【保姆级教程】使用 PyTorch 自定义卷积神经网络(CNN) 实现图像分类、训练验证、预测全流程【附数据集与源码】
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【车辆检测追踪与流量计数系统】 |
| 49.【行人检测追踪与双向流量计数系统】 | 50.【基于YOLOv8深度学习的反光衣检测与预警系统】 |
| 51.【危险区域人员闯入检测与报警系统】 | 52.【高密度人脸智能检测与统计系统】 |
| 53.【CT扫描图像肾结石智能检测系统】 | 54.【水果智能检测系统】 |
| 55.【水果质量好坏智能检测系统】 | 56.【蔬菜目标检测与识别系统】 |
| 57.【非机动车驾驶员头盔检测系统】 | 58.【太阳能电池板检测与分析系统】 |
| 59.【工业螺栓螺母检测】 | 60.【金属焊缝缺陷检测系统】 |
| 61.【链条缺陷检测与识别系统】 | 62.【交通信号灯检测识别】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 环境配置
- 详细步骤
- 结论:
引言
卷积神经网络(也称为 CNN 或 ConvNet)由 Yann LeCun 于 20 世纪 80 年代提出,至今已取得长足进步。基于 CNN 的架构不仅用于简单的数字分类任务,还被广泛用于许多深度学习和计算机视觉相关任务,例如对象检测、图像分割、注视跟踪等。本文将使用 PyTorch 框架在流行的 CIFAR-10 数据集上实现基于 CNN 的图像分类器。
环境配置
为了实现 CNN 并下载 CIFAR-10 数据集,我们需要torch和torchvision模块。除此之外,我们还将使用 numpy 和 matplotlib 进行数据分析和绘图。可以使用以下命令使用 pip 包管理器安装所需的库:
pip install torch torchvision torchaudio numpy matplotlib
详细步骤
步骤1:下载数据并从训练集中打印一些示例图像。
- 在开始进行 模型训练 之前,我们首先需要将数据集下载到本地机器上,我们将在该机器上训练我们的模型。为此,我们将
使用 torchvision库,将 CIFAR-10 数据集分别下载到目录“./CIFAR10/train”和“./CIFAR10/test ”中的训练和测试集中。我们还应用了图像变换,该过程在所有图像的三个通道上完成。 - 现在,我们有一个训练数据集和一个测试数据集,分别包含 50000 和 10000 张图像,尺寸为 32x32x3。之后,我们将这些数据集转换为批大小为 128 的数据加载器,以实现更好的泛化和更快的训练过程。
- 最后,我们从第一批训练数据中绘制出一些样本图像,以了解我们使用torchvision的**make_grid实用程序处理的图像。
具体代码如下:
import torch
import torchvision
import matplotlib.pyplot as plt
import numpy as np
# The below two lines are optional and are just there to avoid any SSL
# related errors while downloading the CIFAR-10 dataset
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
#Defining plotting settings
plt.rcParams['figure.figsize'] = 14, 6
#Initializing normalizing transform for the dataset
normalize_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean = (0.5, 0.5, 0.5),
std = (0.5, 0.5, 0.5))])
#Downloading the CIFAR10 dataset into train and test sets
train_dataset = torchvision.datasets.CIFAR10(
root="./CIFAR10/train",
train=True,
transform=normalize_transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(
root="./CIFAR10/test",
train=False,
transform=normalize_transform,
download=True)
#Generating data loaders from the corresponding datasets
batch_size = 128
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
#Plotting 25 images from the 1st batch
dataiter = iter(train_loader)
images, labels = dataiter.next()
plt.imshow(np.transpose(torchvision.utils.make_grid(
images[:25], normalize=True, padding=1, nrow=5).numpy(), (1, 2, 0)))
plt.axis('off')
输出:

图 1:来自训练数据集的一些示例图像
步骤 2:绘制数据集的类别分布
绘制训练集的类别分布通常是一个好主意。**这有助于检查所提供的数据集是否平衡。**为此,我们分批迭代整个训练集并收集每个实例的相应类别。最后,我们计算唯一类别的数量并绘制它们。
代码如下:
#Iterating over the training dataset and storing the target class for each sample
classes = []
for batch_idx, data in enumerate(train_loader, 0):
x, y = data
classes.extend(y.tolist())
#Calculating the unique classes and the respective counts and plotting them
unique, counts = np.unique(classes, return_counts=True)
names = list(test_dataset.class_to_idx.keys())
plt.bar(names, counts)
plt.xlabel("Target Classes")
plt.ylabel("Number of training instances")
输出:
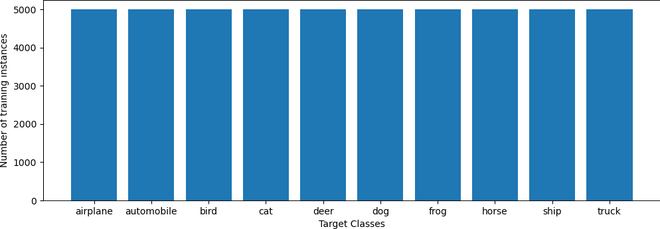
图 2:训练集的类别分布
如图 2 所示,这十个类别中的每一个类别都有几乎相同数量的训练样本。因此,我们不需要采取额外的步骤来重新平衡数据集。
步骤3:实现CNN架构
在架构方面,我们将使用一个简单的模型,该模型采用三个深度分别为32、64 和 64 的卷积层,然后是两个完全连接层以执行分类。
- 每个卷积层都涉及一个包含3×3 卷积滤波器的卷积操作,然后是 ReLU 激活操作以将非线性引入系统,以及带有 2×2 滤波器的最大池化操作以降低特征图的维数。
- 在卷积块结束后,我们将多维层扁平化为低维结构,以开始我们的分类块。在第一个线性层之后,最后一个输出层(也是线性层)针对我们数据集中的十个唯一类别中的每一个都有十个神经元。
架构如下:

图 3:CNN 的架构图
为了构建我们的模型,我们将创建一个从torch.nn.Module类继承的CNN 类,以利用 Pytorch 实用程序。除此之外,我们将使用torch.nn.Sequential容器将我们的层一个接一个地组合起来。
- Conv2D ()、ReLU()和MaxPool2D()层执行卷积、激活和池化操作。我们使用 1 的填充来为内核提供足够的学习空间,因为填充为图像提供了更多的覆盖区域,尤其是外框中的像素。
- 卷积块之后,***Linear()***全连接层执行分类。
代码:
class CNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = torch.nn.Sequential(
#Input = 3 x 32 x 32, Output = 32 x 32 x 32
torch.nn.Conv2d(in_channels = 3, out_channels = 32, kernel_size = 3, padding = 1),
torch.nn.ReLU(),
#Input = 32 x 32 x 32, Output = 32 x 16 x 16
torch.nn.MaxPool2d(kernel_size=2),
#Input = 32 x 16 x 16, Output = 64 x 16 x 16
torch.nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3, padding = 1),
torch.nn.ReLU(),
#Input = 64 x 16 x 16, Output = 64 x 8 x 8
torch.nn.MaxPool2d(kernel_size=2),
#Input = 64 x 8 x 8, Output = 64 x 8 x 8
torch.nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, padding = 1),
torch.nn.ReLU(),
#Input = 64 x 8 x 8, Output = 64 x 4 x 4
torch.nn.MaxPool2d(kernel_size=2),
torch.nn.Flatten(),
torch.nn.Linear(64*4*4, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 10)
)
def forward(self, x):
return self.model(x)
步骤 4:定义训练参数并开始训练
我们通过选择训练模型的设备(即 CPU 或 GPU)来开始训练过程。然后,我们定义模型超参数,如下所示:
- 我们对模型进行了50 轮训练,由于我们有一个多类问题,我们使用交叉熵损失作为我们的目标函数。
- 我们采用了流行的Adam 优化器,学习率为 0.001,**weight_decay 为 0.01,**通过正则化来优化目标函数,防止过度拟合。
最后,我们开始训练循环,其中包括计算每个批次的输出,并通过将预测标签与真实标签进行比较来计算损失。最后,我们绘制了每个时期的训练损失,以确保训练过程按计划进行。
代码:
#Selecting the appropriate training device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = CNN().to(device)
#Defining the model hyper parameters
num_epochs = 50
learning_rate = 0.001
weight_decay = 0.01
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
#Training process begins
train_loss_list = []
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}:', end = ' ')
train_loss = 0
#Iterating over the training dataset in batches
model.train()
for i, (images, labels) in enumerate(train_loader):
#Extracting images and target labels for the batch being iterated
images = images.to(device)
labels = labels.to(device)
#Calculating the model output and the cross entropy loss
outputs = model(images)
loss = criterion(outputs, labels)
#Updating weights according to calculated loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
#Printing loss for each epoch
train_loss_list.append(train_loss/len(train_loader))
print(f"Training loss = {train_loss_list[-1]}")
#Plotting loss for all epochs
plt.plot(range(1,num_epochs+1), train_loss_list)
plt.xlabel("Number of epochs")
plt.ylabel("Training loss")
输出:
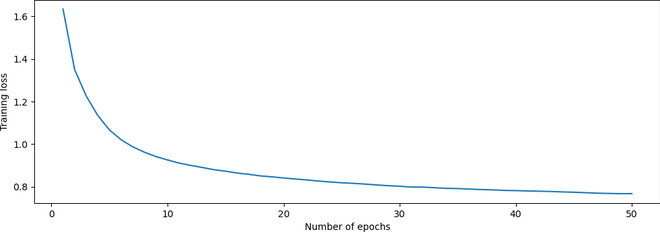
图 4:训练损失与周期数的关系图
从图 4 中我们可以看出,随着训练次数的增加,损失逐渐减少,这表明训练过程成功。
步骤 5:计算模型在测试集上的准确率
现在我们的模型已经训练完毕,我们需要检查它在测试集上的表现。为此,我们分批迭代整个测试集,并通过比较每个批次的真实标签和预测标签来计算准确率。
代码:
test_acc=0
model.eval()
with torch.no_grad():
#Iterating over the training dataset in batches
for i, (images, labels) in enumerate(test_loader):
images = images.to(device)
y_true = labels.to(device)
#Calculating outputs for the batch being iterated
outputs = model(images)
#Calculated prediction labels from models
_, y_pred = torch.max(outputs.data, 1)
#Comparing predicted and true labels
test_acc += (y_pred == y_true).sum().item()
print(f"Test set accuracy = {100 * test_acc / len(test_dataset)} %")
输出:

图 5:测试集上的准确率
步骤 6:生成测试集中样本图像的预测
如图 5 所示,我们的模型已达到近 72% 的准确率。为了验证其性能,我们可以为一些样本图像生成一些预测。为此,我们获取测试集最后一批的前五张图像,并使用torchvision 的make_grid实用程序绘制它们。然后,我们从模型中收集它们的真实标签和预测,并将它们显示在图的标题中。
代码:
#Generating predictions for 'num_images' amount of images from the last batch of test set
num_images = 5
y_true_name = [names[y_true[idx]] for idx in range(num_images)]
y_pred_name = [names[y_pred[idx]] for idx in range(num_images)]
#Generating the title for the plot
title = f"Actual labels: {y_true_name}, Predicted labels: {y_pred_name}"
#Finally plotting the images with their actual and predicted labels in the title
plt.imshow(np.transpose(torchvision.utils.make_grid(images[:num_images].cpu(), normalize=True, padding=1).numpy(), (1, 2, 0)))
plt.title(title)
plt.axis("off")
输出:

图 6:测试集中 5 个样本图像的实际标签与预测标签。请注意,标签的顺序与相应图像的顺序相同,从左到右。
从图 6 可以看出,除了第二张图像外,该模型对所有图像都产生了正确的预测,因为它将狗错误地归类为猫!
结论:
本文介绍了在流行的 CIFAR-10 数据集上用 PyTorch 实现的简单 CNN。我们还可以尝试网络架构和模型超参数,以进一步提高模型准确性!
关注文末名片G-Z-H:【阿旭算法与机器学习】,发送【开源】可获取更多学习资源

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!