论文浅尝 | TaxoLLaMA: 用基于WordNet的模型来解决多个词汇语义任务(ACL2024)

笔记整理:屠铭尘,浙江大学硕士,研究方向为知识图谱
论文链接:https://arxiv.org/abs/2403.09207
发表会议:ACL2024
1. 动机
探索LLM在解决经典词汇语义任务上的能力。
(1)本文假设:使用hypernym上位词(IS-A关系)来finetune模型,可以提升模型解决分类相关任务(taxonomy-related tasks)的能力。
(2)基本方法:建立了一个基于taxonomy、源于English WordNet的指令集,微调模型TaxoLLaMA。
本文探索的具体词汇语义任务:
(1)Hypernym Discovery: 预测给定下位词的上位词。

(2)Taxonomy Enrichment: 在已有的分类(Taxonomy)中加入一个新的、正确的上位词。

(3)Lexical Entailment: 辨别两个短语对之间的语义关系,是否蕴含。
(4)Taxonomy Construction: 给定一系列领域专业词汇,提取词汇间的上位词-下位词关系,并建立专业领域分类(Taxonomy)
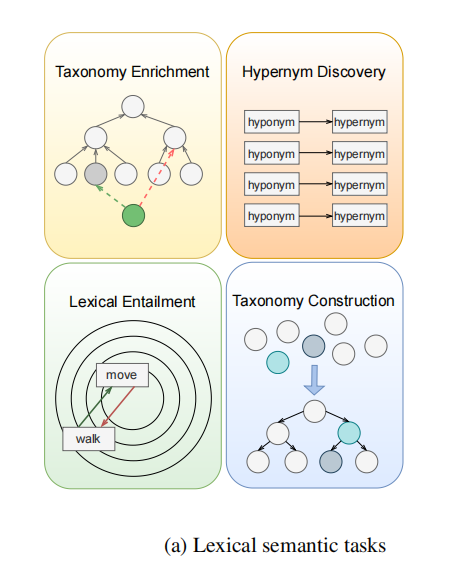
图1 本文所探究的四种词汇语义任务概要
2. 贡献
(1)利用WordNet构建taxonomy指令集、通过上位词预测相关任务来微调LLM,解决词汇语义任务;
(2)提供了一个解决一系列词汇语义任务的统一模型TaxoLLaMA,在11/16个任务上达到SOTA,并在4个任务上排在第二名;
(3)提出了基于WordNet的指令数据集,以及一些输入词汇的定义;
(4)提供了基于人工和ChatGPT的全面的错误分析;
3. 方法
3.1 Data Collection
仿照Are Large Language Models Good at Lexical Semantics? A Case of Taxonomy Learning(LREC2024)的算法,随机从WordNet-3.0中采样出名词和动词,随机选择边组成上位词-下位词对。为避免歧义,通过以下方法获得词语的定义,加入instruction:①从WordNet中获取;②由ChatGPT3.5生成;③从Wikidata中获得。

图2 指令调优集示例
3.2 Training Details
主要训练两种模型:①TaxoLLaMA,在整个WordNet-3.0数据集上训练,后期社区使用,44772 samples;②TaxoLLaMA-bench,保证训练集中没有测试集四种任务的节点,36775 samples。另外训练一种③TaxoLLaMA-Verb,使用WordNet中的verb子树训练,7712 samples。
基座模型LLaMA-2(7B),使用QLoRA方法高效微调。
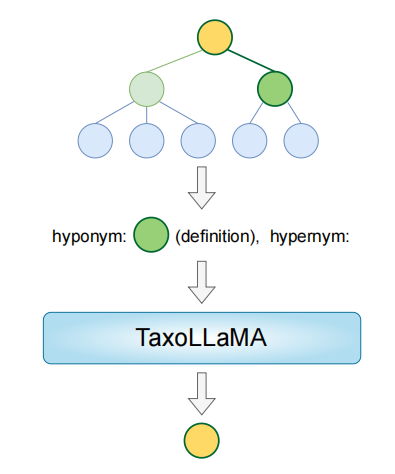
图3 训练过程
3.3 Task Adaptation
如下图(b)下方所示,”TRUE”和”两点有链接”形式上没有不同,但实际上两个任务又是不同的,因此需要有所设计。
总的来说,对于四个任务,分成两种pipeline:
(1)Generative Approach 给定一个下位词,让模型生成一系列对应上位词。在Hypernym Discovery和Taxonomy Enrichment任务上使用。
(2)Ranking Approach 使用模型困惑度perplexity来评估,困惑度越低表示关系越紧密。同时为了表征上下位关系,互换两个词关系,看困惑度是否变高。用这两个分数的比来衡量排名。比值越低,两者的上下位关系越紧密。在Taxonomy Construction和Lexical Entailment数据集上使用,使用时轻微调整。
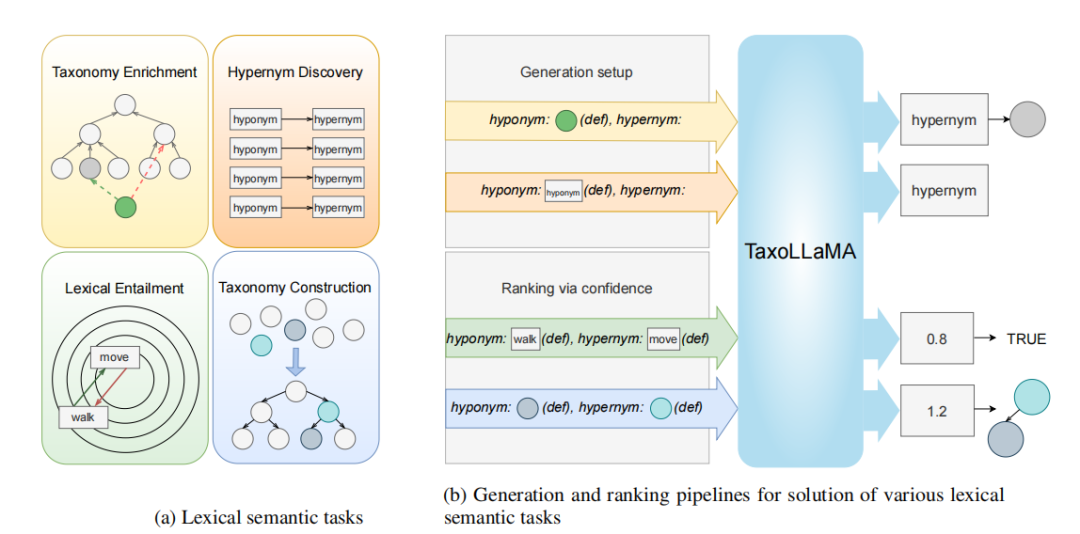
图4 四种任务(a)及对应pipeline(b)
4. 实验
4.1 Hypernym Discovery
采用测试集SemEval-2018,包含一个英文子集(通用问题+音乐、医药领域特定问题)和一个意大利西班牙语子集(通用问题)。用Mean Reciprocal Rank (MRR) metric评估。
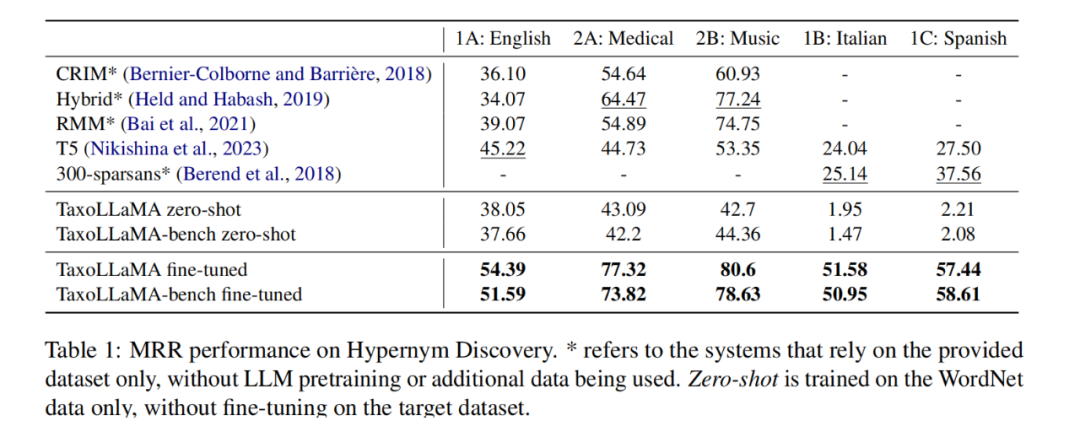
Finetune后的模型都达到了SOTA(对比方法都finetune过)。
通过Figure3a可以看出,除了2B任务,当用50个例子finetune就能达到SOTA。
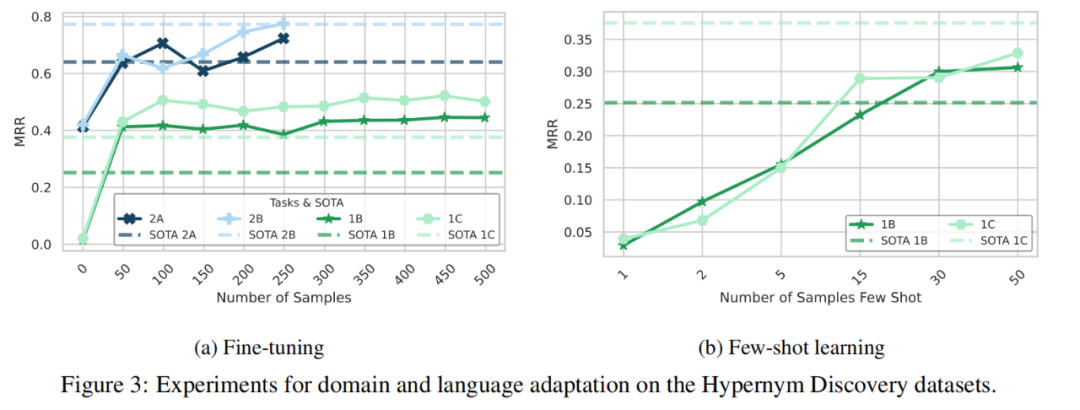
在两个非英语任务下用in-context few-shot learning达不到SOTA,认为是压缩模型的原因。
4.2 Taxonomy Enrichment
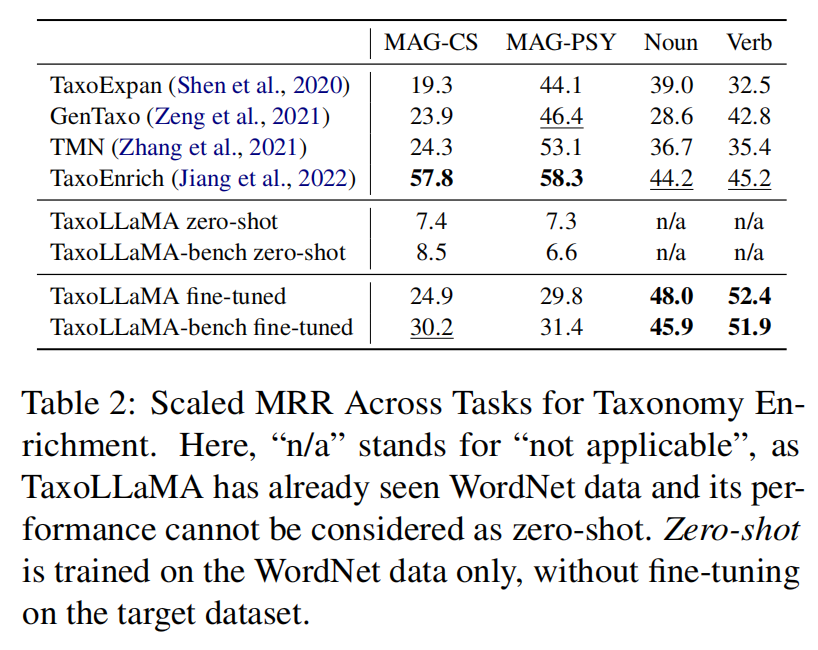
包括WordNet Noun, WordNet Verb, MAGPSY和MAG-CS四个datasets。每个数据集Sample 1000个节点。Metric:scaled MRR。
①在WordNet Noun和WordNet Verb任务上SOTA;②在MAG-CS和MAG-PSY上达不到SOTA;③在少量数据上训练的bench版本比完整模型表现更好。
4.3 Taxonomy Construction
数据集:TexEval-2 中的子任务,“Eurovoc science”、“Eurovoc environment”和“WordNet food”;评估指标:F1。
特别注意,前述比例在“食品”域的阈值设置为1.8,“环境”域的阈值设置为4.6,“科学”域的阈值设置为1.89。
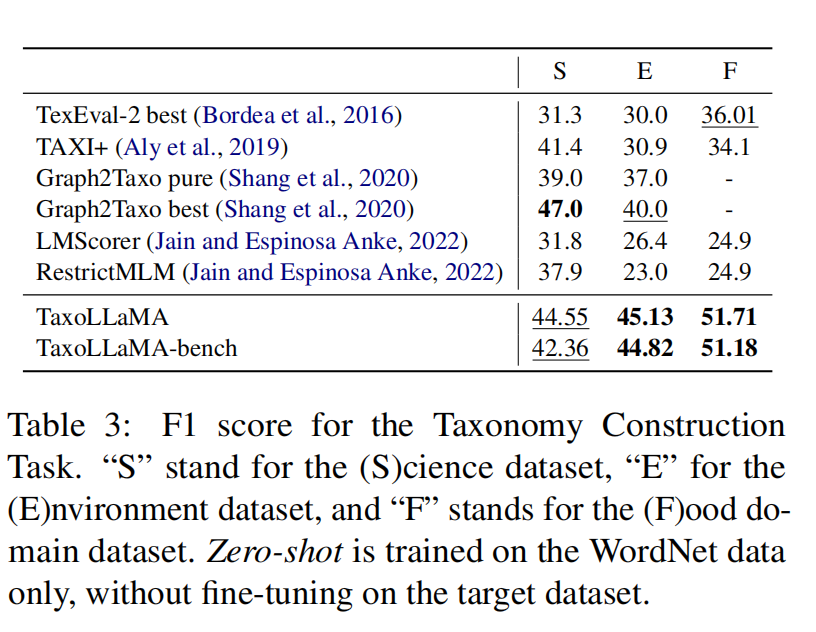
模型在Environment和Food子集上达到SOTA,在Science子集保持第二。
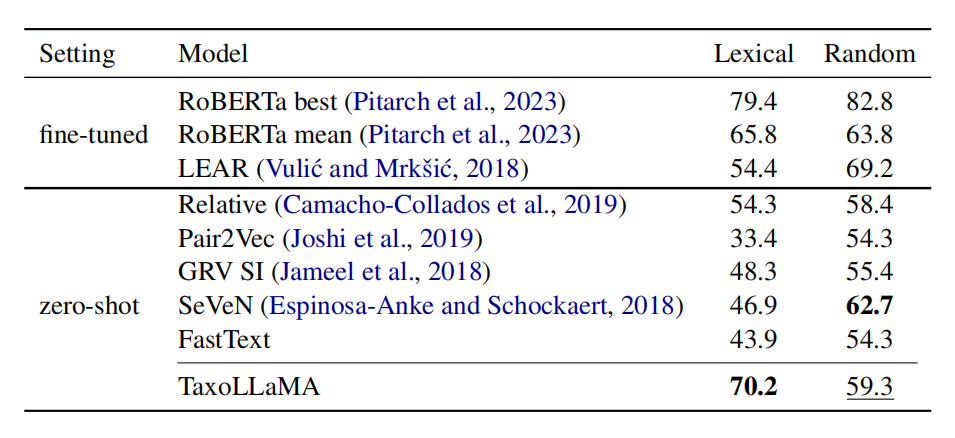
4.4 Lexical Entailment
Dataset:
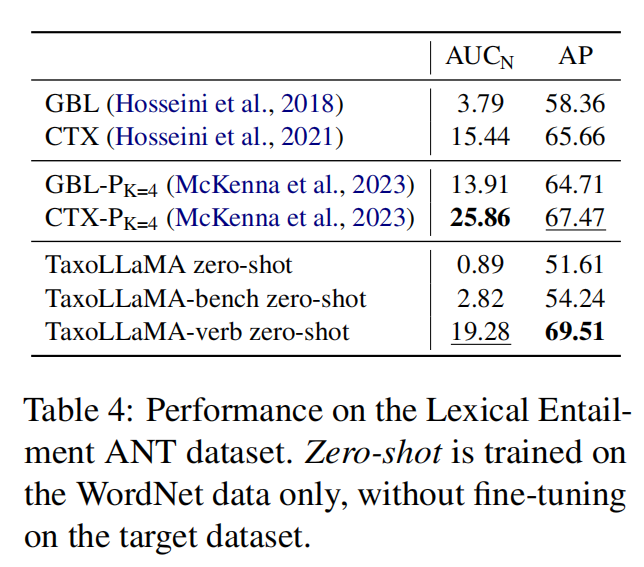
①ANT entailment subset 考察相似句子间的关系。(Metric: 刚刚提到的正向Perplexity/f反转后Perplexity的比例用L2范数正则化,衡量两个句子之间的蕴含关系。)
②HyperLex Dataset 考察动词和名词之间的蕴含关系。把perplexity看做模型预测。
ANT Dataset:在Average Precision上达到SOTA,在normalized AUC上第二。
HyperLex Dataset:①在Lexical子集上SOTA;②与过往模型在Random上通常表现比Lexcical相反,这可能说明其他模型通过Random子集的训练对模型有更多的提升。
5. 总结
本文提出了一个基于WordNet、上下位词关系进行指令微调的LLM——TaxoLLaMA,通过提升模型预测上位词的能力,使模型能更好地解决各种经典词汇语义任务。在16项任务中,11项取得了SOTA,在另外4项任务中排名第二。
基于人工和chatgpt的错误分析表明,由于过度拟合特殊的WordNet结构和无法适应目标数据集等原因,75%的错误例子都表现为将概念预测得过于宽泛。与先前研究相同,实验表明指令中加入词汇定义能更好地消除输入单词的歧义,从而有利于在Taxonomy Enrichment任务上的表现。总体而言,最困难的测试数据集是MAGs,这可能是因为该测试集与我们模型训练所用的数据有很大差异。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。