百度 AI Studio 脚本任务篇,它不同于notebook任务是支持免费的, 脚本任务是需要算力卡的,更好的算力 支持四张显卡,
 aistudio 脚本任务是需要算力卡的,是收费的一个项目,估计是运行效率更高,支持4张显卡,同时计算。
aistudio 脚本任务是需要算力卡的,是收费的一个项目,估计是运行效率更高,支持4张显卡,同时计算。
# -*- coding: utf-8 -*-
"""
空白模板
"""
###### 欢迎使用脚本任务,首先让我们熟悉脚本任务的一些使用规则 ######
# 详细教程请在AI Studio文档(https://ai.baidu.com/ai-doc/AISTUDIO/Ik3e3g4lt)中进行查看.
# 脚本任务使用流程:
# 1.编写代码/上传本地代码文件
# 2.调整数据集路径以及输出文件路径
# 3.填写启动命令和备注
# 4.提交任务选择运行方式(单机单卡/单机四卡/双机四卡)
# 5.项目详情页查看任务进度及日志
# 注意事项:
# 1.输出结果的体积上限为20GB,超过上限可能导致下载输出失败.
# 2.脚本任务单次任务最大运行时长为72小时(三天).
# 3.在使用单机四卡或双击四卡时可不配置GPU编号,默认启动所有可见卡;如需配置GPU编号,单机四卡的GPU编号为0,1,2
# 日志记录. 任务会自动记录环境初始化日志、任务执行日志、错误日志、执行脚本中所有标准输出和标准出错流(例如pri
# -------------------------------关于数据集和输出文件的路径问题---------------------------------
# 数据集路径
# datasets_prefix为数据集的根路径,完整的数据集文件路径是由根路径和相对路径拼接组成的。
# 相对路径获取方式:请在编辑项目状态下通过点击左侧导航「数据集」中文件右侧的【复制】按钮获取.
# datasets_prefix = '/root/paddlejob/workspace/train_data/datasets/'
# train_datasets = datasets_prefix + '通过路径拷贝获取真实数据集文件路径'
# 输出文件路径
# 任务完成后平台会自动把output_dir目录所有文件压缩为tar.gz包,用户可以通过「下载输出」将输出结果下载到本地.
# output_dir = "/root/paddlejob/workspace/output/"
# -------------------------------关于启动命令需要注意的问题------------------------------------
# 脚本任务支持两种运行方式
# 1.shell 脚本. 在 run.sh 中编写项目运行时所需的命令,并在启动命令框中填写如 bash run.sh 的命令使脚本任务正
# 2.python 指令. 在 run.py 编写运行所需的代码,并在启动命令框中填写如 python run.py <参数1> <参数2> 的命令使
# 注:run.sh、run.py 可使用自己的文件替代,如python train.py 、bash train.sh.
# 命令示例:
# 1. python 指令
# ---------------------------------------单机四卡-------------------------------------------
# 方式一(不配置GPU编号):python -m paddle.distributed.launch run.py
# 方式二(配置GPU编号):python -m paddle.distributed.launch --gpus="0,1,2,3" run.py
# ---------------------------------------双机四卡-------------------------------------------
# 方式一(不配置GPU编号):python -m paddle.distributed.launch run.py
# 方式二(配置GPU编号):python -m paddle.distributed.launch --gpus="0,1" run.py
# 2. shell 命令
# 使用run.sh或自行创建新的shell文件并在对应的文件中写下需要执行的命令(需要运行多条命令建议使用shell命令的方
# 以单机四卡不配置GPU编号为例,将单机四卡方式一的指令复制在run.sh中,并在启动命令出写出bash run.sh
脚本任务说明
脚本任务执行由GPU集群作为支撑, 具有实时高速的并行计算和浮点计算能力, 有效解放深度学习训练中的计算压力, 提高处理效率.
用户可以先在Notebook项目中, 利用在线的Notebook功能, 完成代码的编写与调试, 之后在脚本任务中运行, 从而提高模型训练速度.
创建脚本任务
-
点击创建项目按钮
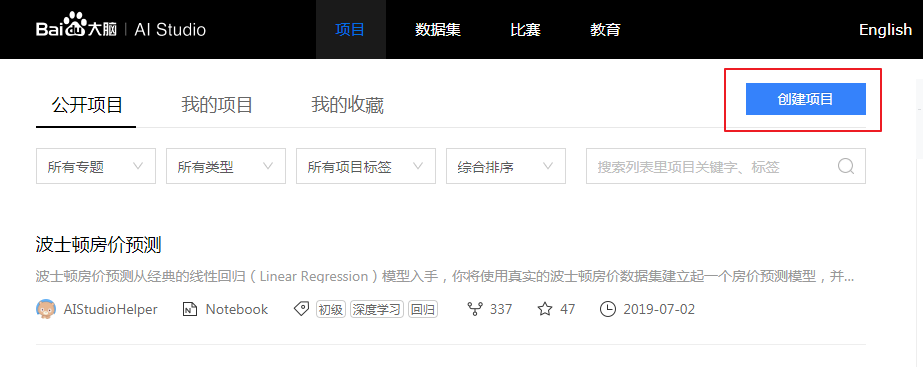
-
选择创建脚本任务
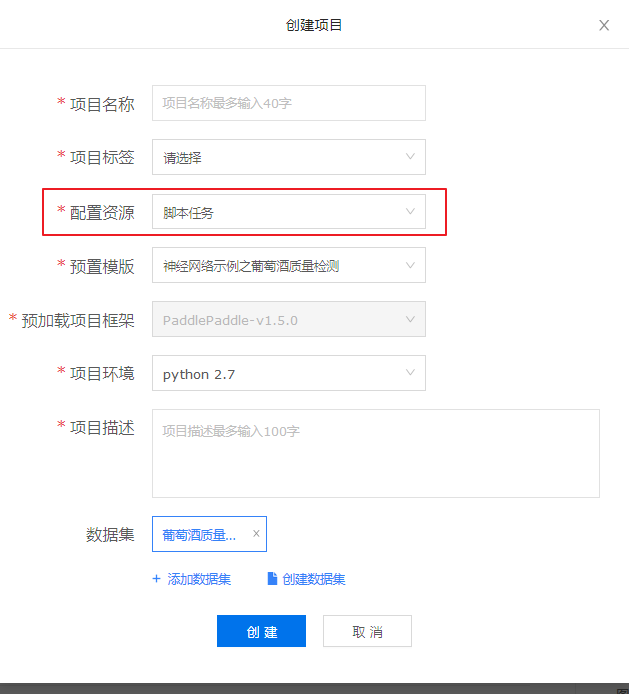
页面概览
在脚本任务详情页中, 用户可以浏览自己创建的项目内容, 编辑项目名称及数据集等信息, 查看历史任务信息等.
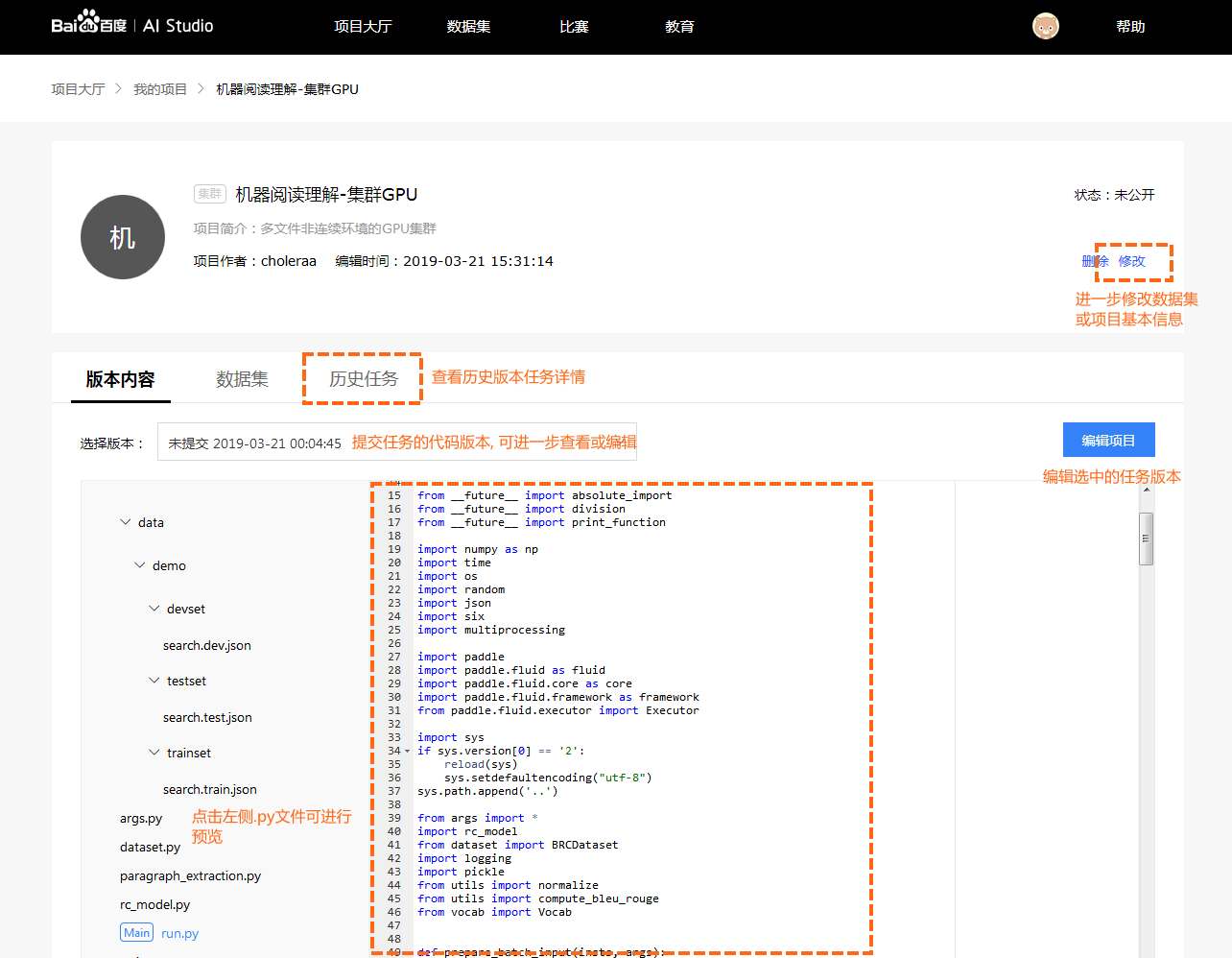
- 版本内容: 默认展示当前Notebook最新内容. 初始化状态为脚本任务示例代码. 用户可以手动选择提交任务时对应的历史版本.
- 数据集: 项目所引用的数据集信息.
- 历史任务: 每一次执行任务的记录.
代码编辑
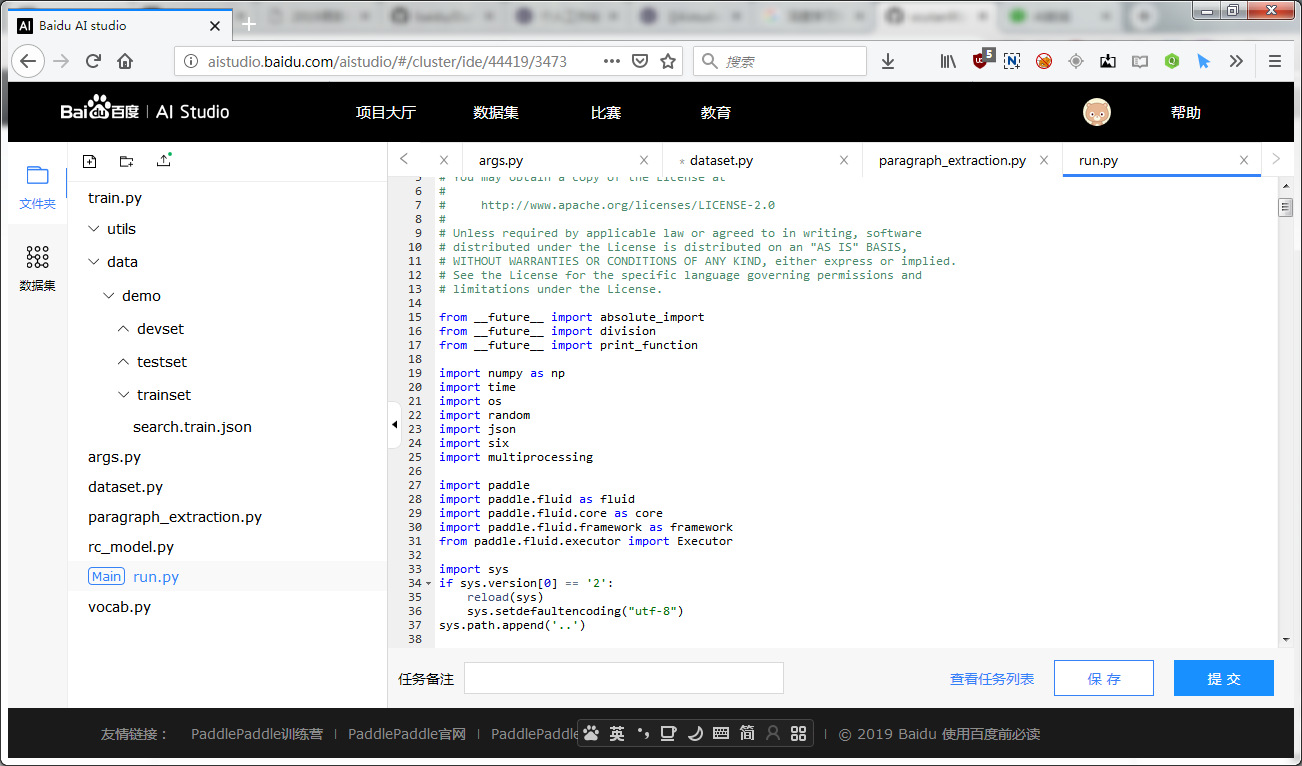
代码编辑界面主要分为左侧: 文件管理及数据集, 和右侧: 代码编辑区及提交任务
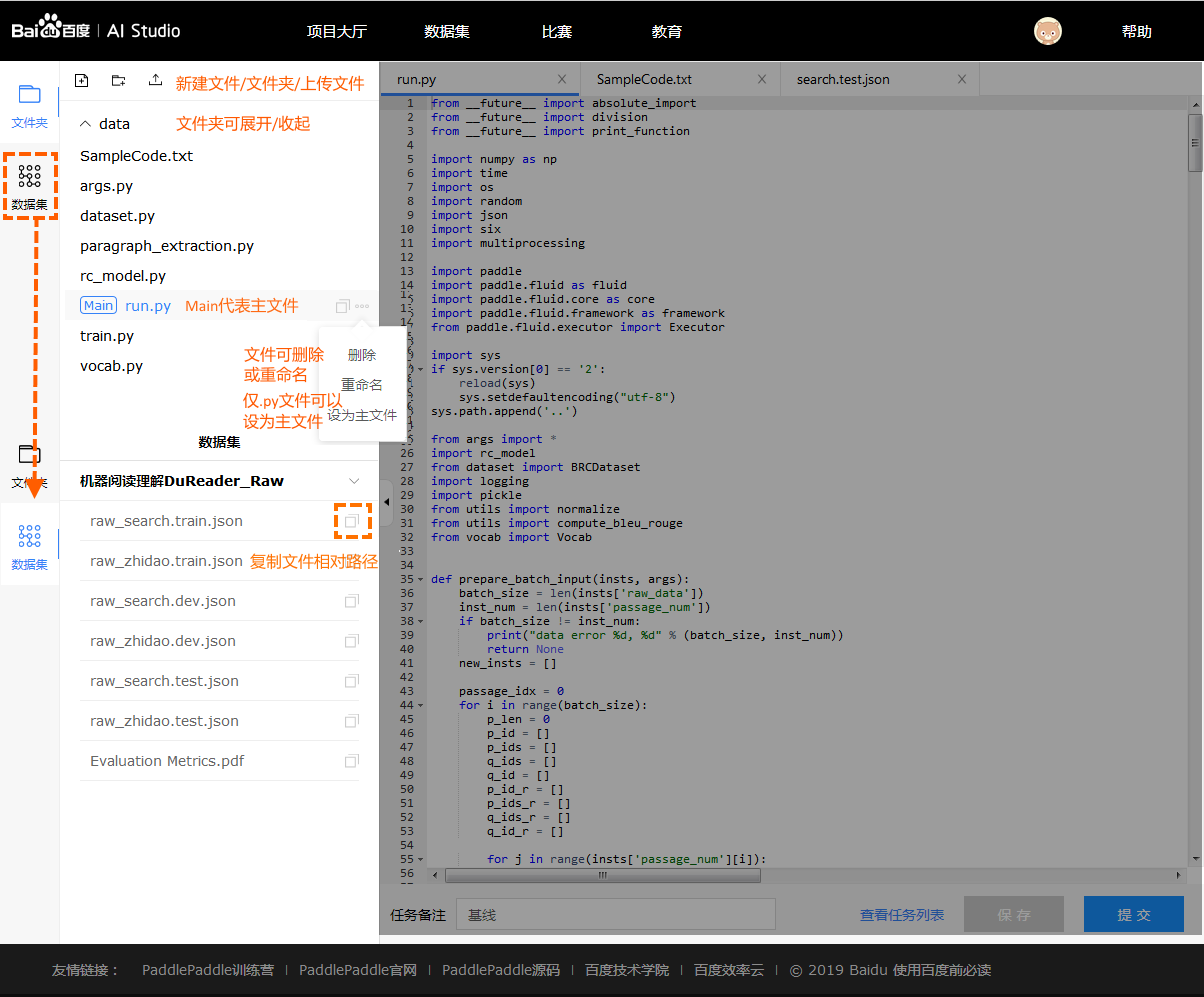
左侧文件管理和数据集
文件管理
- 用户可以手动创建文件/文件夹, 对文件/文件夹进行重命名或删除.
- 其中用户可以选择指定文件, 并设置为主文件. 用作整个项目运行入口.
- 用户也可以手动上传文件(体积上限为20MB, 体积巨大的文件请通过数据集上传).
- 用户可以双击文件, 在右侧将新建一个tab. 用户可以进一步查看或编辑该文件的内容. (目前仅支持.py文件和.txt文件; 同时预览文件的体积上限为1MB)
数据集管理
- 用户可以查看数据集文件, 并复制该文件的相对路径. 最后拼合模板内置绝对路径, 即可使用. 下方有详细介绍.
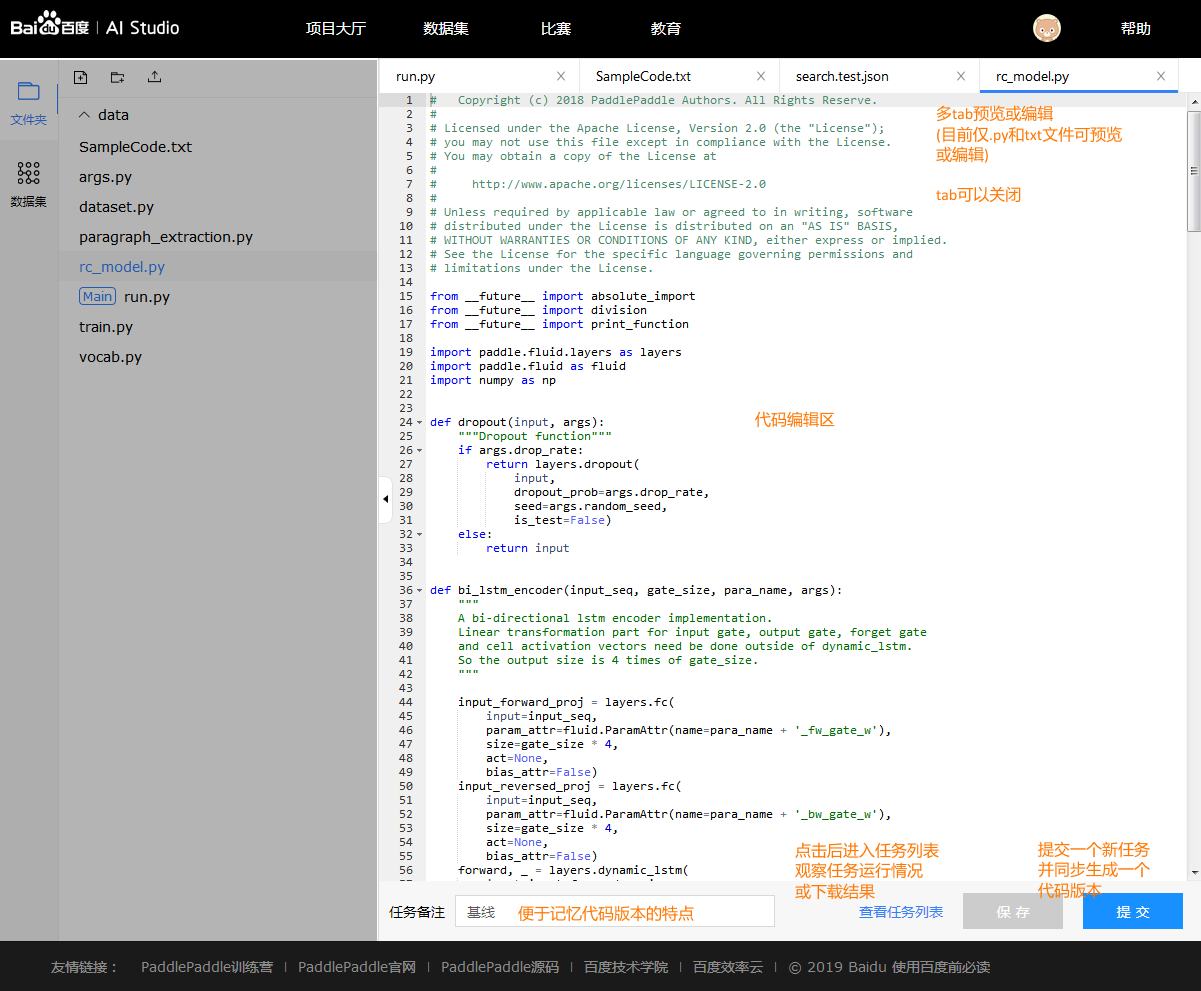
右侧文件预览编辑和提交任务
- 当多个文件被打开时, 用户可以将它们逐一关闭, 当至最后一个文件时即不可关闭
- 选中文件对应的tab即可对文件内容进行预览和编辑, 但当前仅支持.py和.txt格式的文件
- 点击保存按钮, 会将所有文件的改动信息全部保存, 如用户不提交任务, 直接退出, 则自动保存为一个"未提交"版本
- 提交任务前, 建议写一个备注名称, 方便未来进行不同版本代码/参数的效果比较
PaddlePaddle脚本任务说明
PaddlePaddle基于集群的分布式训练任务与单机训练任务调用方法不同。基于pserver-trainer架构的的分布式训练任务分为两种角色: parameter server(pserver)和trainer.
在Fluid 中, 用户只需配置单机训练所需要的网络配置, DistributeTranspiler模块会自动地根据 当前训练节点的角色将用户配置的单机网路配置改写成pserver和trainer需要运行的网络配置:
t = fluid.DistributeTranspiler()
t.transpile(
trainer_id = trainer_id,
pservers = pserver_endpoints,
trainers = trainers)
if PADDLE_TRAINING_ROLE == "TRAINER":
# 获取pserver程序并执行它
trainer_prog = t.get_trainer_program()
...
elif PADDLE_TRAINER_ROLE == "PSERVER":
# 获取trainer程序并执行它
pserver_prog = t.get_pserver_program(current_endpoint)
...
- 目前脚本任务中提供的默认环境
PADDLE_TRAINERS=1(PADDLE_TRAINERS是分布式训练任务中 trainer 节点的数量) - 非PaddlePaddle代码请放到
if PADDLE_TRAINING_ROLE == "TRAINER":分支下执行, 例如数据集解压任务
更多集群项目说明请参考PaddlePaddle官方文档
数据集与输出文件路径说明
- 脚本任务中添加的数据集统一放到绝对路径
./datasets
# 数据集文件会被自动拷贝到./datasets目录下
CLUSTER_DATASET_DIR = '/root/paddlejob/workspace/train_data/datasets/'
- 脚本任务数据集文件路径的获取
在页面左侧数据集中点击复制数据集文件路径, 得到文件的相对路径, 例如点击后复制到剪切板的路径为data65/train-labels-idx1-ubyte.gz.
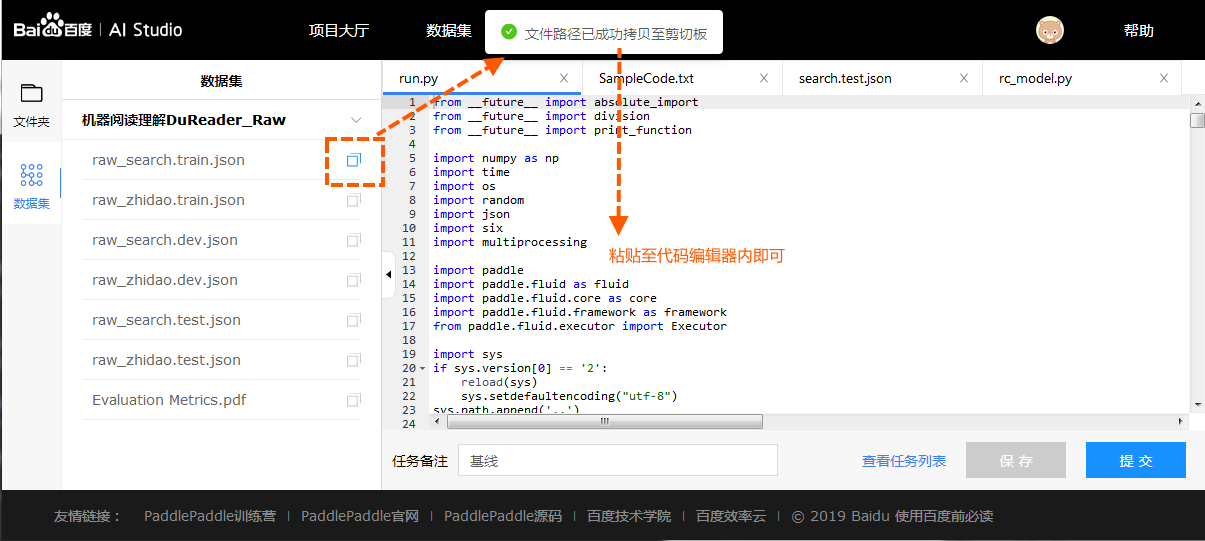
# 数据集文件相对路径
file_path = 'data65/train-labels-idx1-ubyte.gz'
真正使用的时候需要将两者拼合 train_datasets = datasets_prefix + file_path
- 集群项目输出文件路径为
./output
# 需要下载的文件可以输出到'/root/paddlejob/workspace/output'目录
CLUSTER_OUTPUT_DIR = '/root/paddlejob/workspace/output'
提交任务
点击【运行项目】后进入到任务编辑页面.
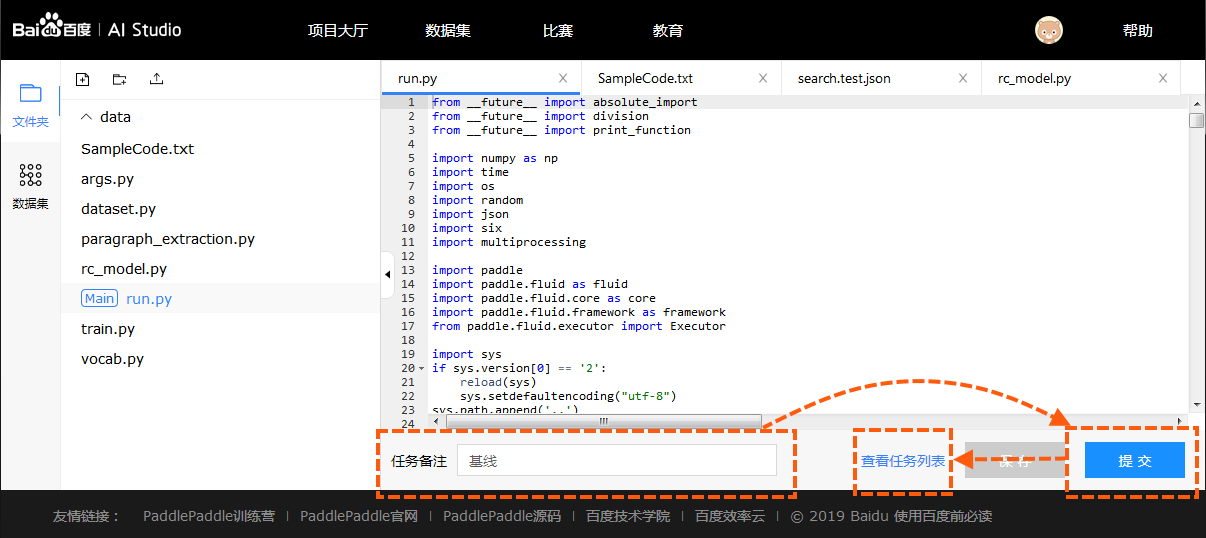
- 提交: 点击提交会发起本次本次任务的执行. 并将代码自动保存为一个版本.
- 任务备注: 任务自定义标识, 用于区分项目内每次执行的任务.
历史任务
历史任务页面如下所示.
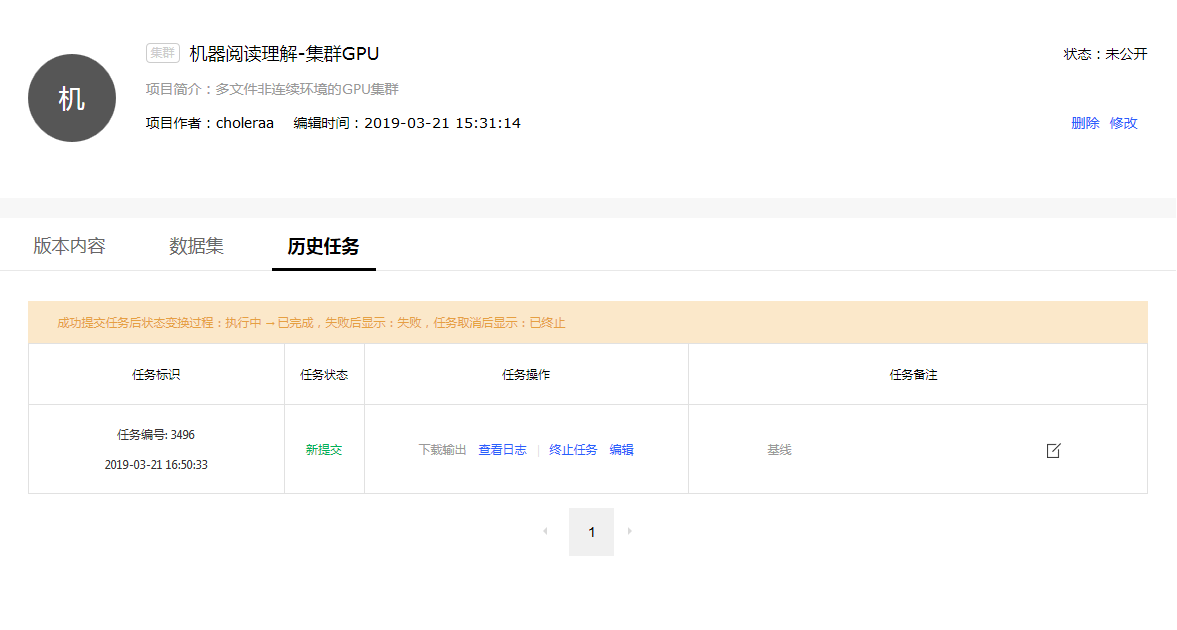
任务操作:
- 下载输出: 下载任务输出文件, 文件格式
xxx(任务编号)_output.tar.gz. - 查看/下载日志: 在任务运行过程中, 点击"查看日志", 可以查看实时日志, 掌握运行进度. 运行结束后, 按钮转为"下载日志". 下载任务执行日志, 日志格式
xxx(任务编号)_log.tar.gz. - 终止任务: 在任务执行过程中, 可以点击终止任务.
- 编辑: 编辑任务对应的代码版本内容.
空间说明
- 脚本任务空间安装包列表
| Package | Version |
|---|---|
| backports.functools-lru-cache | 1.5 |
| cycler | 0.10.0 |
| graphviz | 0.10.1 |
| kiwisolver | 1.0.1 |
| matplotlib | 2.2.3 |
| nltk | 3.4 |
| numpy | 1.15.4 |
| opencv-python | 3.4.4.19 |
| paddlepaddle-gpu | 1.3.1 |
| Pillow | 5.3.0 |
| pip | 18.1 |
| protobuf | 3.1.0 |
| pyparsing | 2.3.0 |
| rarfile | 3.0 |
| recordio | 0.1.5 |
| requests | 2.9.2 |
| scipy | 1.1.0 |
| setuptools | 40.6.2 |
| six | 1.12.0 |
| subprocess32 | 3.5.3 |
| wheel | 0.32.3 |
问题反馈
如在使用中遇到问题, 可以邮件至 aistudio@baidu.com