Redis面经
缓存系列
缓存穿透
 什么是缓存穿透
什么是缓存穿透
缓存穿透:查询一个数据库中不存在的数据,那么查询不成功也就会导致数据库中的查询不会返回缓存,从而通过大量的请求去造成负担
 实践方案一:如果数据库查询失败就返回为空给Redis从而实现防止穿透的效果
实践方案一:如果数据库查询失败就返回为空给Redis从而实现防止穿透的效果
但是这个方案的缺点也很明显,如果大量的数据库查询为空打过来那么也就会导致很多缓存,消耗了内存,同时如果大量的不一样的不在数据库中的请求打过来那么一样可以造成宕机
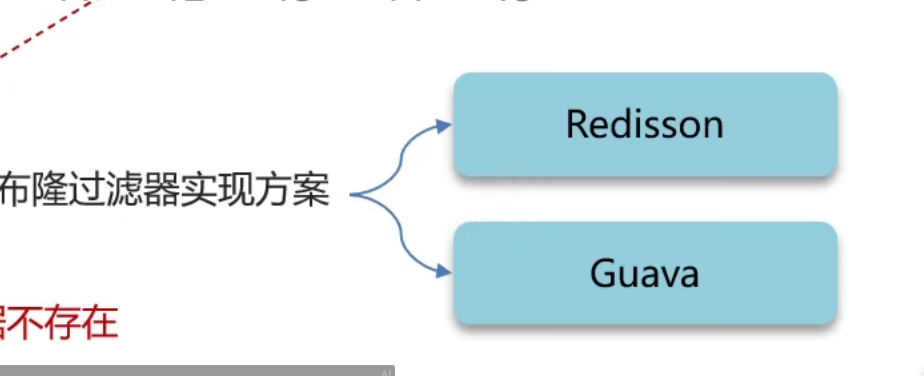
方案二:布隆过滤器
那么布隆过滤器是采用什么原理呢
布隆过滤器,实际上就是在查询流程中间添加一个过滤器,从而把一些很大可能不存在的东西给过滤走,降低直接打到DB的可能性
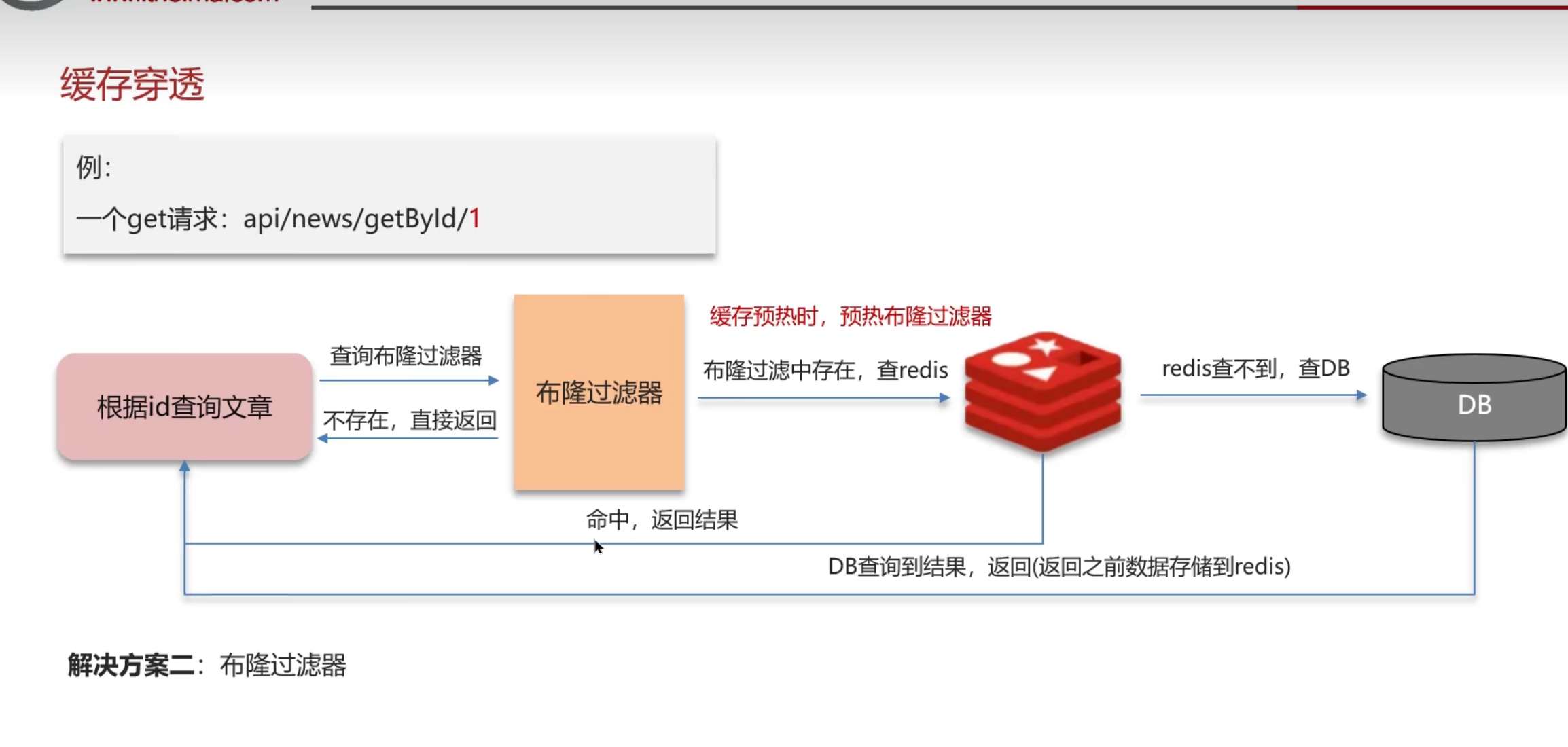
那么缺点呢也很明显,直接加了个布隆过滤器,那么肯定会影响效率和时间
,外加上并不是百分百可能完全过滤
关于布隆过滤器的原理
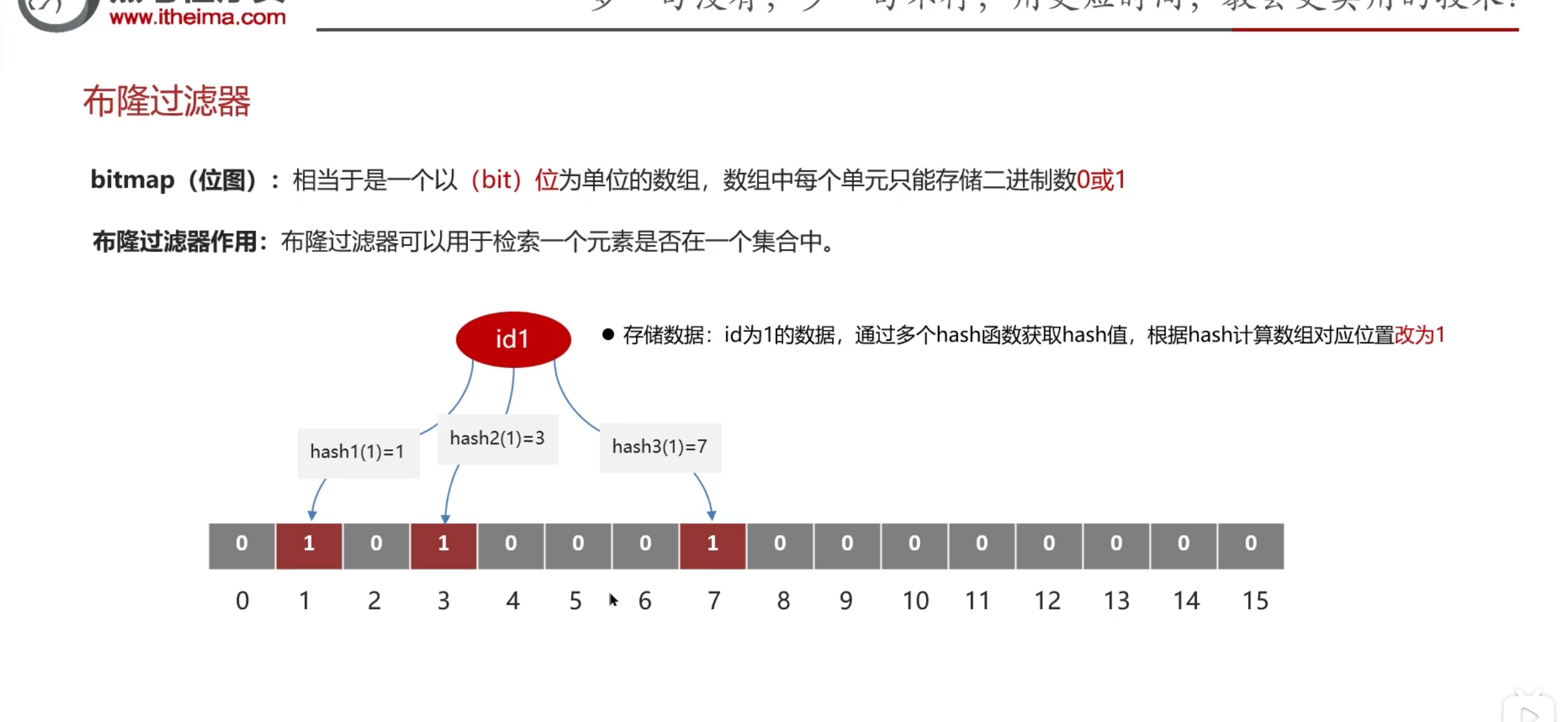
本质上就是一个以bit为单位的数组,储存二进制数0或1
通过hash函数把这个id1放到数组里面去判断这个查询的函数是否在数据库里面
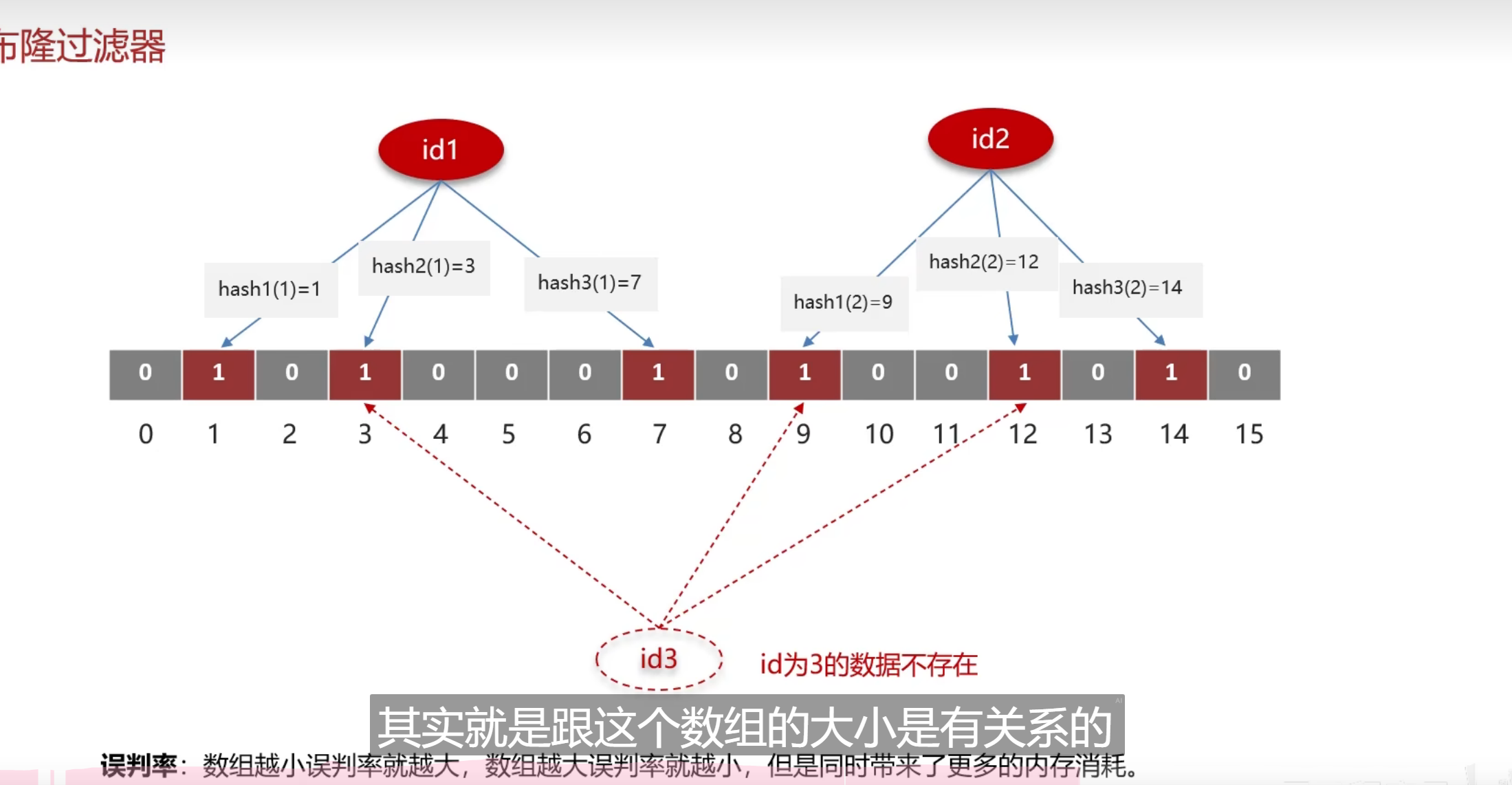
通过这个去判断是否存在误判

下一个问题
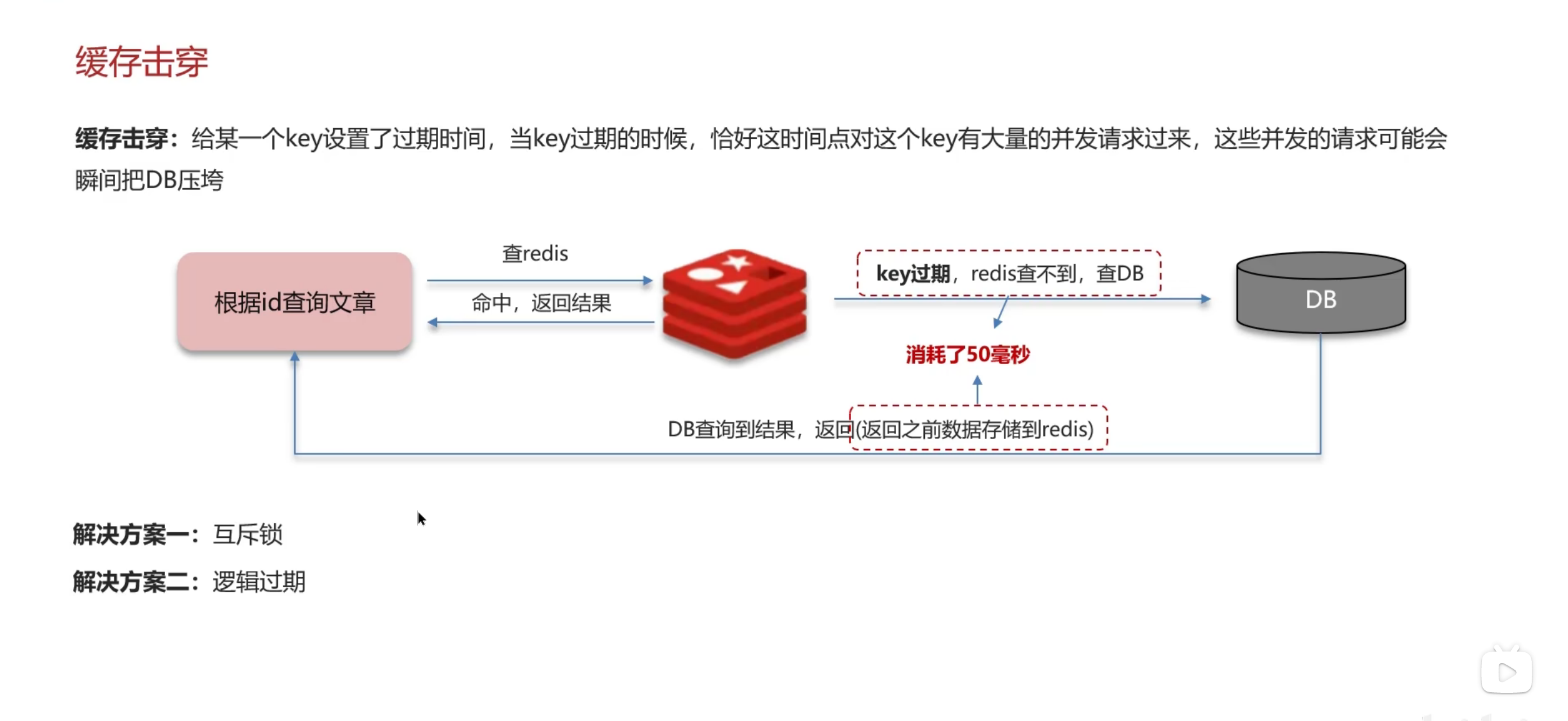
缓存击穿
缓存击穿就是:在某个时段,设置的key失效了,同时有大量关于这个key的并发请求打进来导致数据库宕机
那么解决方案也很简单,第一个就是限制多线程嘛,降低效率,让符合在数据库的承受能力即可
第二个逻辑过期
就是让redis中的key不在同时去进行失效
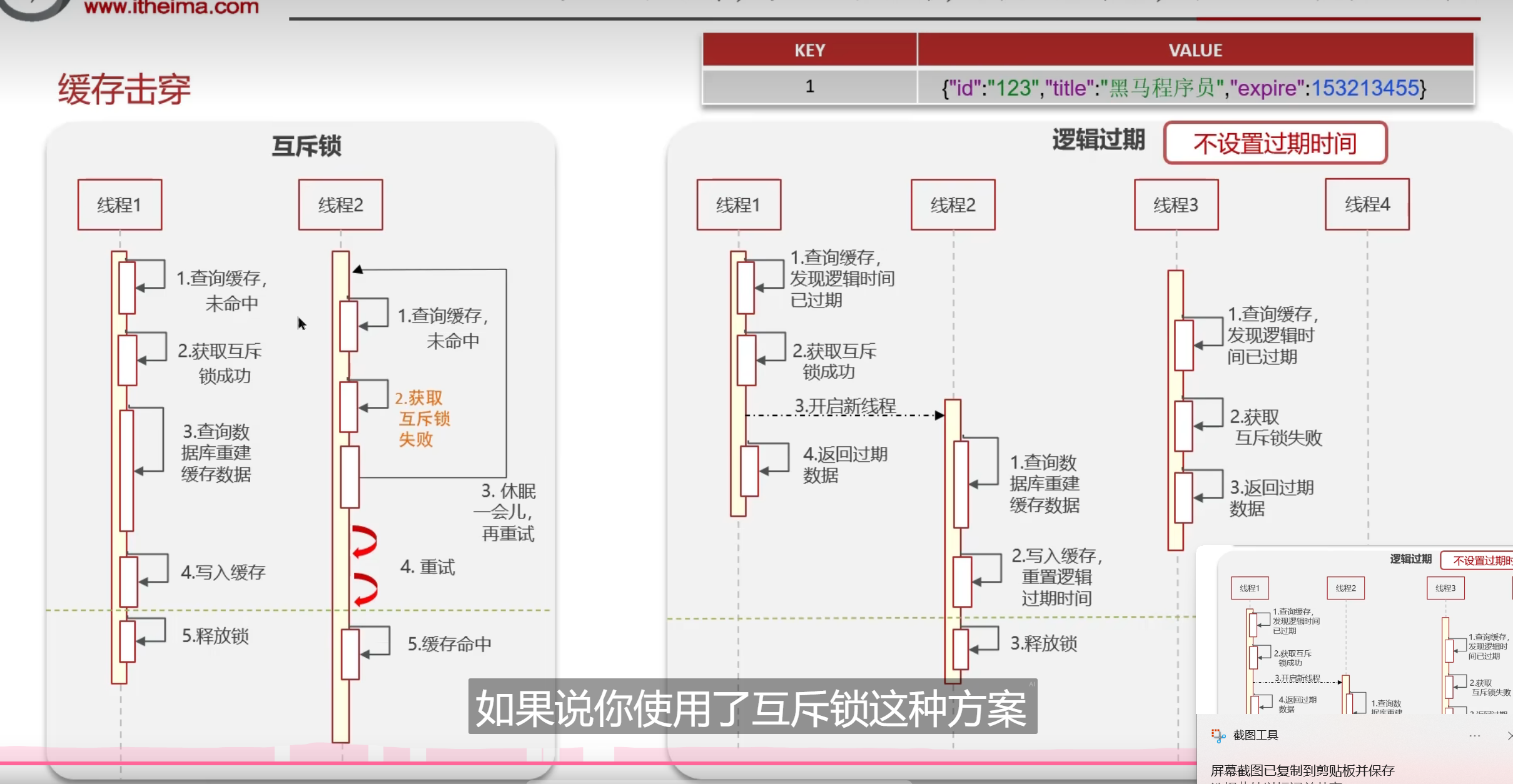
这个还是逻辑过期比较牛逼
这个方案的话解决了很多问题,但是我觉得这个方案的话会导致内存有比正常多一点占用不过问题应该不大
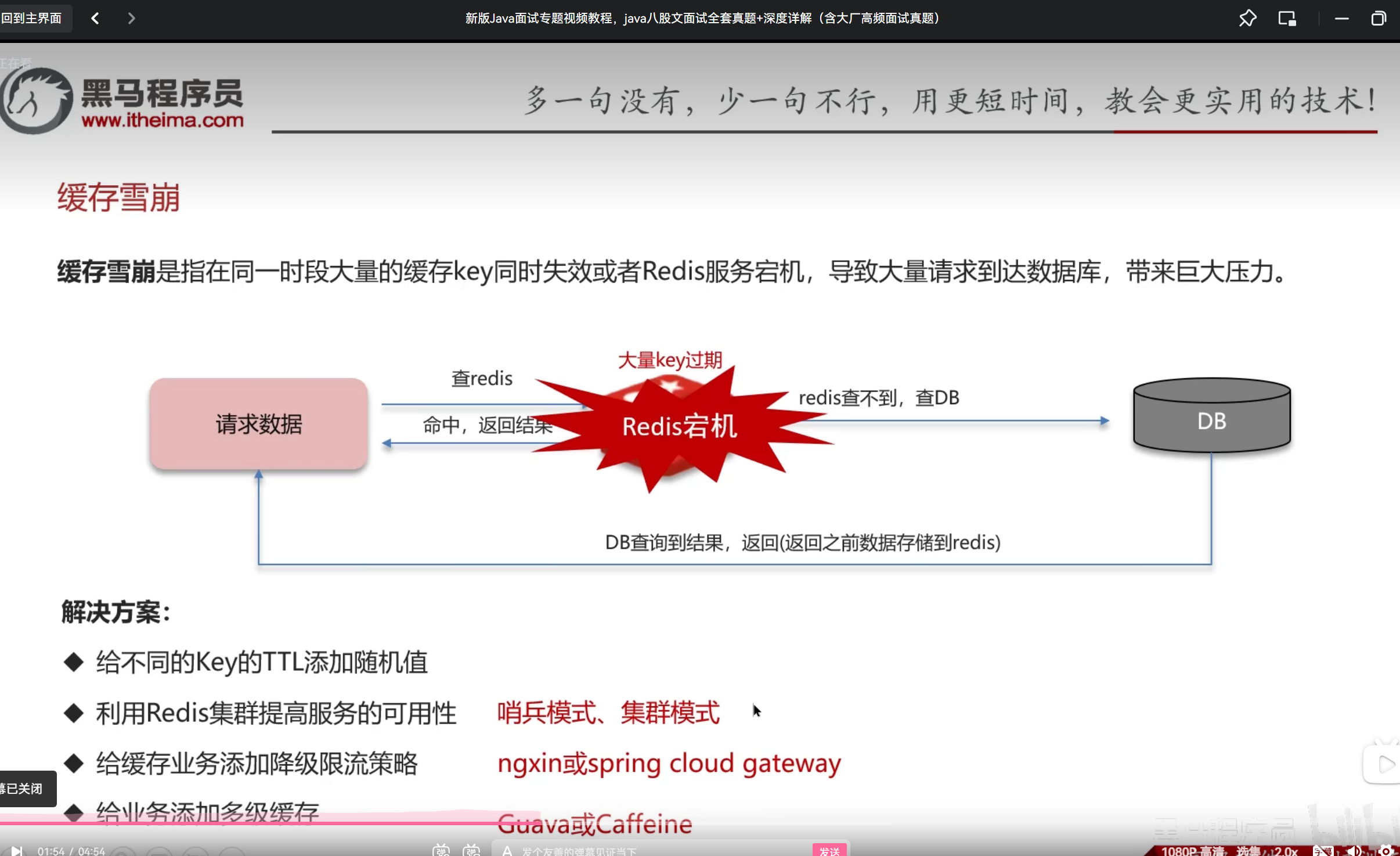
缓存雪崩:在某个时段,设置的key的失效时间都一样,其实也就是大量key在同一时间失效了或者Redis宕机了,从而导致如果这个时间有大量的请求打进来,导致数据库可能存在宕机
微服务等等
多级缓存多级查询,降低极端情况的时间复杂度
Redis集群
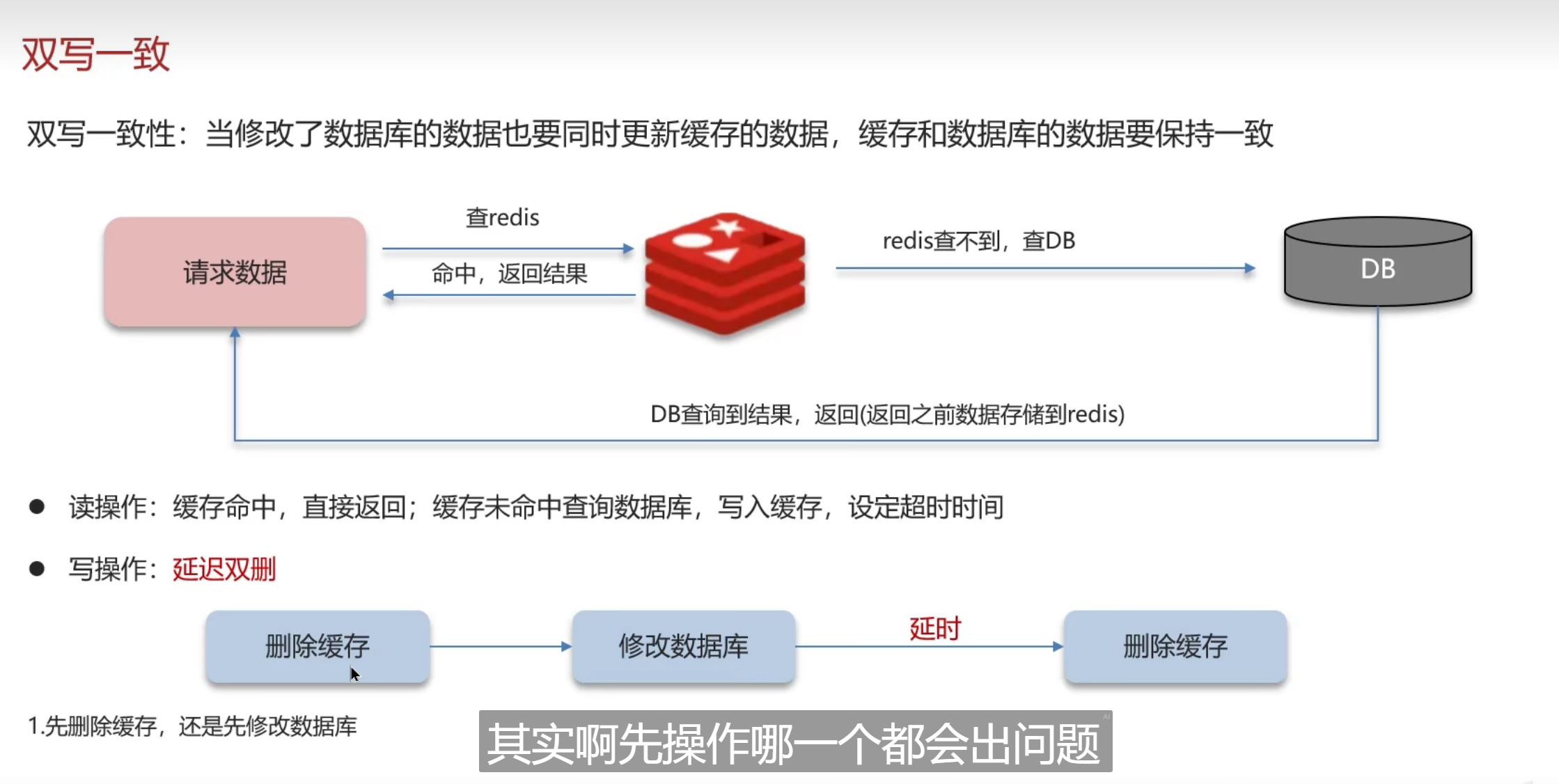
双写一致性
关于双写一致性
mysql读和写与Redis之间的一致性,要具体结合业务方案去进行回答
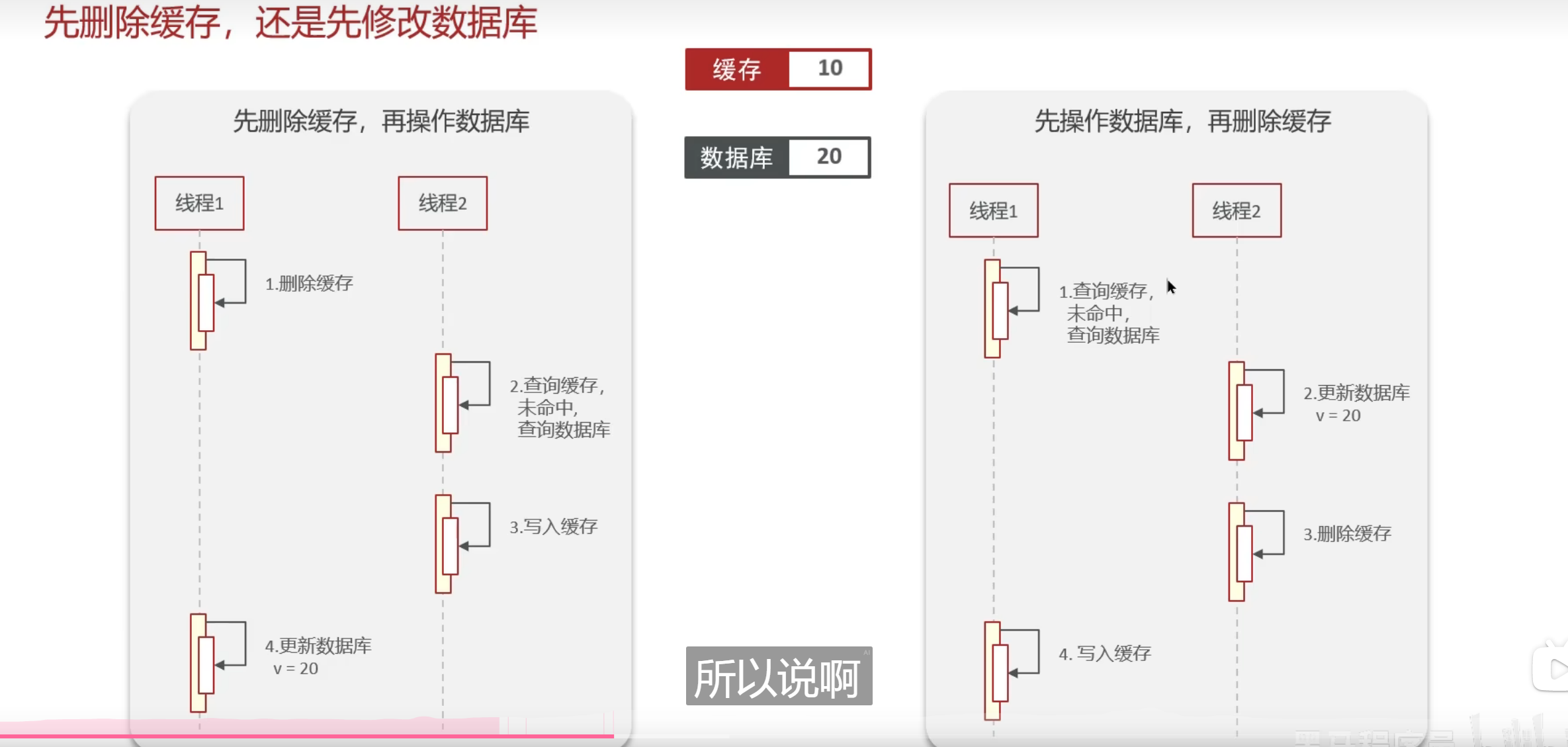
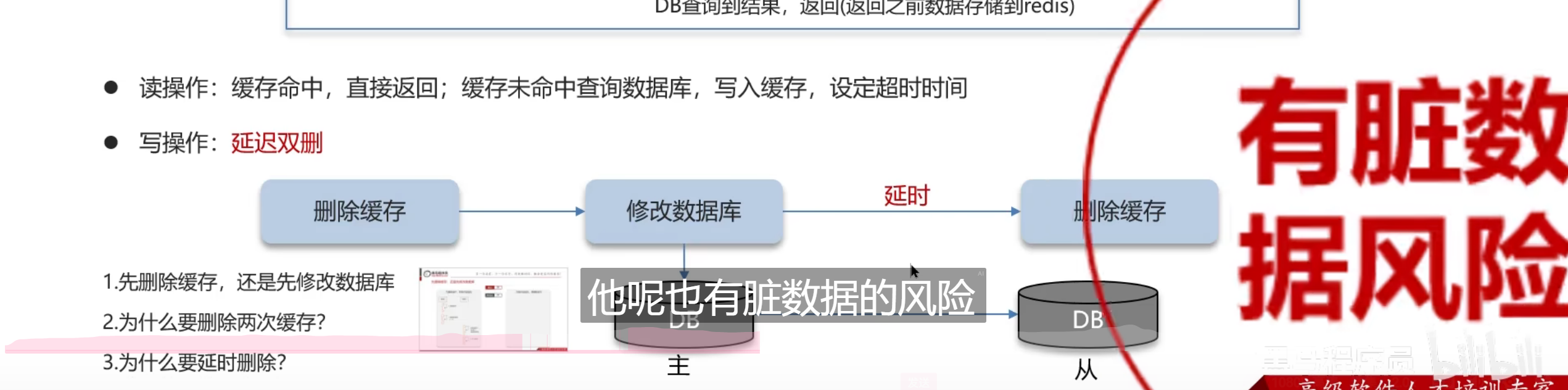
两种有问题的方式
优秀的解决方案一般都是比较中庸的
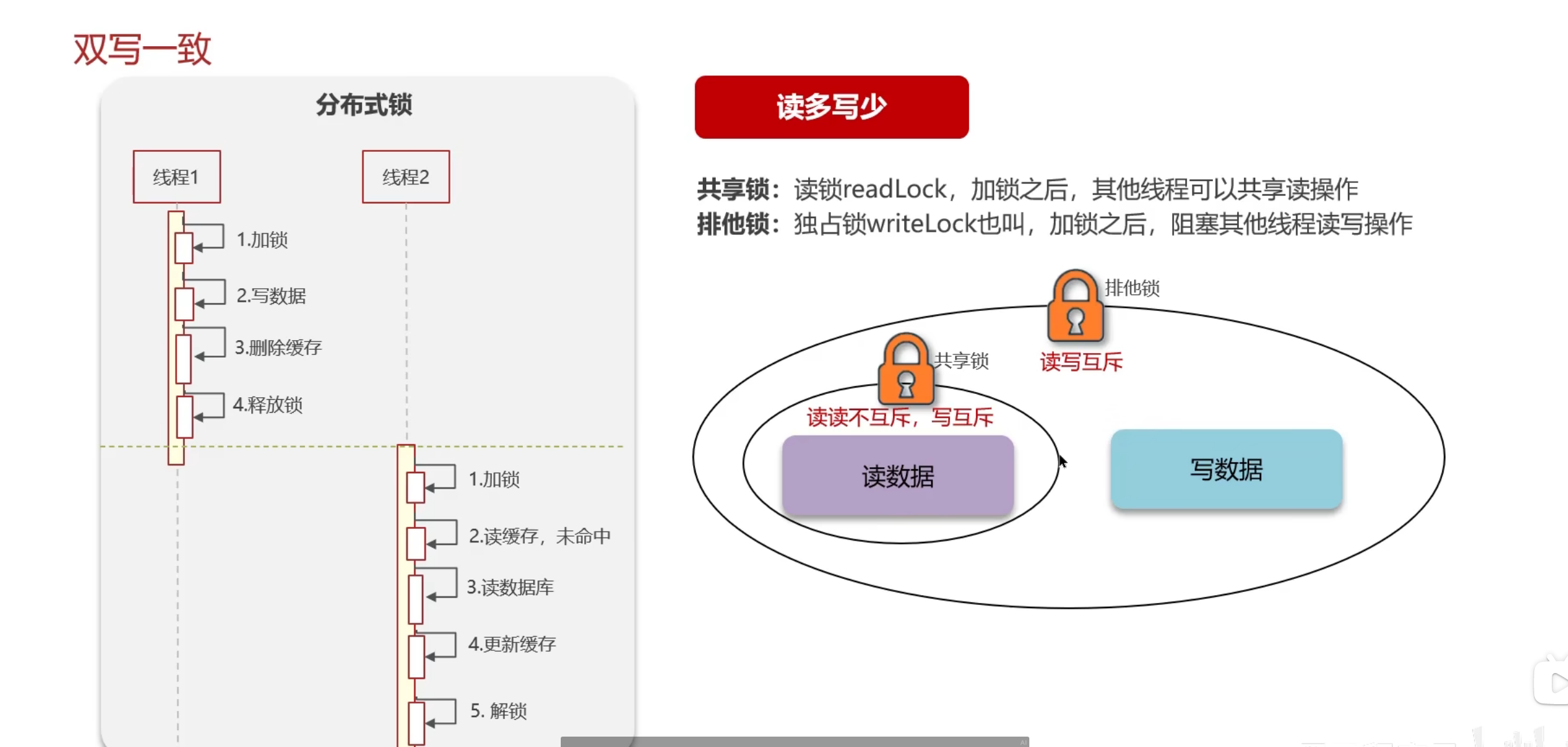
这就是方差的魅力
这个方案必须是强一致性要求的业务解决方案,如果不是强一致性的业务
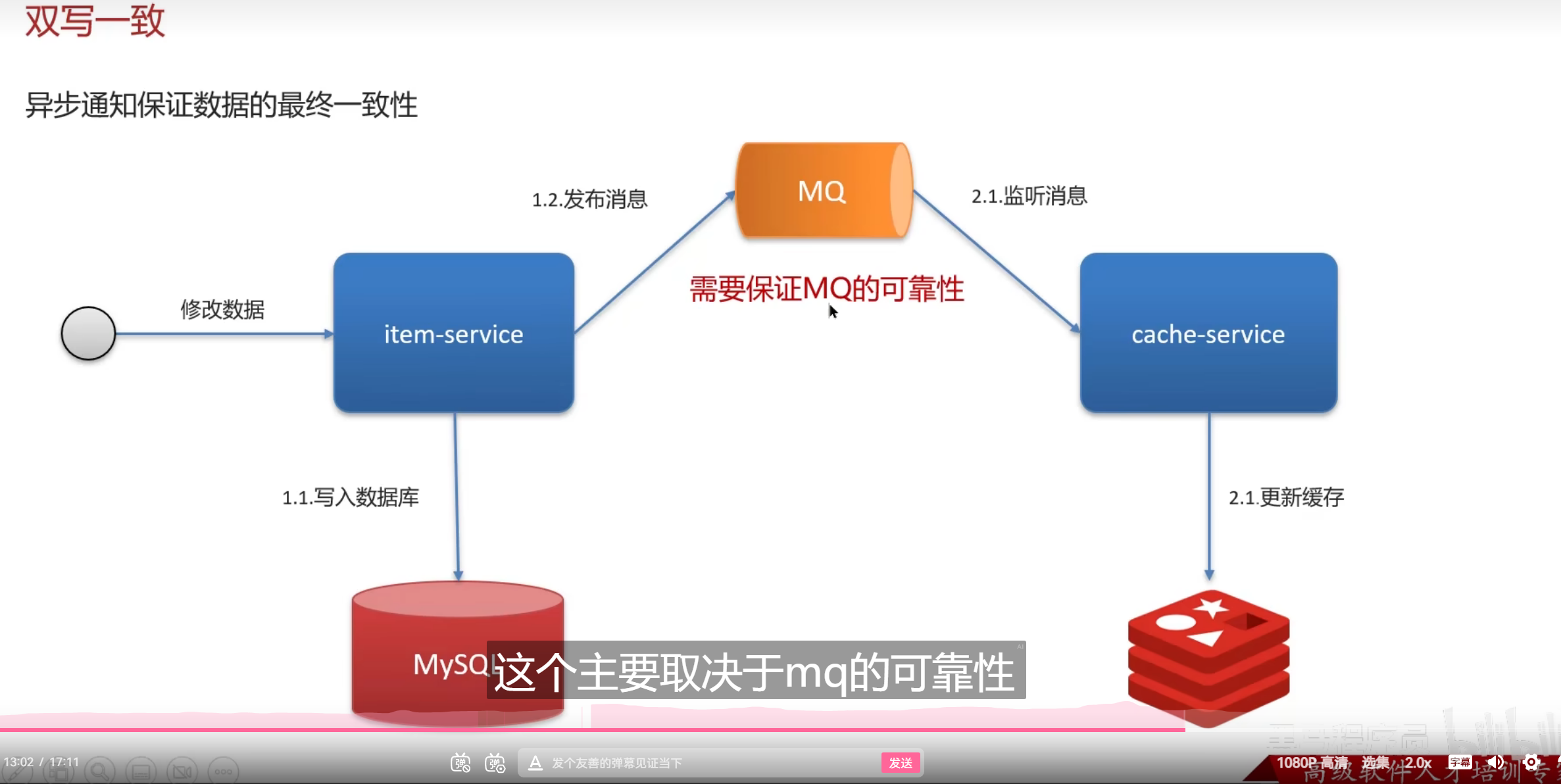
这个就是MQ的
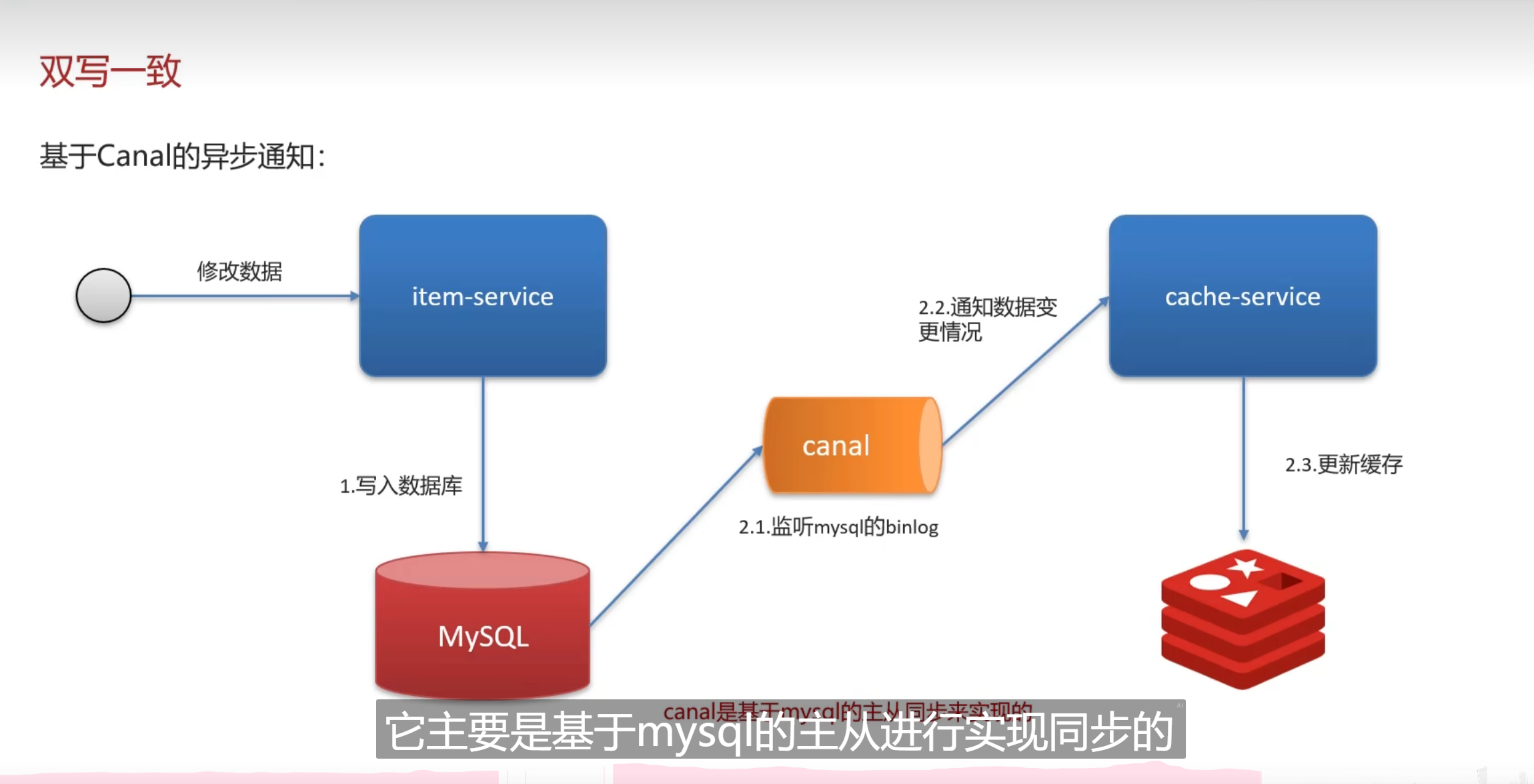
本质上都差不多的解决方案都是通过异步,连接,同时去通知就行
有点类似于包装成一个事务

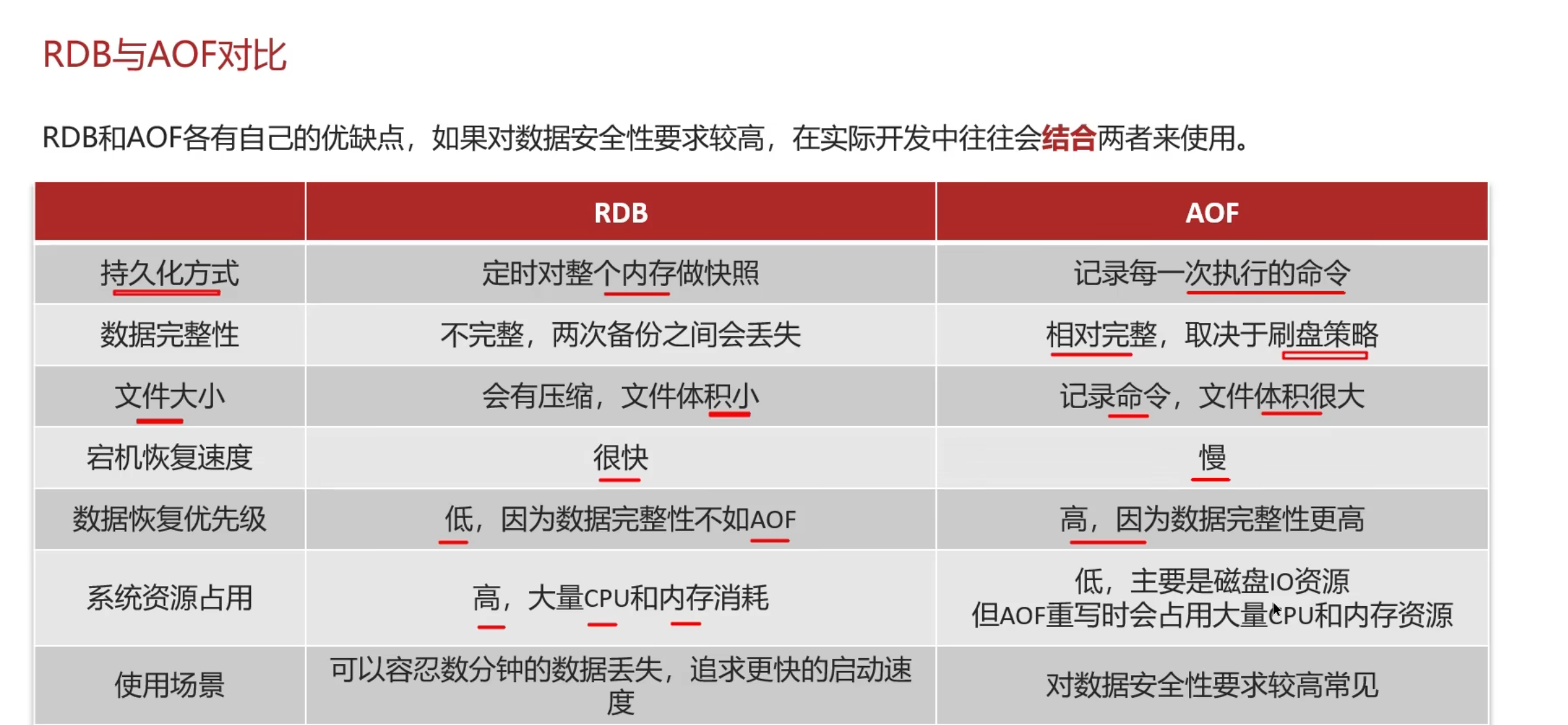
Redis持久化
1.RDB
数据快照
数据恢复
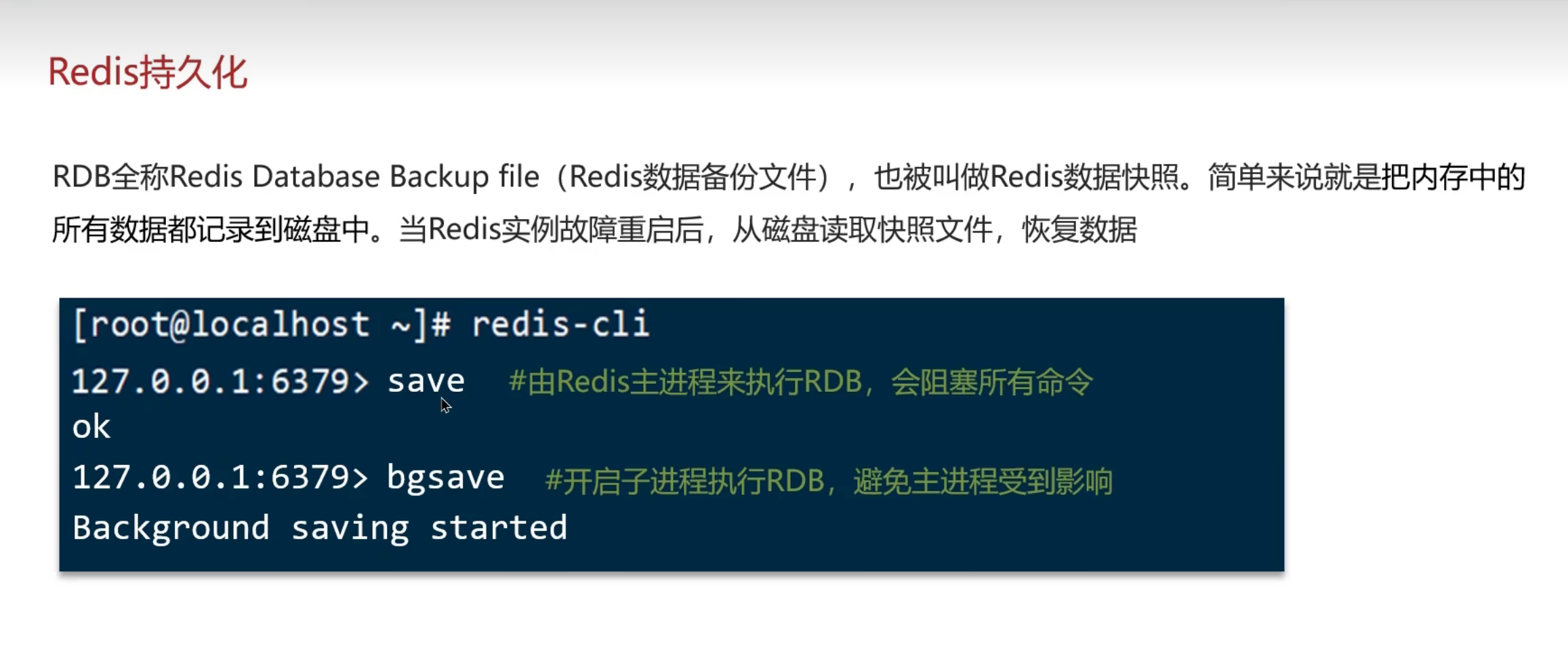
一般是哦你bgsave
当然前面用了save
Redis内部有RDB触发条件方案在redis.conf里面配置文件

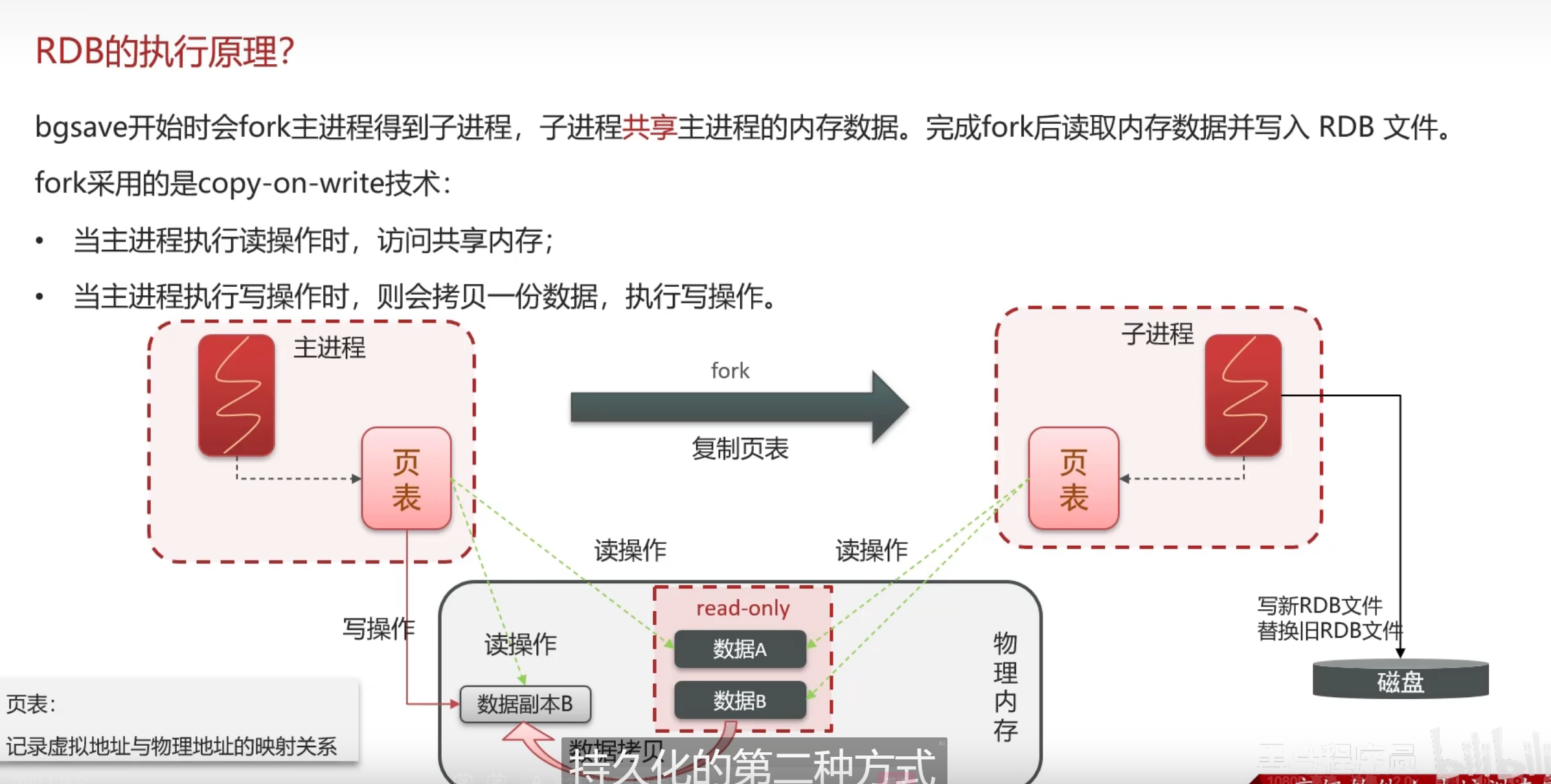
这个学深入了总算
2.AOF
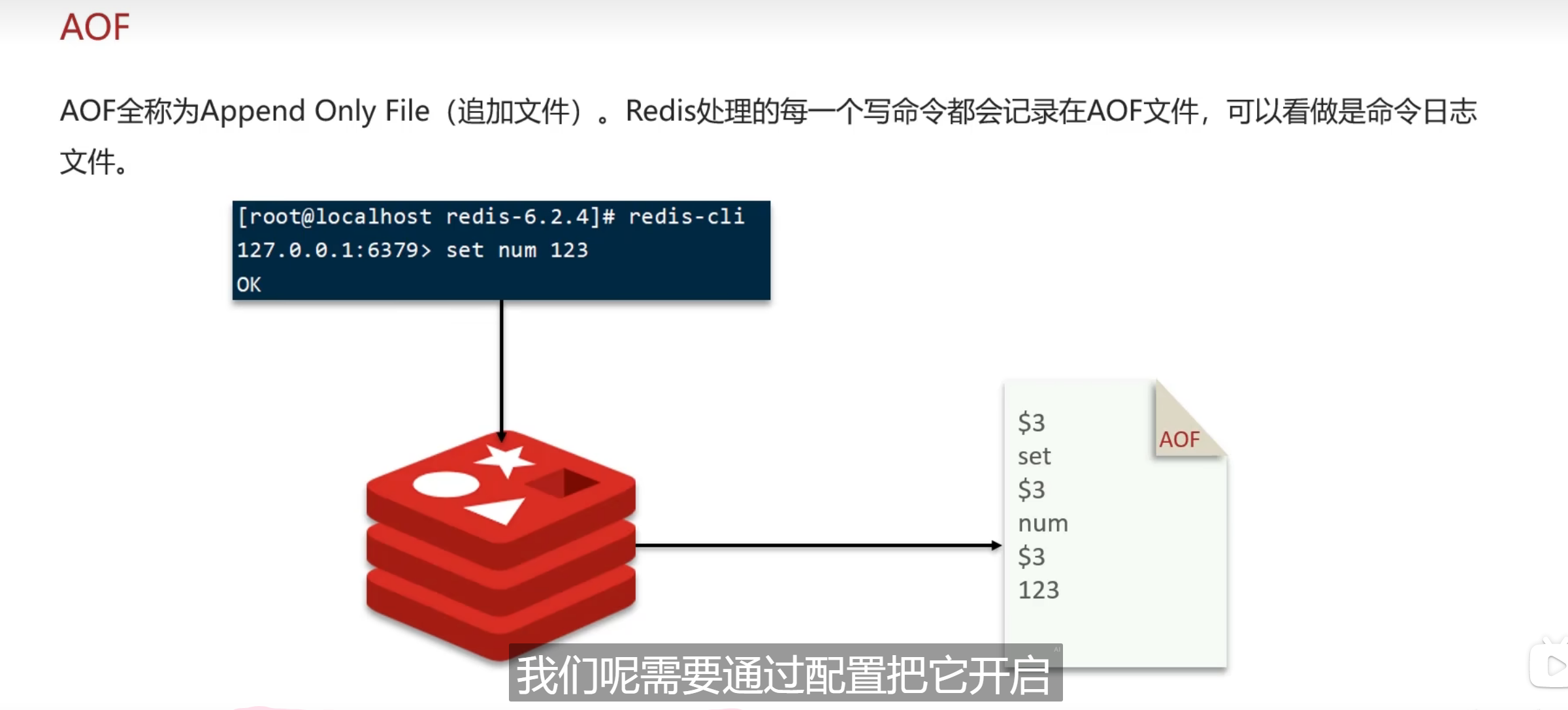
有点像日志
默认关闭
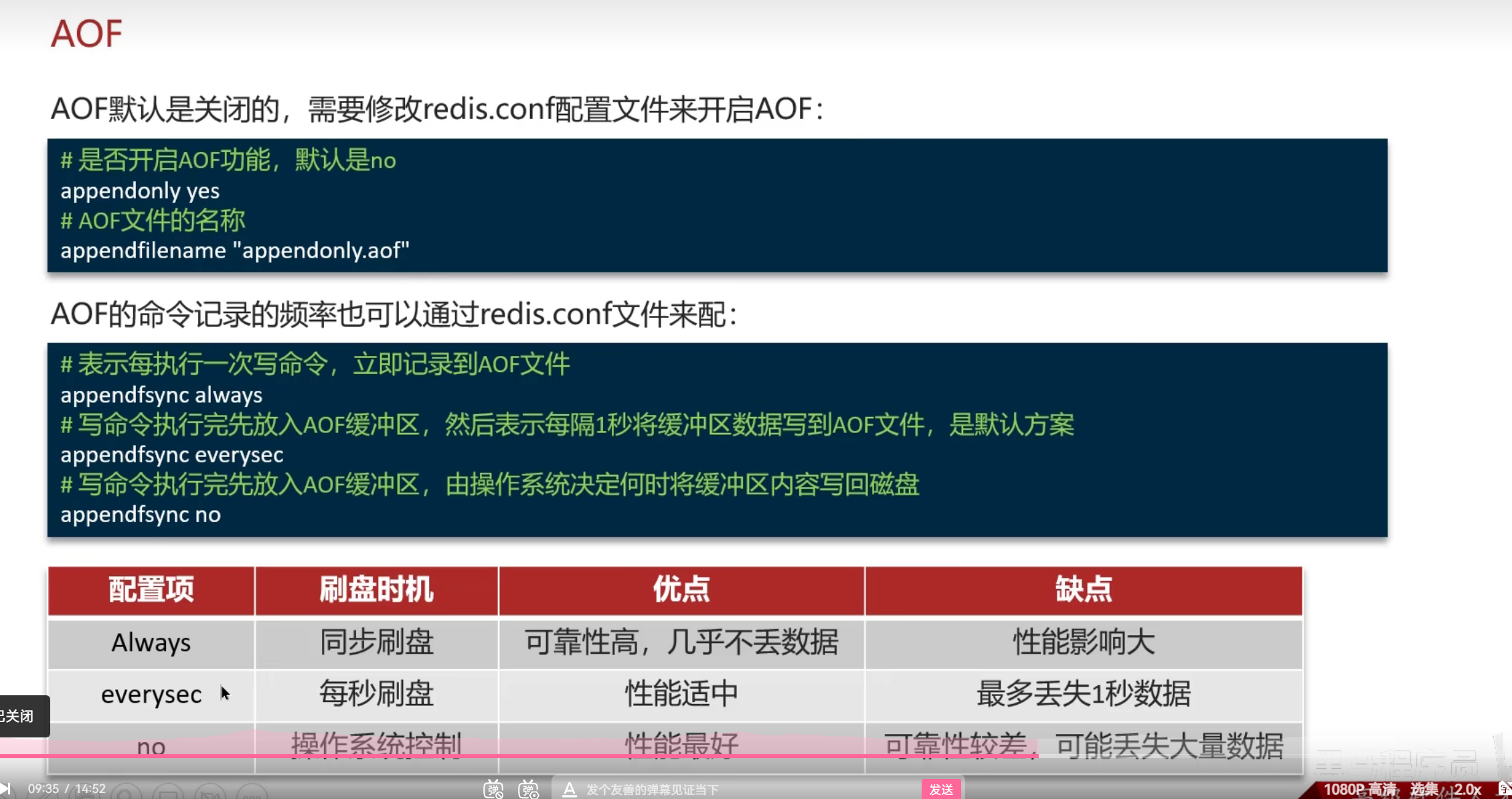
刷新的时候需要控制频率根据业务
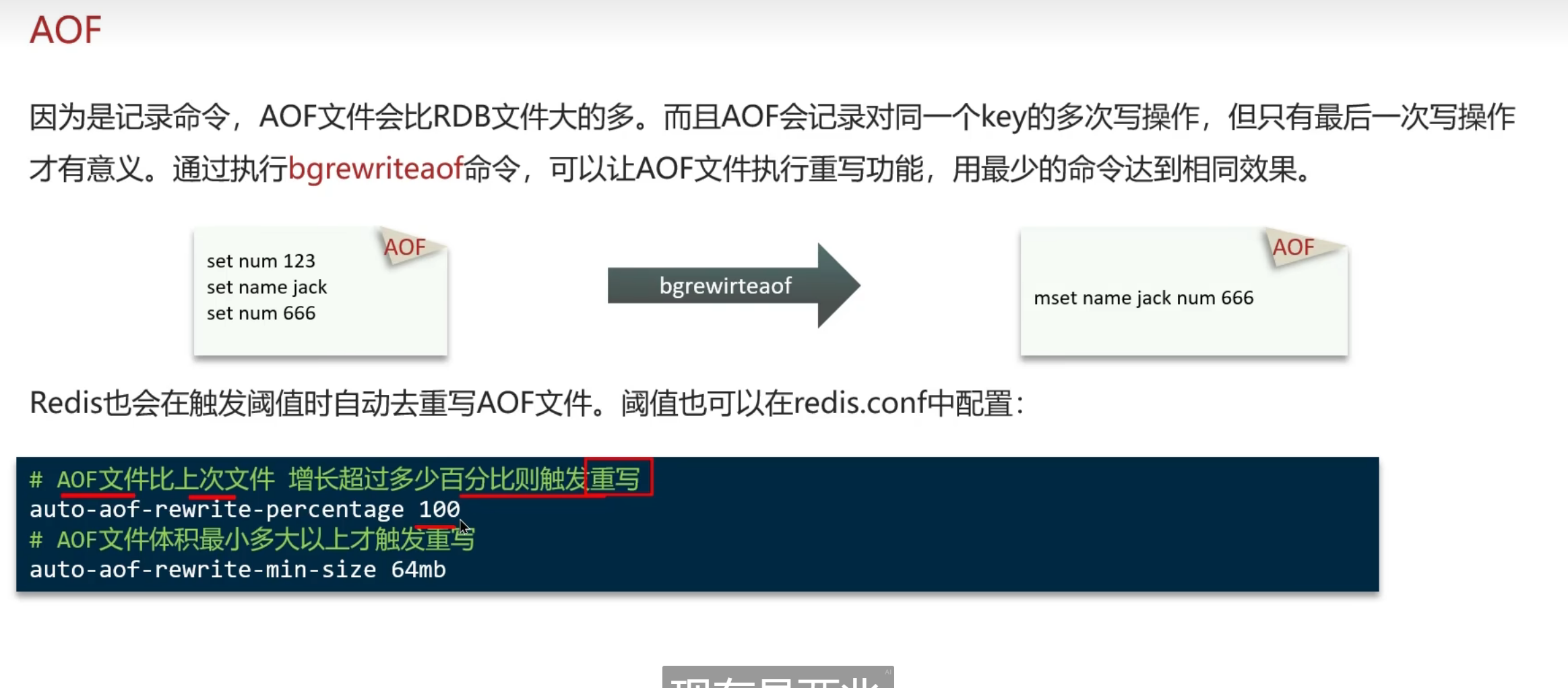
AOF的重写功能
Redis数据过期策略
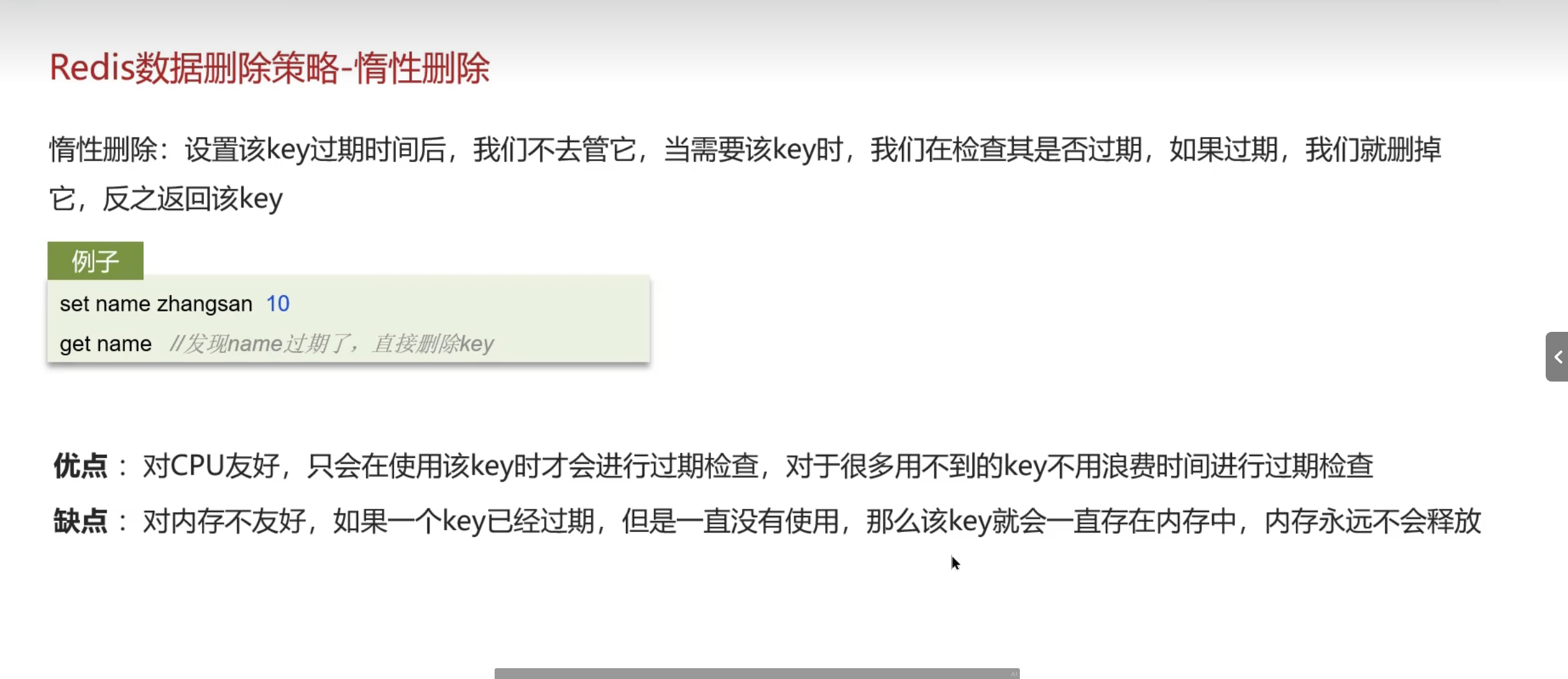
永远都是空间换时间
时间换空间

最终业务方案一般是两种一起结合来进行使用
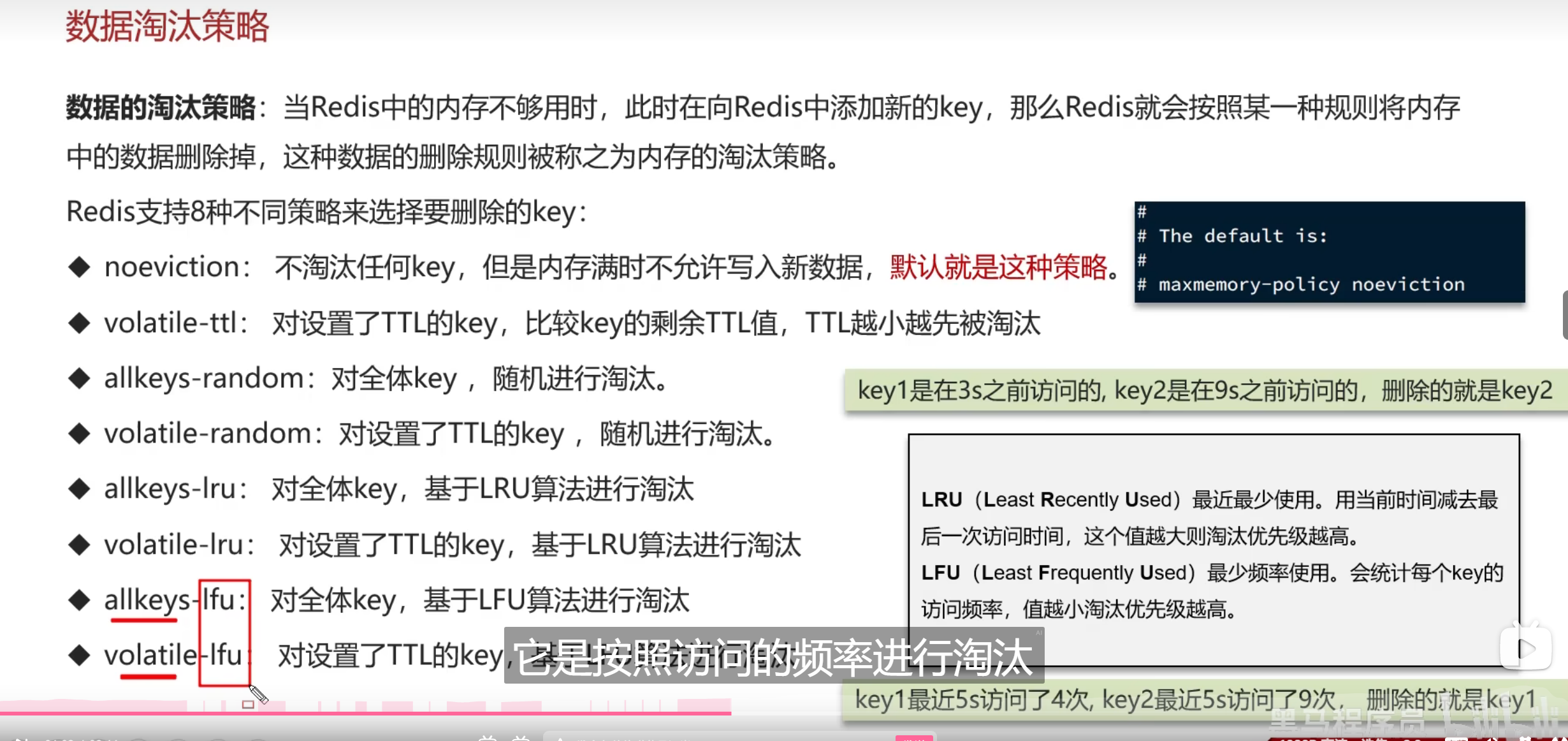
数据淘汰策略

Redis中主要用了八种这样的策略

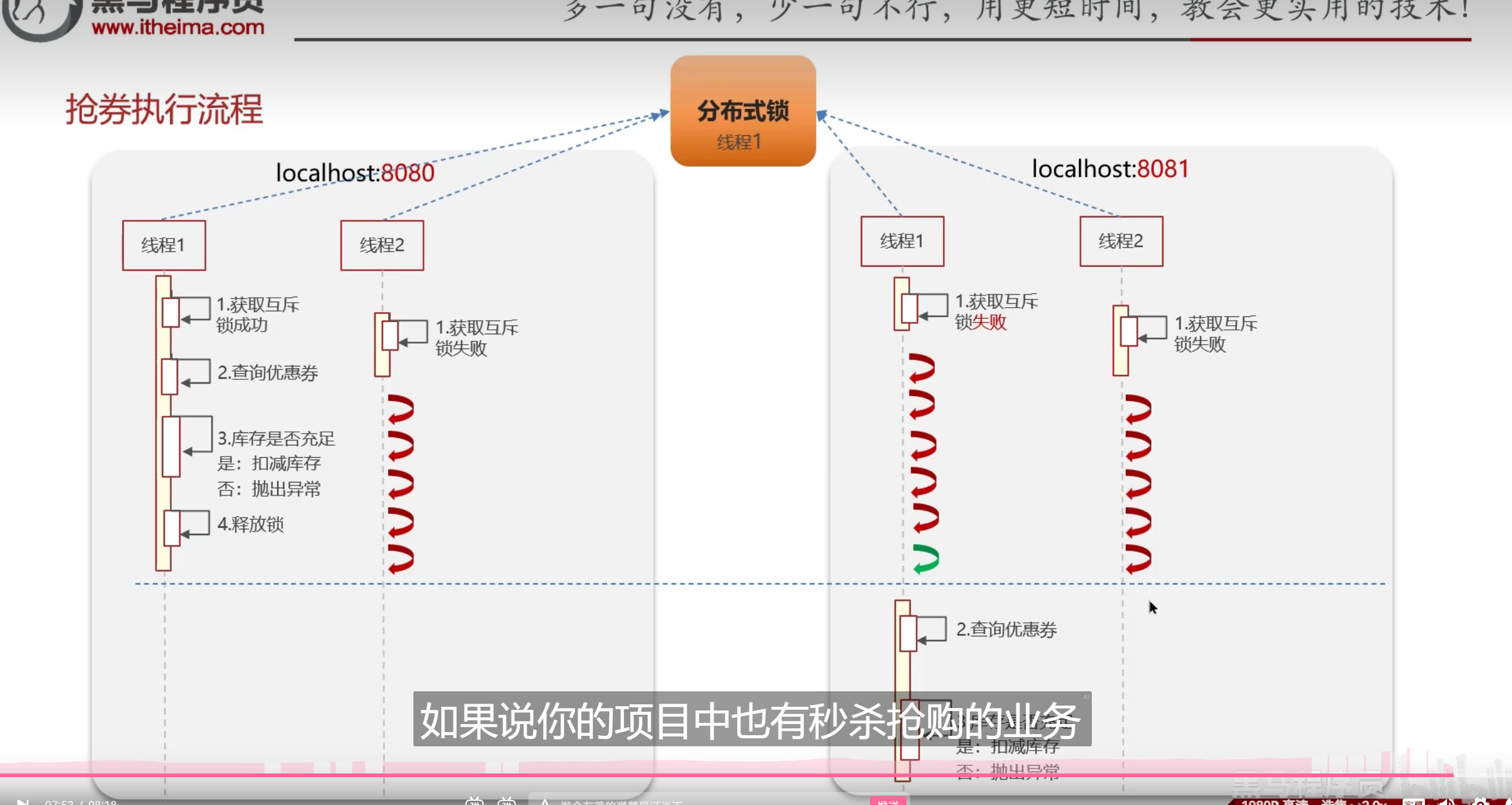
分布式锁

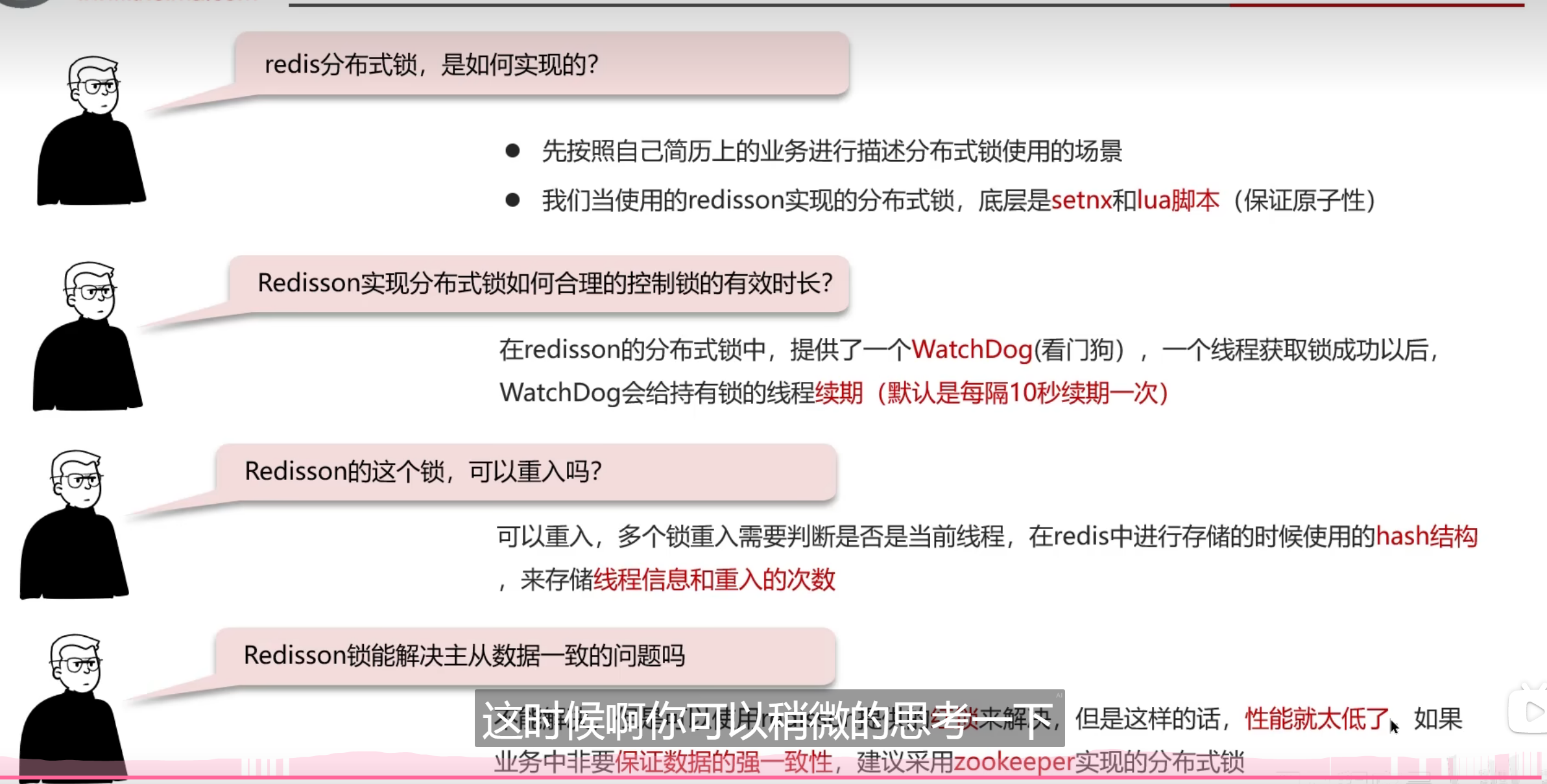
什么是分布式锁呢
这个概念我还真不太清楚
使用场景
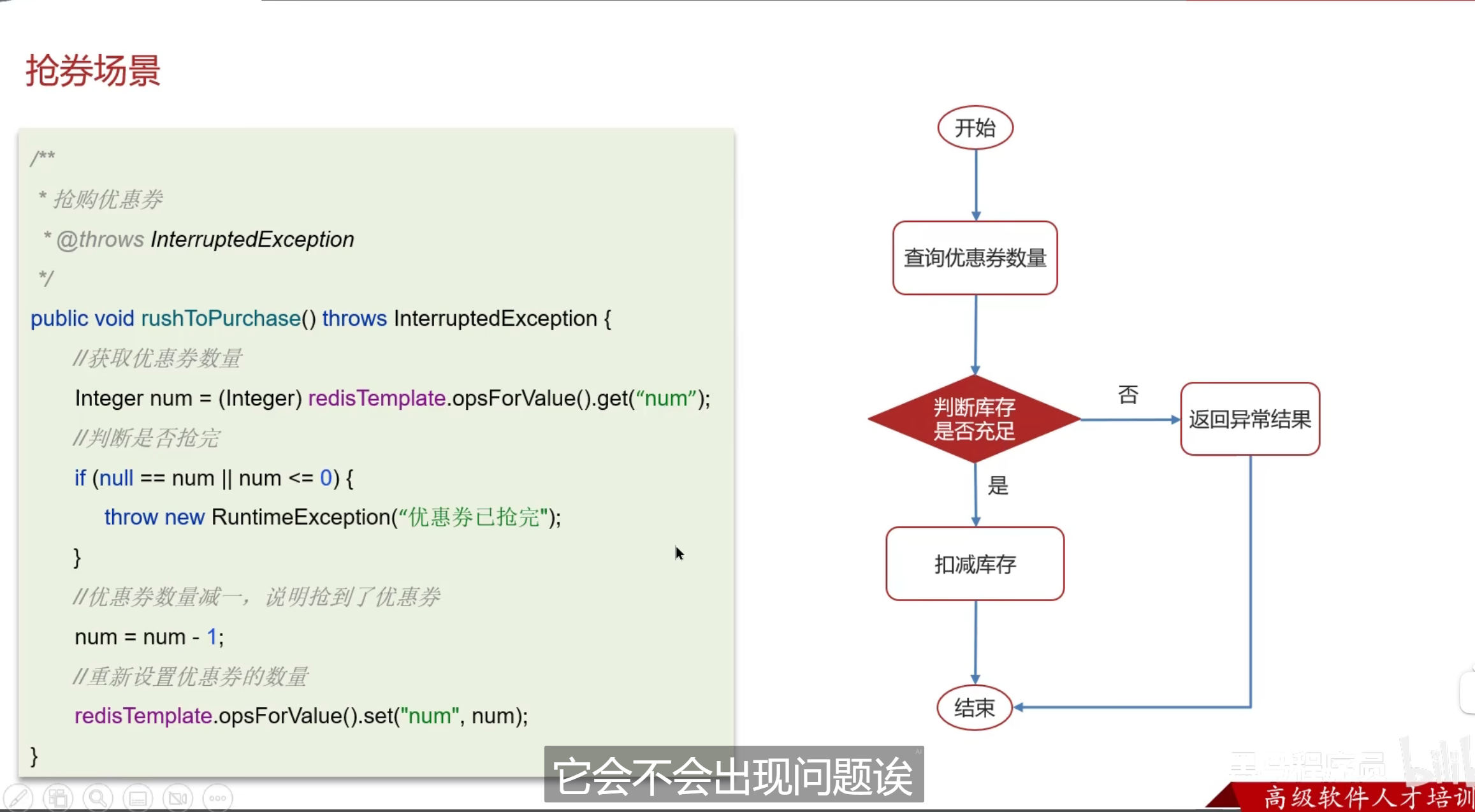
方案
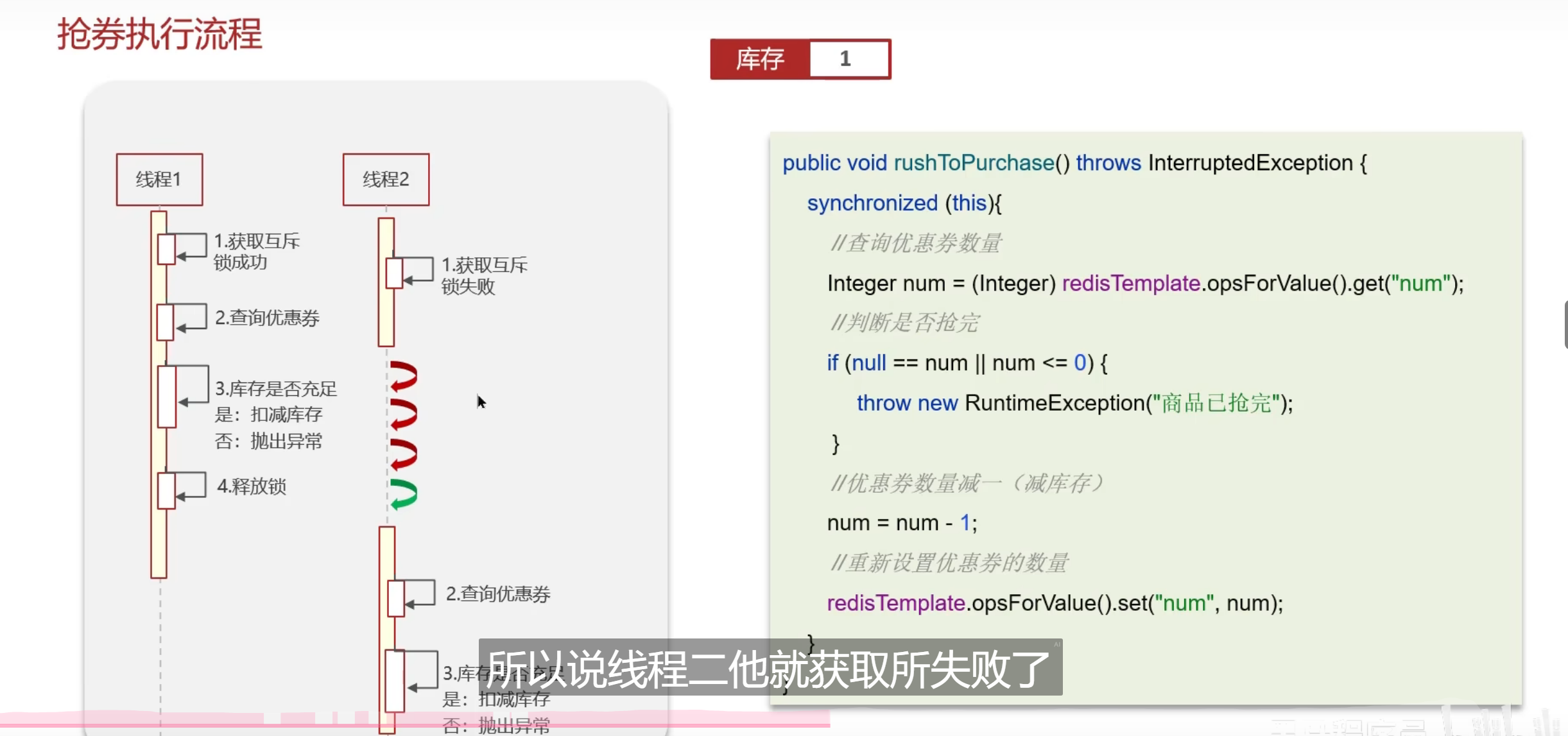
加锁我觉得太蠢了
性能太低了
我觉得要去对某个临近没有的值去进行限制
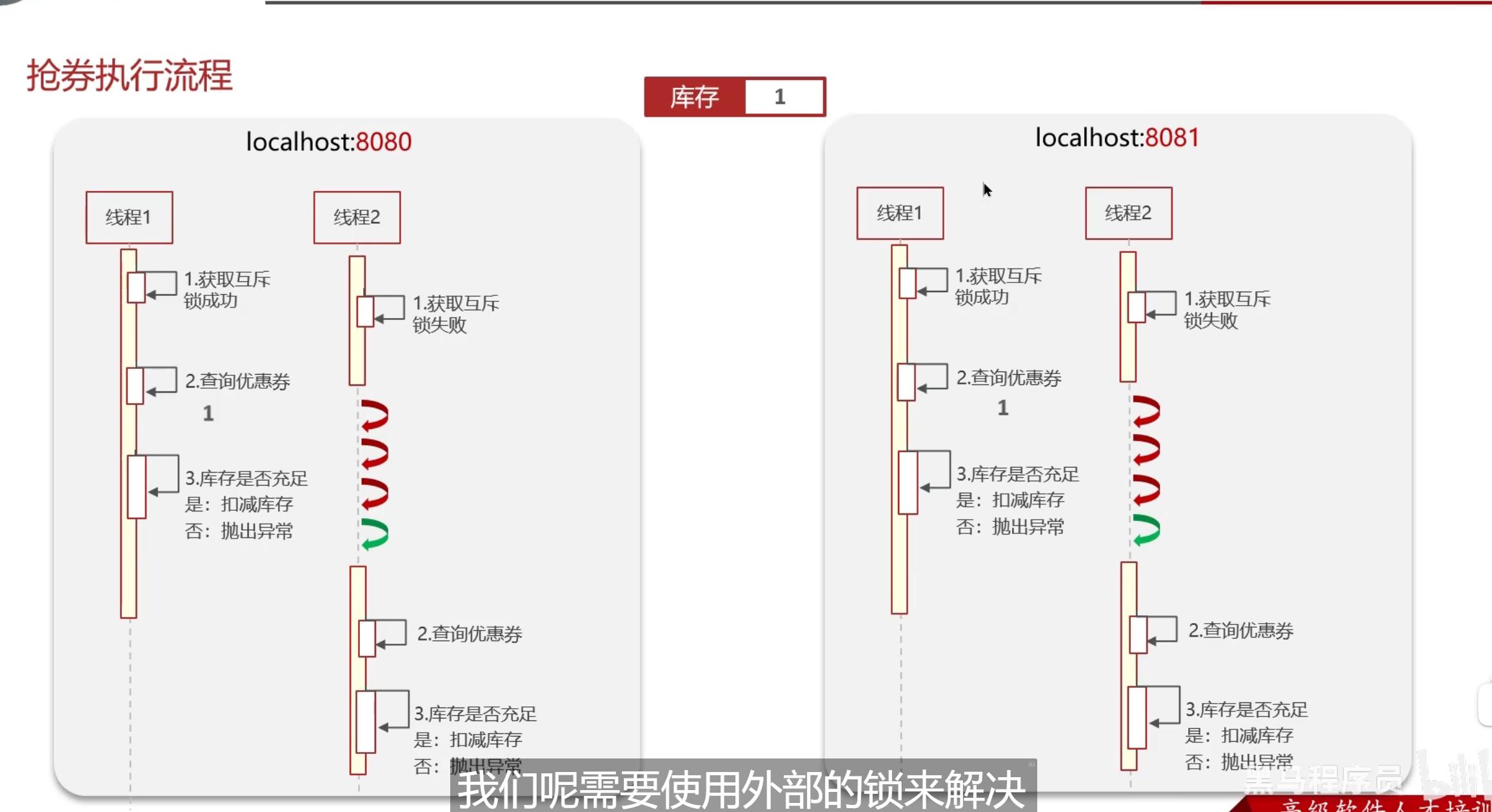
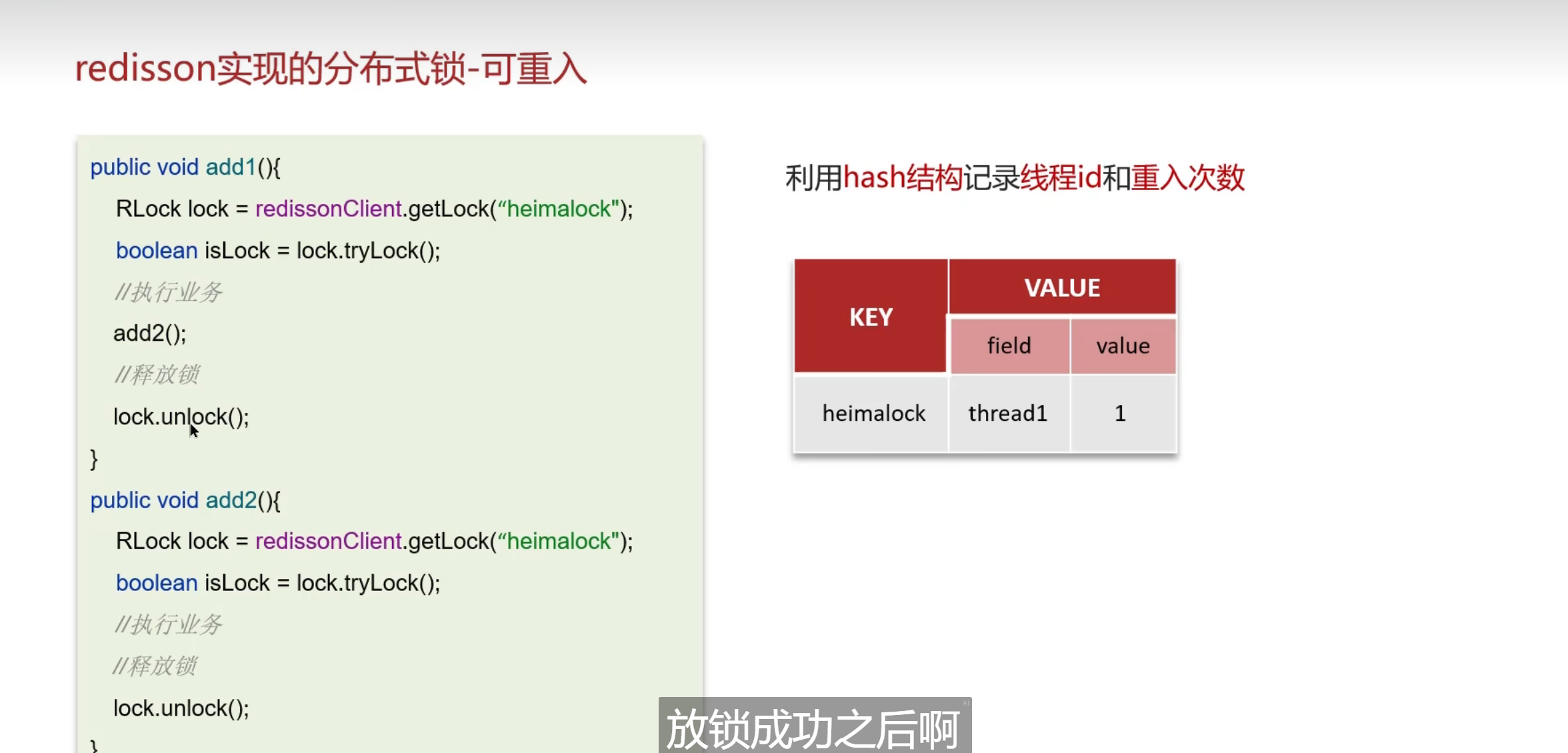
这里的锁还有几个关键,因为这种业务分布比较广,可能会到多个服务器后端去进行处理,单独给一个地方加锁是不能够去让业务成功的
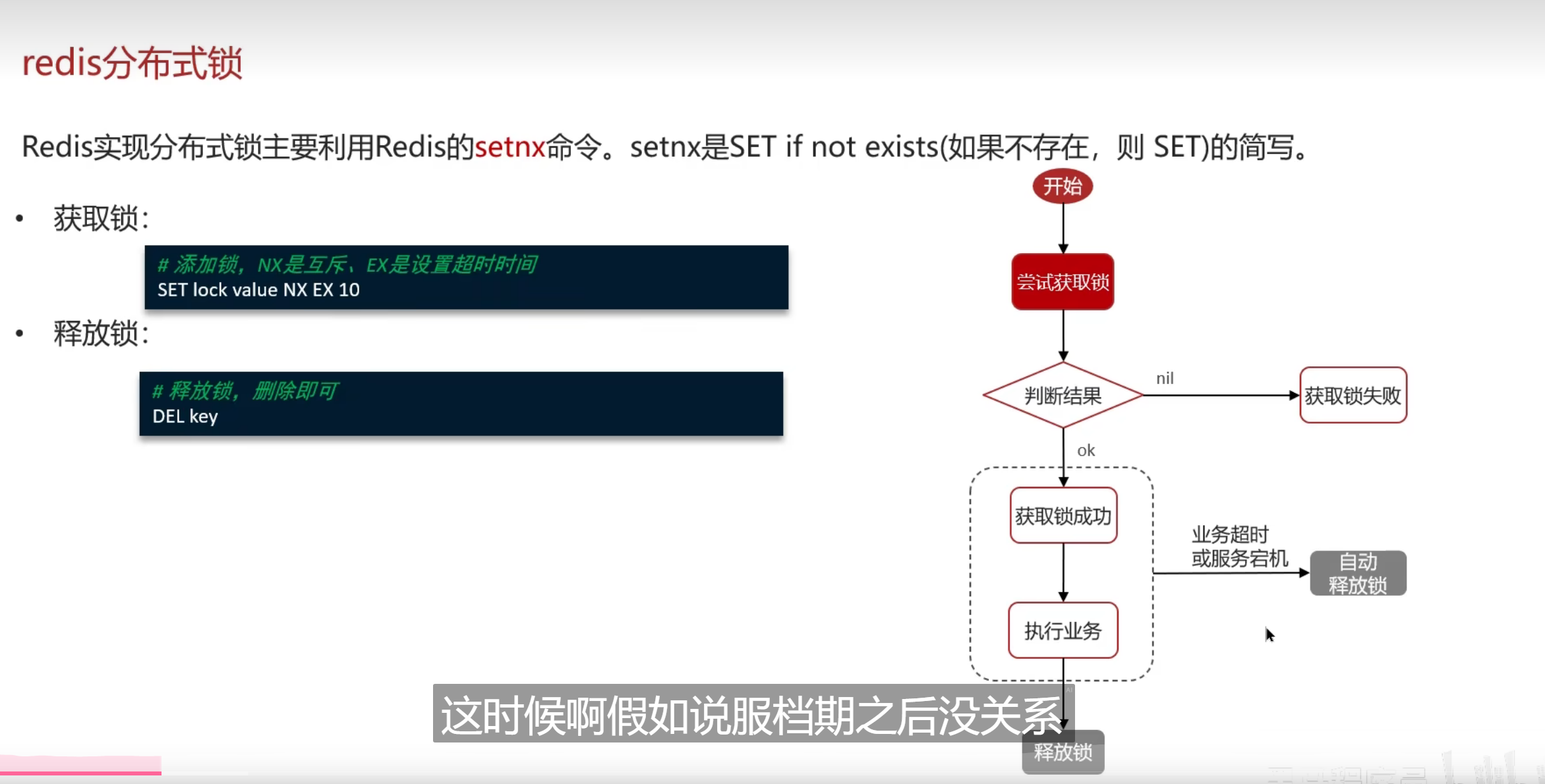
setnx命令
之所以要去设置超时时间,是为了去防止死锁的问题,而且
大多数命令执行需要时间是不会多少的,我们只需要去进行一下基本的操作

给锁续期
redission分布式锁区续期
Watch dog的续期呢
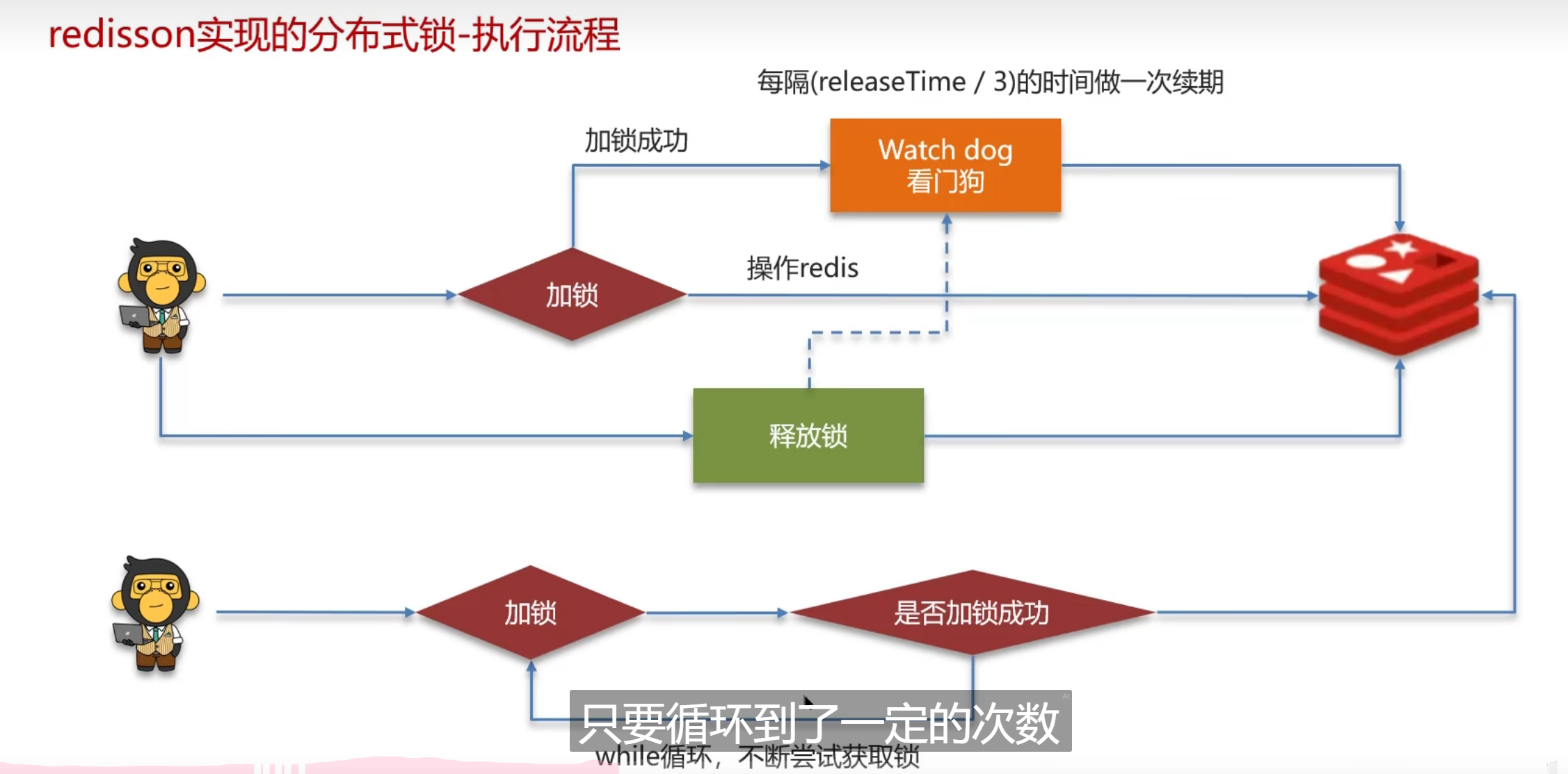
在高并发情况下去增加性能
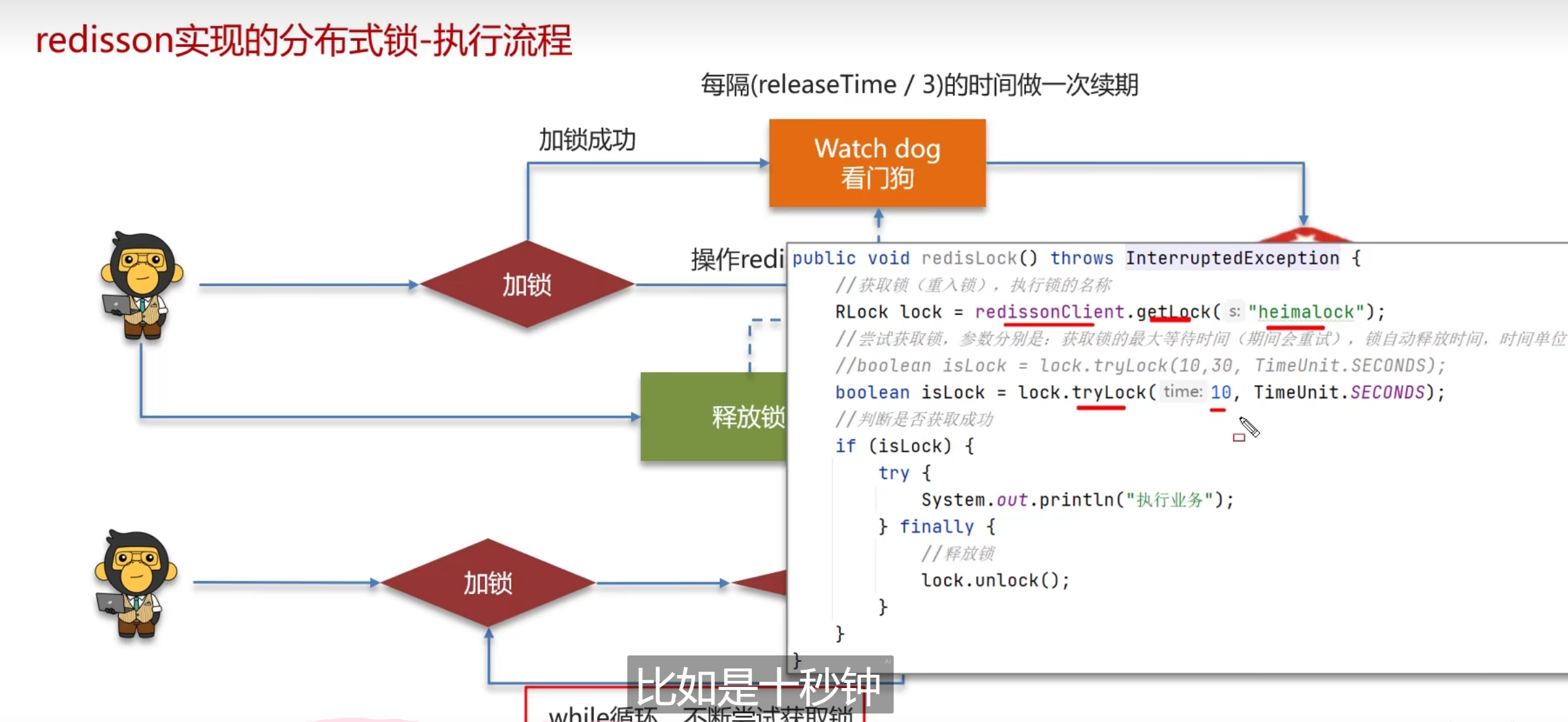
加锁基本都通过lua去执行,保证原子性
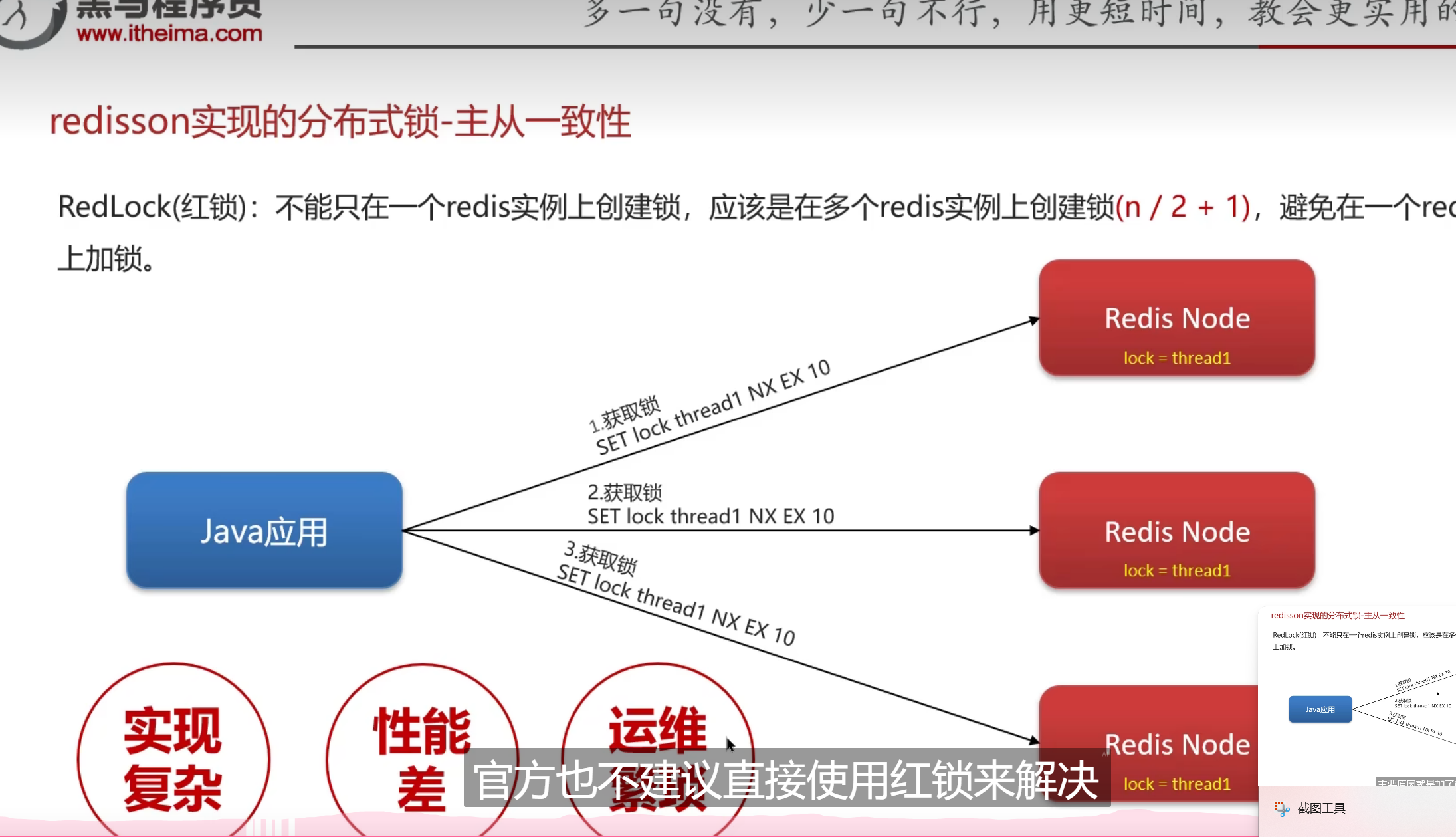
主从集群
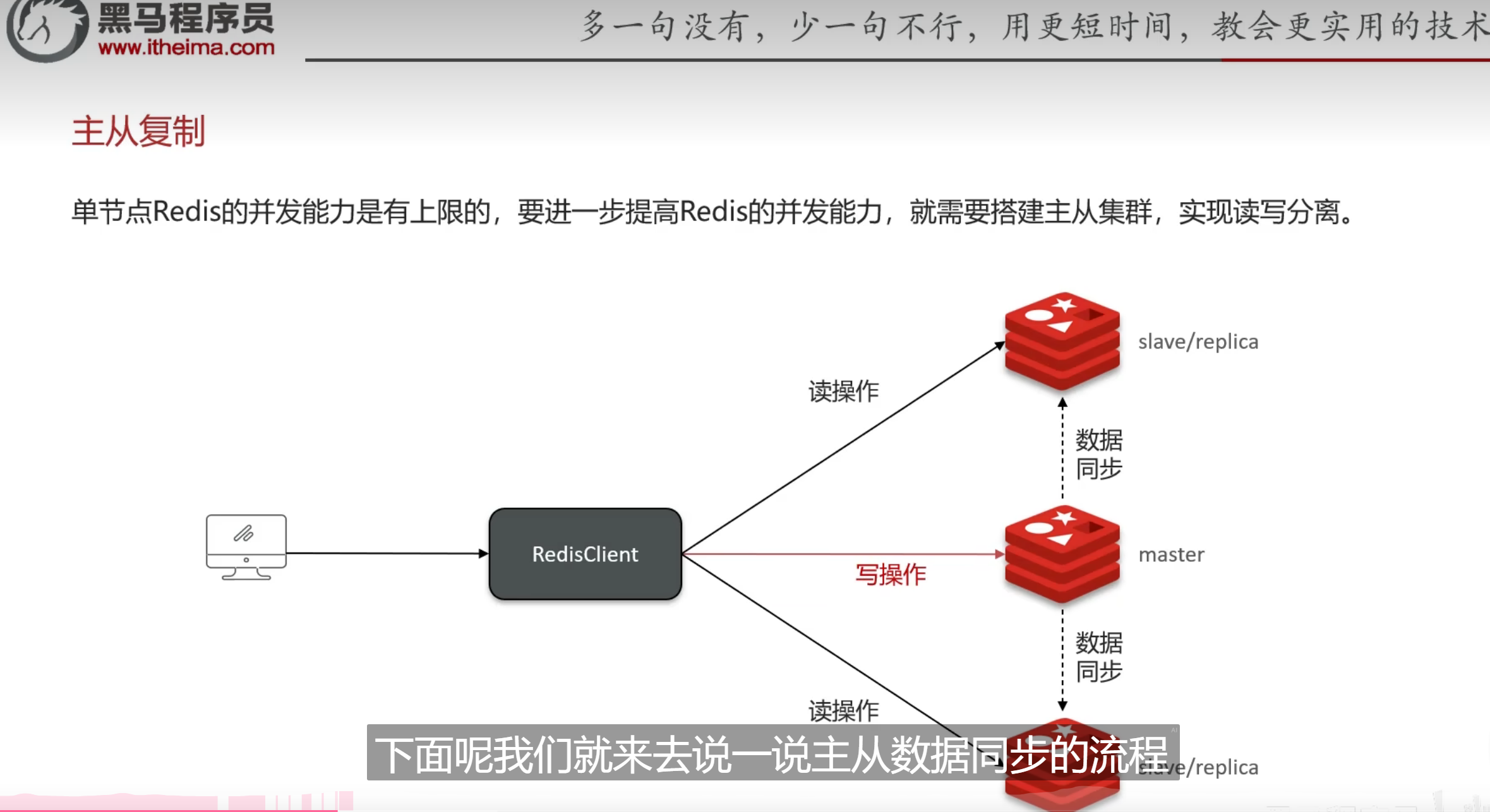
关于主从集群这个,其实云计算里面也有不少这方面的内容
主从集群有两个同步方案
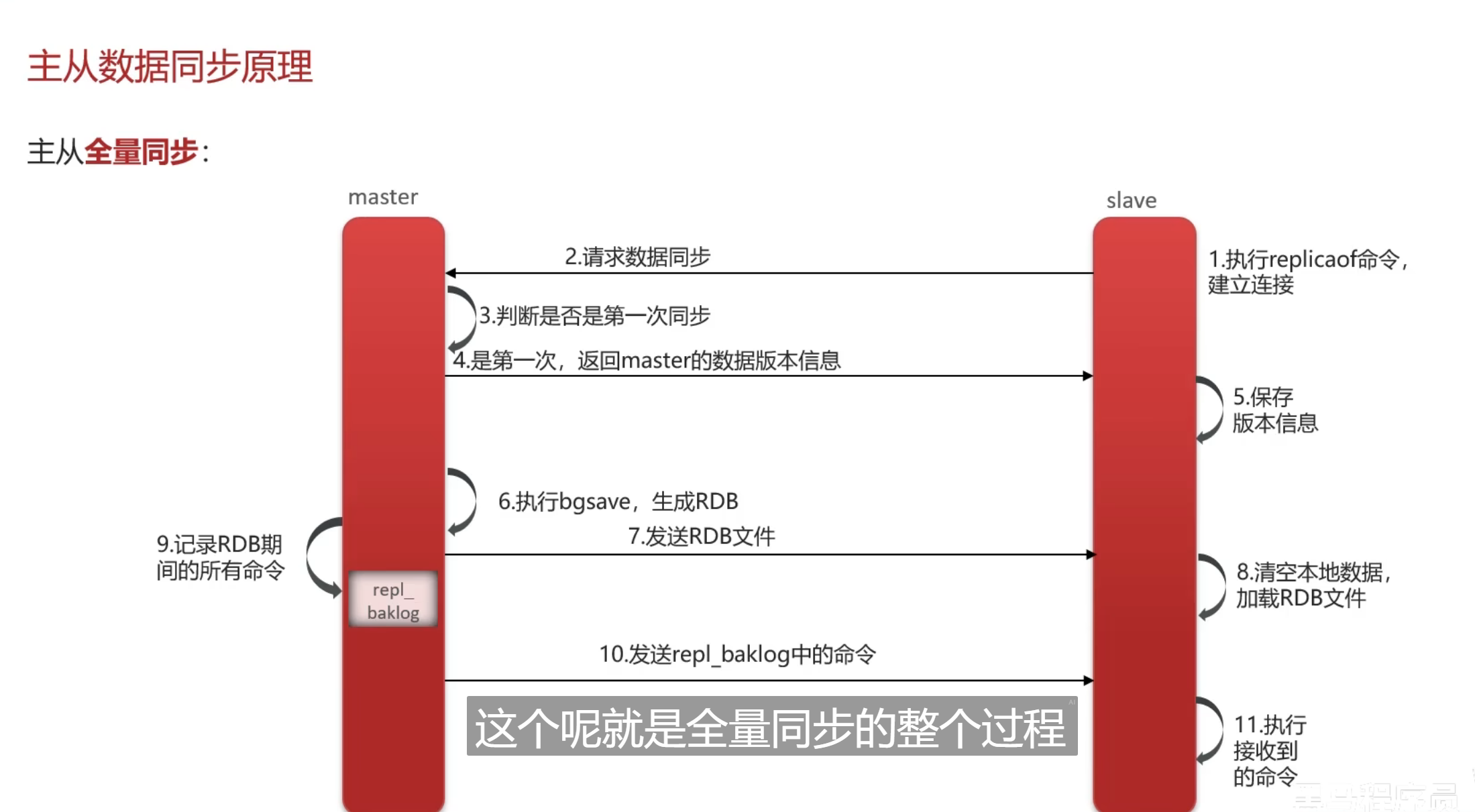
全量同步
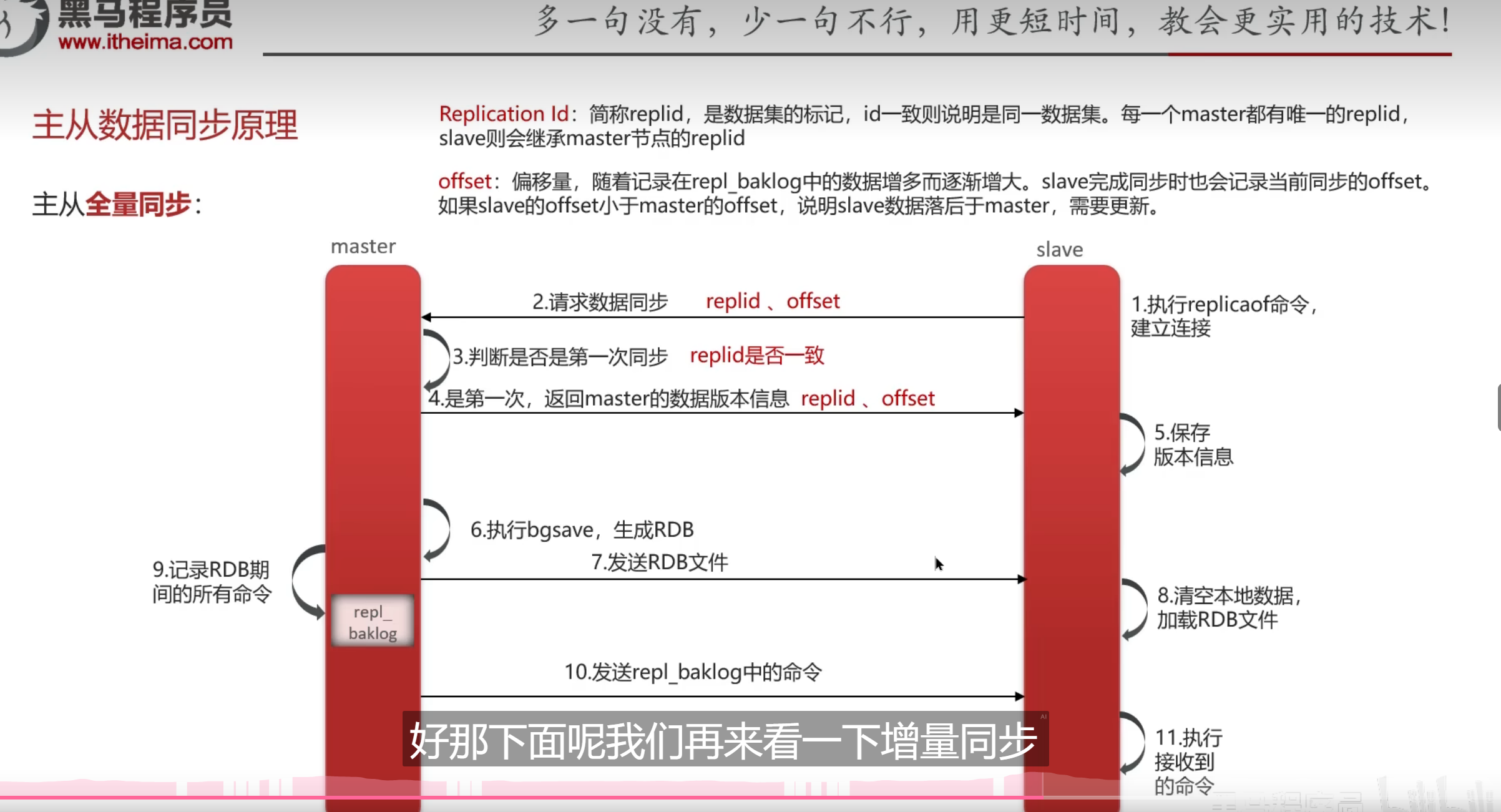
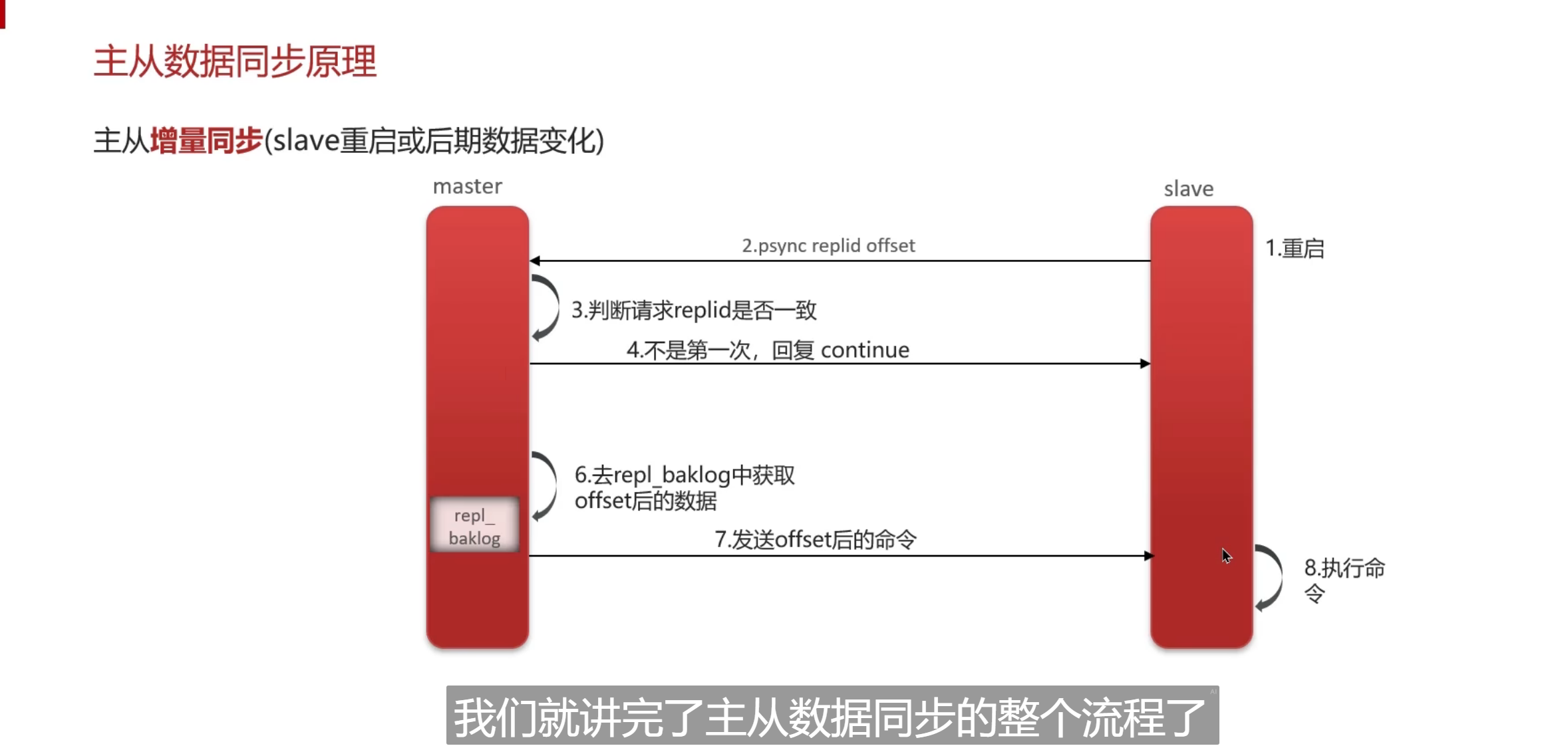
先全量后增量,我估摸着是这样

哨兵模式
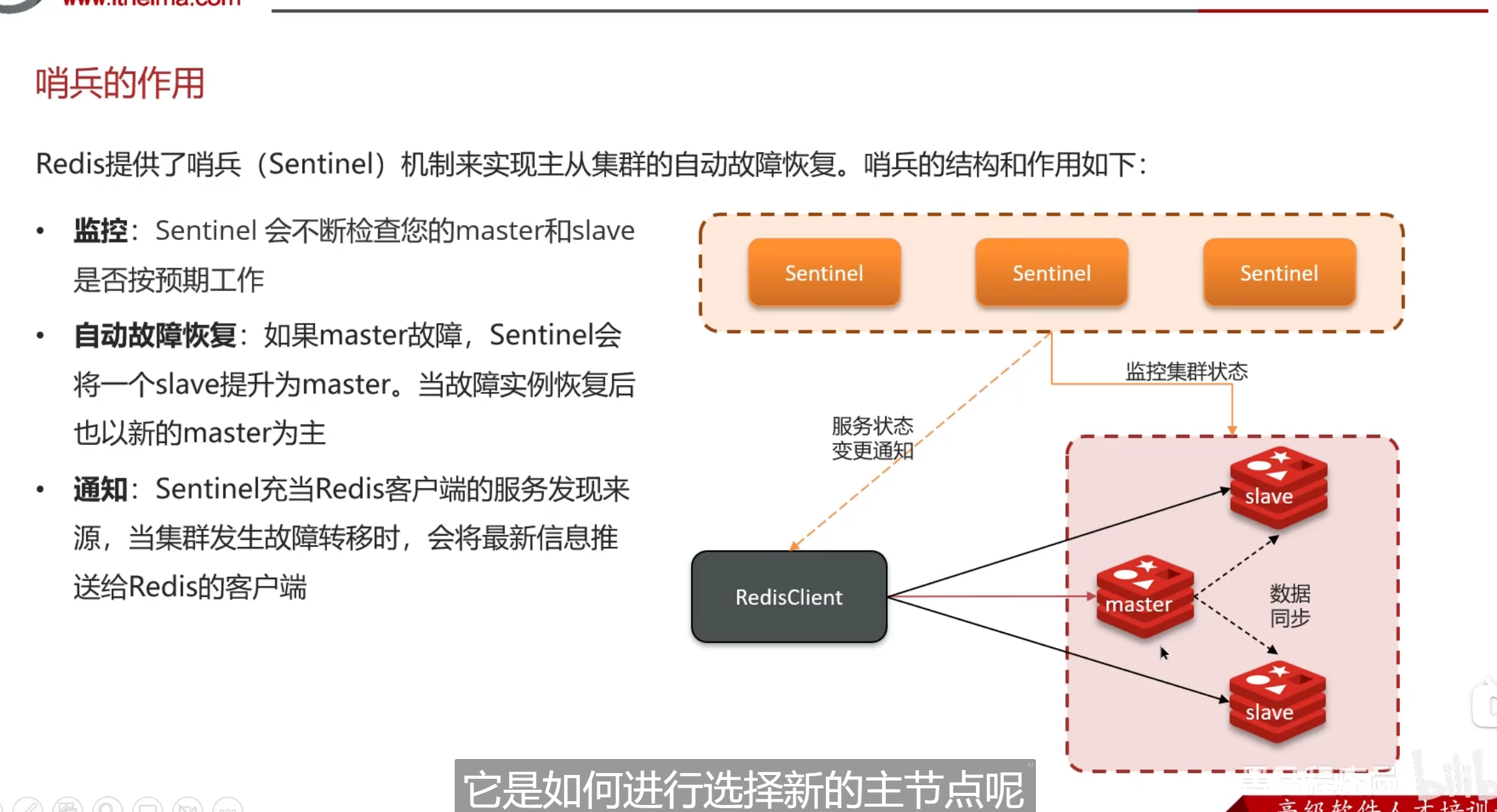 哨兵就是主从的一个监控
哨兵就是主从的一个监控

越接近原本正常状态越好
优先级设置,选主
主观下线和客观下线
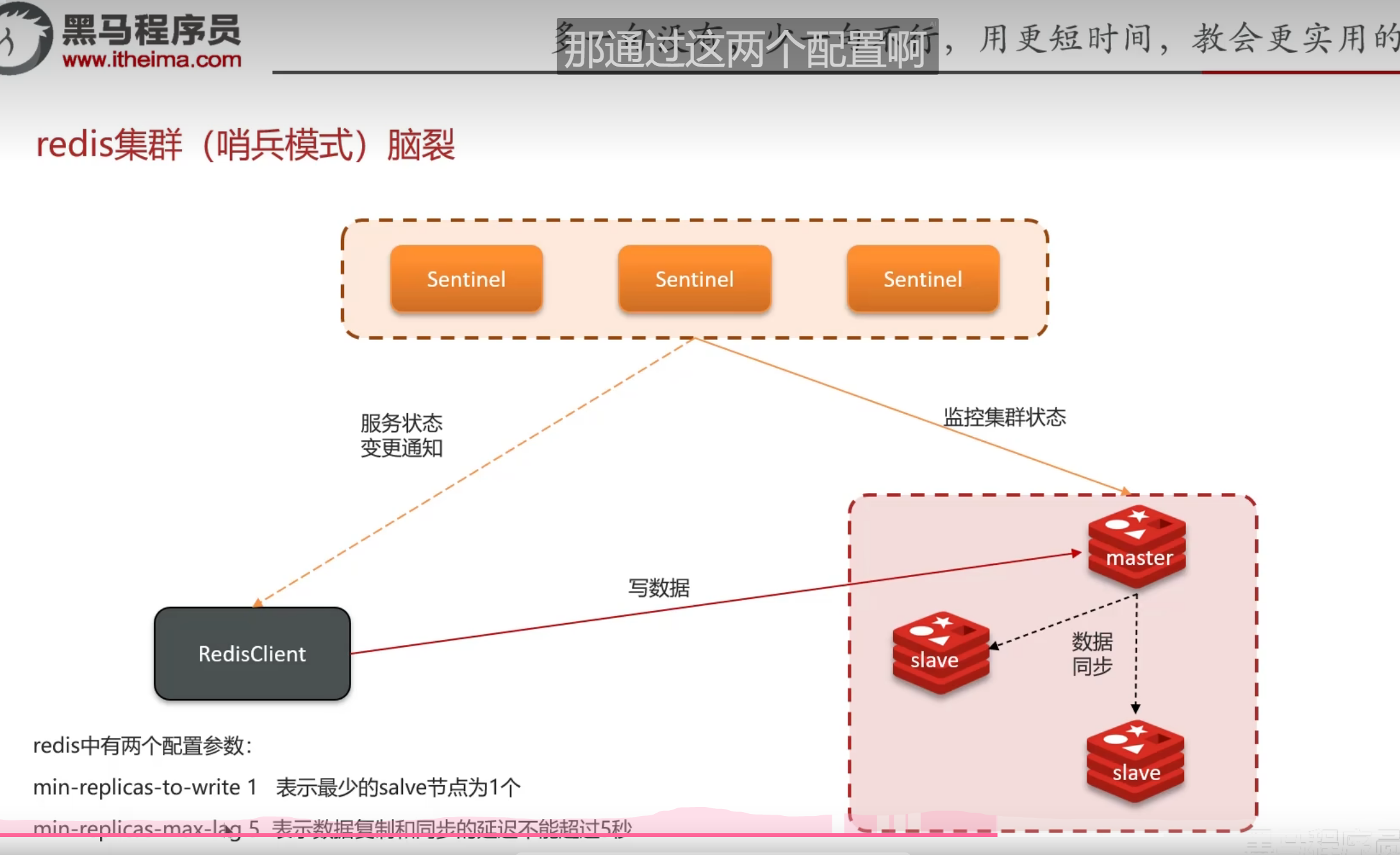
避免数据不同步
原本的master节点强制降级为slave

分片集群
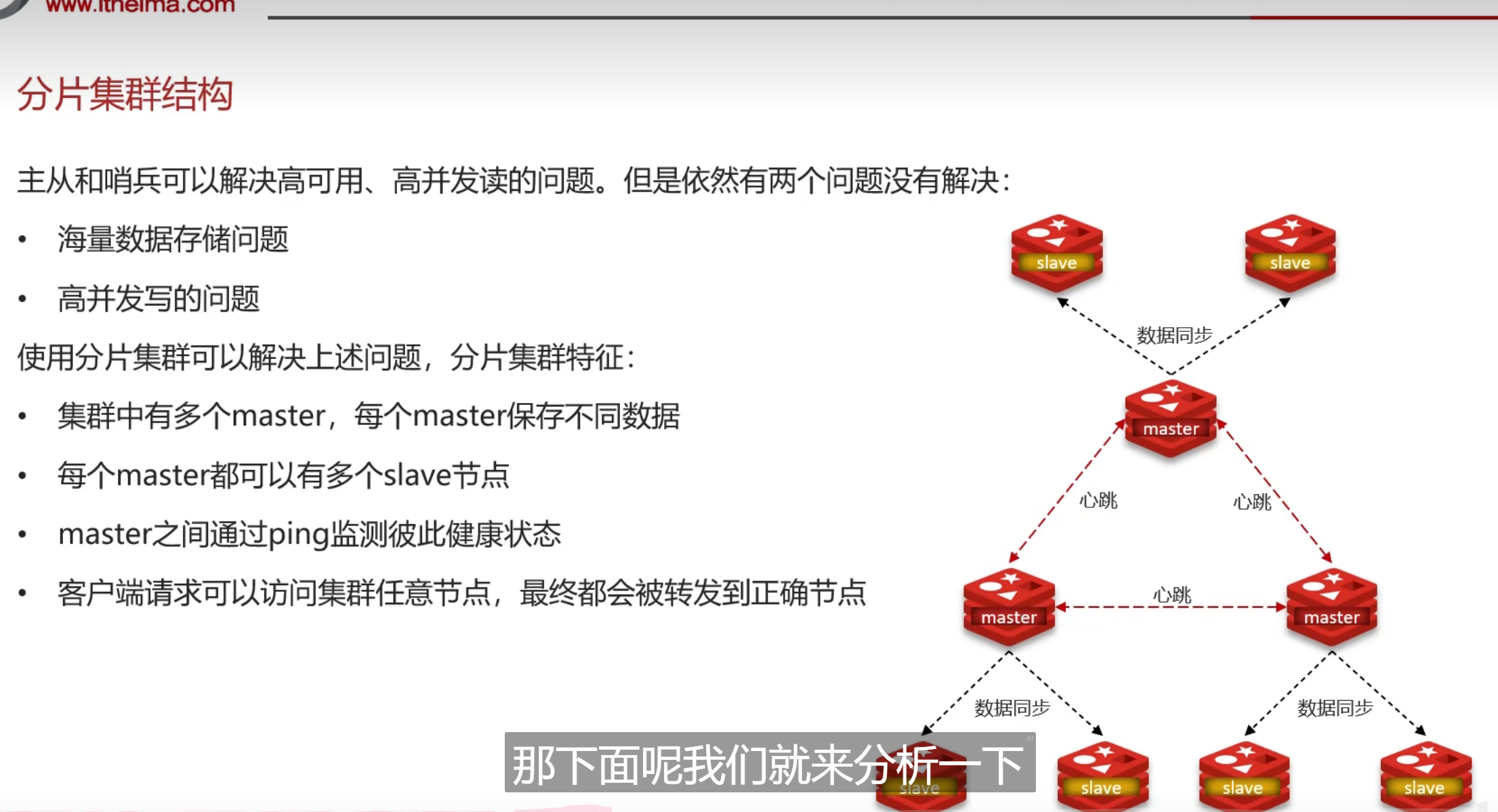
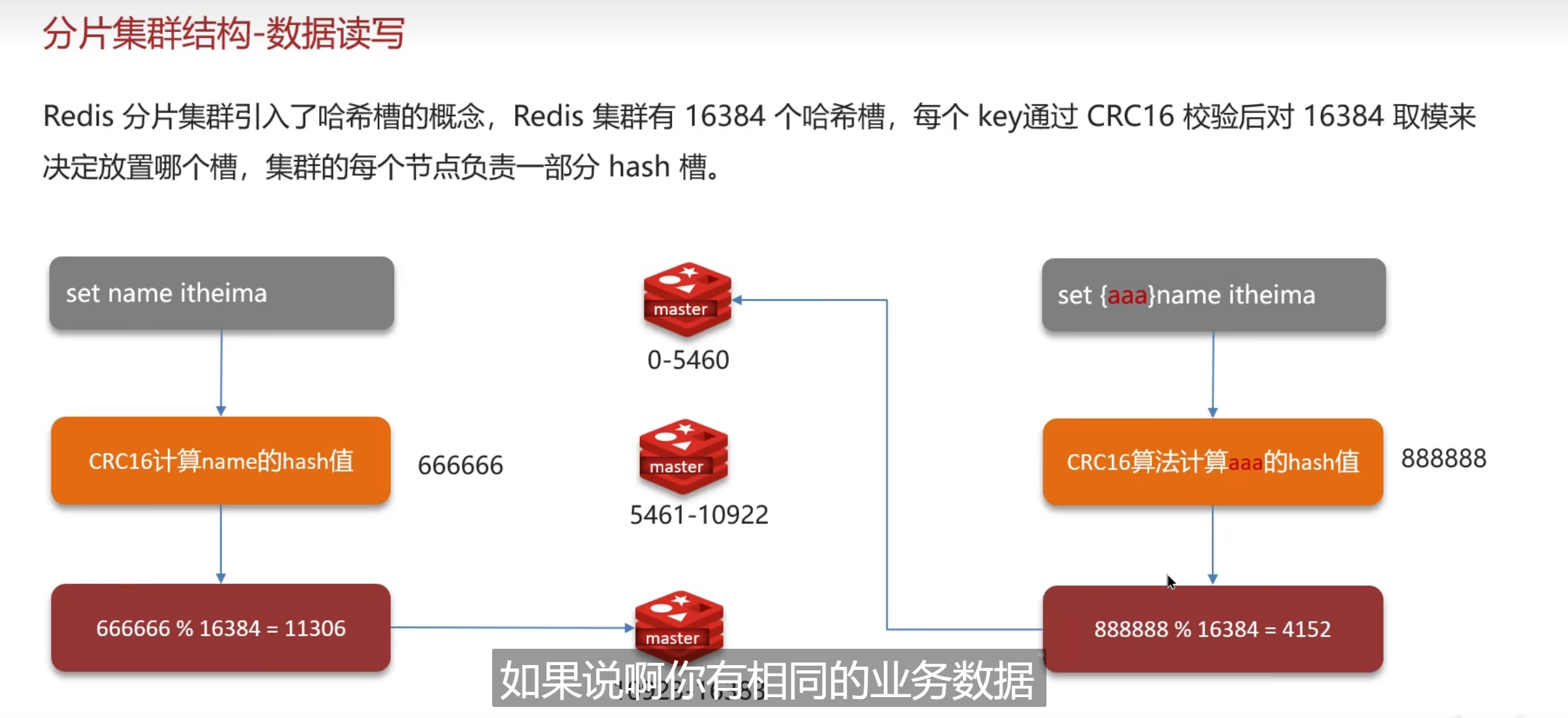
又通过hash值去进行内存存放
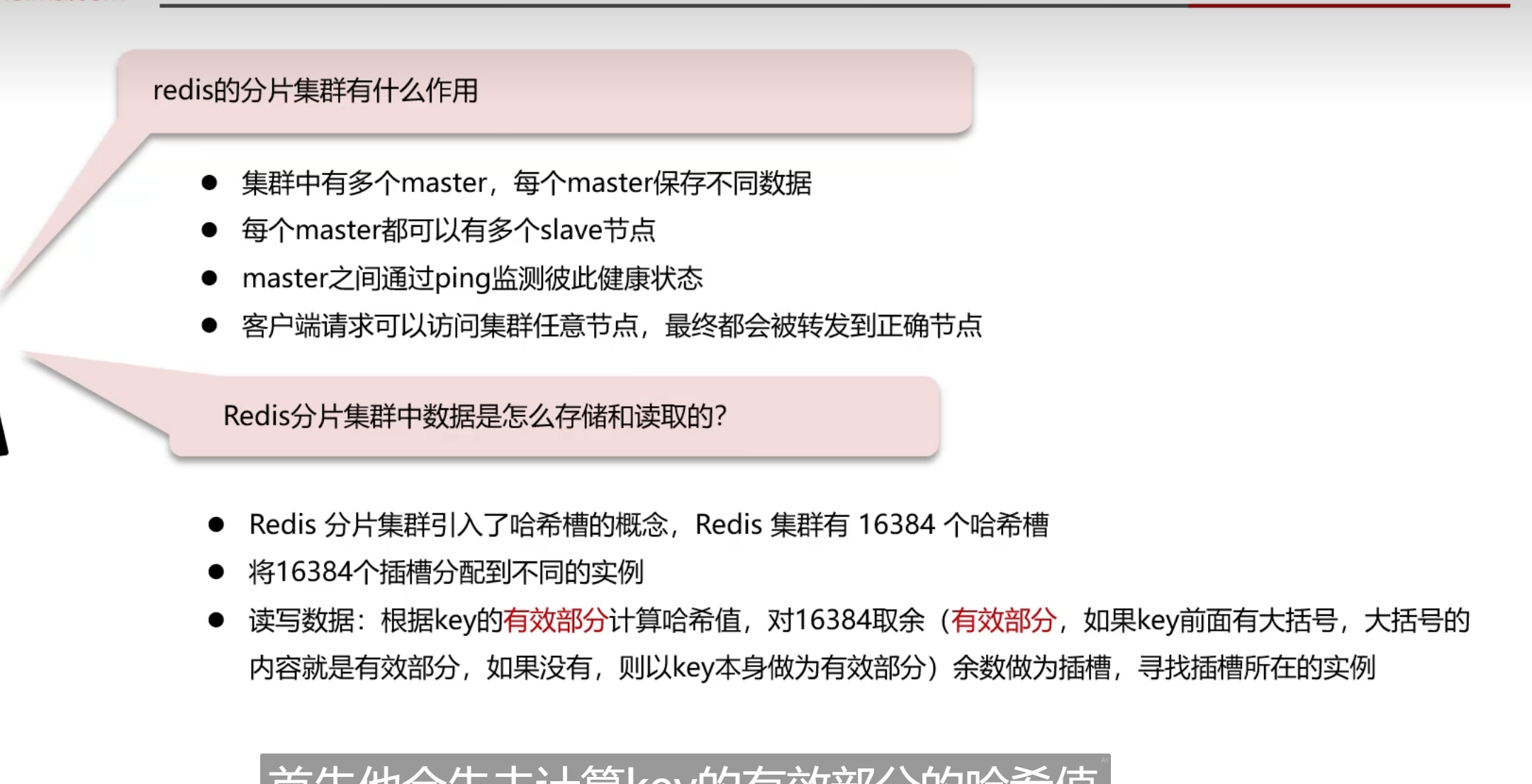
16384
这个值进行曲余
其它问题
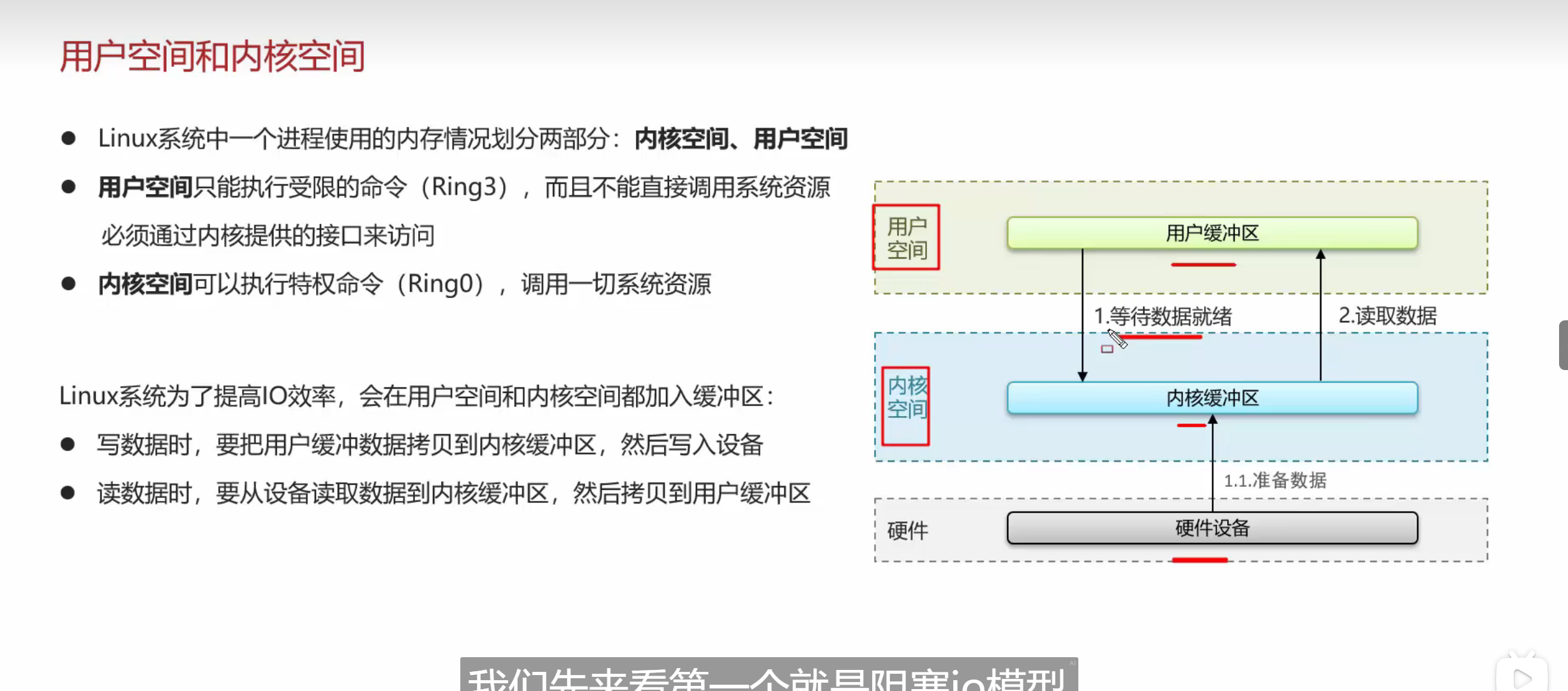
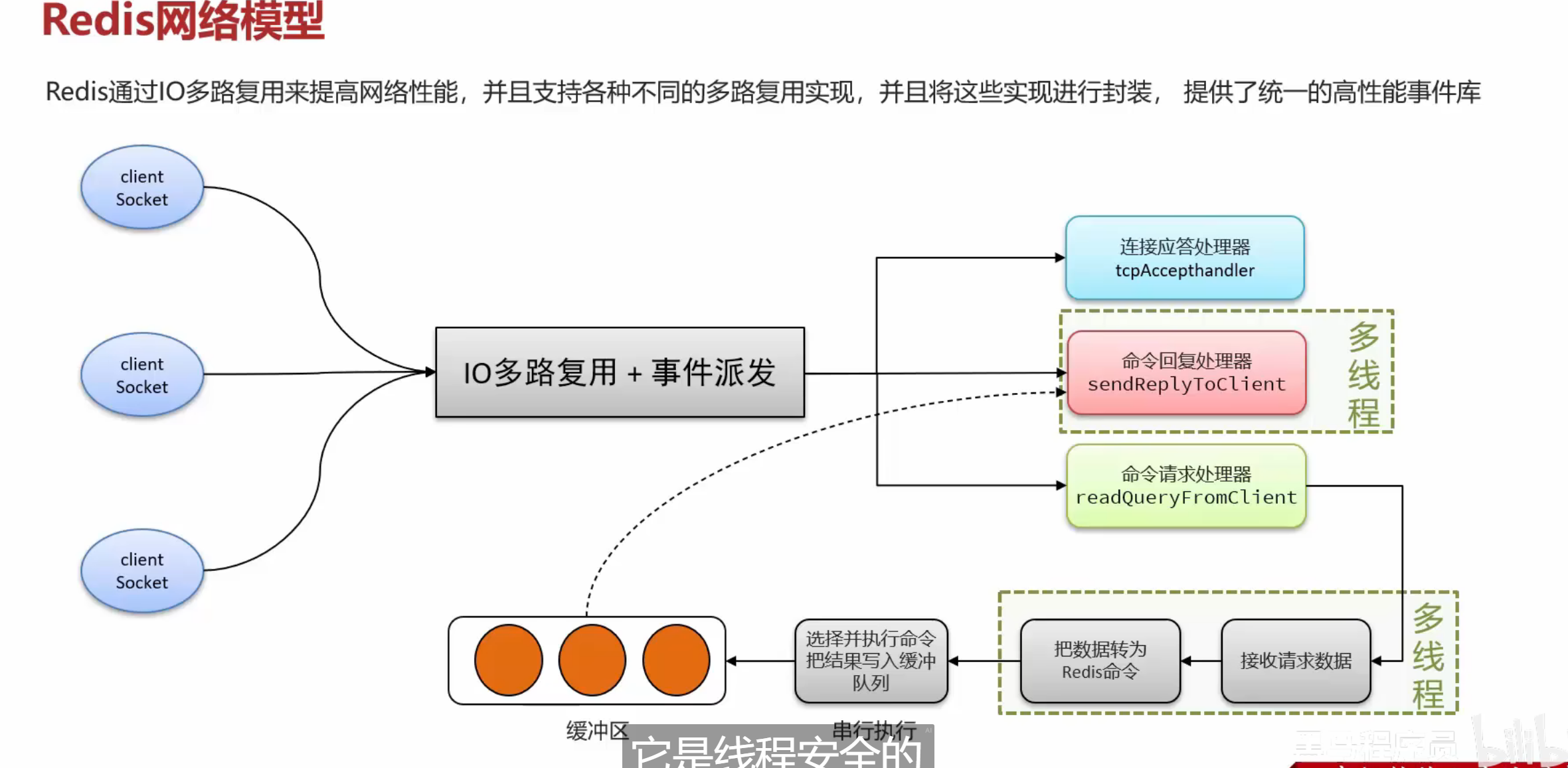
IO流程的一个前置知识点
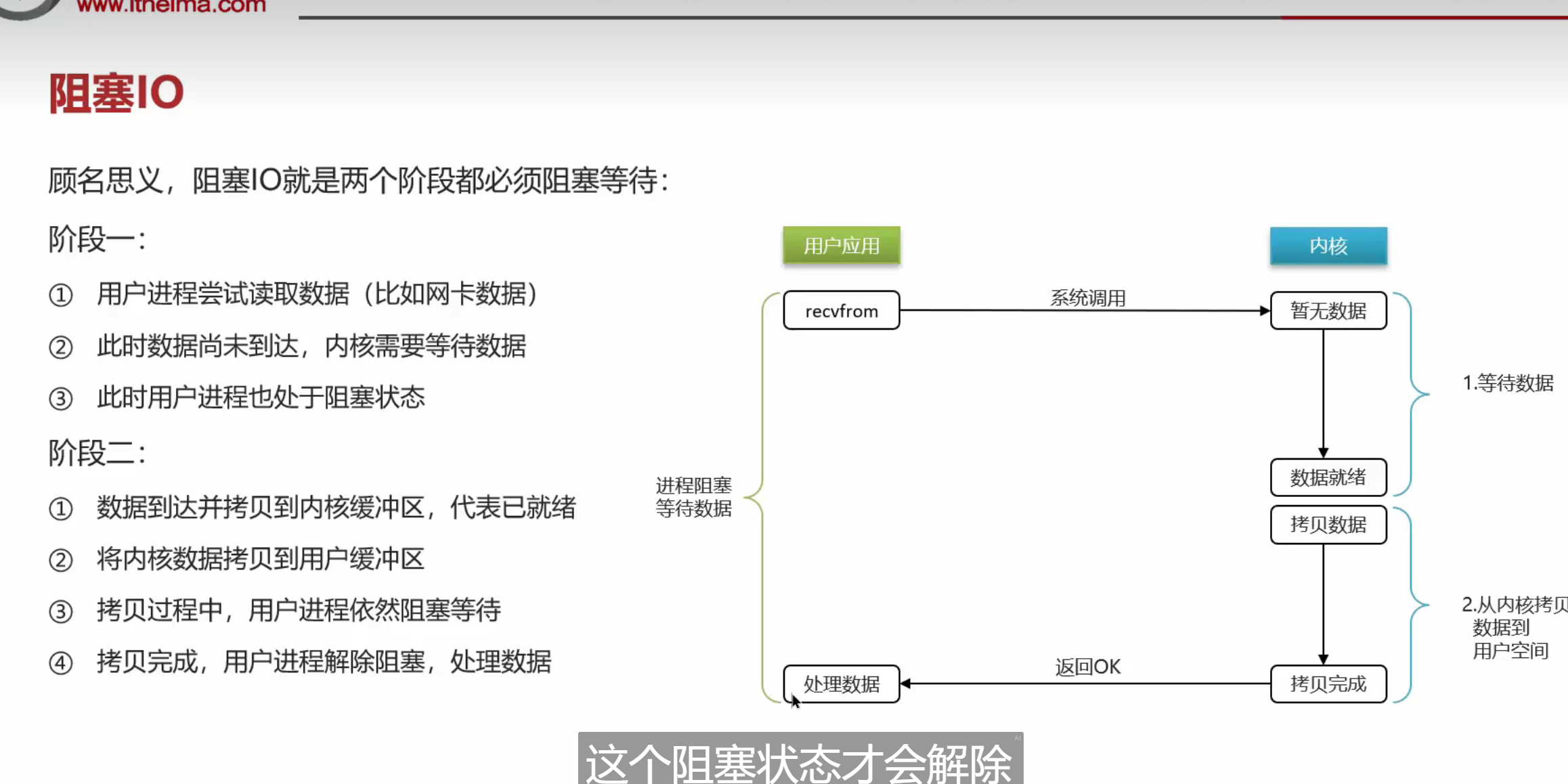 阻塞IO就性能很慢,就相当于打电话一直等
阻塞IO就性能很慢,就相当于打电话一直等
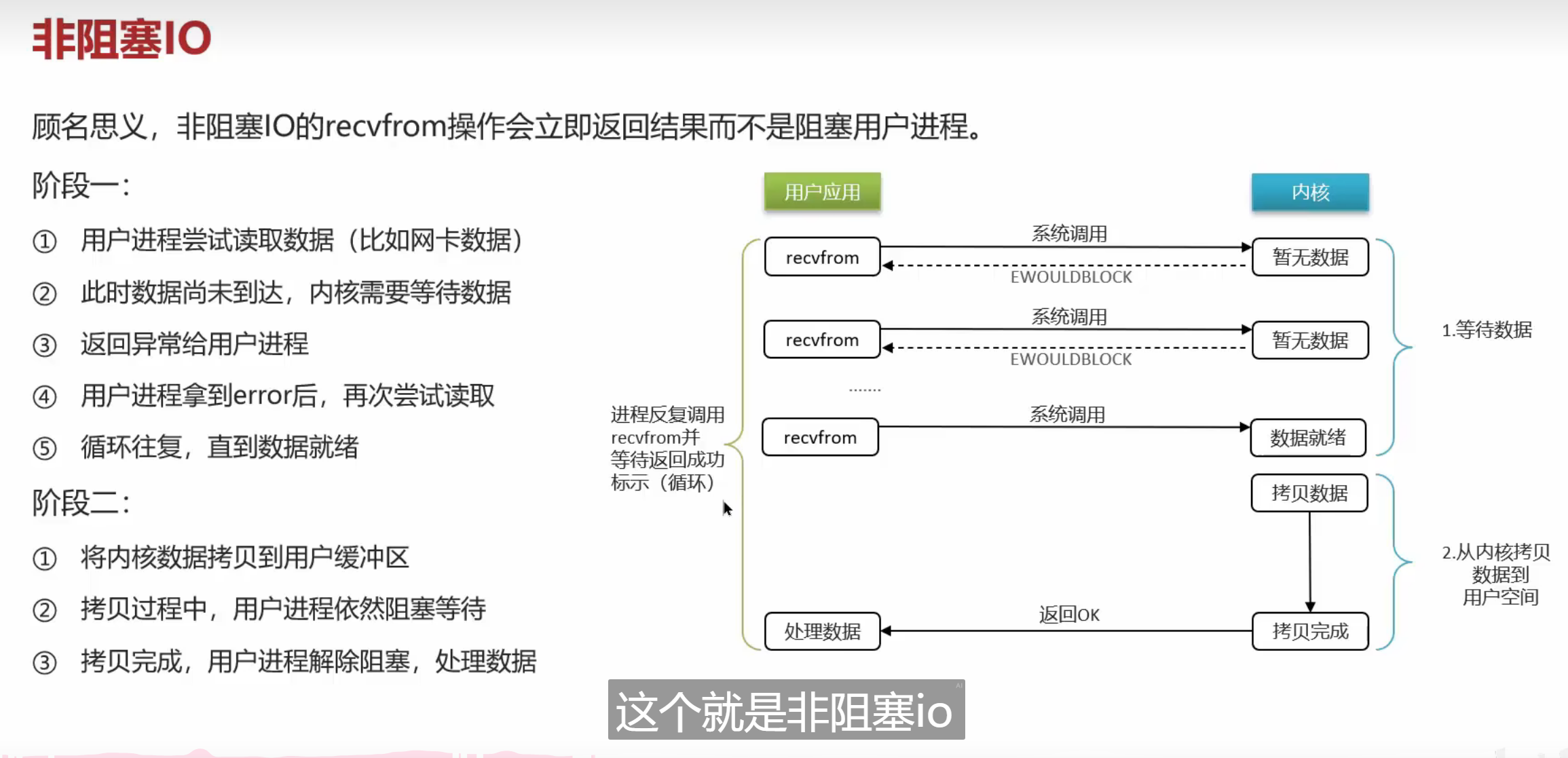
这个知识点在二哥那边已经学过了
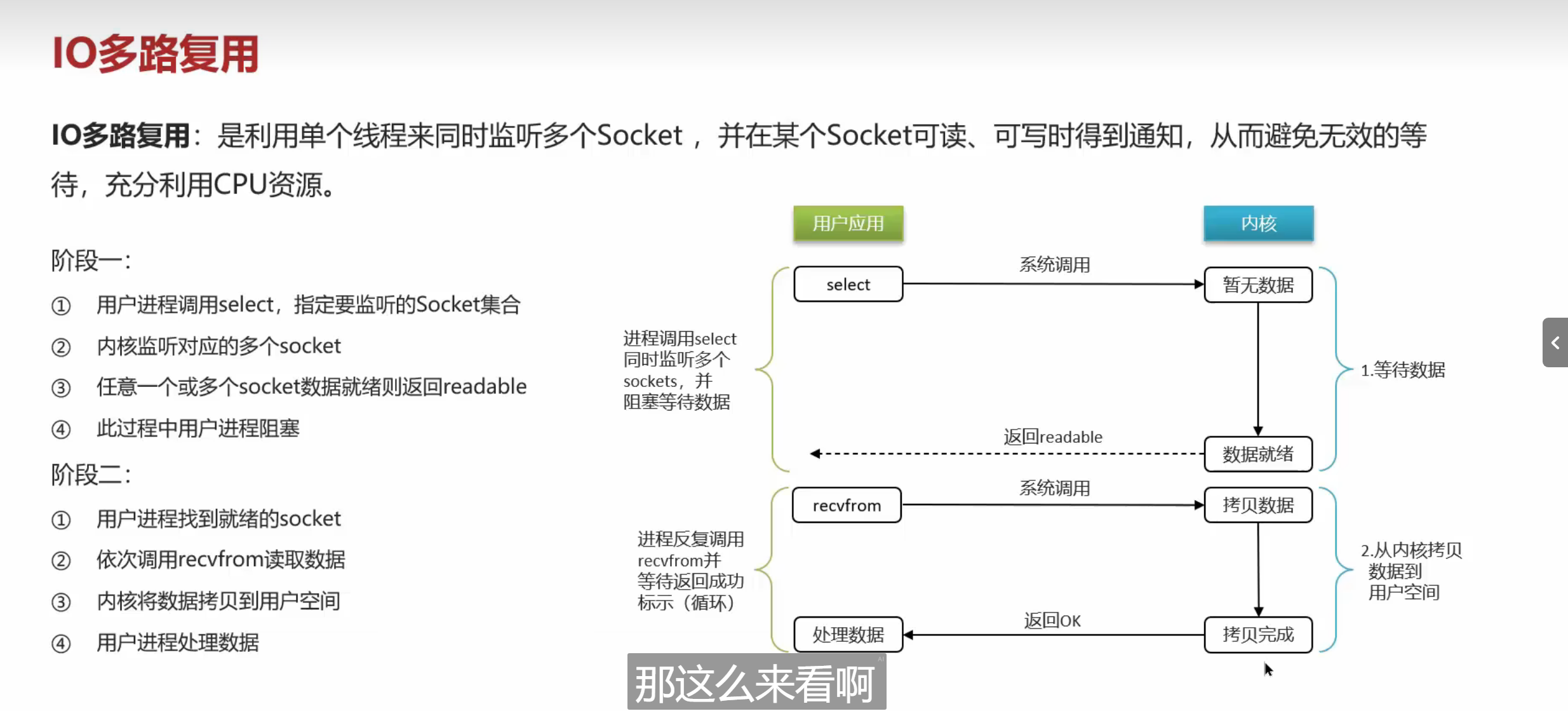
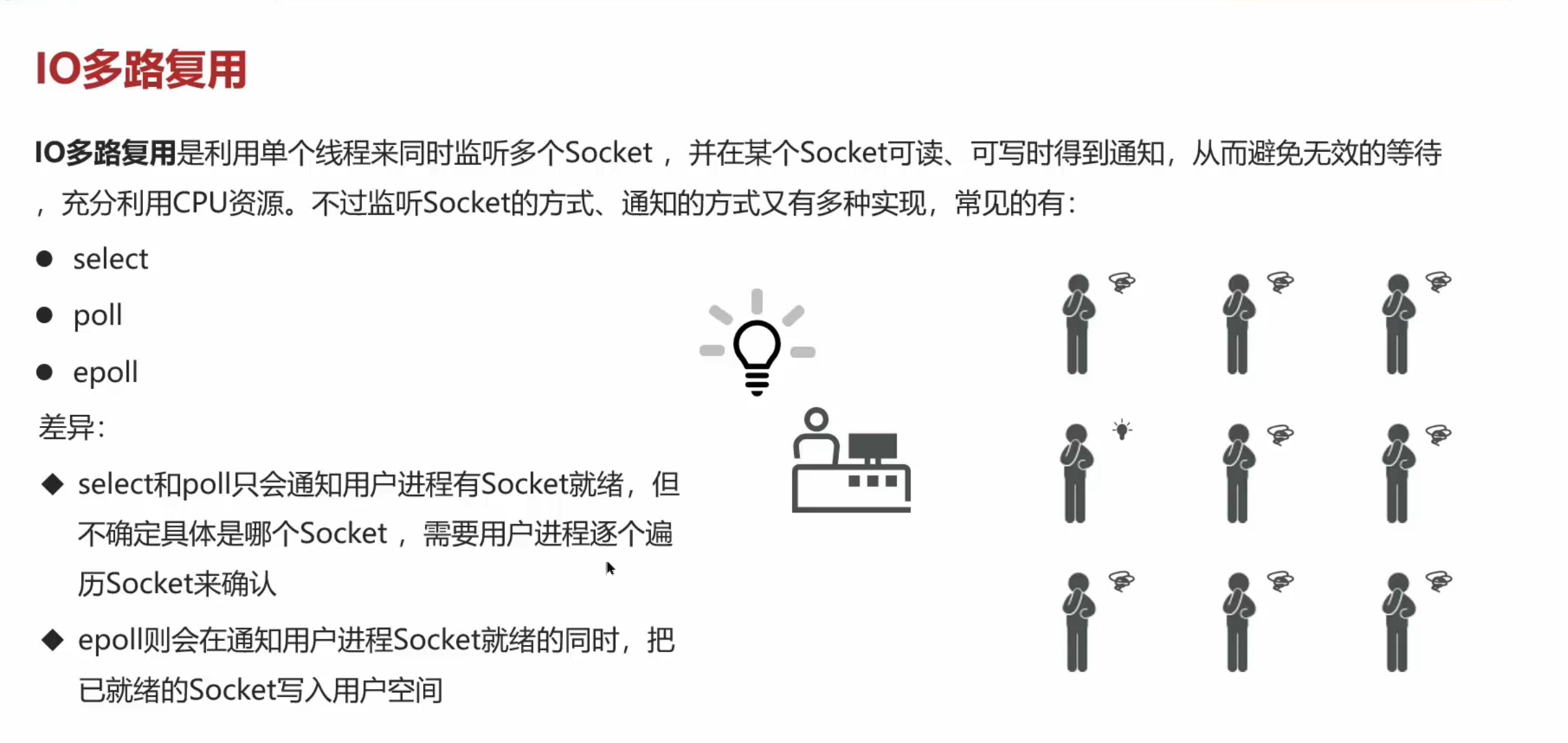 确定性,多用点技术和设备就能解决了
确定性,多用点技术和设备就能解决了