Kafka日志及常见问题
目录
1.Topic下的消息是如何存储的
1.1log文件追加记录所有消息
1.2index和timeindex加速读取日志信息
2.文件清理机制
2.1如何判断哪些日志文件过期了
2.2日志清理策略
3.Kafka的文件高效读写机制
3.1Kafka的文件结构
3.2顺序写磁盘
3.3零拷贝
3.3.1传统IO
3.3.2mmap文件映射机制
3.3.3sendfile文件传输机制
4.合理配置刷盘频率
5.客户端消费进度管理
6.常见问题
6.1消费者防止消息重新消费
6.2消息零丢失方案
6.2.1产生原因
6.2.2解决方案
6.3消息积压问题
6.4如何保证消息顺序
6.4.1如何保证Producer发到Partition上的消息是有序的
6.4.2Partition中的消息有序后,如何保证Consumer的消费顺序是有序的
本章主要讲解Kafka中每个Broker如何高效地处理以及保存消息。
1.Topic下的消息是如何存储的
在搭建Kafka服务时,我们在server.properties配置文件中通过log.dir属性指定了Kafka的日志存储目录。 实际上,Kafka的所有消息就全都存储在这个目录下。
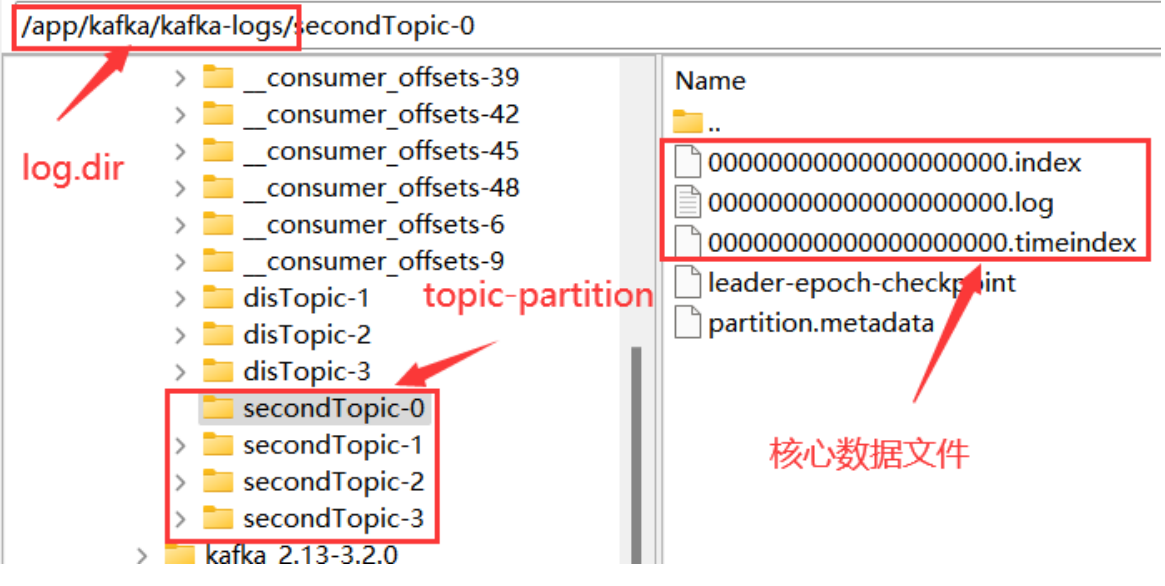
在这些核心数据文件中,.log结尾的就是实际存储消息的日志文件。他的大小固定为1G,写满后就会新增一个新的文件。一个文件也成为一个segment文件名,名字以当前日志文件记录的第一条消息的偏移量命名。
.index和.timeindex是日志文件对应的索引文件。不过.index是以偏移量为索引来记录对应的.log日志文件中的消息偏移量。而.timeindex则是以时间戳为索引。
另外的两个文件,partition.metadata简单记录当前Partition所属的cluster和Topic。leader-epoch-checkpoint文件参见上面的epoch机制
1.1log文件追加记录所有消息
在每个文件内部,Kafka都会以追加的方式写入新的消息日志。position就是消息记录的起点,size就是消息序列化后的长度。Kafka中的消息日志,只允许追加,不支持删除和修改。
每个Log文件都保持固定的大小。如果当前文件记录不下了,就会重新创建一个log文件,并以这个log文件写入的第一条消息的偏移量命名。这种设计其实是为了更方便进行文件映射,加快读消息的效率。
1.2index和timeindex加速读取日志信息
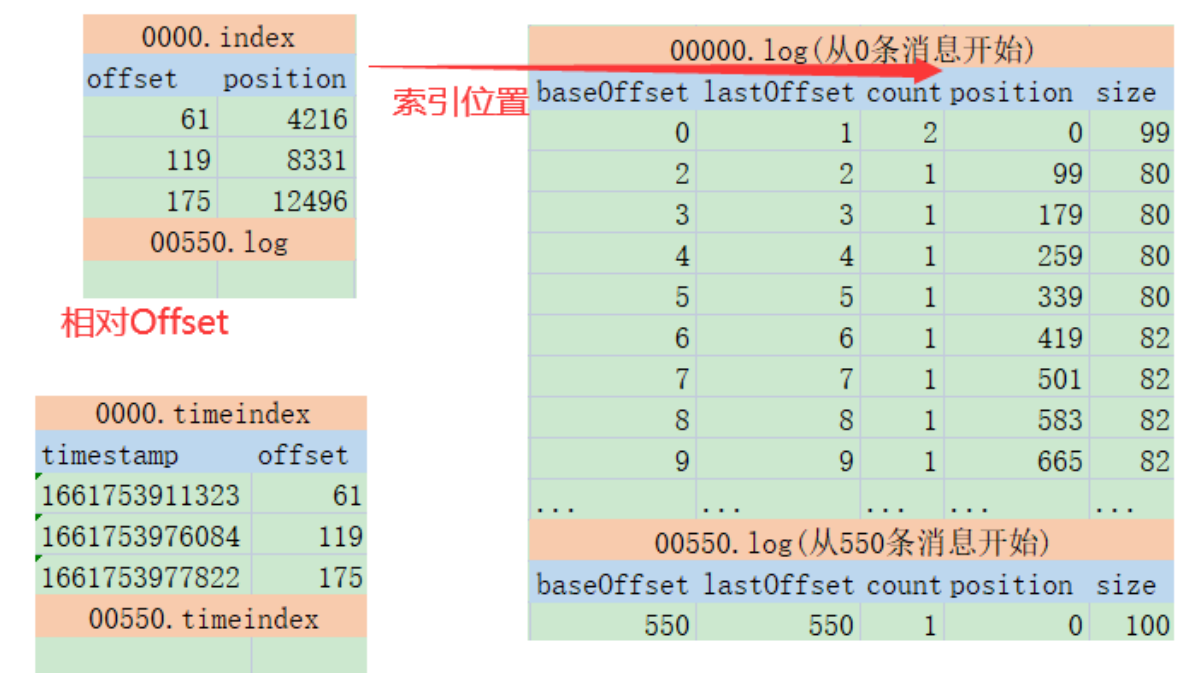
index和timeindex都是以相对偏移量的方式建立log消息日志的数据索引。比如说 0000.index和0550.index中记录的索引数字,都是从0开始的。表示相对日志文件起点的消息偏移量。而绝对的消息偏移量可以通过日志文件名 + 相对偏移量得到。
index文件的作用类似于数据结构中的跳表,他的作用是用来加速查询log文件的效率。而timeindex文件的作用则是用来进行一些跟时间相关的消息处理,比如文件清理。
2.文件清理机制
2.1如何判断哪些日志文件过期了
- log.retention.check.interval.ms:定时检测文件是否过期。默认是 300000毫秒,也就是五分钟。
- log.retention.hours , log.retention.minutes, log.retention.ms 。 这一组参数表示文件保留多长时间。默认生效的是log.retention.hours,默认值是168小时,也就是7天。如果设置了更高的时间精度,以时间精度最高的配置为准。
- 在检查文件是否超时时,是以每个.timeindex中最大的那一条记录为准。
2.2日志清理策略
日志清理策略(log.cleanup.policy):
(1)delete表示删除日志文件;
(2)compact表示压缩日志文件。
当log.cleanup.policy选择delete时,还有一个参数可以选择。log.retention.bytes:表示所有日志文件的大小。当总的日志文件大小超过这个阈值后,就会删除最早的日志文件。默认是-1,表示无限大。
压缩日志文件虽然不会直接删除日志文件,但是会造成消息丢失。压缩的过程中会将key相同的日志进行压缩,只保留最后一条。
3.Kafka的文件高效读写机制
3.1Kafka的文件结构
Kafka的数据文件结构设计可以加速日志文件的读取。比如同一个Topic下的多个Partition单独记录日志文件,并行进行读取,这样可以加快Topic下的数据读取速度。然后index的稀疏索引结构,可以加快log日志检索的速度。
3.2顺序写磁盘
对每个Log文件,Kafka会提前规划固定的大小,这样在申请文件时,可以提前占据一块连续的磁盘空间。然后,Kafka的log文件只能以追加的方式往文件的末端添加(这种写入方式称为顺序写),这样,新的数据写入时,就可以直接往直前申请的磁盘空间中写入,而不用再去磁盘其他地方寻找空闲的空间(普通的读写文件需要先寻找空闲的磁盘空间,再写入。这种写入方式称为随机写)。由于磁盘的空闲空间有可能并不是连续的,也就是说有很多文件碎片,所以磁盘写的效率会很低。
kafka的官网有测试数据,表明了同样的磁盘,顺序写速度能达到600M/s,基本与写内存的速度相当。而随机写的速度就只有100K/s,差距比加大。
(Kakfa顺序读写的实现方式不太需要SSD这样高性能的磁盘。同等容量SSD硬盘的成本比机械硬盘要高出非常多,没有必要。将SSD的成本投入到MySQL这类的服务更合适。)
3.3零拷贝
零拷贝是Linux操作系统提供的一种IO优化机制,而Kafka大量的运用了零拷贝机制来加速文件读写。
3.3.1传统IO
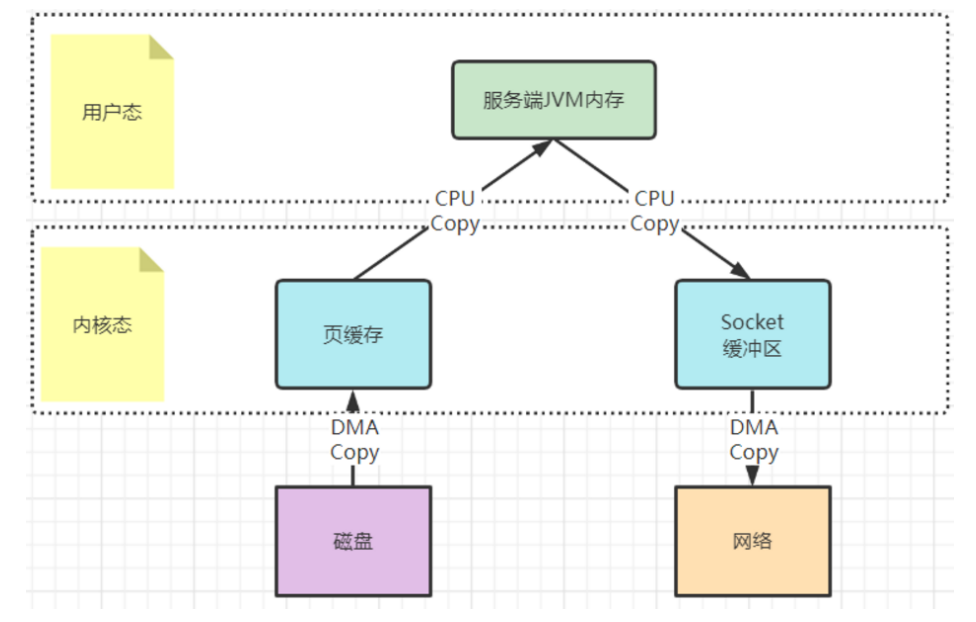
内核态的内容复制是在内核层面进行的,而零拷贝的技术,重点是要配合内核态的复制机制,减少用户态与内核态之间的内容拷贝。
具体有两种实现方式:
3.3.2mmap文件映射机制
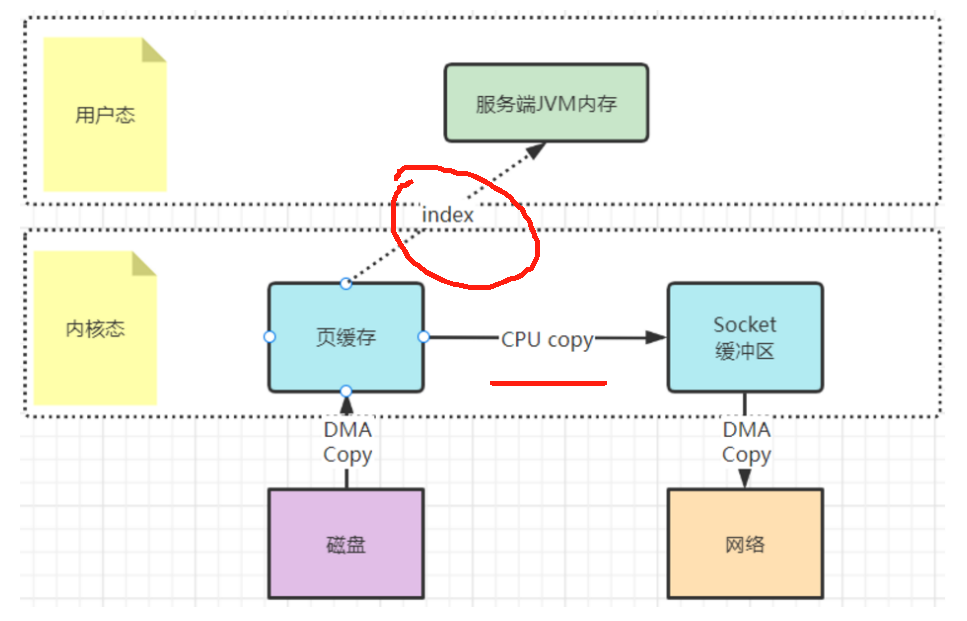
这种方式是在用户态不再缓存整个IO的内容,改为只持有文件的一些映射信息。通过这些映射,"遥控"内核态的文件读写。这样就减少了内核态与用户态之间的拷贝数据大小,提升了IO效率。(其实用户态和内核态使用的都是内存,不过操作系统对内存进行了具体的划分)
这种mmap文件映射方式,适合于操作不是很大的文件,通常映射的文件不建议超过2G。所以kafka将.log日志文件设计成1G大小,超过1G就会另外再新写一个日志文件。这就是为了便于对文件进行映射,从而加快对.log文件等本地文件的写入效率。(Kafka利用mmap+顺序写快速的将producer发送到broker的数据持久化到磁盘)
3.3.3sendfile文件传输机制
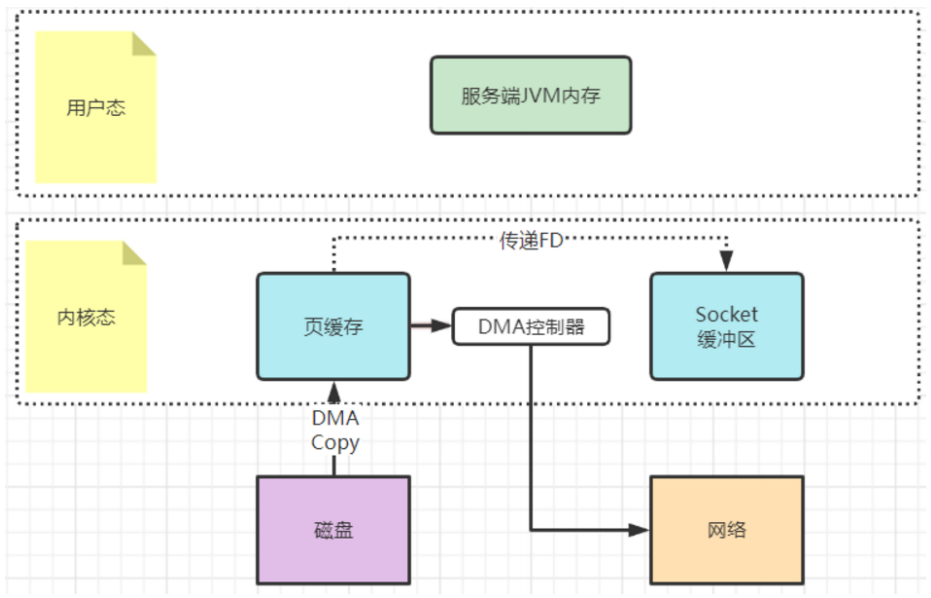
这种机制可以理解为用户态,也就是应用程序不再关注数据的内容,只是向内核态发一个sendfile指令,让他去复制文件就行了。这样数据就完全不用复制到用户态,从而实现了零拷贝。
相比mmap,连索引都不读了,直接通知操作系统去拷贝就是了。
例如在Kafka中,当Consumer要从Broker上poll消息时,Broker需要读取自己本地的数据文件,然后通过网卡发送给Consumer。这个过程当中,Broker只负责传递消息,而不对消息进行任何的加工。所以Broker只需要将数据从磁盘读取出来,复制到网卡的Socket缓冲区(仅仅是传递了FD文件描述符到Socket缓冲区,相比于mmap,减少了一次内存拷贝),然后通过网络发送出去。这个过程当中,用户态就只需要往内核态发一个sendfile指令,而不需要有任何的数据拷贝过程。Kafka大量的使用了sendfile机制,用来加速对本地数据文件的读取过程。
补充:JDK中8中java.nio.channels.FileChannel类提供了transferTo和transferFrom方法,底层就是使用了操作系统的sendfile机制。
4.合理配置刷盘频率
缓存数据断电就会丢失,所以缓存中的数据如果没有及时写入到硬盘(刷盘),那么当服务突然崩溃,就会有丢消息的可能。
同步刷盘:每写一条数据,就刷一次盘;
Kafka为了最大化性能,默认是将刷盘操作交由了操作系统进行统一管理。
下面是Kafka刷盘的一些参数:
- flush.ms : 多长时间进行一次强制刷盘。
- log.flush.interval.messages:表示当同一个Partiton的消息条数积累到这个数量时,就会申请一次刷盘操作。默认是Long.MAX。
- log.flush.interval.ms:当一个消息在内存中保留的时间,达到这个时间值时,就会申请一次刷盘操作。他的默认值是空。如果这个参数配置为空,则生效的是下一个参数。
- log.flush.scheduler.interval.ms:检查是否有日志文件需要进行刷盘的频率。默认也是Long.MAX。
补充:
(1)Kafka并没有实现写一个消息就进行一次刷盘的“同步刷盘”操作。但是在RocketMQ中却支持了这种同步刷盘机制。
(2)刷盘操作在Linux系统中对应了一个fsync的系统调用。
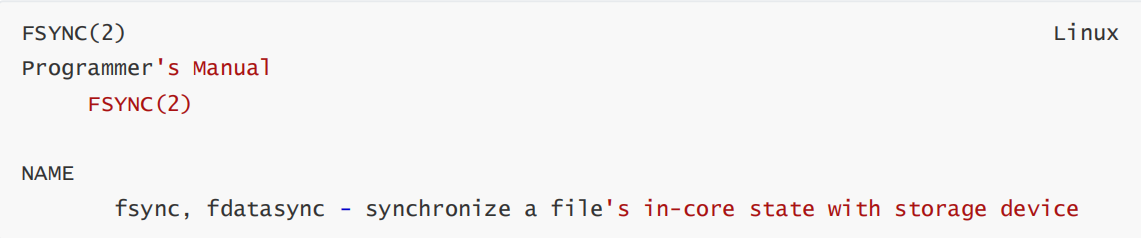
这里真正容易产生困惑的,是这里所提到的in-core state(内核态)。这并不是我们平常开发过程中接触到的缓存,而是操作系统内核态的缓存-pageCache。这是应用程序接触不到的一部分缓存。比如我们用应用程序打开一个文件,实际上文件里的内容,是从内核态的PageCache中读取出来的。
因为与磁盘这样的硬件交互,相比于内存,效率是很低的。操作系统为了提升性能,会将磁盘中的文件加载到PageCache缓存中,再向应用程序提供数据。修改文件时也是一样的。用记事本修改一个文件的内容,不管你保存多少次,内容都是写到PageCache里的。然后操作系统会通过他自己的缓存管理机制,在未来的某个时刻将所有的PageCache统一写入磁盘。这个操作就是刷盘。比如在操作系统正常关机的过程中,就会触发一次完整的刷盘机制。
所以,对于刷盘,应用程序其实是没有办法插手的。他并不能够决定自己产生的数据在什么时候刷入到硬盘当中。应用程序唯一能做的,就是尽量频繁的通知操作系统进行刷盘操作。但是,这必然会降低应用的执行性能,而且,也不是能百分之百保证数据安全的。应用程序在这个问题上,只能取舍,不能解决。
5.客户端消费进度管理
kafka为了实现分组消费的消息转发机制,需要在Broker端保持每个消费者组的消费进度。而这些消费进度,就被Kafka管理在自己的一个内置Topic中。这个Topic就是__consumer__offsets。这是Kafka内置的一个系统Topic,在日志文件可以看到这个Topic的相关目录。Kafka默认会将这个Topic划分为50个分区。
同时,Kafka也会将这些消费进度的状态信息记录到Zookeeper中。
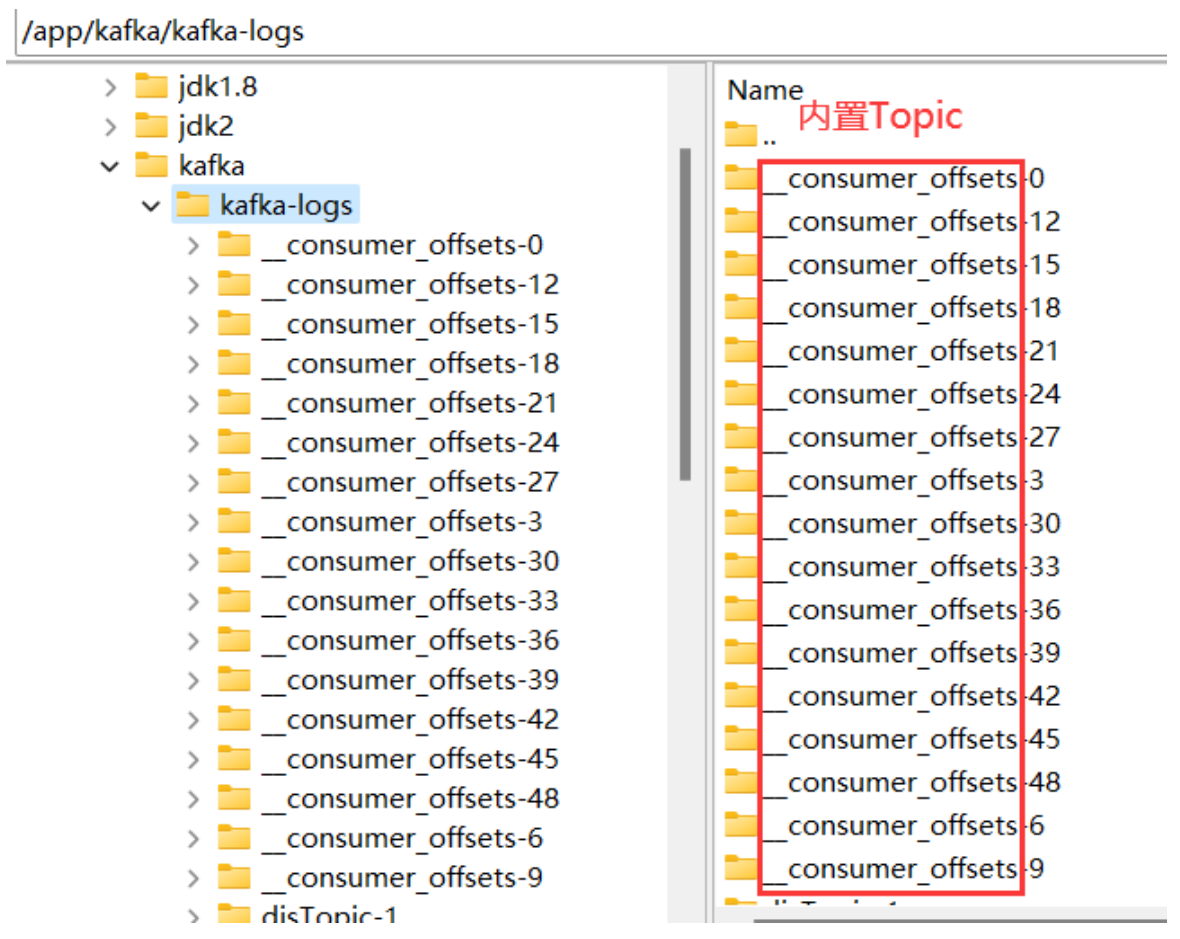
这个系统Topic中记录了所有ConsumerGroup的消费进度。
这个Topic是Kafka内置的一个系统Topic,可以启动一个消费者订阅这个Topic中的消息。
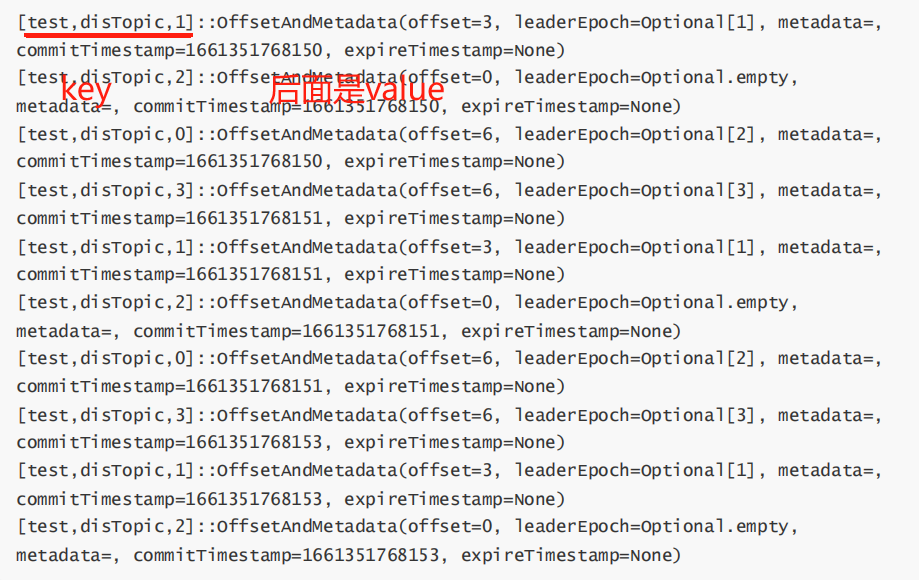
从这里可以看到,Kafka也是像普通数据一样,以Key-Value的方式来维护消费进度。key是groupid+topic+partition,value则是表示当前的offset。这些Offset数据,可以被消费者修改(从指定位置消费)。
6.常见问题
6.1消费者防止消息重新消费
产生原因:在一些大型项目中,消费者的业务处理流程会很长,这时就会带来一些问题。比如,一个消费者在正常处理这一批消息,但是时间需要很长。Broker就有可能认为消息消费失败了,从而让同组的其他消费者开始重试这一批消息。这就给消费者端带来不必要的幂等性问题。
解决:
(1)消费者端的幂等性问题,当然可以交给消费者自己进行处理,比如对于订单消息,消费者根据订单ID去确认一下这个订单消息有没有处理过。这种方式当然是可以的,大部分的业务场景下也都是这样处理的。但是这样会给消费者端带来更大的业务复杂性。
(2)在大型项目中有一种比较好的处理方式就是将Offset放到Redis中自行进行管理。通过Redis中的offset来判断消息之前是否处理过。
伪代码:
- 拉取消息
- 从Redis获取partition的偏移量
- 如果redis获取的偏移量>=kafka实际的偏移量,表示已经消费过了,则丢弃
- 业务端调用doMessage()方法,处理业务即可,不用再处理幂等性问题
- 处理完成后立即保存redis偏移量
- 异步提交

将这段代码封装成一个抽象类,具体的业务消费者端只要继承这个抽象类,然后就可以专注于实现doMessage方法,处理业务逻辑即可,不用再过多关心幂等性的问题。
6.2消息零丢失方案
6.2.1产生原因
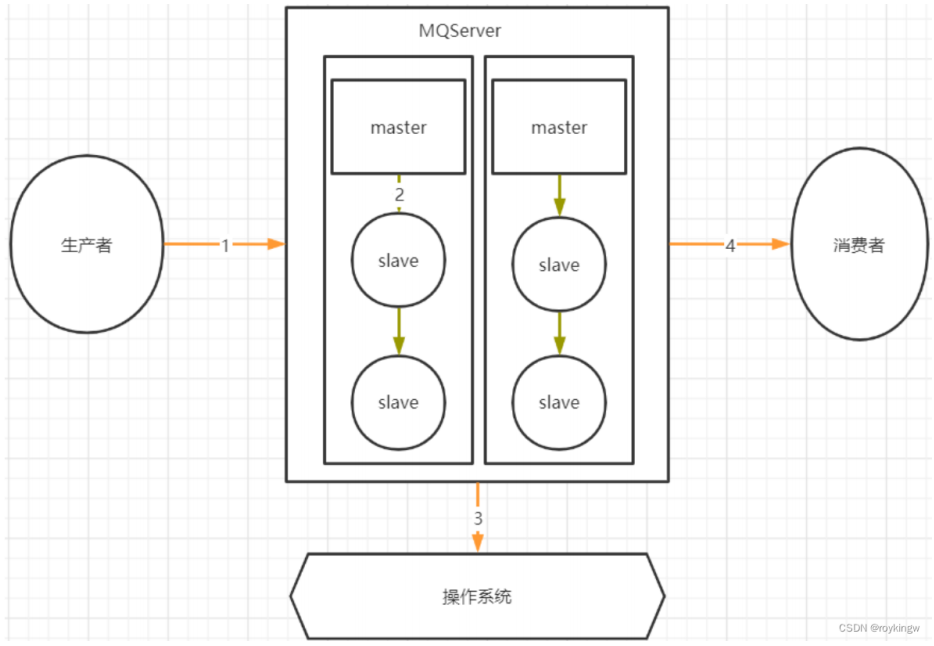
6.2.2解决方案
1.生产者发送消息到Broker不丢失
Kafka的消息生产者Producer,支持定制一个参数,ProducerConfig.ACKS_CONFIG。
- acks配置为0 : 生产者只负责往Broker端发消息,而不关注Broker的响应。也就是说不关心Broker端有没有收到消息。性能高,但是数据会有丢消息的可能。
- acks配置为1:当Broker端的Leader Partition接收到消息后,只完成本地日志文件的写入,然后就给生产者答复。其他Partiton异步拉取Leader Partiton的消息文件。这种方式如果其他Partiton拉取消息失败,也有可能丢消息。
- acks配置为-1或者all:Broker端会完整所有Partition的本地日志写入后,才会给生产者答复。数据安全性最高,但是性能显然是最低的。
对于KafkaProducer,只要将acks设置成1或-1,那么Producer发送消息后都可以拿到Broker的反馈RecordMetadata,里面包含了消息在Broker端的partition,offset等信息。通过这这些信息可以判断消息是否发送成功。如果没有发送成功,Producer就可以根据情况选择重新进行发送。
2.Broker端保存消息不丢失
(1)配置多备份因子,防止单点消息丢失。(同步信息,涉及故障恢复,存在消息不安全的可能)
(2)合理优化刷盘频率,防止服务异常崩溃造成消息未刷盘。(刷盘)
3.消费者端防止异步处理丢失消息
消费者端由于有消息重试机制,正常情况下是不会丢消息的。每次消费者处理一批消息,需要在处理完后给Broker应答,提交当前消息的Offset。Broker接到应答后,会推进本地日志的Offset记录。如果Broker没有接到应答,那么Broker会重新向同一个消费者组的消费者实例推送消息,最终保证消息不丢失。
这时,消费者端采用手动提交Offset的方式,相比 自动提交 会更容易控制提交Offset的时机。
消费者端唯一需要注意的是,不要异步处理业务逻辑。因为如果业务逻辑异步进行,而消费者已经同步提交了Offset,那么如果业务逻辑执行过程中出现了异常,失败了,那么Broker端已经接收到了消费者的应答,后续就不会再重新推送消息,这样就造成了业务层面的消息丢失。
6.3消息积压问题
- 如果业务运行正常,只是因为消费者处理消息过慢,造成消息加压。那么可以增加Topic的Partition分区数,将消息拆分到更到的Partition。然后增加消费者个数,最多让消费者个数=Partition分区数,让一个Consumer负责一个分区,将消费进度提升到最大。
- 在发送消息时,还是要尽量保证消息在各个Partition中的分布比较均匀。比如,在原有Topic下,可以调整Producer的分区策略,让Producer将后续的消息更多的发送到新增的Partition里,这样可以让各个Partition上的消息能够趋于平衡。如果你觉得这样太麻烦,那就新增一个Topic,配置更多的Partition以及对应的消费者实例。然后启动一批Consumer,将消息从旧的Topic搬运到新的Topic。这些Consumer不处理业务逻辑,只是做消息搬运,所以他们的性能是很高的。这样就能让新的Topic下的各个Partition数量趋于平衡。
- 如果是消费者的业务问题导致消息阻塞了,从而积压大量消息,并影响了系统正常运行。比如消费者序列化失败,或者业务处理全部异常。这时可以采用一种降级的方案,先启动一个Consumer将Topic下的消息先转发到其他队列中,然后再慢慢分析新队列里的消息处理问题。类似于死信队列的处理方式。
6.4如何保证消息顺序
- 因为kafka中各个Partition的消息是并发处理的,所以要保证消息顺序,对于Producer,要保证将一组有序的消息发到同一个Partition里。因为Partition的数据是顺序写的,所以自然就能保证消息是按顺序保存的。
- 接下来对于消费者,需要能够按照1,2,3的顺序处理消息。
6.4.1如何保证Producer发到Partition上的消息是有序的
(1)Topic只配一个Partition,没有其他Partition可选了,自然所有消息都到同一个Partition上了。
(2)Topic依然配置多个Partition,但是通过定制Producer的Partition分区器,将消息分配到同一个Partition上。例如在电商场景,我可能只是需要保证同一个订单相关的多条消息有序,但是并不要求所有消息有序。这样就可以通过自定义分区路由器,将订单相同的多条消息发送到同一个Partition。消息幂等性中所用的序列号保证了消息是有序的,也保证了消息不丢失。
6.4.2Partition中的消息有序后,如何保证Consumer的消费顺序是有序的
Kafka的ConsumerConfig中明确提到Consumer其实是每次并行的拉取多个Batch批次的消息进行处理的。也就是说Consumer拉取过来的多批消息并不是串行消费的。所以在Kafka提供的客户端Consumer中,是没有办法直接保证消费的消息顺序。其实这也比较好理解,因为Kafka设计的重点是高吞吐量,所以他的设计是让Consumer尽最大的能力去消费消息。而只要对消费的顺序做处理,就必然会影响Consumer拉取消息的性能。
所以这时候,我们能做的就是在Consumer的处理逻辑中,将消息进行排序。比如将消息按照业务独立性收集到一个集合中,然后在集合中对消息进行排序。
那么针对消费者顺序消费的问题,有没有其他的处理思路呢?在RocketMQ中提供了一个比较好的方式。RocketMQ中提供了顺序消息的实现。他的实现原理是先锁定一个队列(在RocketMQ中称为MessageQueue,类似于Kafka中的Partition,都是实际存储消息的队列结果),消费完这一个队列后,才开始锁定下一个队列,并消费队列中的消息。再结合MessageQueue中的消息有序性,就能保证整体消息的消费顺序是有序的。