专利复现_基于ngboost和SHAP值可解释预测方法
大家好,我是重庆未来之智的Toby老师,最近看到一篇专利,名称是《基于NGBoost和SHAP值的可解释地震动参数概率密度分布预测方法》。该专利申请工日是2021年3月2日。








专利复现
我看了这专利申请文案后,文章整体布局和文字内容结构不错,就是创新点半天找不到。我们公司之前申请专利至少还有算法创新点,不由感叹现在专利局审核尺度也太松弛了。
ngboost是2019年出来的算法,SHAP是博弈论中经典算法。两者组合还算不错,今天就为大家复现基于ngboost和SHAP值可解释预测方法。
NGboost概述
NGBoost(Natural Gradient Boosting)是一种基于梯度提升框架的集成学习算法,它通过自然梯度优化来更新模型参数。NGBoost结合了梯度提升决策树(GBDT)的预测能力与自然梯度的优化优势,尤其在处理高维数据和复杂模型时表现出色。
斯坦福 ML Group最近在他们的论文 Duan et al., 2019 中发表了一种新算法,其实现称为 NGBoost。该算法通过使用自然梯度将不确定性估计包括在梯度提升中。这篇文章试图理解这个新算法,并与其他流行的增强算法 LightGBM 和 XGboost 进行比较,看看它在实践中是如何工作的。
斯坦福ngboost官网如下
https://stanfordmlgroup.github.io/projects/ngboost/

自然梯度使学习高效且有效
什么是自然梯度提升?
NGBoost 是一种新的提升算法,它使用自然梯度提升,一种用于概率预测的模块化提升算法。该算法由基学习器、参数概率分布和评分规则组成。
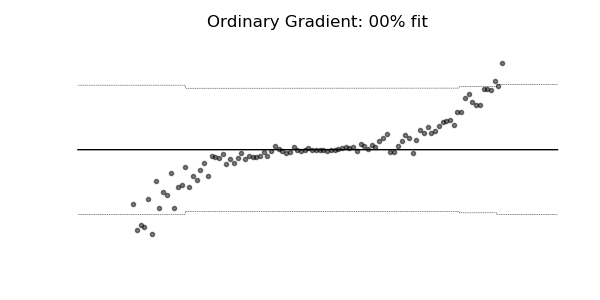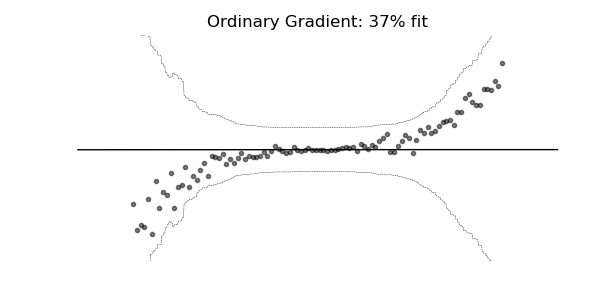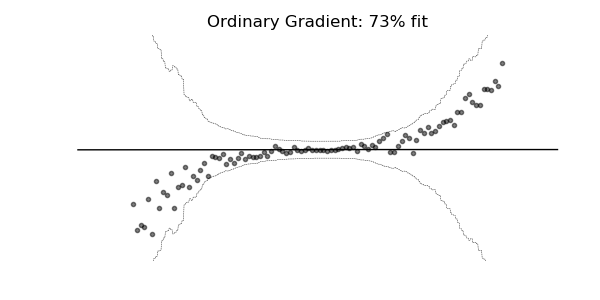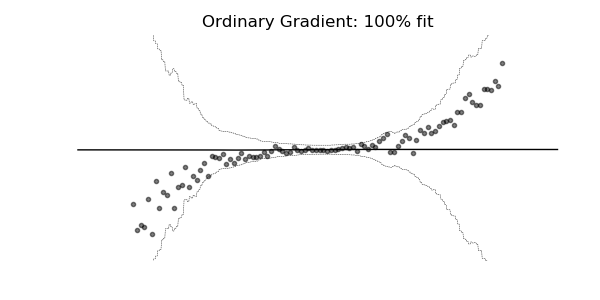
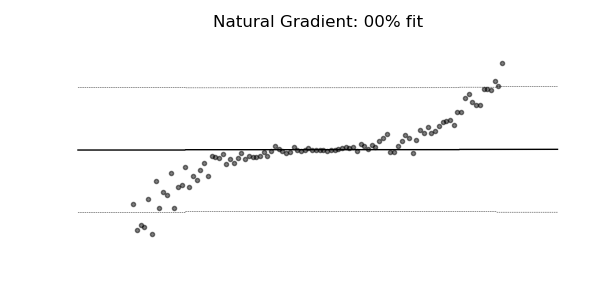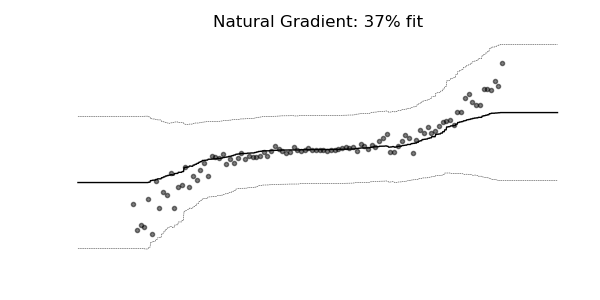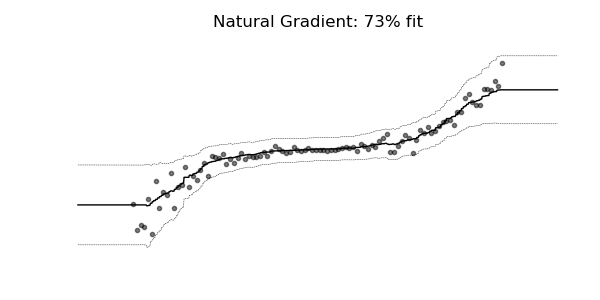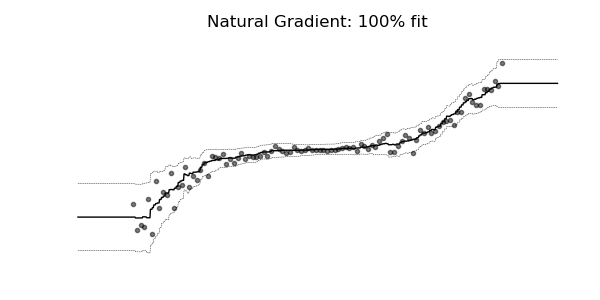
普通梯度可能非常不适合学习多参数概率分布(例如正态分布)。如上面的概率回归示例所示,使用自然梯度的训练动态往往更加稳定并产生更好的拟合。
在不确定性估计和传统指标方面的竞争表现
与竞争方法相比,NGBoost 所需的专业知识要少得多,并且在常见的基准测试中表现同样出色。NGBoost 在较小的数据集上具有特别强的性能。
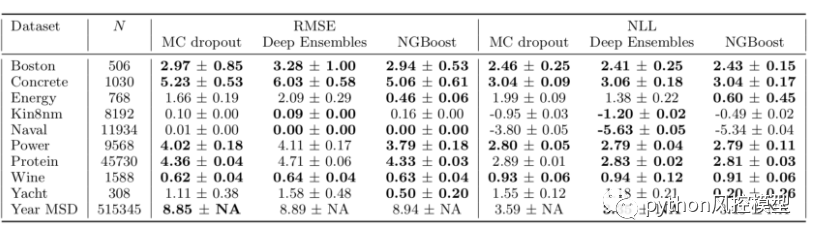
在一个回归模型的实验中,我们发现ngboost获得更低的rmse.
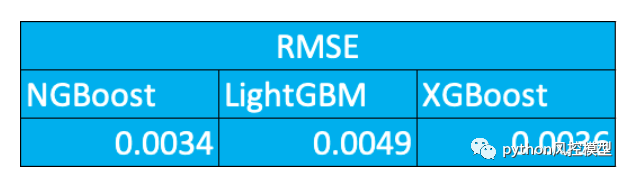
SHAP概述
SHAP(SHapley Additive exPlanations)是一种解释机器学习模型预测的方法,它基于博弈论中的Shapley值概念。SHAP值提供了一种公平的方法来量化每个特征对模型预测结果的贡献。以下是SHAP的关键特点和概述:
-
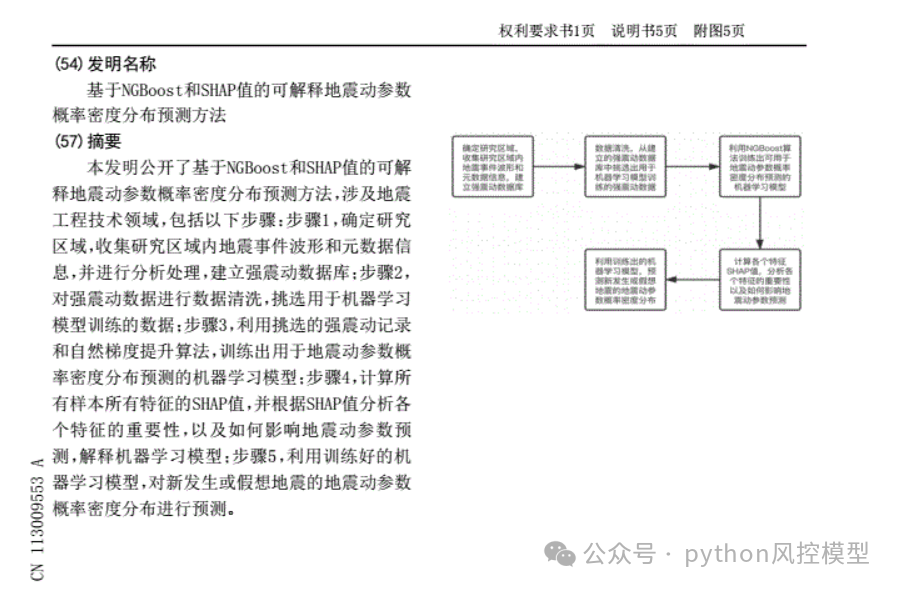
基于Shapley值:
-
SHAP值基于Shapley值,这是一种在合作游戏中分配支付的标准方法,确保每个玩家(在这里是特征)获得其“公平”的份额。
-
-
可解释性:
-
SHAP值提供了一种直观的方式来理解模型的预测,通过分解预测结果并将其归因于各个特征。
-
-
特征贡献度量:
-
对于给定的预测,SHAP值可以量化每个特征对预测结果的正面或负面影响。
-
-
一致性和公平性:
-
SHAP值满足一致性、公平性等博弈论的公理,确保了特征贡献的合理分配。
-
-
多种模型支持:
-
SHAP可以解释多种类型的机器学习模型,包括决策树、随机森林、梯度提升机、线性模型、深度神经网络等。
-
-
可视化工具:
-
SHAP提供了丰富的可视化工具,如力导向图(force plot)和汇总图(summary plot),帮助用户直观地理解模型预测。
-
-
Python实现:
-
SHAP有Python库支持,可以方便地集成到现有的Python机器学习工作流程中。
-
-
交互式解释:
-
SHAP值的计算可以是交互式的,允许用户探索不同特征组合对模型预测的影响。
-
-
适用于复杂模型:
-
尽管SHAP值的计算对于复杂的模型可能很耗时,但它提供了一种强大的方法来解释这些模型的决策过程。
-
-
理论和实践结合:
-
SHAP结合了理论基础和实际应用,使得即使是非技术背景的用户也能够理解模型的工作原理。
-
-
开源和社区支持:
-
SHAP是一个开源项目,得到了数据科学和机器学习社区的广泛支持。
-
SHAP值是解释机器学习模型的重要工具,尤其适用于需要模型透明度和可解释性的场景。通过SHAP值,研究人员和实践者可以更好地理解模型的行为,提高模型的信任度,并做出更明智的决策。
专利复现-基于ngboost和SHAP值可解释预测方法
前期理论知识给大家说清楚了,现在Toby老师用15万真实金融风控数据来复现基于ngboost和SHAP值可解释预测方法。下图是建模数据集,模型通过喂养数据,训练数据,最终生成具有预测能力的AI大模型。
下图是我方已经建立好ngboost预测模型。
下图是我方计算的SHAP values值。
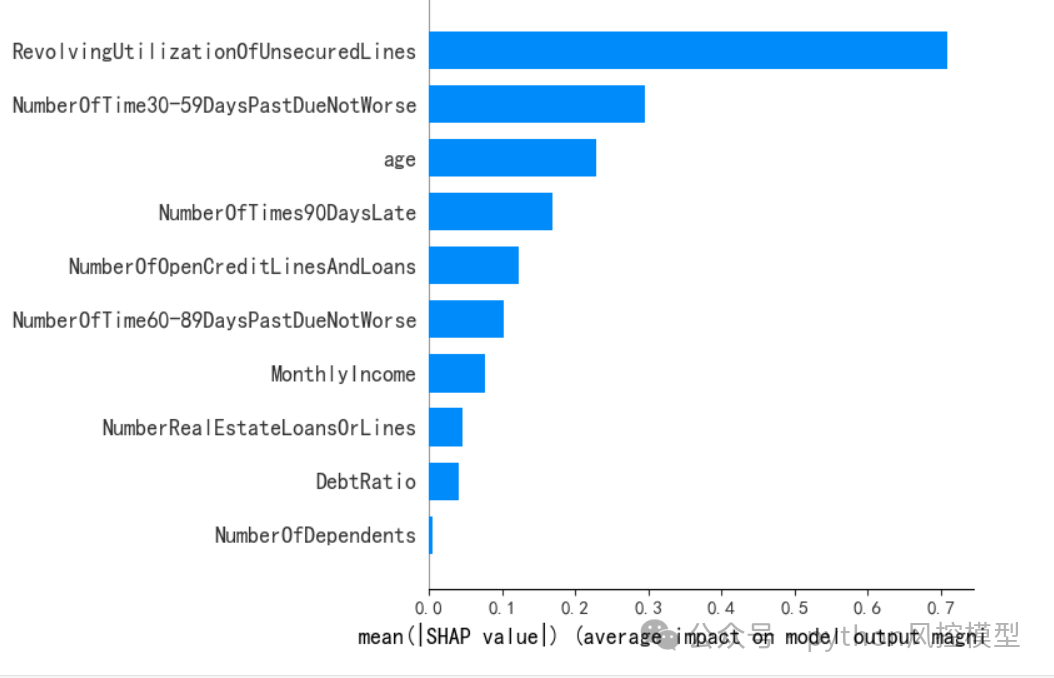
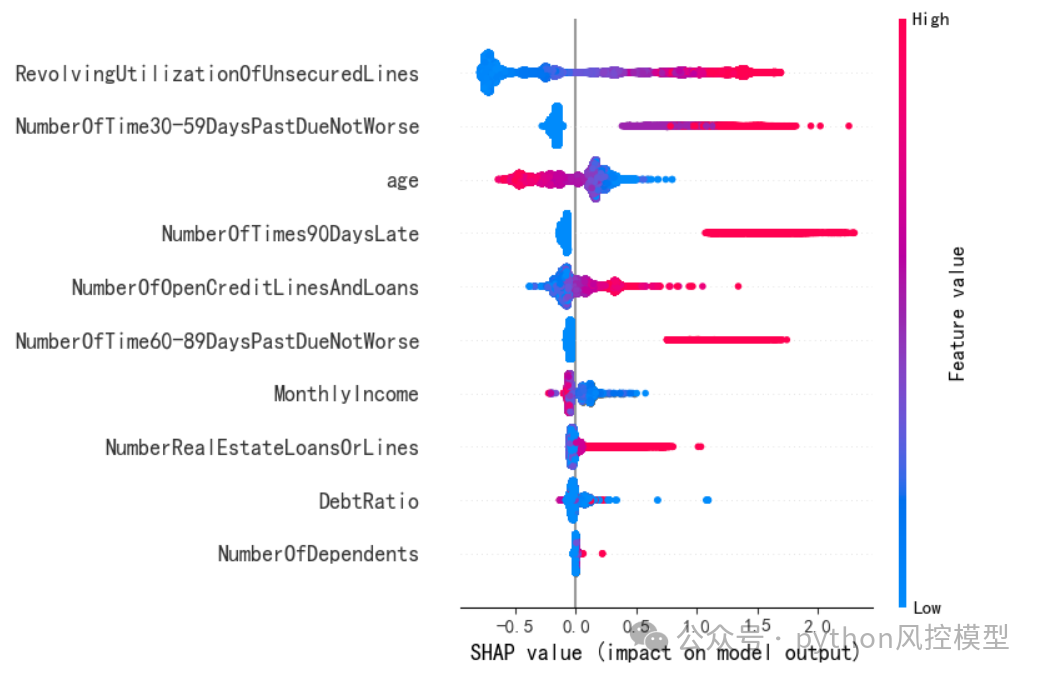
通过SHAP values值,我们计算变量重要性,并从大到小排序。如下图,SHAP+ngboost分析得出Revolving Utilization of Unsecured Lines变量是最重要变量。
"Revolving Utilization of Unsecured Lines"(未担保循环信用额度的使用率)是一个金融术语,通常用于个人信用报告和信贷分析中。它指的是借款人在循环信用账户(如信用卡)上使用的信用额度与可获得的总信用额度的比例。
该变量计算公式=(当期未偿还余额 / 信用额度上限) * 100%。
Revolving Utilization of Unsecured Lines对信用评分有重要影响:
该变量高使用率可能会对个人的信用评分产生负面影响,因为这表明借款人可能面临较高的财务压力。
金融机构和贷款人使用这一指标来评估借款人的信用风险。较高的使用率可能表明借款人依赖信贷来维持消费,这可能增加违约风险。
借款人可以通过降低使用率来提高信用评分,例如通过支付下账单或要求提高信用额度。
SHAP除了横向比较变量重要性,还可以纵向分析变量解释性。如下图,Revolving Utilization of Unsecured Lines值越高,SHAP值越高,违约风险也相应提高,反之亦然。age年龄分析得到相反结论,年龄越小信用风险越高,反之亦然。
如果是金融小白不懂风控,不懂编程,不懂金融,不懂业务,没时间学习没有关系。重庆未来之智信息技术咨询服务有限公司帮助用户设计好零基础操作界面。审批人员无需风控建模知识,无需编程知识,只需要输入用户信息,鼠标点击预测,工具就为显示预测结果。接下来为大家展示。
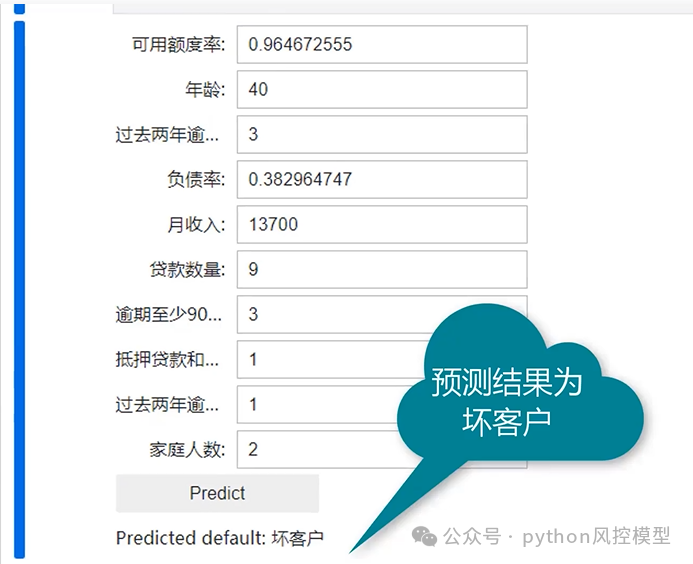
该功能对小白友好,可以增强该专利的功能。