CS224W—07 Machine Learning with Heterogeneous Graphs
CS224W—07 Machine Learning with Heterogeneous Graphs
本节中,我们将学习如何在异构图中进行图神经网络学习。
Heterogeneous Graphs
图中的节点类型/边类型不同,就会形成一个异构图(Heterogeneous Graph),例如下图中的节点有两种类型:Paper节点/Author节点;第二个图中的边有两种类型:Cite/Like;也可以是多种节点和边的结合,如第三个图。
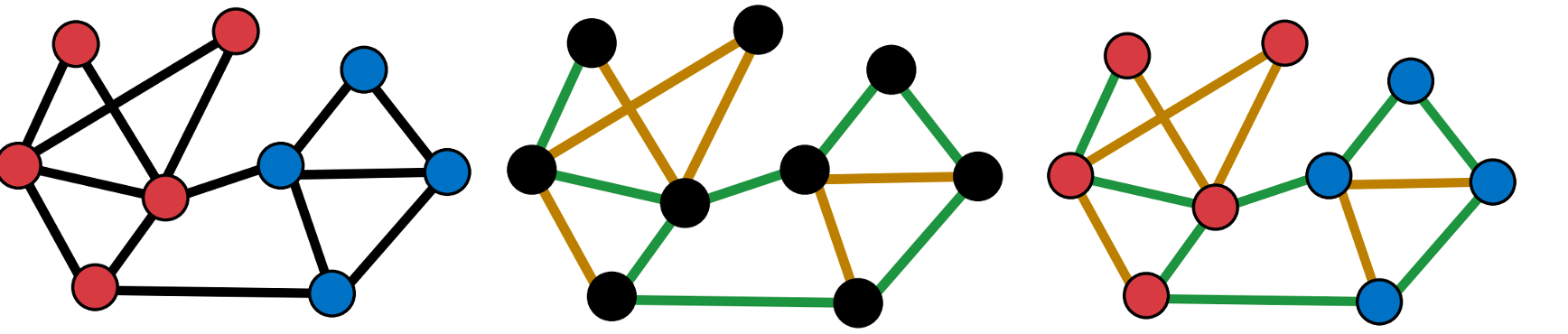
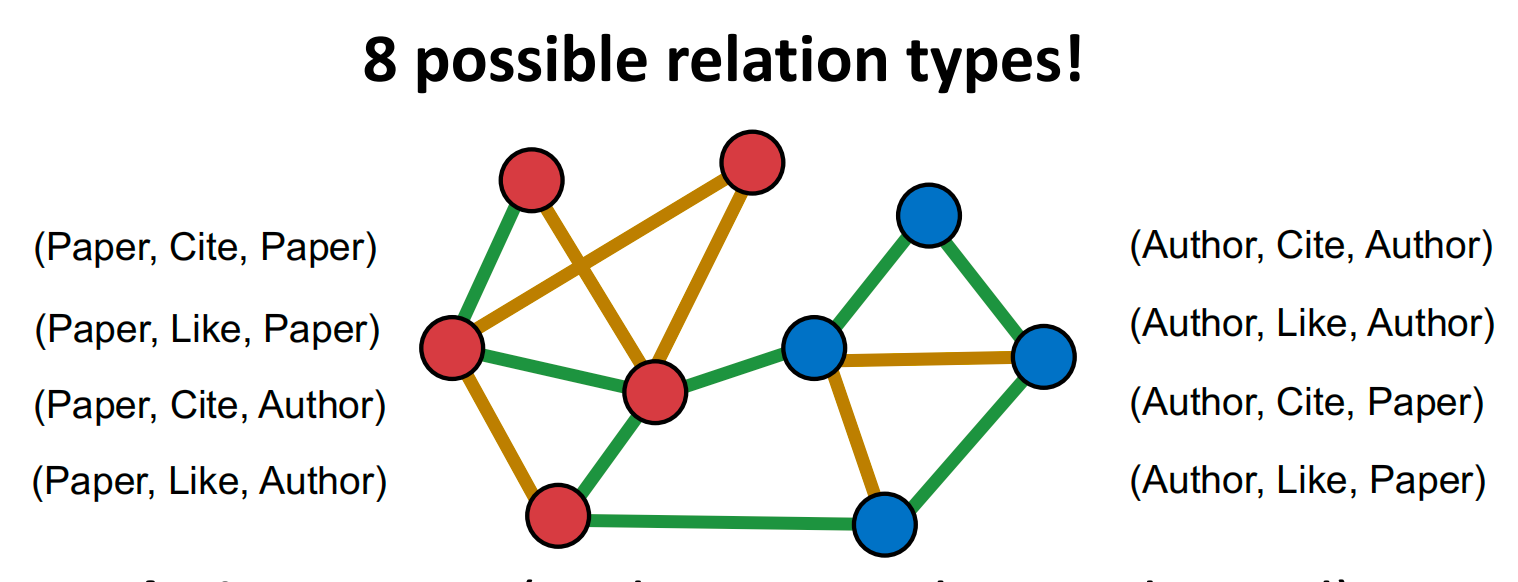
为了更好的捕捉节点和边的交互,使用relation type来描述一条边:
Relation Type: (node_start, edge, node_end)
异构图定义为
G
=
(
V
,
E
,
τ
,
ϕ
)
G = (V, E, \tau, \phi)
G=(V,E,τ,ϕ)
-
具有节点类型 τ ( v ) \tau(v) τ(v) 的节点 v ∈ V v \in V v∈V
-
具有边类型 ϕ ( u , v ) \phi(u, v) ϕ(u,v) 的边 ( u , v ) ∈ E (u, v) \in E (u,v)∈E
-
边 e e e 的relation type是一个元组: r ( u , v ) = ( τ ( u ) , ϕ ( u , v ) , τ ( v ) ) r(u, v) = \left(\tau(u), \phi(u, v), \tau(v)\right) r(u,v)=(τ(u),ϕ(u,v),τ(v))
观察:我们也可以将节点和边的类型视为特征 示例:为节点和边添加一位有效指示器
- 给每个“作者节点”附加特征 [1, 0];
- 给每个“论文节点”附加特征 [0, 1]
- 同样,我们可以为不同类型的边分配边特征;然后,异构图简化为标准图
那我们何时需要异构图?
- 情景1:不同的节点/边类型有不同形状的特征
- 情景2:不同的relation type代表不同类型的interaction
- 比如 (English, translate, French) 和 (English, translate, Chinese) 需要不同的模型。
异构图的计算成本是很高的,也有许多方法将异构图转换为同构图来进行计算。
Relational GCN (RGCN)
论文地址:https://arxiv.org/pdf/1703.06103
经典的GCN:
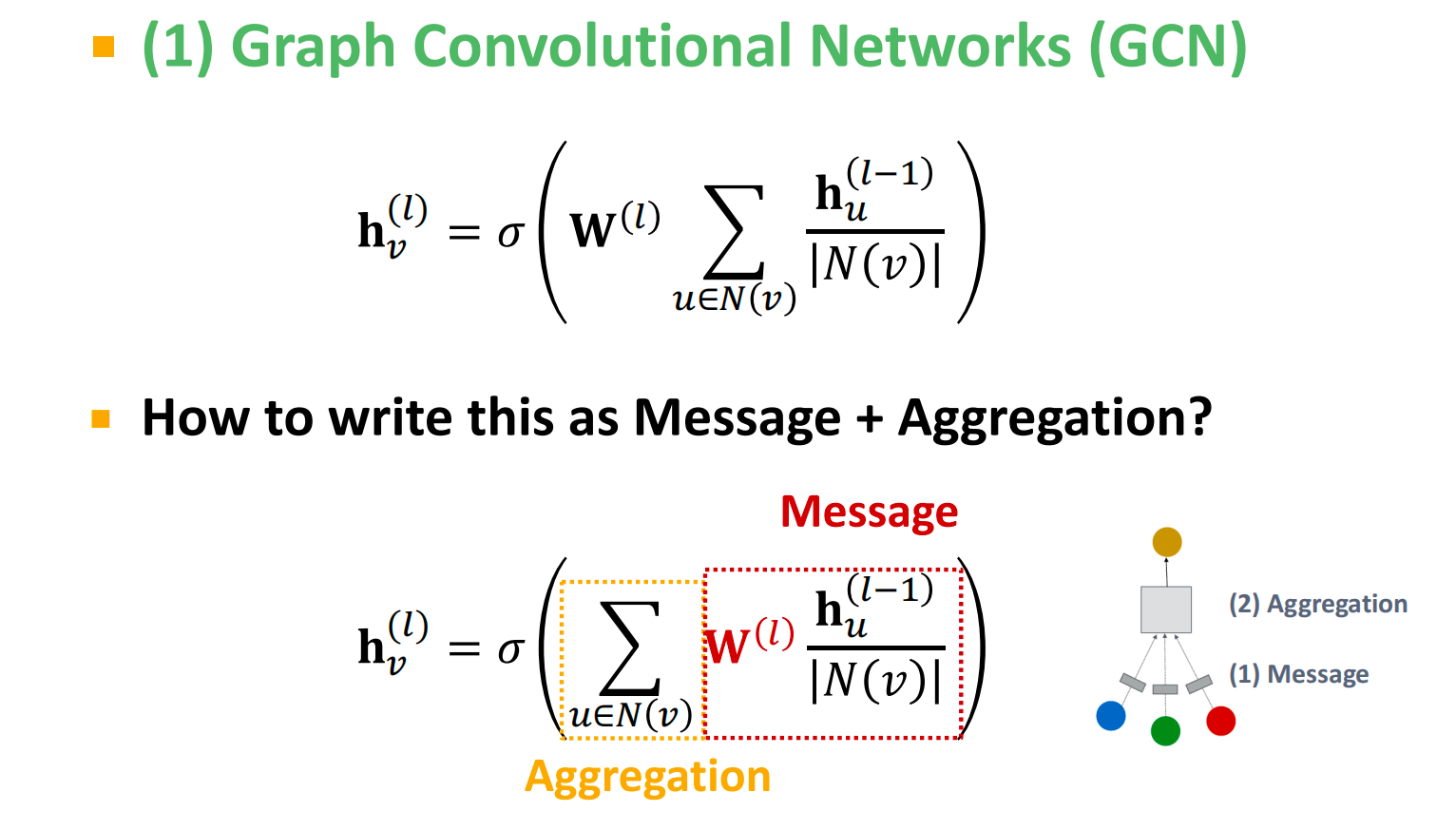
对于只有一种relation的有向图:
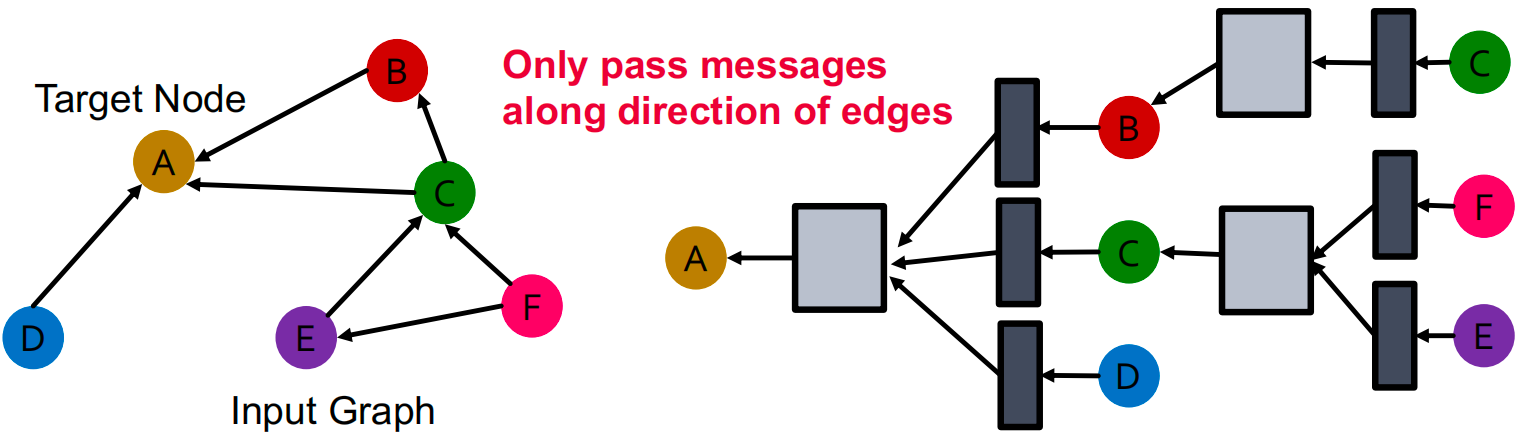
对于有多种relation types的图,不同的relation type 使用不同的神经网络参数:
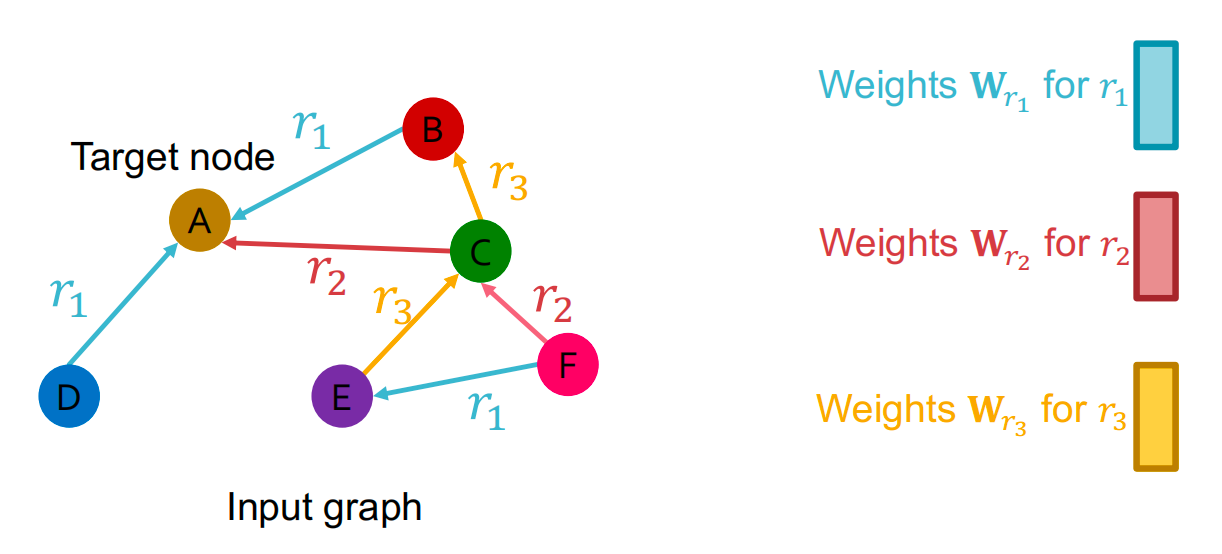
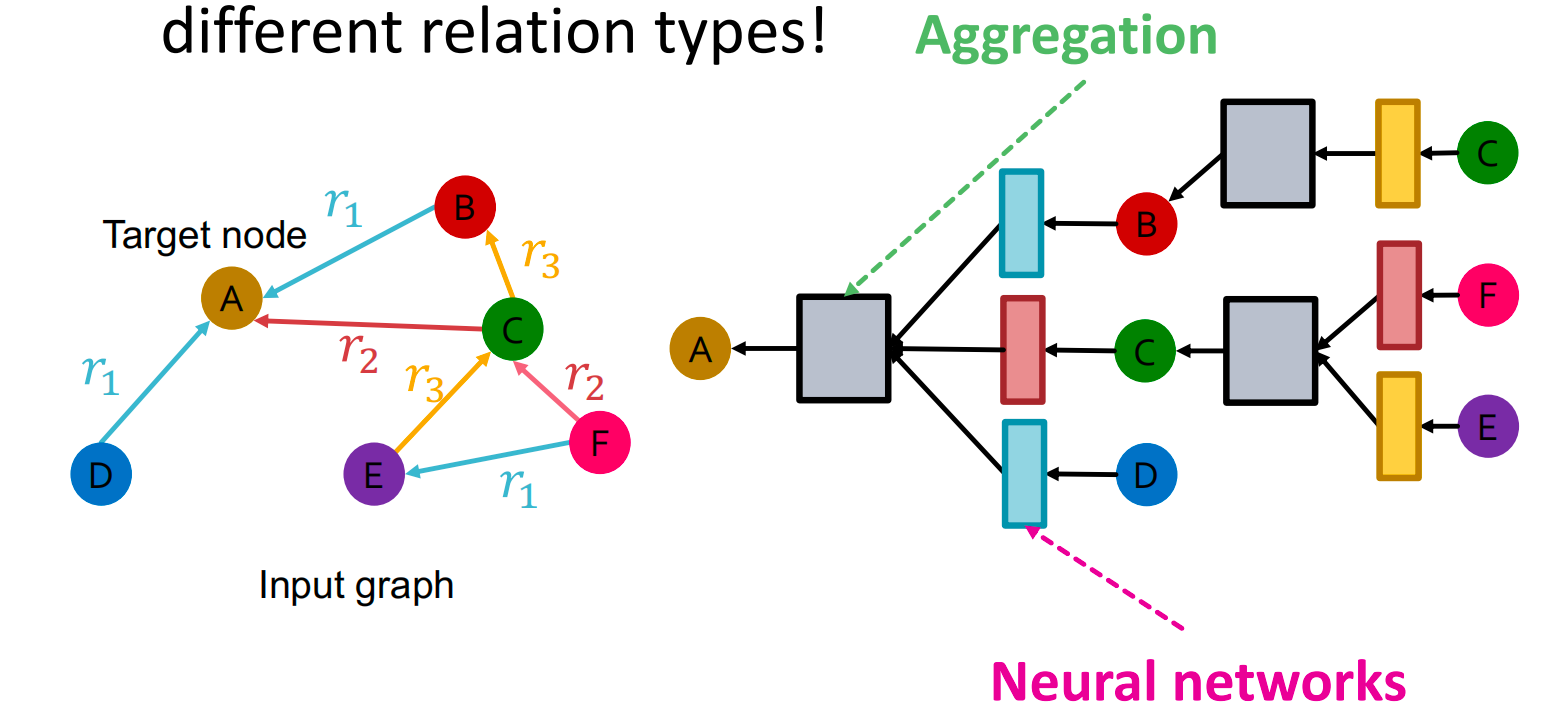
RGCN Definition
h v ( l + 1 ) = σ ( ∑ r ∈ R ∑ u ∈ N v r 1 C ν , r W r ( l ) h u ( l ) + W 0 ( l ) h v ( l ) ) \mathbf{h}_v^{(l+1)}=\sigma\left(\sum_{r\in R}\sum_{u\in N_v^r}\frac{1}{C_{\nu,r}}\mathbf{W}_r^{(l)}\mathbf{h}_u^{(l)}+\mathbf{W}_0^{(l)}\mathbf{h}_v^{(l)}\right) hv(l+1)=σ r∈R∑u∈Nvr∑Cν,r1Wr(l)hu(l)+W0(l)hv(l)
Message:
-
每个给定relation ( r ) 的领居消息:
m u , r ( l ) = 1 c v , r W r ( l ) h u ( l ) , c v , r = ∣ N v r ∣ \mathbf{m}_{u,r}^{(l)}=\frac1{c_{v,r}}\mathbf{W}_r^{(l)}\mathbf{h}_u^{(l)}, \quad c_{v,r}=|N_v^r| mu,r(l)=cv,r1Wr(l)hu(l),cv,r=∣Nvr∣ -
自身消息:
m v ( l ) = W 0 ( l ) h v ( l ) \mathbf{m}_v^{(l)}=\mathbf{W}_0^{(l)}\mathbf{h}_v^{(l)} mv(l)=W0(l)hv(l)
Aggregation:
- 对来自邻居和自身的消息进行求和,然后进行激活:
h v ( l + 1 ) = σ ( S u m ( { m u , r ( l ) , u ∈ N ( v ) } ∪ { m v ( l ) } ) ) \mathbf{h}_v^{(l+1)}=\sigma\left(\mathrm{Sum}\left(\left\{\mathbf{m}_{u,r}^{(l)},u\in N(v)\right\}\cup\left\{\mathbf{m}_v^{(l)}\right\}\right)\right) hv(l+1)=σ(Sum({mu,r(l),u∈N(v)}∪{mv(l)}))
RGCN Scalability
每种关系都有 L L L 个矩阵: W r ( 1 ) , W r ( 2 ) ⋯ W r ( L ) W_r^{(1)}, W_r^{(2)} \cdots W_r^{(L)} Wr(1),Wr(2)⋯Wr(L)。每个 W r ( l ) W_r^{(l)} Wr(l) 的大小是 d ( l + 1 ) × d ( l ) d^{(l+1)} \times d^{(l)} d(l+1)×d(l), d ( l ) d^{(l)} d(l) 是第 l l l 层的隐藏维度。
参数数量相对于关系数量的快速增长!过拟合成为一个问题。
两种方法来正则化权重 W r ( l ) W_r^{(l)} Wr(l):
- 使用分块对角矩阵( Block Diagonal Matrices)
- 基/字典学习(Basis/Dictionary learning)
Block Diagonal Matrices
关键:使权重变得稀疏!使用分块对角矩阵对 W r W_r Wr 进行稀疏化
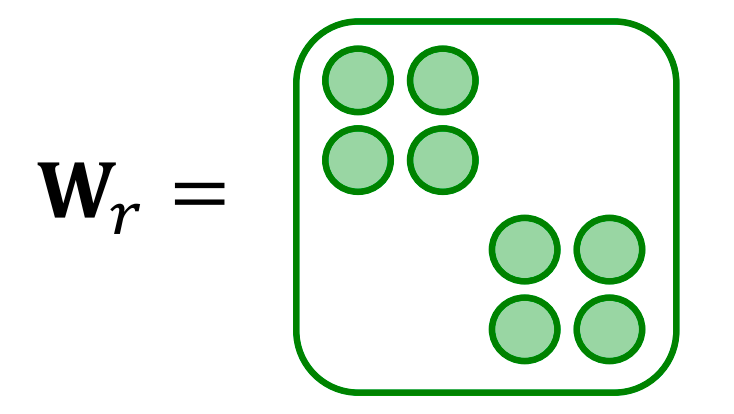
限制:只有邻近的神经元/维度可以通过 W W W 进行交互。 如果使用 B B B 个低维矩阵,则参数数量从 d ( l + 1 ) × d ( l ) d^{(l+1)} \times d^{(l)} d(l+1)×d(l) 减少到 B × d ( l + 1 ) B × d ( l ) B B \times \frac{d^{(l+1)}}{B} \times \frac{d^{(l)}}{B} B×Bd(l+1)×Bd(l)。
Basis Learning
关键:在不同的relation之间分享权重
将每种关系的矩阵表示为基变换的线性组合:
W
r
=
∑
b
=
1
B
a
r
b
⋅
V
b
,
W_{r} = \sum_{b=1}^{B} a_{r b} \cdot V_{b},
Wr=b=1∑Barb⋅Vb,
其中
V
b
V_{b}
Vb 在所有关系中共享。
-
V b V_{b} Vb 是基矩阵。
-
a r b a_{r b} arb 是矩阵 V b V_{b} Vb 的重要性权重。
现在每种关系只需要学习 { a r b } b = 1 B \{a_{r b}\}_{b=1}^{B} {arb}b=1B,这是 B B B 个标量。
Example: Entity/Node Classification
任务:对于给定节点,预测其标签
如果我们从 k k k 个类别中预测节点 A 的类别,取最后一层(预测头): h A ( L ) ∈ R k h_{A}^{(L)} \in \mathbb{R}^{k} hA(L)∈Rk, h A ( L ) h_{A}^{(L)} hA(L) 中的每个项代表该类别的概率。
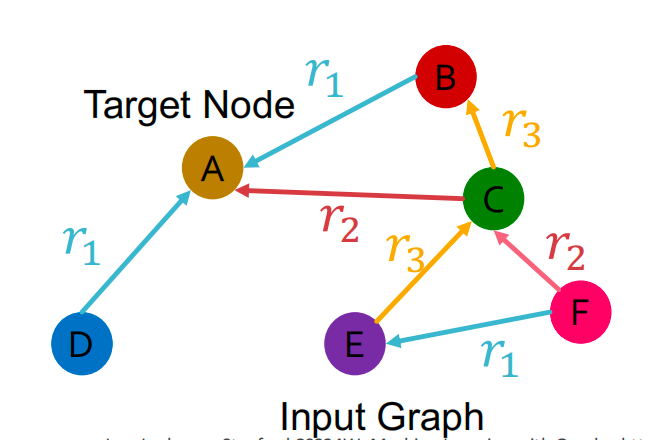
Link Prediction
在异质图中,将每种关系对应的边都分成 training message edges, training supervision edges, validation edges, test edges 四类。
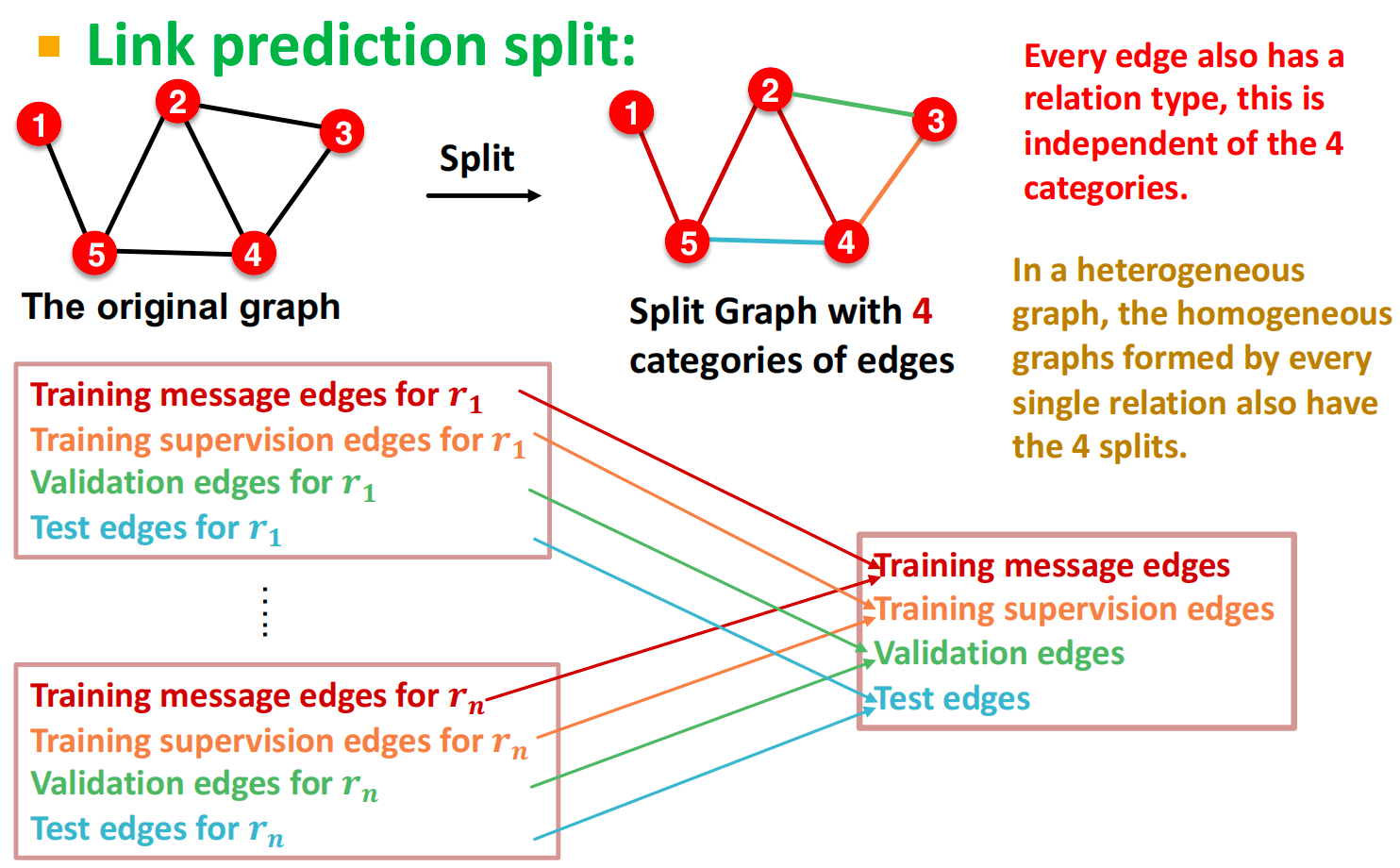
假设 ( E , r 3 , A ) \left(E, r_{3}, A\right) (E,r3,A) 是training supervision edge,所有其他边都是training message edges。使用RGCN对 ( E , r 3 , A ) \left(E, r_{3}, A\right) (E,r3,A) 进行评分:
- 取 E E E 和 A A A 的最后一层: h E ( L ) h_{E}^{(L)} hE(L) 和 h A ( L ) ∈ R d h_{A}^{(L)} \in \mathbb{R}^{d} hA(L)∈Rd。
- 关系特定的评分函数
f
r
f_{r}
fr:
R
d
×
R
d
→
R
\mathbb{R}^{d} \times \mathbb{R}^{d} \rightarrow \mathbb{R}
Rd×Rd→R
- 例子: f r 1 ( h E , h A ) = h E T W r 1 h A , W r 1 ∈ R d × d f_{r_1}\left(h_E, h_A\right) = h_E^T W_{r_1} h_A, W_{r_1} \in \mathbb{R}^{d \times d} fr1(hE,hA)=hETWr1hA,Wr1∈Rd×d
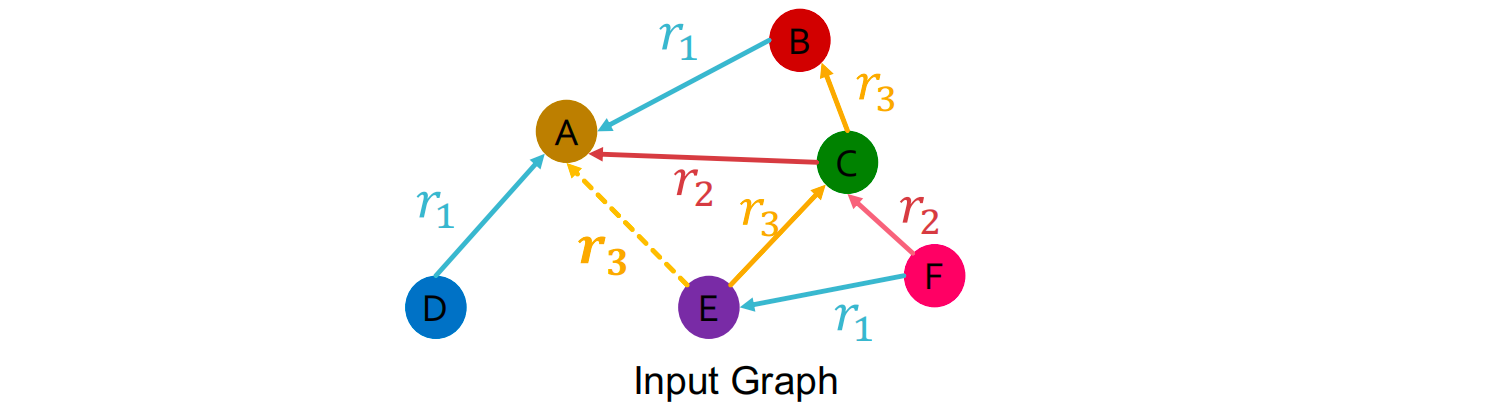
训练阶段:用 training message edges 预测 training supervision edges
- 用RGCN给training supervision edge ( E , r 3 , A ) (E,r_3,A) (E,r3,A) 打分
- 通过perturb supervision edge 得到negative edge :例如perturb ( E , r 3 , A ) (E,r_3,A) (E,r3,A) 得到 ( E , r 3 , B ) (E,r_3,B) (E,r3,B)
- 使用GNN计算 negative edge的分数
- 优化交叉熵损失函数,使 training supervision edge 上得分最高,negative edge 上得分最低:
- ℓ = − log σ ( f r 3 ( h E , h A ) ) − log ( 1 − σ ( f r 3 ( h E , h B ) ) ) \ell=-\log\sigma\left(f_{r_3}(h_E,h_A)\right)-\log(1-\sigma\big(f_{r_3}(h_E,h_B))\big) ℓ=−logσ(fr3(hE,hA))−log(1−σ(fr3(hE,hB))), σ : S i g m o i d \sigma: Sigmoid σ:Sigmoid
验证阶段:用 training message edges 和 training supervision edges 预测 validation edges: ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 。 ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 的得分应该比所有不在 training message edges 和 training supervision edges 的点得分更高,比如 ( E , r 3 , B ) (E,r_3,B) (E,r3,B)
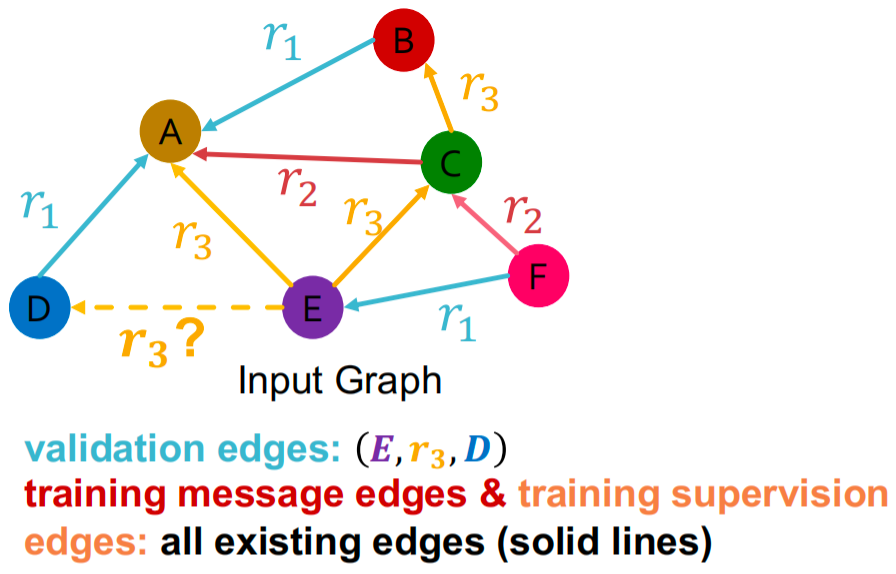
具体步骤:
- 计算 ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 的得分
- 计算所有 negetive edges 的得分 { ( E , r 3 , v ) ∣ v ∈ { B , F } } \{(E,r_3,v)|v\in\{B,F\}\} {(E,r3,v)∣v∈{B,F}}
- 获得 ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 的排名
- 计算指标