【加密社】3分钟快速制作一个爬虫?不懂编程也没关系
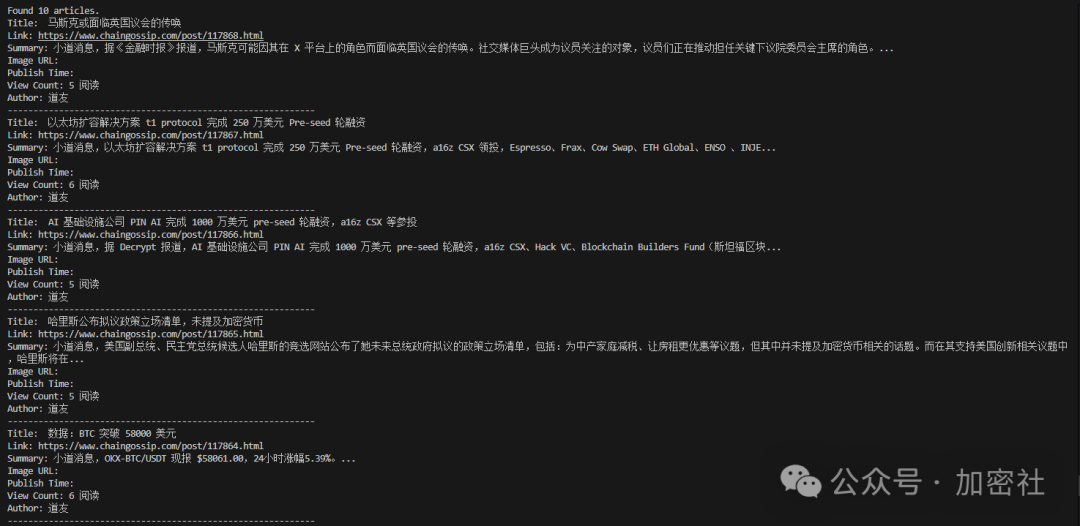
先上图,我们爬取的是某个区块链快讯的网站。

-
为什么我们要使用爬虫?
![]()
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
像电商网站(比如亚马逊、淘宝)每天都会有大量的商品上新和用户评论。而在搜索引擎中,随便搜索一个热门关键词,比如“智能手机”,就能找到成千上万条相关的网页信息。
面对如此庞大的信息量,我们如何从中找到对我们有用的信息呢?
答案自然是筛选,那你作为用户,又没有权力直接进入人家数据库去筛选。那咋办呢?
那就需要用到我们的 “爬虫” 了
尽管网络爬虫这个名字听起来有点怪异,让人联想到那些软软蠕动的小生物,但它实际上是一个在网络世界中非常强大的工具。
网络爬虫可以帮助我们在海量的信息中快速找到我们需要的内容,为我们提供决策支持和有用的数据。
-
如何快速制作一个爬虫(Python)
![]()
1.安装环境
首先第一步,那肯定是要先安装python环境了,类似的教程网上有很多,在这里我就不介绍了。
2.安装依赖库
pip install beautifulsoup4比如我的文件夹在,这个路径下,那么我在这个路径下运行cmd,输入上面的命令
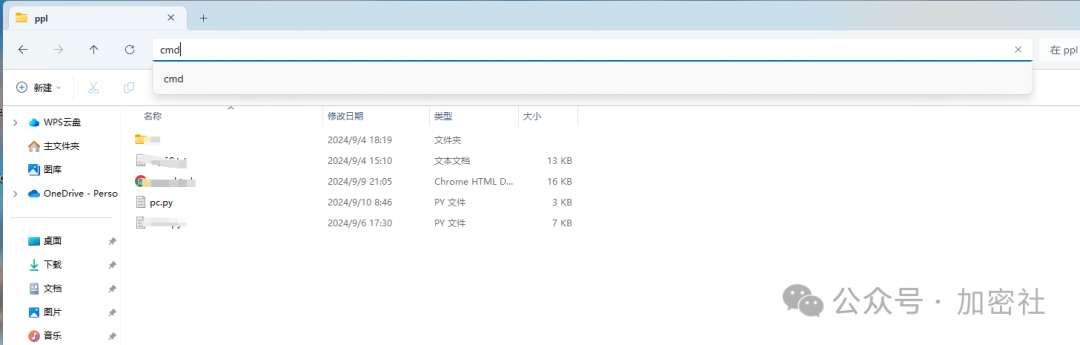
一旦安装完成,你就可以开始使用 BeautifulSoup 来解析 HTML 文档了。
3.选择要爬取的网站,并提取HTML
我在这举个例子,大家就能看懂了。
-
爬取某区块链资讯网站
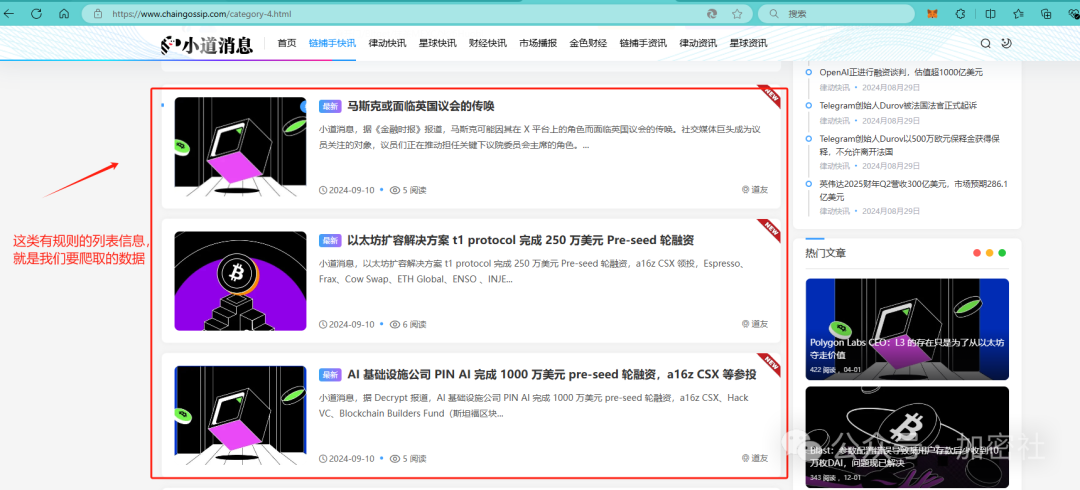
在网页上按F12进入开发者调试模式
利用HTML选择器,找到这块的HTML
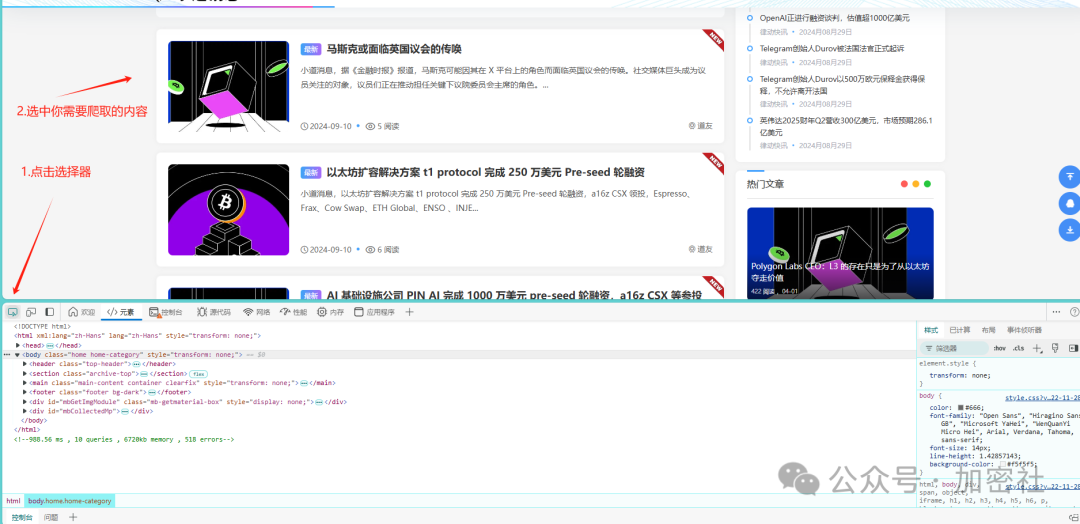
那在这里可以看到,article标签就是我们要找的这一类的HTML

如果要优化的话,可以更深层次的往下去找,
例如这个div,每个article标签下都存在于这样的DIV,那么事情就简单了
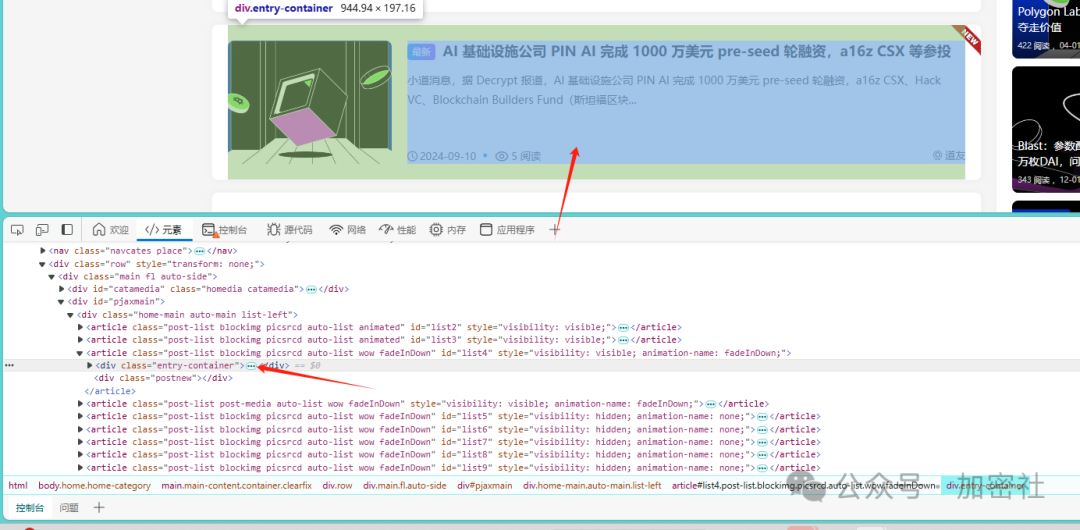
鼠标放在刚才的div上,右键,编辑为html
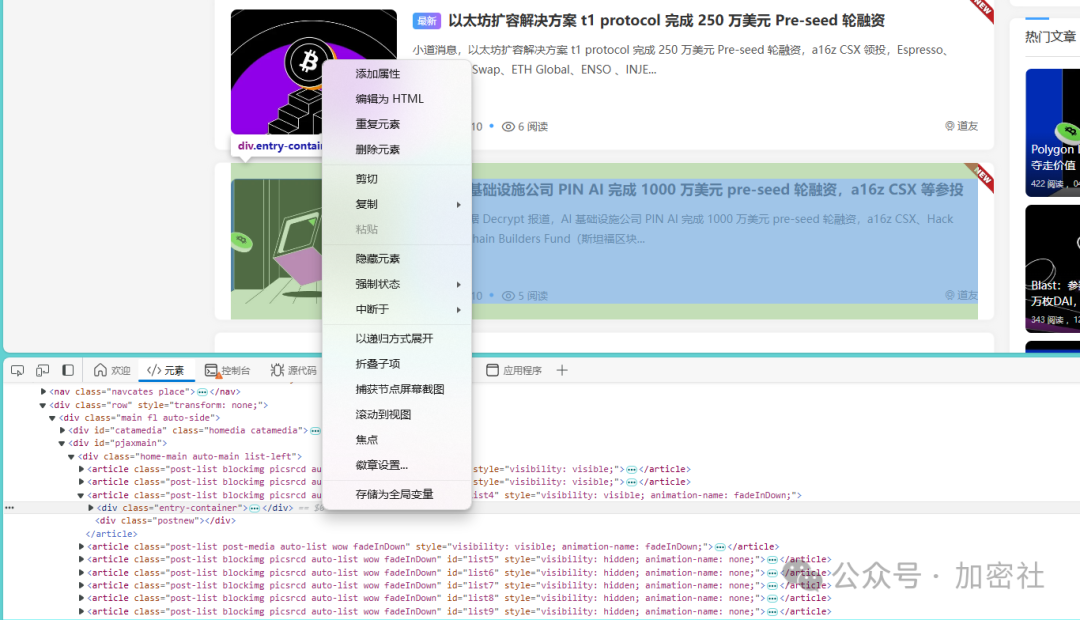
把里面的东西全复制出来,类似于这样的结构

原封不动的,去找AI,我是这样问的


于是乎,AI就生成了一个爬虫的原型,对于不同的网站来说,HTML结构不同,但是AI也能处理的非常好。
如果它生成的脚本不对,你还可以把python内报错的信息发给他,他会重新给你生成一遍,一般来说,3次左右,就能生成一个完整无缺的,针对于你指定网站,指定内容的网站脚本。