Java基础——方法引用、单元测试、XML、注解
一、方法引用
方法引用是JDK8开始出现,主要的作用,是对Lambda表达式进行进一步的简化
方法引用使用一对冒号::
可以使语言的构造更紧凑简洁,减少冗余代码
注:只能是一个参数的时候
public class Main {
public static void main(String[] args) {
ArrayList<String> letter = new ArrayList<>();
Collections.addAll(letter,"A","B","C");
letter.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
//鼠标放在黄色位置ALt+Enter变成下面的应用
letter.forEach(s->System.out.println(s));
letter.forEach(System.out::println);
//静态方法引用,类名引用
letter.forEach(A::method);
//非静态方法引用,对象名引用方法
final A a = new A();
letter.forEach(a::method2);
}
}
class A{
public static void method(String e){
System.out.println(e);
}
public void method2(String e){
System.out.println(e);
}
}二、单元测试
就是针对最小的功能单元(方法),编写测试代码对其正确性进行测试。
JUnit:最流行的Java测试框架之一,提供了一些功能,方便程序进行单元测试(第三方公司提供)。
1. JUnit单元测试是做什么的?
测试类中方法的正确性
2. JUnit单元测试的优点是什么?
可以选择执行一 一个测试方法,或执行全部测试方法
可以自动生成测试报告 (通过:绿色,失败:红色)
一个测试方法执行失败, 不会影响其它测试方法
3. JUnit单元测试的命名规范?
类: xxxxTest (规范)
方法: public void xxxx(){...} (规定)
JUnit安装方法
第一步:在方法上面写@Text 然后 Alt + Enter

第二步:选择第一个点一下,下载一下

第三步:下载完成后,在@Text 然后 Alt + Enter 导入

导入完成后,左侧有个绿色的运行箭头。

三、XML
可扩展标记语言(英语: Extensible Markup Language, 简称: XML) 是一种标记语言
作用:常用于当做配置文件存储数据 ,适用于存储一对多的标记
.properties文件是用于存储一对一的标记
语法:
1.创建一个XML类型的文件,要求文件的后缀必须使用xml,如he1lo_ world. xml
2.编写文档声明(必须是第一行第一-列)
<?xml version="1. 0" encoding="UTF-8" ?>
version:该属性是必须存在的
encoding:该属性不是必须的
standalone:该属性不是必须的,描述XML 文件是否依赖其他的xm1文件,取值为
yes/no
3.编写根标签(必须存在一个根标签, 有且只能有一个)标签必须成对出现
<student> </student>
4.特殊的标签可以不成对,但是必须有结束标记<address/>
5.标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来
<student id="1"> </student>
6.标签需要正确的嵌套
7.XML文件中可以定义注释信息: <!- 注释内容-->
8.XML文件中可以存在以下特殊字符
9.XML文件中可以存在CDATA区: <![CDATA[ ..内... ]>
<?xml version="1.0" encoding="utf-8" ?>
<Students>
<Student id="1" name="北京">
<name>张三</name>
<age>23</age>
<address><北京></address>
<content><![CDATA[<哈哈>]]></content>
</Student>
</Students><?xml version="1.0" encoding="UTF-8" ?>
<Citys>
<city name="北京">
<area>海淀区</area>
<area>东城区</area>
<area>西城区</area>
</city>
</Citys>约束:(了解)
用来限定xml文件中可使用的标签以及属性
约束分类:
1. dtd约束
步骤:
1)创建一一个文件,这个文件的后缀名为. dtd
2)看xm1文件中使用了哪些元素公<!ELEMENT>可以定义元素
<!ELEMENT persons (person)> //标签名必须叫persons要有子标签person
<! ELEMENT person (name, age)>//子标签person中有name, age标签
<!ELEMENT name ( #PCDATA)>//name标签内是文本,age同理
< !ELEMENT age (#PCDATA)>
<?xml version="1.0" encoding="UTF-8" ?>
<!--第一种引入-->
<!--<!DOCTYPE persons SYSTEM 'stu.dtd'>-->
<!--第二种引入-->
<!--<!DOCTYPE persons [
<!ELEMENT persons (person)>
<!ELEMENT person (name, age)>
<!ELEMENT name ( #PCDATA)>
<!ELEMENT age (#PCDATA)>]>-->
<!--
<persons>
<person>
<name>张三</name>
<age>22</age>
</person>
</persons>-->
<!--第三种引入-->
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<databaseIdProvider type=""></databaseIdProvider>
</configuration> 3)引入dtd约束
本地引入:<!DOCTYPE根元素名称 SYSTEM 'DTD文件的路径'>
内部引入:< !DOCTYPE根元素名称 [ dtd文件内容]>
网络引入:< !DOCTYPE根元素的名称 PUBLIC "DTD文件名称" "DTD文档的URL">
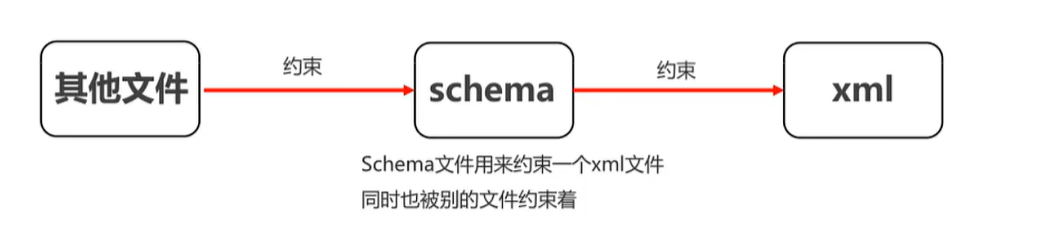
2. schema约束
schema 和 dtd 的区别
1)schema约束文件也是一个xm1文件,符合xm1的语法,这个文件的后缀名. xsd
2)一个xm1中可以引用多个schema约束文件,多个schema使用名称空间区分 (名称空间类
似于java包名)
3)dtd里面元素类型的取值比较单一常见的是PCDATA类型, 但是在schema里面可以支持很
多个数据类型
4)schema 语法更加的复杂
步骤:
1)创建一个文件,这个文件的后缀名为.xsd
2)定义文档声明
3)schema文件的根标签为: <schema>
4)在<schema>中定义属性:
xmlns=http:/ /wwW. w3. org/ 2001/XMLSchema
5)在<schema>中定义属性:
targetNamespace =唯一-的ur l地址,指定当前这个schema文件的名称空间
6)在<schema>中定义属性:
elementFormDefault= " qualified",表示当前schema文件是一个质量良好的文件
7)通过element定义元素
8)判断当前元素是简单元素还是复杂元素
<?xml version="1.0" encoding="UTF-8" ?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://mstu.com"
elementFormDefault="qualified"
>
<element name="students">
<complexType>
<!-- 顺序这指定最大子标签数量-->
<sequence maxOccurs="unbounded">
<element name="student" >
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
<!-- 给谁加属性就在那个标签里添加attribute-->
<attribute name="id" type="string" use="required"/>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema><?xml version="1.0" encoding="UTF-8" ?>
<!--可以引入多份-->
<students xmlns:xi="http://www.w3.org/2001/XMLSchema-instance"
xmln="http://mstu.com"
xi:schemalocation="http://mstu.com mstu.xsd">
<student>
<name>张三</name>
<age>23</age>
</student>
</students>XML解析
SAX 解析:不会把整体的xm1文件都加载到内存,而是从上往下逐行进行扫描。
缺点:只能读取,不能添加,不能删除。
优点:因为他是逐行描不需要把整体的xmi文件都加载到内存,所以他可以解析比较大
的xml文件。
DOM 解析:会把整体的xml文件都加载到内存,形成-个树形结构, 我们可以通过这个树形结构去
解析xm1文件。
优点:可以读取,可以添加,可以删除,可以做任何事情。
缺点:需要xm1文件全部加载到内存,所以不能解析非常大的xml文件。
解析框架
| 名称 | 说明 |
| JAXP | SUN公司提供的一套XML的解析的API(不好用) |
| JDOM | JDOM是一个开源项目, 它基于树型结构,利用纯JAVA的技术对XML文档实现解析、生成、序列化以及多种操作。 |
| Dom4j | 是JDOM的升级品,用来读写XML文件的。具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,同时它也是一个开放源代码的软件, Hibernate也用它来读写配置文件。 |
| jsoup | 功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便 |
Dom4j的使用
1. 导入dom4j-1.6.1.jar包
2.关联要解析的xml文件, 获取Document对象
3. 解析
获取跟标签
| 方法名 | 说明 |
| Element getRootElement() | 获得根元素对象 |
获取子标签
| 方法名 | 说明 |
| List<Element> elements() | 得到当前元素下所有子元素 |
| List< Element> elements(String name) | 得到当前元素下指定名字的子元素返回集合 |
| Element element(String name) | 得到当前元素下指定名字的子元素,如果有很多名字相同的返回第一个 |
| String getName() | 得到元素名字 |
| String attributeValue(String name) | 通过属性名直接得到属性值 |
| String elementText(子 元素名) | 得到指定名称的子元素的文本 |
| String getText() | 得到文本 |
public class ExplainXML {
public static void main(String[] args) throws DocumentException {
SAXReader saxReader = new SAXReader();
//1.关联XML文件获取文件对象
Document doc = saxReader.read("day19\\src\\XML\\mstu.xml");
//2.获取根标签
Element rootElement = doc.getRootElement();
//3获取子标签,是个List,需要自己定义成Element属性
List<Element> elements = rootElement.elements();
//4.遍历子标签集合
for (Element stuElement : elements) {
//5获取属性
String id = stuElement.attributeValue("id");
System.out.println(id);
//6获取元素和元素中的内容
Element name = stuElement.element("name");
Element age = stuElement.element("age");
System.out.println(name.getText());
System.out.println(age.getText());
}
}
}四、注解
Annotation表示注解, 是JDK1 . 5的新特性。注解的主要作用:对程序进行标注。
理解:注释是给人看的,注解是给虚拟机看的
通过注解可以给类增加额外的信息。
编译器或JVM可以根据注解来完成对应的功能
JDK中常见注解:
1. @Override: 表示方法的重写
2. @Deprecated: 表示修饰的方法已过时
3. @SuppressWarnings("all"): 压制警告
自定义注解
自定义注解单独存意义不大,一般会跟反射结合起来使用
格式:

注意:在使用注解时,如果注解的属性没有给出默认值,需要手动给出
@Anno( name="张三E " )
如果数组中只有一个属性值,在使用时{ }是可以省略的
属性类型:基本数据类型,String,Class,注解,枚举,以上类型的一维数组
常用位置:类和方法上
特殊属性value:
定义注解中如果有多个属性没有赋值,使用时需要全部赋值
如果只有一个属性名字为value没有赋值,使用时直接给出值,不需要写属性名
@SuppressWarnings("a1l"):压制警告 (点进去发现就是calue属性)
元注解:用在注解上的注解
| 名称 | 说明 |
| @Target | 指定了注解能在哪里使用 |
| @Retention | 可以理解为保留时间(生命周期) |
@Target:用来标识注解使用的位置,如果没有使用该注解标识,则自定义的注解可以使用在任意位置 (重点看前两个)

@Retention:用来标识注解的生命周期(有效范围)

案例:
需求:自定义一-个注解@MyTest,用于指定类的方法上
如果类中的某个的方法.上使用了该注解,就执行该方法.
@Target(ElementType.METHOD)//只能用在方法上面
@Retention(RetentionPolicy.RUNTIME)
public @interface MyText {
}
public class AnnoDome {
@MyText
public static void print1(){
System.out.println("print1********");
}
@MyText
public static void print2(){
System.out.println("print2********");
}
public static void print3(){
System.out.println("print3********");
}
}
public class TextMain {
public static void main(String[] args) throws Exception {
//获取自解码文件
Class<AnnoDome> annoDomeClass = AnnoDome.class;
final AnnoDome annoDome = annoDomeClass.getConstructor().newInstance();
//通过自解码文件获取所有类方法
final Method[] methods = annoDomeClass.getMethods();
//循环所有方法
for (Method method : methods) {
//判断方法上是否添加了自定义注释
if(method.isAnnotationPresent(MyText.class)){
method.invoke(annoDome);
}
}
}
}