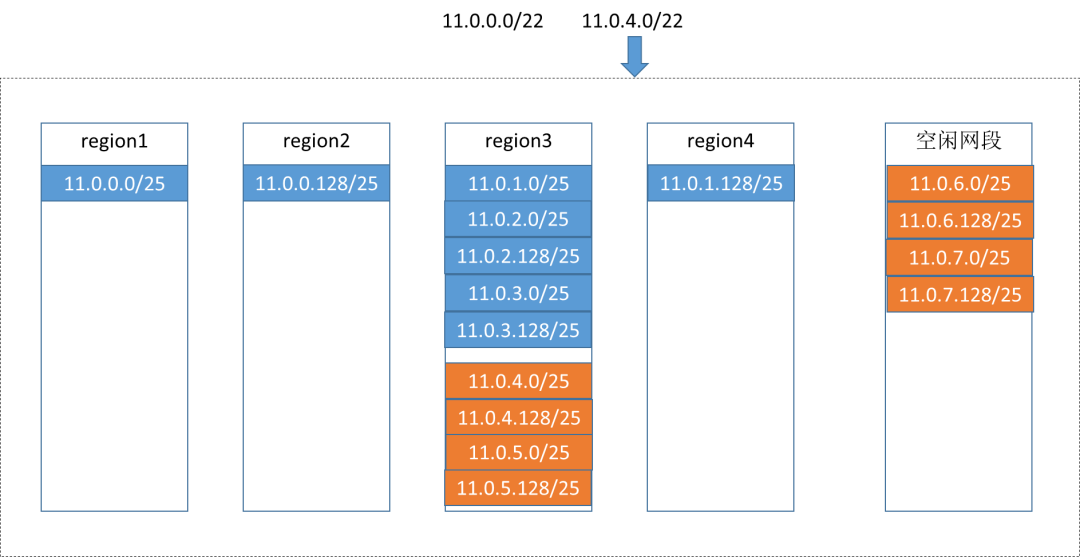
现在的方案:继续创建新的子网,新子网的网段继续被切分以后平均分给所有集群,哪怕有的集群实际上根本没有资源创建新的虚机。
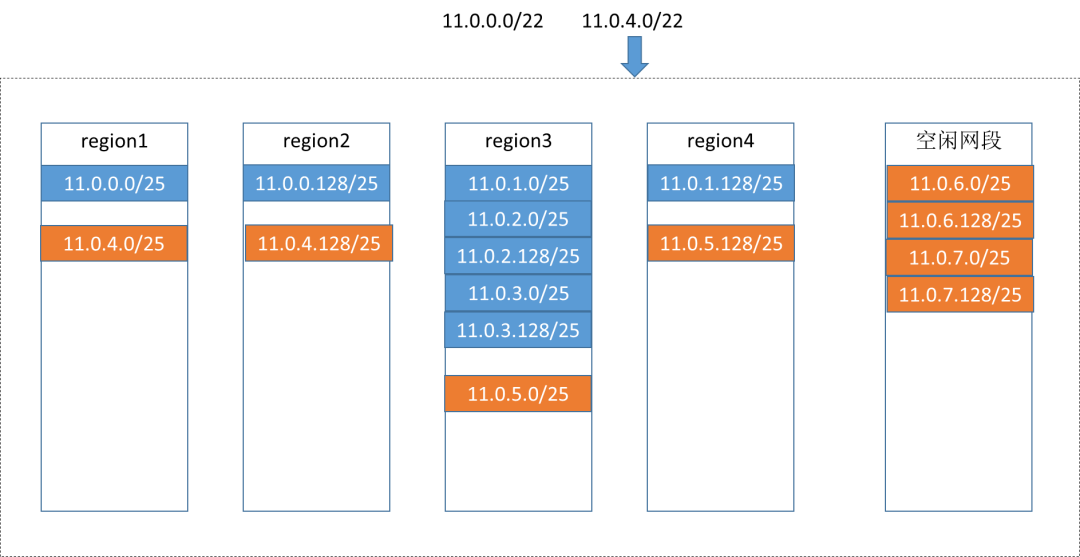
优化方案:可以在保证所有集群都有适当数量的IP地址的情况下,把新增的子网创建到指定的那个集群下,减少IP地址的浪费。
06
展望总结
本次奥创的升级优化主要从功能、性能以及后期的运维复杂度、稳定性等方面考虑,不仅要在开发设计上更贴近openstack产品,同时又要有能够应对后期openstack集群规模扩大的应对能力,同时还要尽量的能够降低运维复杂度,方便后期运维。目前奥创v2已经稳定服务公司内部HULK等平台,总体从在线离线任务处理时间等性能方面以及运维易用性等方面来看表现出色,当然本次升级优化并不代表该架构以及设计就是最优的,后期仍会不断优化改进。
360智汇云简介

360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
官网:https://zyun.360.cn
客服电话:4000052360