大语言模型数据增强与模型蒸馏解决方案
背景
在人工智能和自然语言处理领域,大语言模型通过训练数百亿甚至上千亿参数,实现了出色的文本生成、翻译、总结等任务。然而,这些模型的训练和推理过程需要大量的计算资源,使得它们的实际开发应用成本非常高;其次,大规模语言模型的高能耗和长响应时间问题也限制了其在资源有限场景中的使用。模型蒸馏将大模型“知识”迁移到较小模型。通过模型蒸馏,可以在保留大部分性能的前提下,显著减少模型的规模,从而降低计算资源的消耗,为更多的实际应用场景提供支持。本方案以通义千问2(Qwen2)大语言模型为基础,为您介绍大语言模型数据增强和蒸馏解决方案的完整开发流程。
1.准备指令数据
您可以参照数据格式要求和数据准备策略准备相应的训练数据集。
2.可选步骤:使用指令增广模型进行指令增广
您在快速开始(QuickStart)中使用预置的指令增广模型,根据准备的数据集的指令语义信息,自动扩写更多相似的指令,指令增广有助于提升大语言模型的蒸馏训练的泛化性。
3.可选步骤:使用指令优化模型进行指令优化
您在快速开始(QuickStart)中使用预置的指令优化模型,将准备的数据集的指令(及增广的指令)进行优化精炼,指令优化有助于提升大语言模型的语言生成能力。
4.部署教师大语言模型生成对应回复
您在快速开始(QuickStart)中使用预置的教师大语言模型对训练数据集中的指令生成回复,从而将对应教师大模型的知识进行蒸馏
5.蒸馏训练较小的学生模型
您在快速开始(QuickStart)中使用生成完成的指令-回复数据集,蒸馏训练对应较小的学生模型,用于实际的应用场景。
前提条件
在开始执行操作前,请确认您已完成以下准备工作:
-
已开通PAI(DLC、EAS)后付费,并创建默认工作空间,详情请参见开通PAI并创建默认工作空间。
-
已创建OSS存储空间(Bucket),用于存储训练数据和训练获得的模型文件。关于如何创建存储空间,详情请参见控制台创建存储空间。
准备指令数据
数据准备策略
为了提升模型蒸馏的有效性和稳定性,您可以参考以下策略准备数据:
-
您应该至少准备数百条数据,准备的数据多有助于提升模型的效果。
-
准备的种子数据集的分布应该尽可能广泛且均衡。包含任务场景分布广泛,数据输入输出长度应该包含较短和较长的场景。如果数据不止一种语言,例如有中文和英文,应当确保语言分布较为均衡。
-
即使是少量的异常数据也会对微调效果造成很大的影响。应当先使用基于规则的方式清洗数据,过滤掉数据集中的异常数据。
数据格式要求
训练数据集格式要求为:JSON格式的文件,包含instruction一个字段,为输入的指令,相应的指令数据示例如下:
[
{
"instruction": "在2008年金融危机期间,各国政府采取了哪些主要措施来稳定金融市场?"
},
{
"instruction": "在气候变化加剧的背景下,各国政府采取了哪些重要行动来推动可持续发展?"
},
{
"instruction": "在2001年科技泡沫破裂期间,各国政府采取了哪些主要措施来支持经济复苏?"
}
]
使用指令增广模型进行指令增广(可选步骤)
指令增广是大语言模型提示工程(Prompt Engineering)的一种常见应用,用于自动增广用户提供的指令数据集,从而达到数据增强的作用,例如给定输入:
如何做鱼香肉丝?
如何准备GRE考试?
如果被朋友误会了怎么办?
模型输出类似如下结果:
教我如何做麻婆豆腐?
提供一个关于如何准备托福考试的详细指南?
如果你在工作中遇到了挫折,你会如何调整心态?
由于指令的多样性直接影响了大语言模型的的学习泛化性,进行指令增广能有效提升最终产出学生模型的效果。基于Qwen2基座模型,PAI提供了两款自研指令增广模型,分别为Qwen2-1.5B-Instruct-Exp和Qwen2-7B-Instruct-Exp,支持用于在PAI-QuickStart一键部署。
部署及调用指令增广模型服务
部署模型服务
您可以按照以下操作步骤,将指令增广模型部署为EAS在线服务。
-
在PAI-QuickStart选择Qwen2-1.5B-Instruct-Exp或Qwen2-7B-Instruct-Exp模型,在模型部署区域,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改,参数配置完成后单击部署按钮。
-
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考5分钟使用EAS一键部署LLM大语言模型应用。以下提供一个示例,展示如何通过客户端发起Request调用:
-
获取服务访问地址和Token。
-
在服务详情页面,单击资源信息区域的查看调用信息。
 编辑
编辑 -
在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
-
在终端中,执行如下代码调用服务。
import argparse
import json
import requests
from typing import List
def post_http_request(prompt: str,
system_prompt: str,
host: str,
authorization: str,
max_new_tokens: int,
temperature: float,
top_k: int,
top_p: float) -> requests.Response:
headers = {
"User-Agent": "Test Client",
"Authorization": f"{authorization}"
}
pload = {
"prompt": prompt,
"system_prompt": system_prompt,
"top_k": top_k,
"top_p": top_p,
"temperature": temperature,
"max_new_tokens": max_new_tokens,
"do_sample": True,
"eos_token_id": 151645
}
response = requests.post(host, headers=headers, json=pload)
return response
def get_response(response: requests.Response) -> List[str]:
data = json.loads(response.content)
output = data["response"]
return output
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top-k", type=int, default=50)
parser.add_argument("--top-p", type=float, default=0.95)
parser.add_argument("--max-new-tokens", type=int, default=2048)
parser.add_argument("--temperature", type=float, default=1)
parser.add_argument("--prompt", type=str, default="给我唱首歌。")
args = parser.parse_args()
prompt = args.prompt
top_k = args.top_k
top_p = args.top_p
temperature = args.temperature
max_new_tokens = args.max_new_tokens
host = "EAS HOST"
authorization = "EAS TOKEN"
print(f" --- input: {prompt}\n", flush=True)
system_prompt = "我希望你扮演一个指令创建者的角色。 你的目标是从【给定指令】中获取灵感,创建一个全新的指令。"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
print(f" --- output: {output}\n", flush=True)
批量实现指令增广
如果使用上述EAS在线服务,可以进行批量调用,实现批量指令增广。以下代码示范了如何读取自己的json格式数据集,批量调用上面的模型接口进行数据增广。post_http_request和get_response函数定义与前述脚本相同。
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # 输入文件名
with open(input_file_path) as fp:
data=json.load(fp)
total_size = 10 # 期望的扩展后的总数据量
pbar = tqdm(total=total_size)
while len(data) < total_size:
prompt = random.sample(data,1)[0]["instruction"]
system_prompt = "我希望你扮演一个指令创建者的角色。 你的目标是从【给定指令】中获取灵感,创建一个全新的指令。"
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 输出文件名
with open(output_file_path, 'w') as f:
json.dump(data, f, ensure_ascii=False)
您也可以使用PAI-Designer的LLM-指令扩充(DLC)组件零代码实现上一功能。
使用指令优化模型进行指令优化(可选步骤)
指令优化是大语言模型提示工程(Prompt Engineering)的另一种常见技术,用于自动优化用户提供的指令数据集,生成更加详细的指令。这些更详细的指令能让大语言模型输出更详细的回复。以下给出输入简略和详细指令,Qwen2-7B-Instruct模型的输出对比,可以明显观察到指令的优化对模型输出显著的提升作用。


在指令优化模型中,给定输入:
如何做鱼香肉丝?
如何准备GRE考试?
如果被朋友误会了怎么办?
模型输出类似如下结果:
请提供一个详细的中国四川风味的鱼香肉丝的食谱。包括所需的具体材料列表(如蔬菜、猪肉和调料),以及详细的步骤说明。如果可能的话,还请推荐适合搭配这道菜的小菜和主食。
请提供一个详细的指导方案,包括GRE考试的报名、所需资料、备考策略和建议的复习资料。同时,如果可以的话,也请推荐一些有效的练习题和模拟考试来帮助我更好地准备考试。
请提供一个详细的指导,教我如何在被朋友误会时保持冷静和理智,并且有效地沟通来解决问题。请包括一些实用的建议,例如如何表达自己的想法和感受,以及如何避免误解加剧,并且建议一些具体的对话场景和情境,以便我能更好地理解和练习。
由于指令的详细性直接影响了大语言模型的的输出指令,进行指令优化能有效提升最终产出学生模型的效果。基于Qwen2基座模型,PAI提供了两款自研指令优化模型,分别为Qwen2-1.5B-Instruct-Refine和Qwen2-7B-Instruct-Refine,支持用于在PAI-QuickStart一键部署。
部署及调用指令优化模型服务
部署模型服务
您可以按照以下操作步骤,将指令增广模型部署为EAS在线服务。
-
在PAI-QuickStart选择Qwen2-1.5B-Instruct-Refine或Qwen2-7B-Instruct-Refine模型,在模型部署区域,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改,参数配置完成后单击部署按钮。
-
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考5分钟使用EAS一键部署LLM大语言模型应用。以下提供一个示例,展示如何通过客户端发起Request调用:
-
获取服务访问地址和Token。
-
在服务详情页面,单击资源信息区域的查看调用信息。
-
在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
-
在终端中,执行如下代码调用服务。
import argparse
import json
import requests
from typing import List
def post_http_request(prompt: str,
system_prompt: str,
host: str,
authorization: str,
max_new_tokens: int,
temperature: float,
top_k: int,
top_p: float) -> requests.Response:
headers = {
"User-Agent": "Test Client",
"Authorization": f"{authorization}"
}
pload = {
"prompt": prompt,
"system_prompt": system_prompt,
"top_k": top_k,
"top_p": top_p,
"temperature": temperature,
"max_new_tokens": max_new_tokens,
"do_sample": True,
"eos_token_id": 151645
}
response = requests.post(host, headers=headers, json=pload)
return response
def get_response(response: requests.Response) -> List[str]:
data = json.loads(response.content)
output = data["response"]
return output
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top-k", type=int, default=2)
parser.add_argument("--top-p", type=float, default=0.95)
parser.add_argument("--max-new-tokens", type=int, default=256)
parser.add_argument("--temperature", type=float, default=0.5)
parser.add_argument("--prompt", type=str, default="给我唱首歌。")
args = parser.parse_args()
prompt = args.prompt
top_k = args.top_k
top_p = args.top_p
temperature = args.temperature
max_new_tokens = args.max_new_tokens
host = "EAS HOST"
authorization = "EAS TOKEN"
print(f" --- input: {prompt}\n", flush=True)
system_prompt = "请优化这个指令,将其修改为一个更详细具体的指令。"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
print(f" --- output: {output}\n", flush=True)
批量实现指令优化
如果使用上述EAS在线服务,可以进行批量调用,实现批量指令优化。以下代码示范了如何读取自己的json格式数据集,批量调用上面的模型接口进行指令优化。post_http_request和get_response函数定义与前述脚本相同。
import requests
import json
import random
from tqdm import tqdm
from typing import List
input_file_path = "input.json" # 输入文件名
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data =[]
for d in data:
prompt = d["instruction"]
system_prompt = "请优化以下指令。"
top_k = 50
top_p = 0.95
temperature = 1
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 输出文件名
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)
您也可以使用PAI-Designer的LLM-指令优化(DLC)组件零代码实现上一功能。
部署教师大语言模型生成对应回复
部署模型服务
在优化好数据集中的指令以后,您可以按照以下操作步骤,部署教师大语言模型生成对应回复。
-
在PAI-QuickStart选择通义千问2-72B-Instruct模型其他教师大模型,在模型部署区域,系统已默认配置了模型服务信息和资源部署信息,您也可以根据需要进行修改,参数配置完成后单击部署按钮。
-
在计费提醒对话框中,单击确定。
系统自动跳转到部署任务页面,当状态为运行中时,表示服务部署成功。
调用模型服务
服务部署成功后,您可以使用API进行模型推理。具体使用方法参考5分钟使用EAS一键部署LLM大语言模型应用。以下提供一个示例,展示如何通过客户端发起Request调用:
-
获取服务访问地址和Token。
-
在服务详情页面,单击资源信息区域的查看调用信息。
-
在调用信息对话框中,查询服务访问地址和Token,并保存到本地。
-
在终端中,执行如下代码调用服务。
import argparse
import json
import requests
from typing import List
def post_http_request(prompt: str,
system_prompt: str,
host: str,
authorization: str,
max_new_tokens: int,
temperature: float,
top_k: int,
top_p: float) -> requests.Response:
headers = {
"User-Agent": "Test Client",
"Authorization": f"{authorization}"
}
pload = {
"prompt": prompt,
"system_prompt": system_prompt,
"top_k": top_k,
"top_p": top_p,
"temperature": temperature,
"max_new_tokens": max_new_tokens,
"do_sample": True,
}
response = requests.post(host, headers=headers, json=pload)
return response
def get_response(response: requests.Response) -> List[str]:
data = json.loads(response.content)
output = data["response"]
return output
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top-k", type=int, default=50)
parser.add_argument("--top-p", type=float, default=0.95)
parser.add_argument("--max-new-tokens", type=int, default=2048)
parser.add_argument("--temperature", type=float, default=0.5)
parser.add_argument("--prompt", type=str)
parser.add_argument("--system_prompt", type=str)
args = parser.parse_args()
prompt = args.prompt
system_prompt = args.system_prompt
top_k = args.top_k
top_p = args.top_p
temperature = args.temperature
max_new_tokens = args.max_new_tokens
host = "EAS HOST"
authorization = "EAS TOKEN"
print(f" --- input: {prompt}\n", flush=True)
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
print(f" --- output: {output}\n", flush=True)
具体使用方法参考5分钟使用EAS一键部署LLM大语言模型应用。
批量实现教师模型的指令标注
以下代码示范了如何读取自己的json格式数据集,批量调用上面的模型接口进行教师模型标注。post_http_request和get_response函数定义与前述脚本相同。
import json
from tqdm import tqdm
import requests
from typing import List
input_file_path = "input.json" # 输入文件名
with open(input_file_path) as fp:
data = json.load(fp)
pbar = tqdm(total=len(data))
new_data = []
for d in data:
system_prompt = "You are a helpful assistant."
prompt = d["instruction"]
print(prompt)
top_k = 50
top_p = 0.95
temperature = 0.5
max_new_tokens = 2048
host = "EAS HOST"
authorization = "EAS TOKEN"
response = post_http_request(
prompt, system_prompt,
host, authorization,
max_new_tokens, temperature, top_k, top_p)
output = get_response(response)
temp = {
"instruction": prompt,
"output": output
}
new_data.append(temp)
pbar.update(1)
pbar.close()
output_file_path = "output.json" # 输出文件名
with open(output_file_path, 'w') as f:
json.dump(new_data, f, ensure_ascii=False)
蒸馏训练较小的学生模型
当获得教师模型的回复后,您可以在QuickStart中,实现学生模型的训练,无需编写代码,极大简化了模型的开发过程。本方案以Qwen2-7B-Instruct模型为例,为您介绍如何使用已准备好的训练数据,在QuickStart中进行模型训练。具体操作步骤如下:
-
进入快速开始页面。
-
登录PAI控制台。
-
在顶部左上角根据实际情况选择地域。
-
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间内。
-
在左侧导航栏选择快速开始。
2.在快速开始页面右侧的模型列表中,单击通义千问2-7B-Instruct模型卡片,进入模型详情页面。
3.在模型详情页面,单击右上角的微调训练。
4.在微调训练配置面板中,配置以下关键参数,其他参数取默认配置。
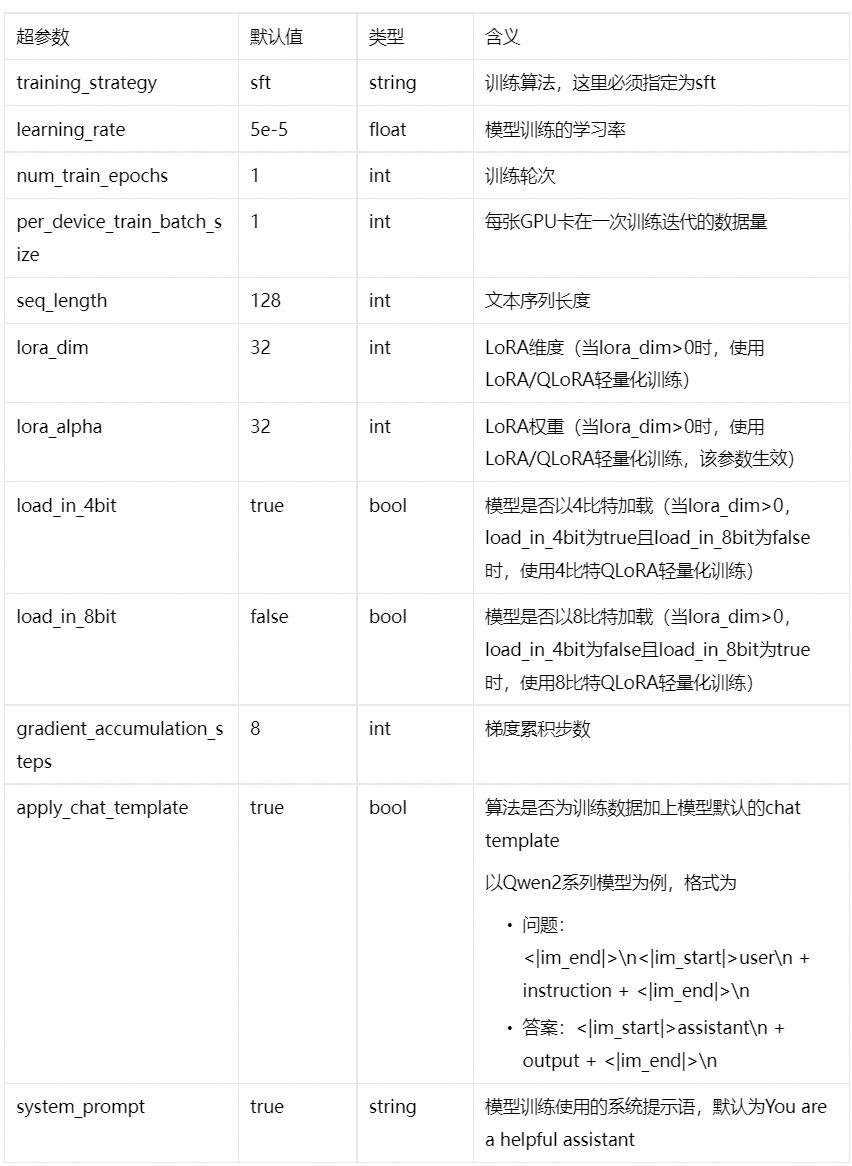
-
问题:<|im_end|>\n<|im_start|>user\n + instruction + <|im_end|>\n
-
答案:<|im_start|>assistant\n + output + <|im_end|>\n || system_prompt | true | string | 模型训练使用的系统提示语,默认为You are a helpful assistant |
点击“训练”按钮,PAI-QuickStart 开始进行训练,用户可以查看训练任务状态和训练日志。
如果在训练完成后,需要将模型部署至PAI-EAS,可以在同一页面的模型部署卡面选择资源组,并且点击“部署”按钮实现一键部署。
相关文档
-
更多关于EAS产品的内容介绍,请参见模型在线服务(EAS)。
-
使用快速开始(QuickStart)功能,您可以轻松完成更多场景的部署与微调任务,包括Llama-3、Qwen1.5、Stable Diffusion V1.5等系列模型。详情请参见场景实践。