scikit-learn:一个强大的机器学习Python库
我是东哥,一个热衷于用Python解决实际问题的技术爱好者。今天,我要和大家分享一个强大的机器学习库——scikit-learn。你是否曾经对机器学习充满好奇,却觉得它高深莫测?scikit-learn库将帮你轻松入门,让你在机器学习的世界里畅游无阻。
基本介绍
scikit-learn是一个开源的Python机器学习库,它基于NumPy、SciPy和matplotlib,为数据挖掘和数据分析提供了简单高效的数据处理和建模工具。scikit-learn拥有丰富的算法集合,包括分类、回归、聚类和降维等,同时还提供了模型选择和评估的工具,使得数据科学家能够轻松地构建和优化机器学习模型。
项目地址:https://github.com/scikit-learn/scikit-learn
安装方法
安装scikit-learn非常简单,你可以使用pip命令来进行安装:
pip install scikit-learn
如果你使用的是Anaconda环境,也可以通过conda命令来安装:
conda install scikit-learn
基本用法
示例1:简单的分类任务
假设你有一个数据集,想要使用scikit-learn来进行分类任务。我们可以用经典的鸢尾花数据集来演示这个过程。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=20240901)
# 创建分类器
classifier = KNeighborsClassifier(n_neighbors=3)
classifier.fit(X_train, y_train)
# 预测测试集
y_pred = classifier.predict(X_test)
# 输出准确率
print("准确率:", accuracy_score(y_test, y_pred))
在这个例子中,我们使用了K-近邻分类器来对鸢尾花数据集进行分类,并计算了模型的准确率,输出准确率如下:
准确率: 0.9777777777777777
示例2:回归任务
接下来,我们来看看如何使用scikit-learn进行回归任务。我们将使用波士顿房价数据集来演示这个过程。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
# 加载数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
y = raw_df.values[1::2, 2]
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=20240901)
# 创建回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 输出均方误差
print("均方误差:", mean_squared_error(y_test, y_pred))
在这个例子中,我们使用了线性回归模型来预测房价,并计算了均方误差,以评估模型的性能。输出均方误差如下:
均方误差: 25.680305066882532
高级用法
示例3:聚类任务
scikit-learn还支持聚类任务,比如K均值聚类。下面的代码演示了如何对数据进行聚类。
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=20240901)
# 创建K均值模型
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
# 获取聚类结果
y_kmeans = kmeans.predict(X)
# 绘制结果
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.show()
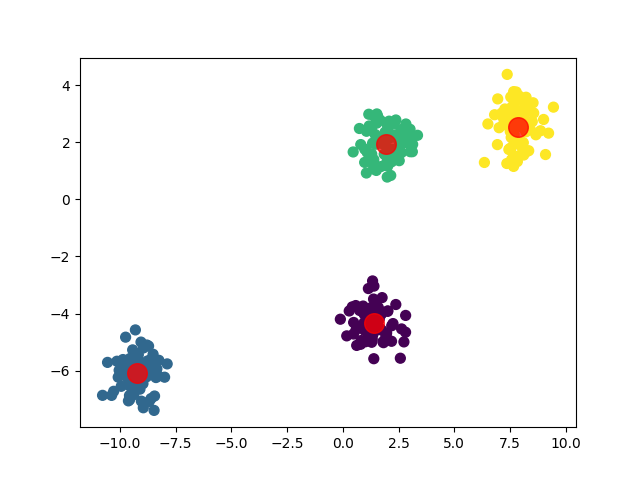
在这个例子中,我们使用了K均值算法对生成的数据进行聚类,并通过散点图可视化了聚类结果。聚类结果可视化如下:
示例4:网格搜索
接下来,通过一个更复杂的例子来展示scikit-learn的高级功能——使用网格搜索来优化模型参数。
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建SVM分类器实例
svc = SVC()
# 设置参数网格
parameters = {'kernel': ('linear', 'rbf'), 'C': [1, 10]}
# 创建GridSearchCV实例
clf = GridSearchCV(svc, parameters)
# 训练模型
clf.fit(X, y)
# 输出最佳参数和最佳得分
print(clf.best_params_)
print(clf.best_score_)
在这个例子中,我们使用了鸢尾花数据集,并尝试通过SVM分类器来进行分类。我们定义了一个参数网格,包含了不同的核函数和C值。然后,我们使用GridSearchCV来进行网格搜索,并找到最佳的参数组合。输出最佳参数组合如下:
{'C': 1, 'kernel': 'linear'}
0.9800000000000001
小结
scikit-learn是一个功能强大的机器学习库,它简化了机器学习的流程,使得初学者也能快速上手。无论你是想进行数据探索、模型训练还是性能评估,scikit-learn都能提供相应的工具和方法。
希望这篇文章能让你对scikit-learn有一个基本的了解,并激发你探索更多可能。如果你有任何问题或想要深入探讨scikit-learn的其他功能,请随时留言。
公众号东哥说AI后台回复005获取文中完整代码~