【java基础】Stream流的各种操作
文章目录
- 基本介绍
- 流的创建
- 流的各种常见操作
- forEach方法
- filter方法
- map方法
- peek方法
- flatMap方法
- limit和skip方法
- distinct方法
- sorted方法
- 收集结果
- 收集为数组(toArray)
- 收集为集合(collect)
- 收集为Map
- 关于流的一些说明(终结操作)
- 总结
基本介绍
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
与集合相比,流提供了一种可以让我们在更高概念级别上指定计算任务的数据视图
注意:学习Stream必须要十分清晰的了解lamdba表达式,如果lambda不清楚,请参考一篇文章彻底搞懂lambda表达式
流的创建
我们在学习流之前,应当先了解一下Stream这个类,Stream类的类图和方法如下
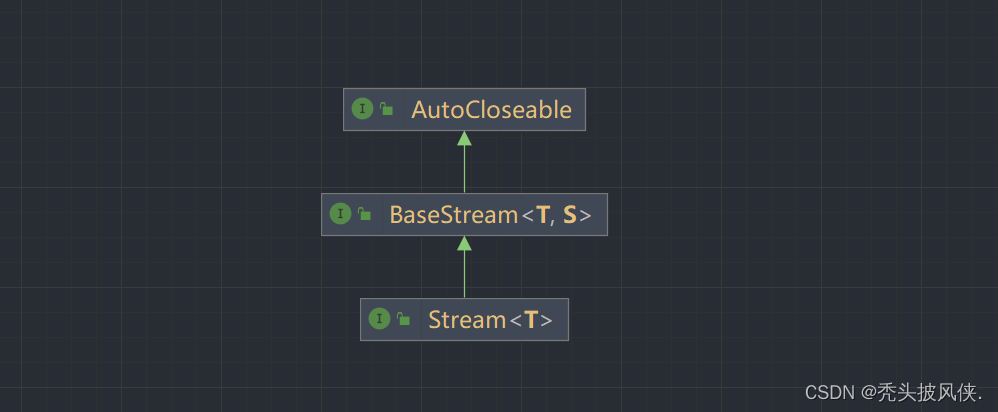
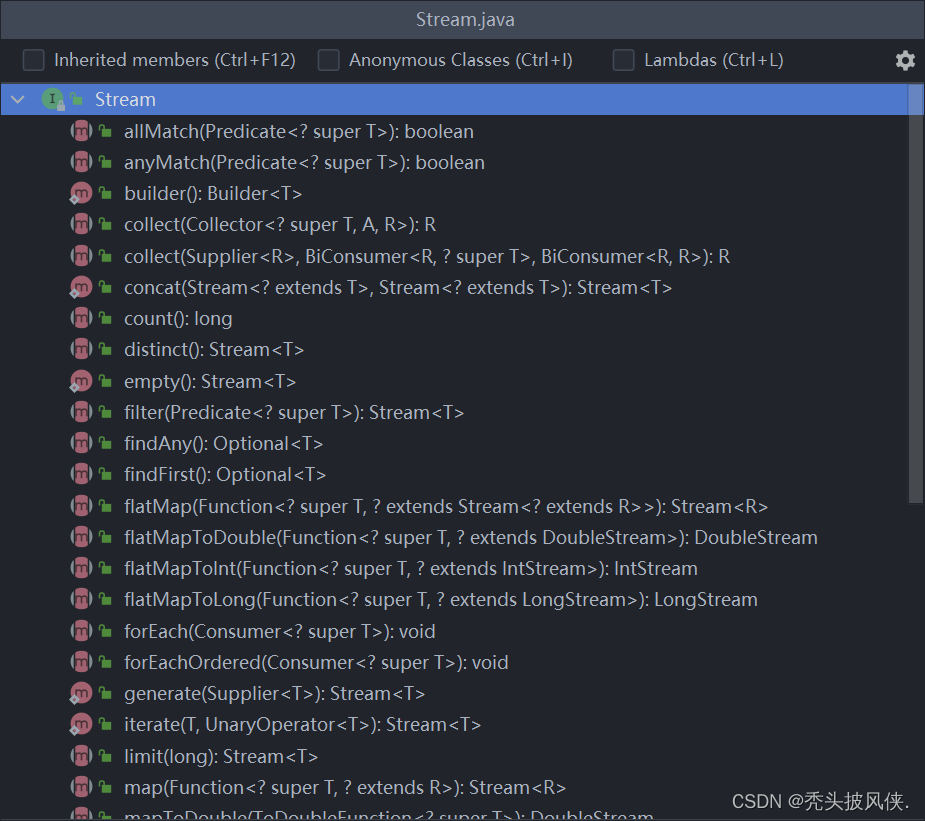
对于创建流,我们可以使用静态方法Stream.of来创建
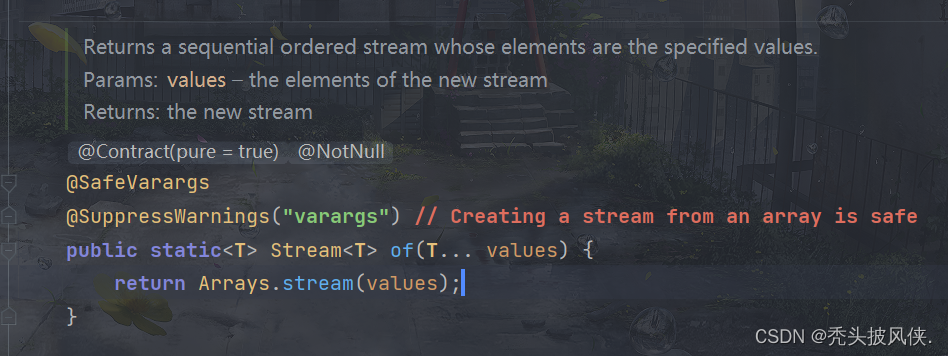
该方法传入一个可变长度的参数,然后就会返回对应类型的流
Stream<Integer> stream = Stream.of(2, 3, 1, 4);
如果要创建一个不包含任何元素的流,可以使用Stream.empty
Stream<Object> empty = Stream.empty();
我们还可以使用Stream的静态方法generate和iterate来创建无限流。
下面就通过generate创建了一个获取随机数的流
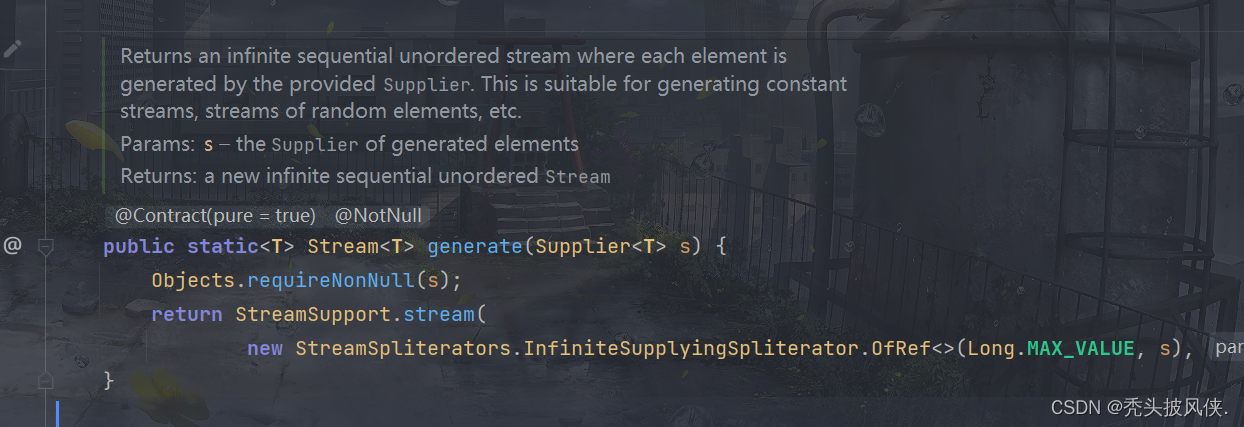
Stream<Double> randomNumStream = Stream.generate(Math::random);
如果想要创建例如0,1,2,3这样有规律的序列流,那么就可以使用iterate方法

Stream<Integer> iterate = Stream.iterate(0, num -> num+1);
除了上面几个静态方法,对于流的创建还有许多方法,例如Arrays.stream方法
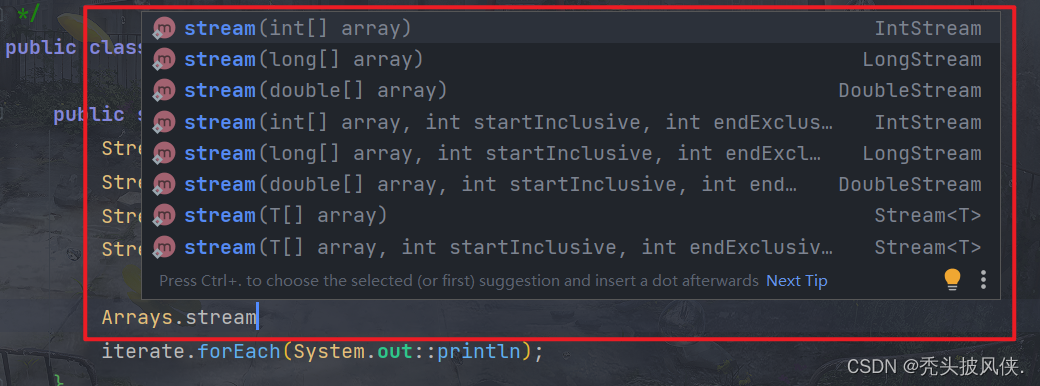
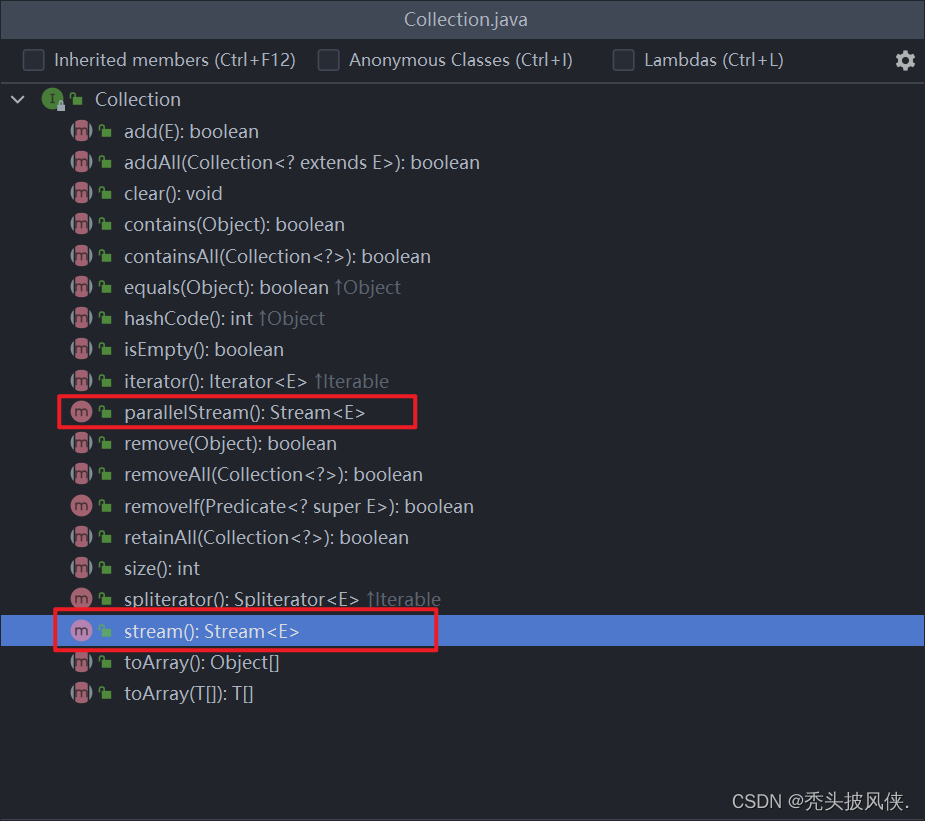
在Collection中有stream方法和parallelStream方法都可以返回一个Stream流,这也就说明了所有的集合都可以调用这2个方法返回对应的流
对于流,我们有几点注意事项如下
- 流并不存储元素,这些元素可能存储在底层的集合中,或者是按需生成的
- 流的操作不会改变其数据源
- 流的操作尽可能惰性执行。这意味着直至需要其结果时,操作才会执行
流的各种常见操作
这里主要介绍在流里面使用频率较高的几个操作,每个方法都会给出该方法的源注释,以及基本使用,请参考注释和代码来进行理解
forEach方法
这个方法可以对流里面的每一个元素执行操作
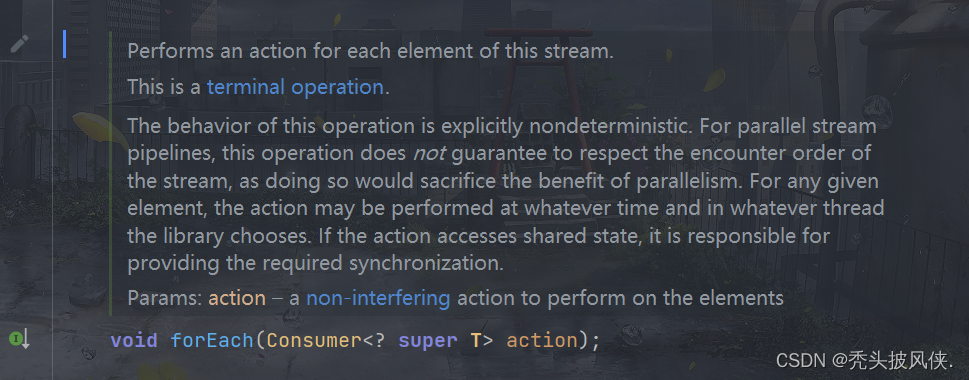
Stream<Integer> stream = Stream.of(2, 3, 1, 4);
stream.forEach(System.out::println);
输出结果如下
2
3
4
1
filter方法
该方法可以过滤掉流中不满足要求的元素,会返回一个新流
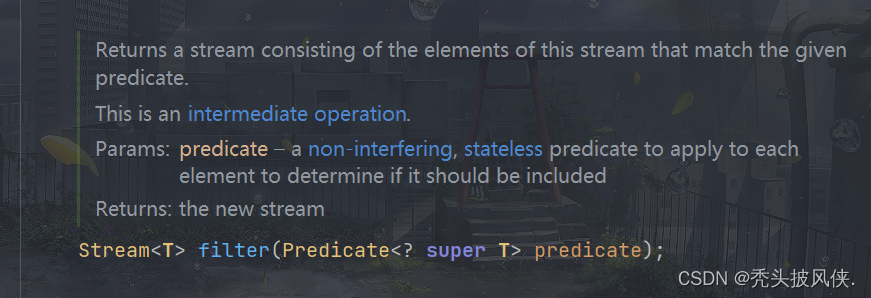
Stream<Integer> stream = Stream.of(2, 3, 1, 4);
Stream<Integer> newStream = stream.filter(num -> num > 2);
System.out.print("过滤之后:");
newStream.forEach(x -> System.out.print(x + " "));
上面代码输出如下
过滤之后:3 4
map方法
当我们想要按照某种方式来转换流中的值的时候,我们就可以使用map

Stream<Integer> stream = Stream.of(2, 3, 1, 4);
Stream<Integer> newStream = stream.map(num -> num + 1);
newStream.forEach(System.out::println);
上面代码输出如下
3
4
2
5
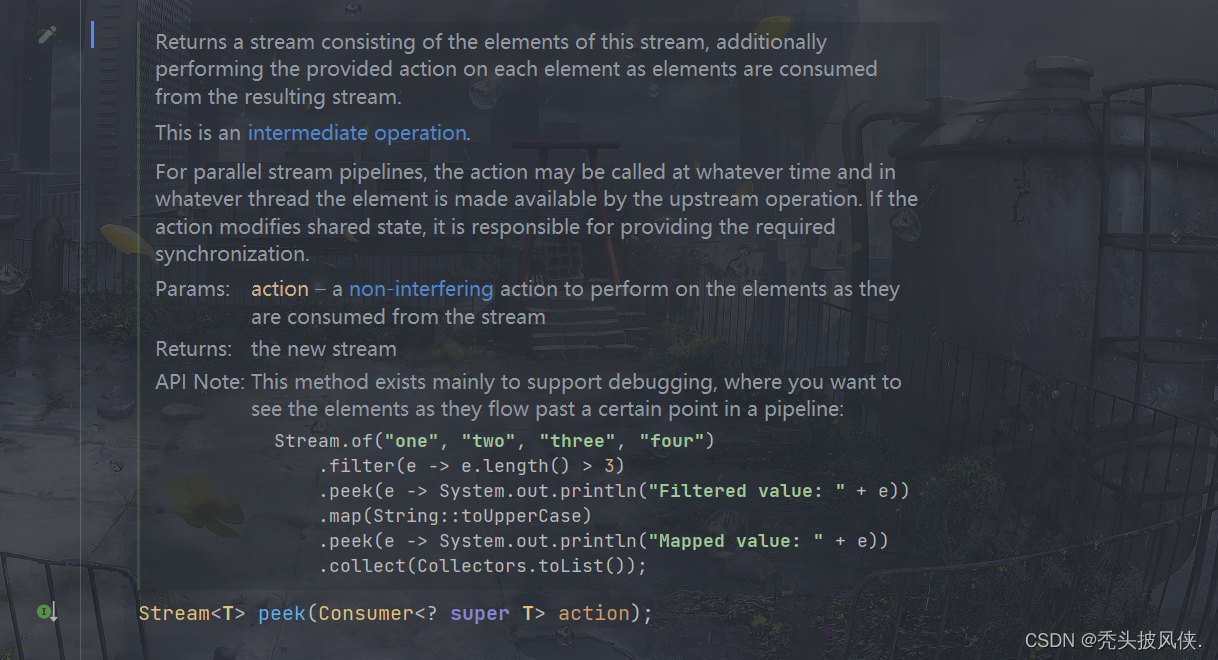
peek方法
该方法可以对流中的每一个元素进行操作,返回新的流
public class Dog {
public String name;
public Integer age;
public Dog(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Dog[] dogs = {new Dog("tom", 1),new Dog("旺财", 2)};
Stream<Dog> dogStream = Arrays.stream(dogs);
Stream<Dog> newDogStream = dogStream.peek(dog -> dog.age = 999);
newDogStream.forEach(System.out::println);
上面代码输出如下
Dog{name='tom', age=999}
Dog{name='旺财', age=999}
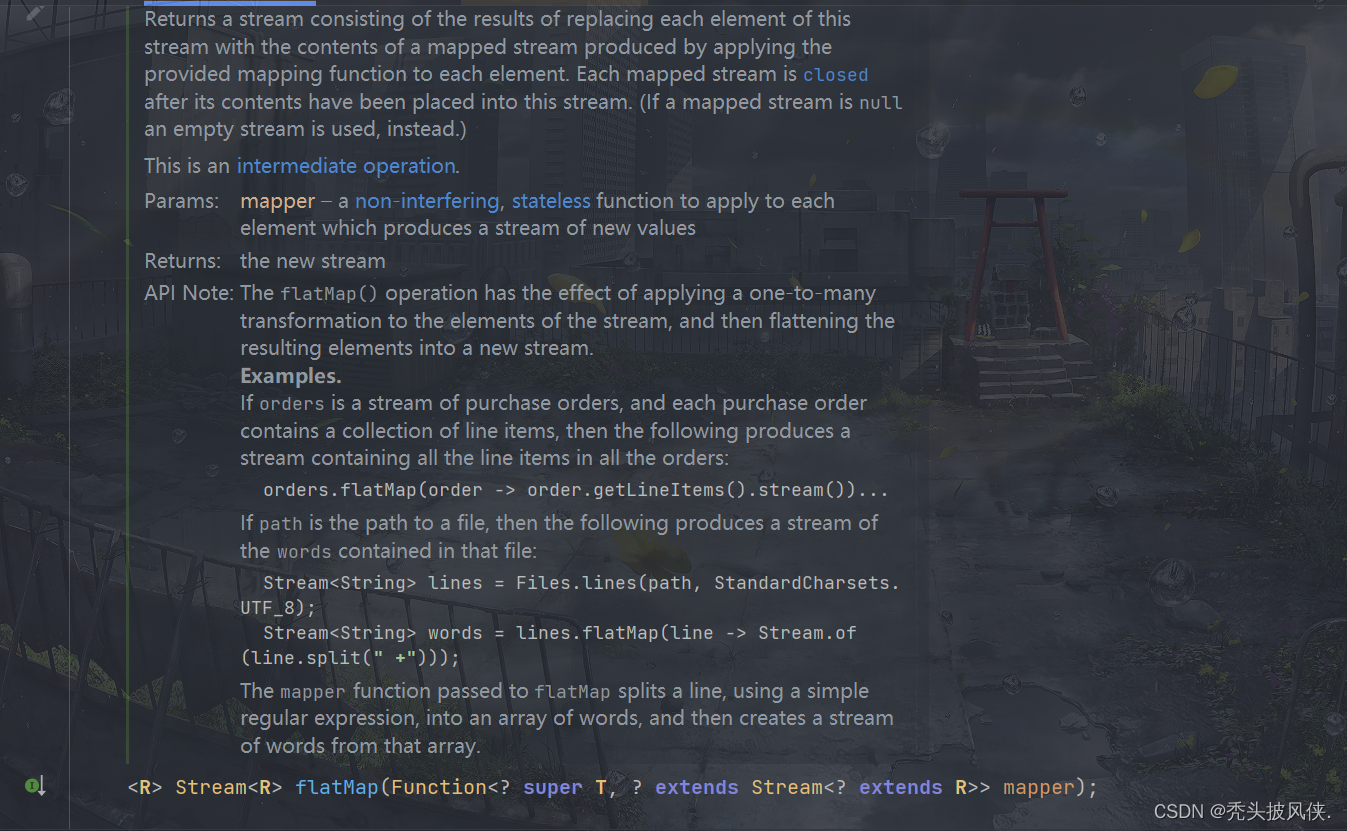
flatMap方法
该方法产生一个流,它是通过将传入lambda表达式应用于当前流中所有元素所产生的结果连接到一起而获得的。(注意,这里的每个结果都是一个流。)
List<Stream<Integer>> streamList = new ArrayList<>();
Stream<Integer> stream1 = Stream.of(1, 2, 3);
Stream<Integer> stream2 = Stream.of(4, 5, 6);
Stream<Integer> stream3 = Stream.of(7, 8, 9);
streamList.add(stream1);
streamList.add(stream2);
streamList.add(stream3);
Stream<Stream<Integer>> stream = streamList.stream();
// flatMap里面的lambda表达式应当返回一个流
Stream<Integer> integerStream = stream.flatMap(x -> x);
integerStream.forEach(System.out::println);
上面代码输出如下
1
2
3
4
5
6
7
8
9
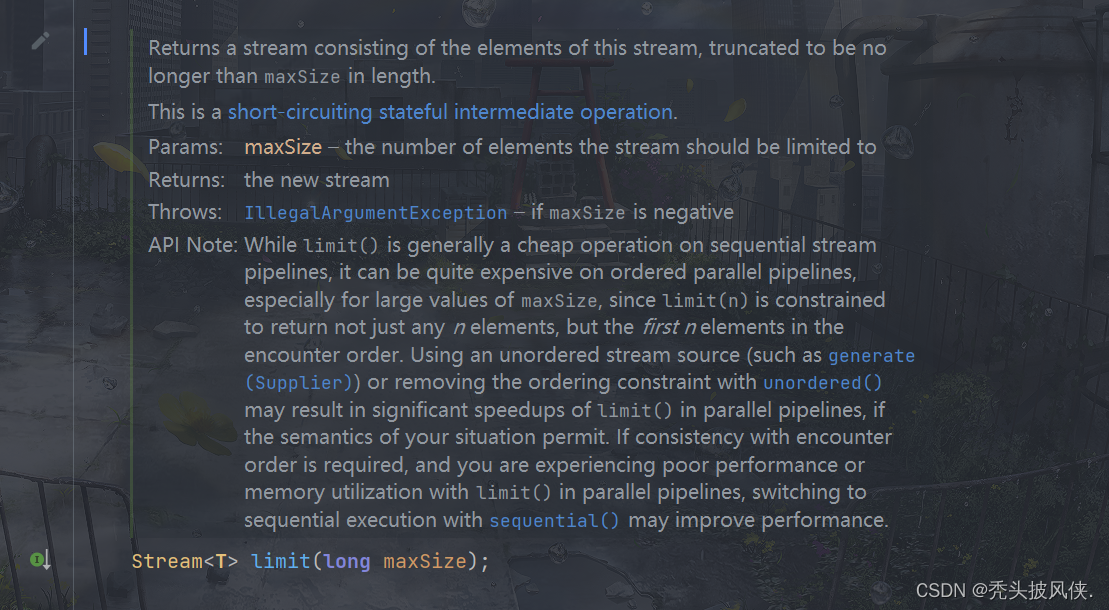
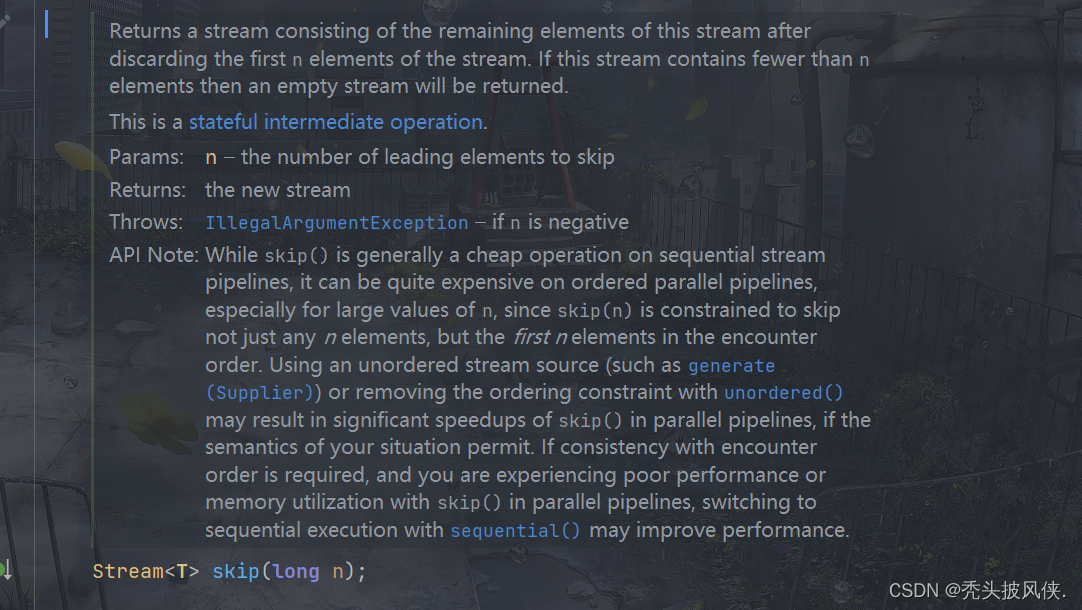
limit和skip方法
limit方法可以对流进行裁剪,只取前n个流,skip方法则是跳过前n个流
由于limit和skip用法基本由于,这里就用limit作为例子
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> newStream = stream.limit(4);
newStream.forEach(System.out::println);
上面代码输出如下
1
2
3
4
distinct方法
这个方法相当于去重

Stream<Integer> stream = Stream.of(1, 2, 3, 3, 1, 4);
Stream<Integer> newStream = stream.distinct();
newStream.forEach(System.out::println);
代码输出如下
1
2
3
4
sorted方法
这个方法一看就知道是排序用的
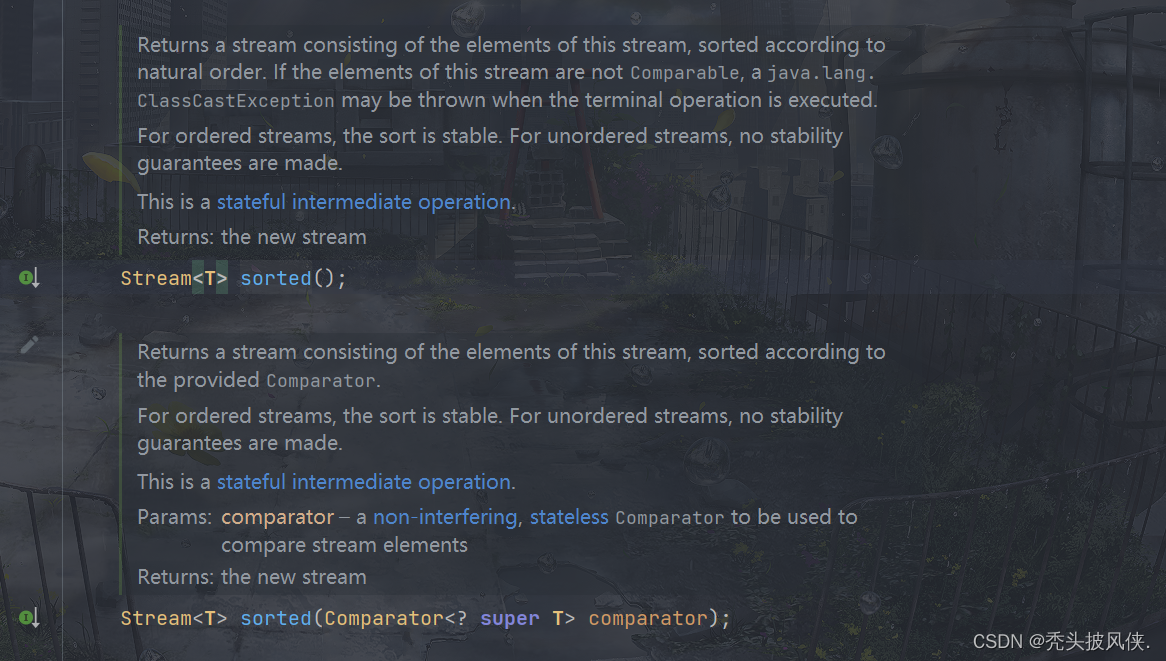
该方法有2个,一个带有Comparator,就是用于指定排序方式的
Stream<Integer> stream = Stream.of(4, 1, 3, 2);
Stream<Integer> newStream = stream.sorted();
newStream.forEach(System.out::println);
代码输出如下
1
2
3
4
收集结果
在上面我们都只是对流进行操作,现在来讲解下如何将流里面的数据收集到集合中。
收集为数组(toArray)
我们可以调用流里面的toArray方法,传入对应的类型数组即可
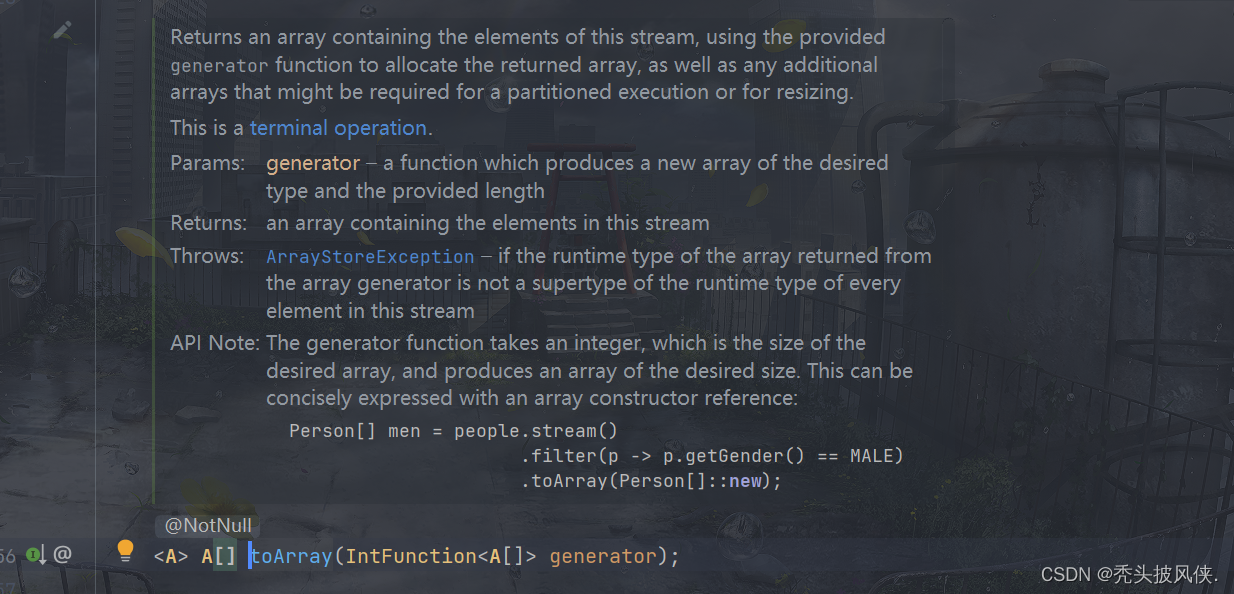
Stream<String> namesStream = Stream.of("tom", "luck", "jerry");
String[] names = namesStream.toArray(String[]::new);
System.out.println(Arrays.toString(names));
上面代码输出如下
[tom, luck, jerry]
收集为集合(collect)
调用stream里面的collect方法,然后传入指定的Collector实例即可,Collector提供了大量用于生成常见收集器的工厂方法。
Collector类的方法如下
可以发现有很多方法,这里先介绍几个常用的,其他的方法在后面文章中进行说明。
List<Integer> nums = Arrays.asList(1,2,3,1,4);
toList()可以将结果收集为List
List<Integer> list = nums.stream().collect(Collectors.toList());
toSet()可以将结果收集为Set
Set<Integer> set = nums.stream().collect(Collectors.toSet());
toCollection()可以指定收集的集的种类
TreeSet<Integer> treeSet = nums.stream().collect(Collectors.toCollection(TreeSet::new));
在Collector这个类里面还有其他的很多方法,建议大家去看看这个类的文档,对每个方法都有个影响,需要用到某种操作的时候查找文档即可。
收集为Map
Map也是集合,但是Map收集要比如List,Set等要麻烦一点,所以这里单独说明一下,toMap方法如下
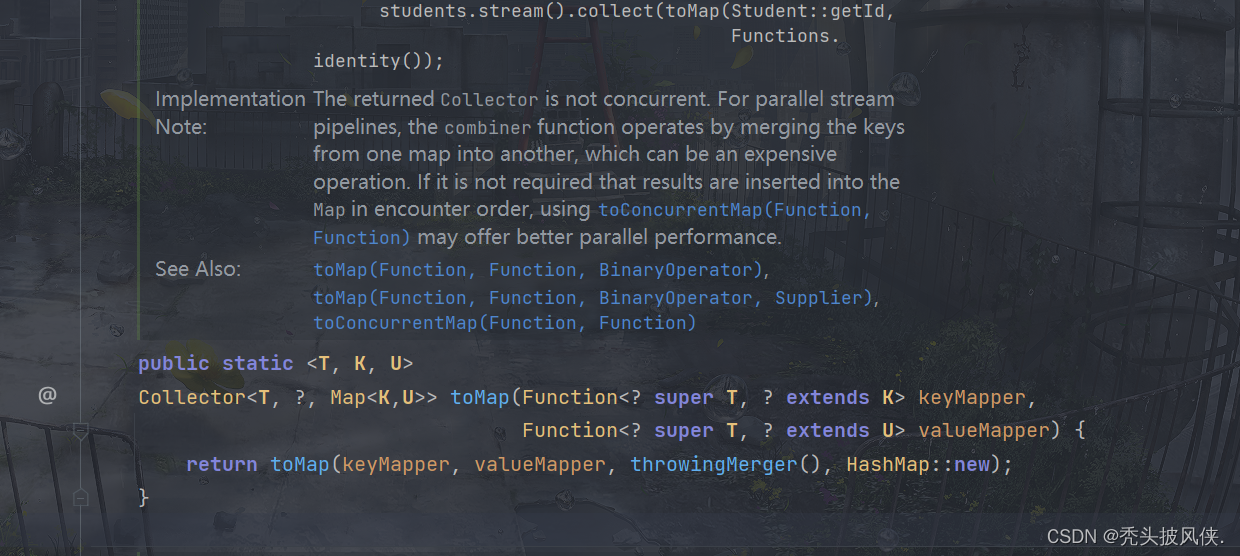
我们需要指定k和v是什么,其实就是对于每一个元素,用什么来作为k和v
Stream<String> namesStream = Stream.of("tom", "jack", "lucy");
Map<Character, String> namesMap = namesStream
.collect(Collectors
.toMap(k -> k.charAt(0), v -> v.toUpperCase()));
System.out.println(namesMap);
上面代码就用字符串的第一个字符作为k,然后用字符串的大写作为v。上面代码输出如下
{t=TOM, j=JACK, l=LUCY}
使用toMap还有一点需要说明,就是key不能冲突,看下面代码,就会产生key冲突
Stream<String> namesStream = Stream.of("tom", "jack", "lucy","ttpfx");
Map<Character, String> namesMap = namesStream
.collect(Collectors
.toMap(k -> k.charAt(0), v -> v.toUpperCase()));
System.out.println(namesMap);
如果产生key冲突,那么collect方法会抛出一个一个IllegalStateException异常
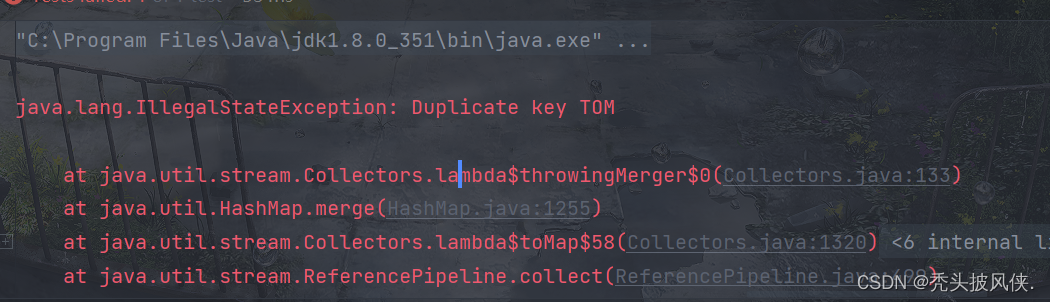
对于key冲突的情况,我们应该给出解决key冲突的逻辑,toMap还有一个重载的方法,用于解决key冲突。也就是保留新值还是旧值
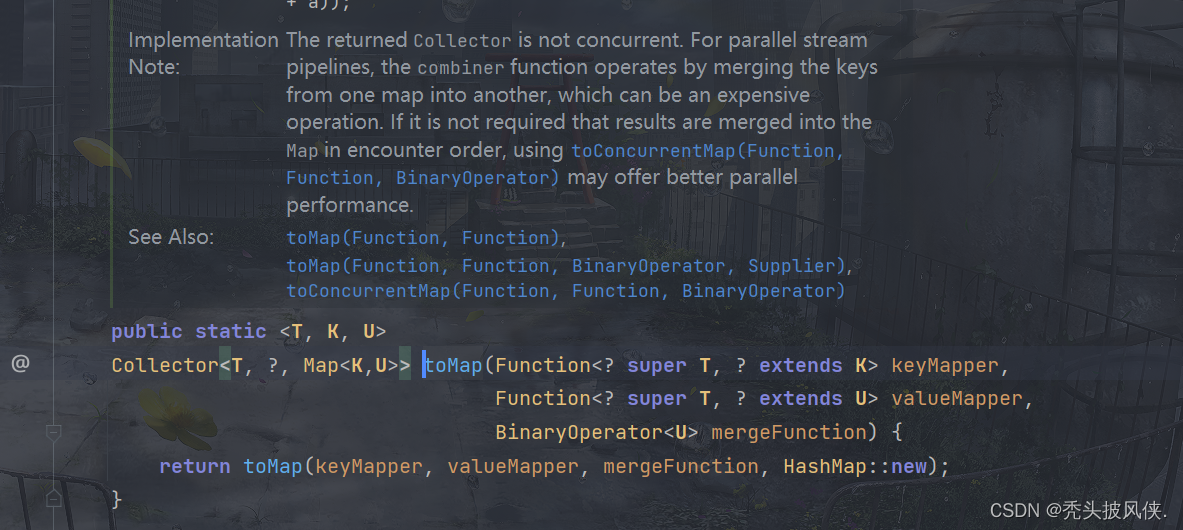
我们遇到key冲突旧保存最新的值即可
Stream<String> namesStream = Stream.of("tom", "jack", "lucy", "ttpfx");
Map<Character, String> namesMap = namesStream
.collect(Collectors
.toMap(k -> k.charAt(0),
v -> v.toUpperCase(),
(oldV, newV) -> newV));
System.out.println(namesMap);
上面代码输出如下
{t=TTPFX, j=JACK, l=LUCY}
对于toMap,都有一个等价的toConcurrentMap
关于流的一些说明(终结操作)
我们先来看下面代码
Stream<Integer> stream = Stream.of(2, 3, 1, 4);
stream.forEach(System.out::println);
Stream<Integer> newStream = stream.filter(x -> x > 2);
newStream.forEach(System.out::println);
上面代码逻辑很简单,就是先输出流里面的元素,然后过滤一下,最后再输出。按理说这个代码应该是没有问题的,我们运行一下
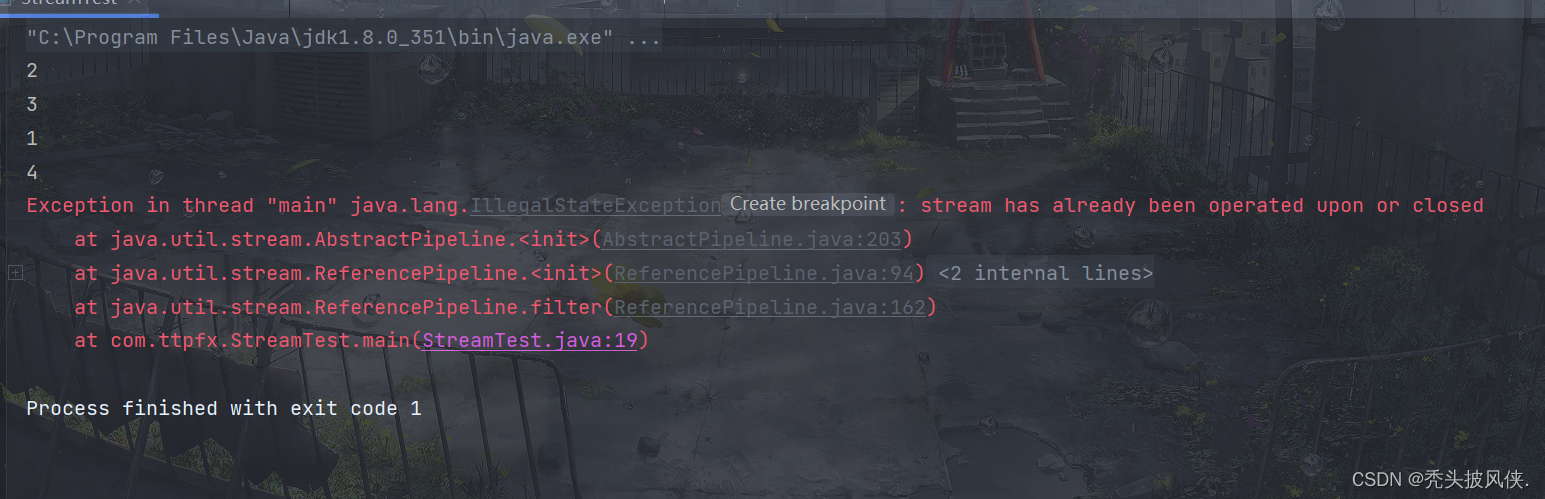
可以发现报错了,报错的原因就是说流已经关闭了,很奇怪啊,我们明明没有执行close操作
造成流关闭的原因就是 forEach方法。还记得在文章开始的说明吗?流是惰性执行的,在流执行终止操作前,流其实都没有执行。而forEach就是一个终止操作。对于终结方法,我们可以简单理解为就是返回值不是Stream的方法。
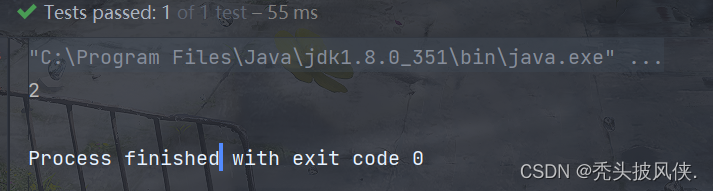
我们用代码验证一下Stream的惰性执行
List<Integer> list = new ArrayList<>();
list.add(1);
Stream<Integer> stream = list.stream();
list.add(2);
long count = stream.count();
System.out.println(count);
大家想一下,count是多少?由于Stream是惰性执行的,那么count显然应该就是2
总结
在这篇文章中介绍了Stream的一些基本使用,对于Stream还有许多的方法没有说明,这些会在后面的文章中进行说明。Stream里面还有一个很重要的Optional,这个将在下一篇文章中进行说明。