Python 中混淆矩阵的热图

欢迎来到雲闪世界。混淆矩阵是一种方便的方式来呈现机器学习模型所犯的错误类型。它是一个带有数字的N x N网格,其中 [n, m] 单元格中的值表示注释为第 n 个类被识别为第 m 个类的示例数。在本教程中,我将重点介绍如何创建混淆矩阵和热图。调色板将用于显示不同组的大小,从而很容易注意到组大小的相似性或显著差异。当您处理大量类别时,这种可视化非常方便。
以下是混淆矩阵元素的直观解释。
请记住,用于演示混淆矩阵的数据是人工的,并不代表任何真实的分类模型。
现在,我将逐步解释如何使用 Python 模块生成这样的混淆矩阵。
Python 最低要求
要创建带有热图的混淆矩阵,您需要三个模块:
pip 安装 scikit-learn、seaborn、pandas假设您有两个预测和真实标签列表,您需要执行以下操作:
- 计算混淆矩阵——
confusion_matrix - 将变量转换为数据框——
pd.DataFrame - 创建热图——
sn.heatmap - 最后,将图保存到文件中 -
cfm_plot.figure.savefig
从sklearn.metrics导入pandas作为pd导入chaos_matrix导入seaborn作为sn如果__name__ == '__main__' : predictions = [ "None","Dog","Cat",...] true_labels = [ "None","Dog","Dog",...] cm = chaos_matrix(true_labels,predictions) df_cfm = pd.DataFrame(cm) cfm_plot = sn.heatmap(df_cfm) cfm_plot.figure.savefig( "data/confusion_matrix_v1.png" )输出如下:
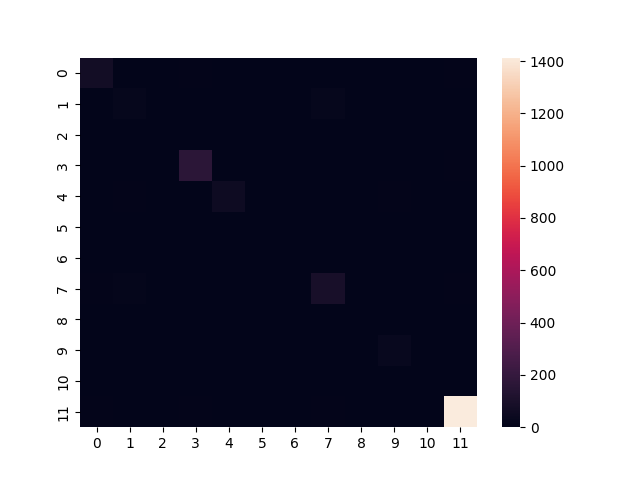
输出结果一点也不令人印象深刻。默认情况下,许多有用的信息和自定义功能被禁用或不适合我们的数据。让我们改进一下图表。
标签
我们需要创建一个包含所有标签的列表来显示这些标签。我们可以使用来自预测和真实标签的信息(第一行)来做到这一点。为了提高可读性并在运行之间保持相同的顺序,我们将多数类(无)作为第一个元素并对剩余的标签进行排序(第二行)。如果没有这个,每次运行代码时标签的顺序可能会有所不同。
接下来,我们将添加到方法labels=label_names中confusion_matrix,并将index=label_names, columns=label_names添加到数据框的构造函数中。
label_names =列表(设置([] + predictions + true_labels))
label_names = [ “None” ] + sorted([a for a in label_names if a != “None” ])
cm = chaos_matrix(true_labels,predictions,labels=label_names)
df_cfm = pd.DataFrame(cm,index=label_names,columns=label_names)
cfm_plot = sn.heatmap(df_cfm)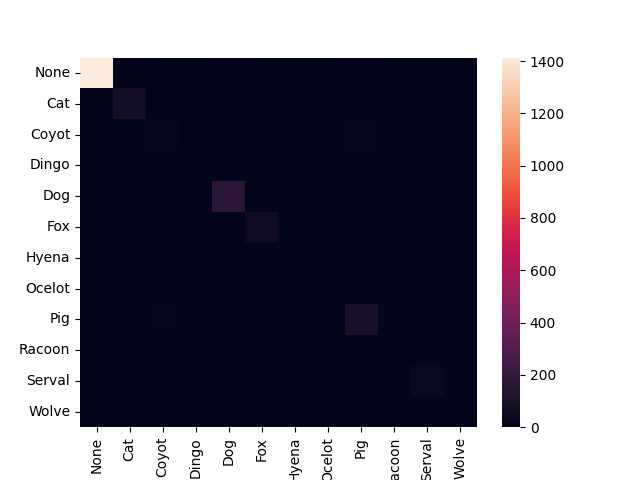
图片来自作者
我们可以看到标签的一个问题。Y 轴上的标签被部分截断。为了解决这个问题,我们可以使用 增加绘图画布figsize。
cm = 混淆矩阵(true_labels,预测,标签=标签名称)
df_cfm = pd.DataFrame(cm,索引=标签名称,列=标签名称)
plt.figure(figsize=(10,7))
cfm_plot = sn.heatmap(df_cfm)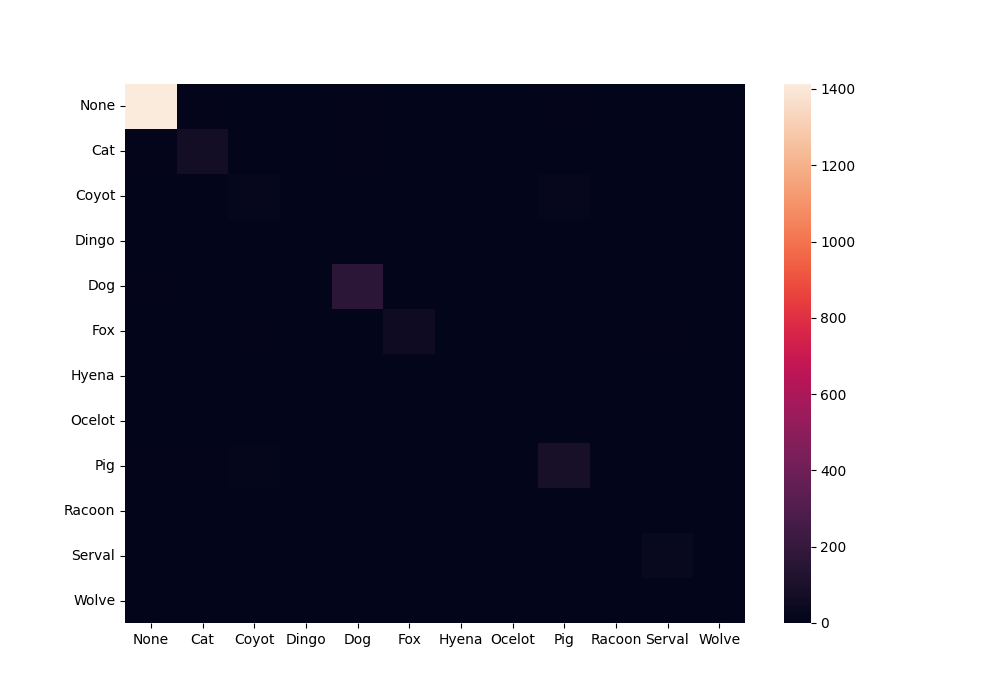
图片来自作者
价值观
在下一步中,我们将为每个单元格显示一个值。这是观察每对类别的确切错误数量的便捷方法。我们将使用annot该heatmap方法的参数来显示值。它采用与我们的混淆矩阵具有相同维度的数据框。因此,我们可以再次传递相同的数据框,即df_cfm。
cm = confused_matrix(true_labels, predictions, labels=label_names)
df_cfm = pd.DataFrame(cm, index=label_names, columns=label_names)
plt.figure(figsize=( 10 , 7 ))
cfm_plot = sn.heatmap(df_cfm, annot=df_cfm)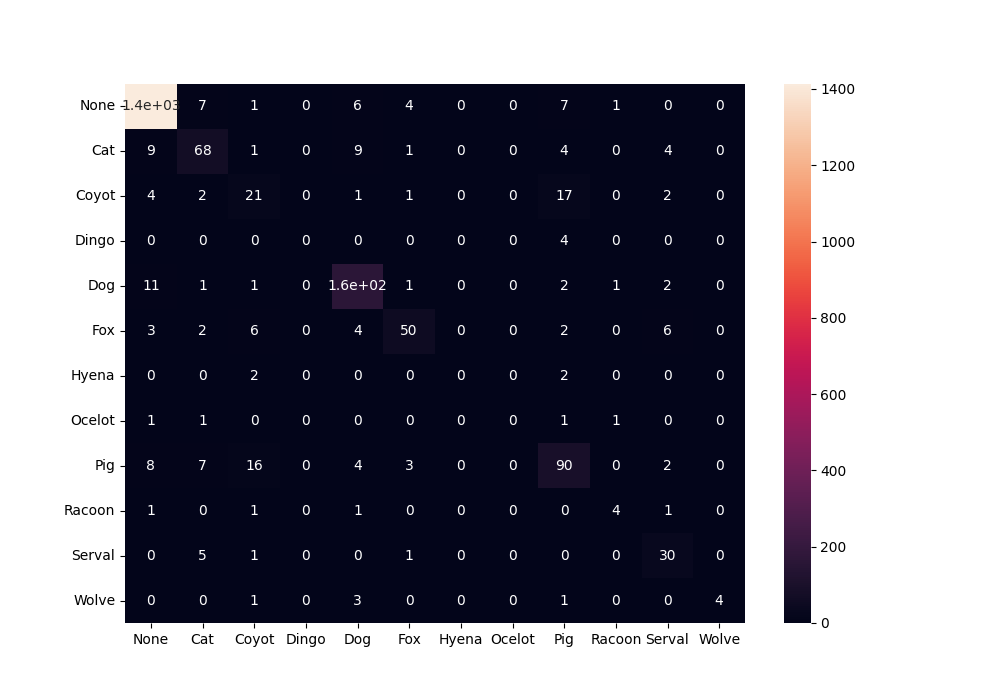
我们可以看到确切的值,但该图有两个问题。第一个是显示大数字的方式很奇怪,另一个是 0 的数量太多,导致图难以阅读。
为了解决显示数字的问题,我们将使用参数将添加注释时使用的默认字符串格式代码从.2g空更改为空fmt。
cm = confused_matrix(true_labels, predictions, labels=label_names)
df_cfm = pd.DataFrame(cm, index=label_names, columns=label_names)
plt.figure(figsize=(10, 7))
cfm_plot = sn.heatmap(df_cfm, annot=df_cfm, fmt= "" )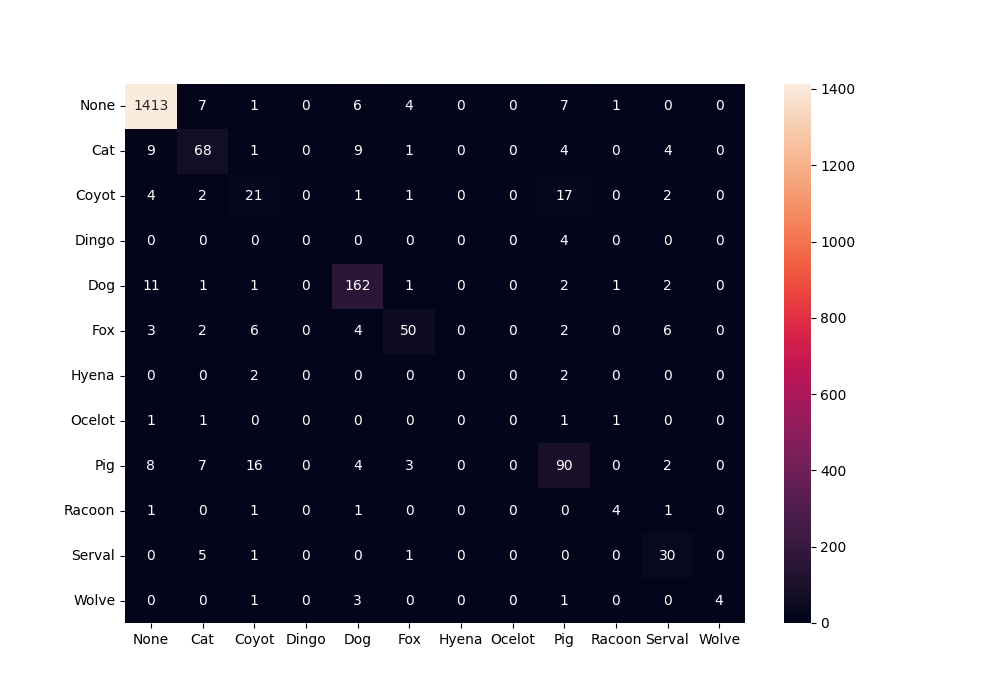
为了隐藏 0,我们将复制数据框并用空字符串替换每个 0。
cm =fusion_matrix(true_labels,predictions,labels=label_names)
df_cfm = pd.DataFrame(cm,index=label_names,columns=label_names)
plt.figure(figsize=(10,7 )) cell_value
= df_cfm.applymap(lambda v:v if v else “”)
cfm_plot = sn.heatmap(df_cfm,annot=cell_value,fmt= “”)
cfm_plot.figure.savefig(“data/confusion_matrix_v6.png”)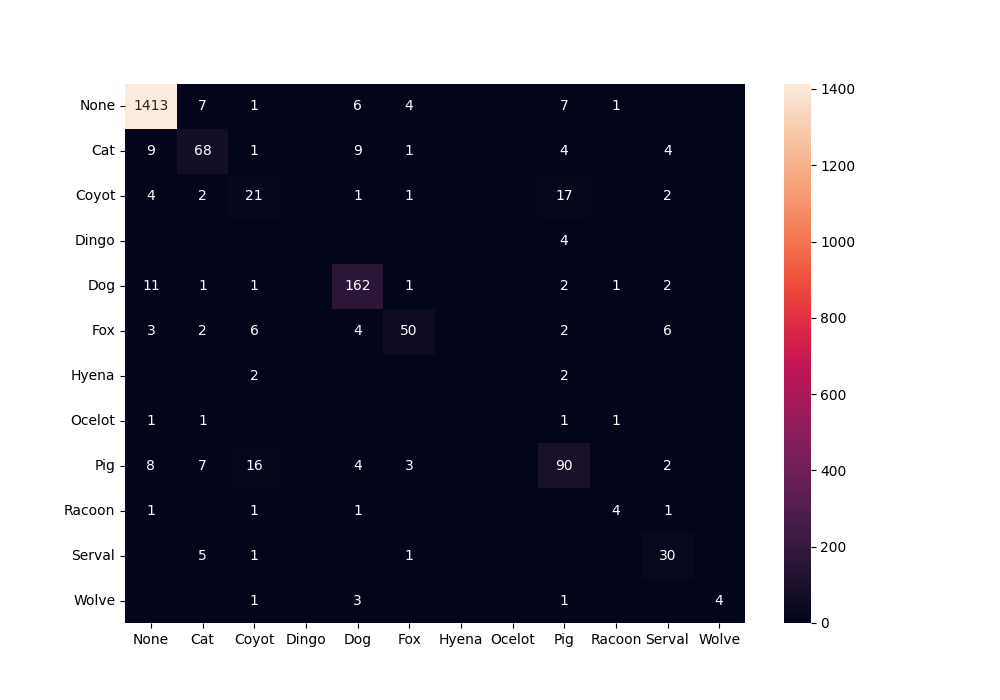
比例和颜色
热图的理念是使用颜色来使值在视觉上多样化。在我们的例子中,我们只能看到一个不同的值,即 None 类的真阳性数,其他类(狗和猪)也是如此,而其余类别看起来相同。问题是我们的值的范围从 0 到 1413,其中大多数值接近 0。为了使值更容易分散注意力,我们可以将颜色的比例从线性更改为对数。可以使用参数norm并将其设置为来完成LogNorm()。
cm = confused_matrix(true_labels, predictions, labels=label_names)
df_cfm = pd.DataFrame(cm, index=label_names, columns=label_names)
plt.figure(figsize=( 10 , 7 ))
cell_value = df_cfm.applymap( lambda v: v if v else "" )
cfm_plot = sn.heatmap(df_cfm, annot=cell_value, fmt= "" , norm=LogNorm())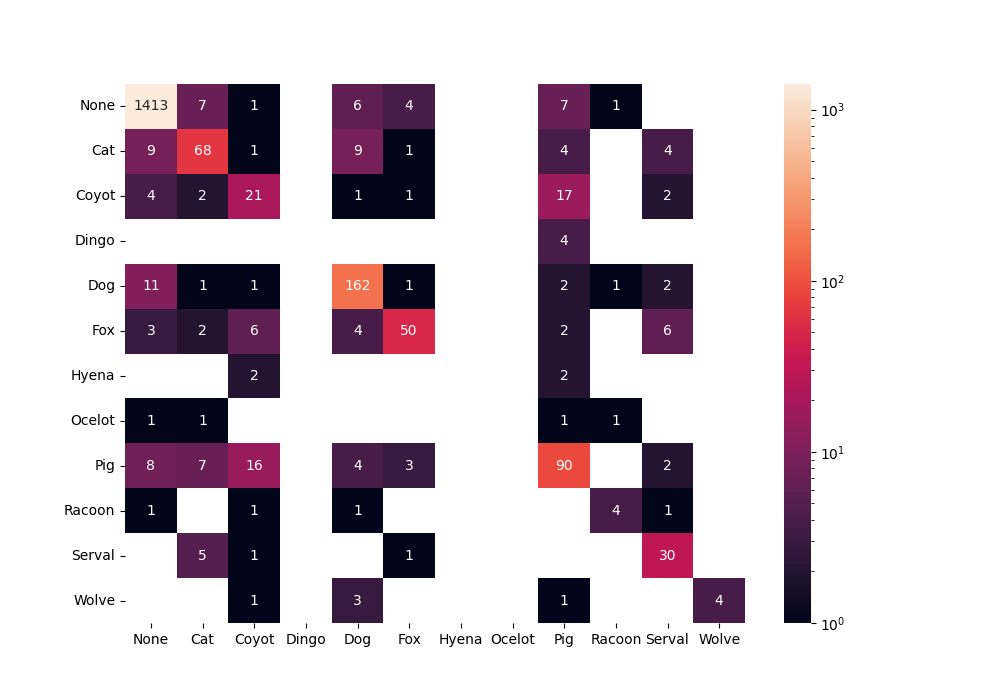
图片来自作者
使用对数标度的颜色,绘图看起来会好得多。删除空单元格后,由于干扰较少,更容易分析非空单元格。在某些情况下,跟踪行和列可能很棘手。为了解决这个问题,我们可以使用linewidth和linecolor参数添加垂直线和水平线。
cm = confused_matrix(true_labels, predictions, labels=label_names)
df_cfm = pd.DataFrame(cm, index=label_names, columns=label_names)
plt.figure(figsize=(10, 7))
cell_value = df_cfm.applymap(lambda v: v if v else "" )
cfm_plot = sn.heatmap(df_cfm, annot=cell_value, fmt= "" , norm=LogNorm(),
linewidths=0.5, linecolor= "grey" )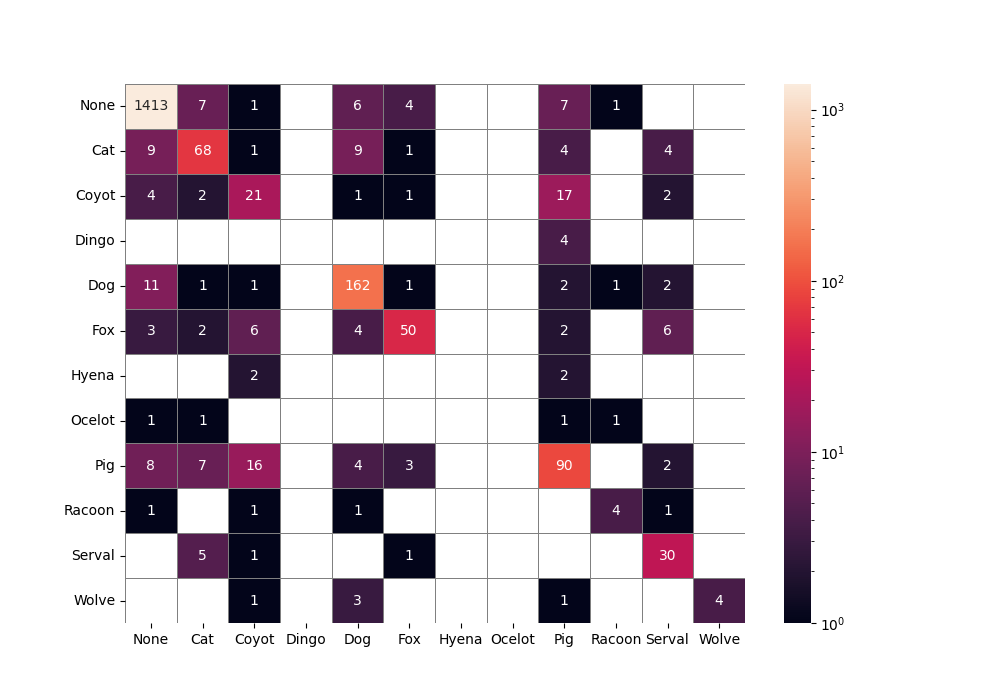
图片来自作者
最后一步是选择首选调色板。Seaborn 有几个现成的调色板,如下所示:Choosing color palettes — seaborn 0.13.2 documentation。要更改调色板,请将调色板的名称提供给参数cmap。以下是使用调色板的示例crest。
cm = chaos_matrix(true_labels, predictions, labels=label_names)
df_cfm = pd.DataFrame(cm, index=label_names, columns=label_names)
plt.figure(figsize=( 10 , 7 ))
cell_value = df_cfm.applymap( lambda v: v if v else "" )
cfm_plot = sn.heatmap(df_cfm, annot=cell_value, fmt= "" , norm=LogNorm(),
linewidths= 0.5 , linecolor= "grey" , cmap= "crest" )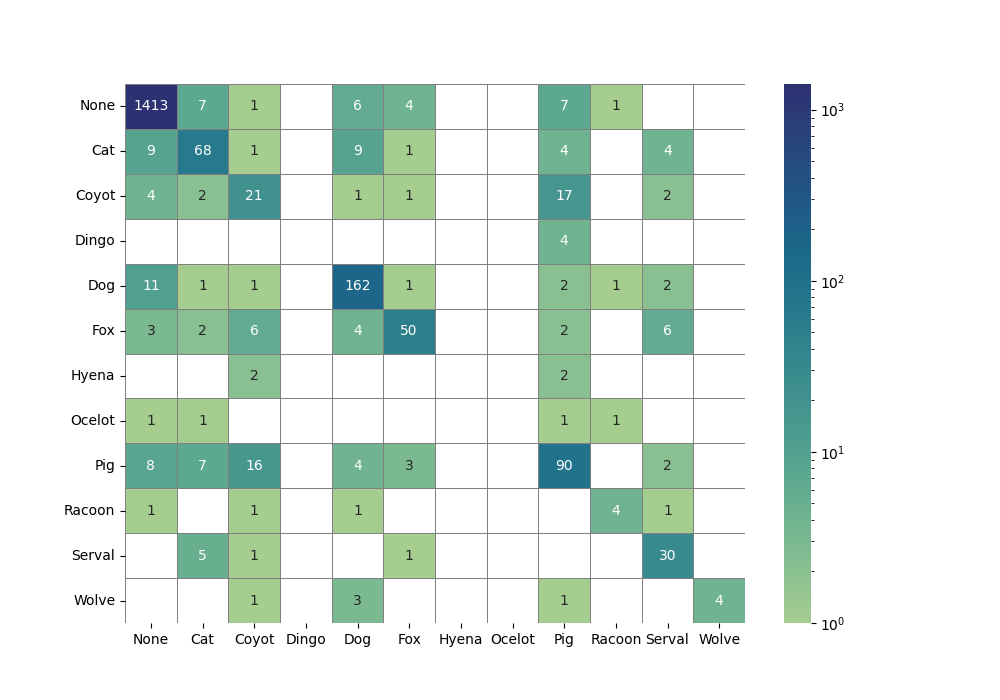
以下是一些其他调色板的示例:
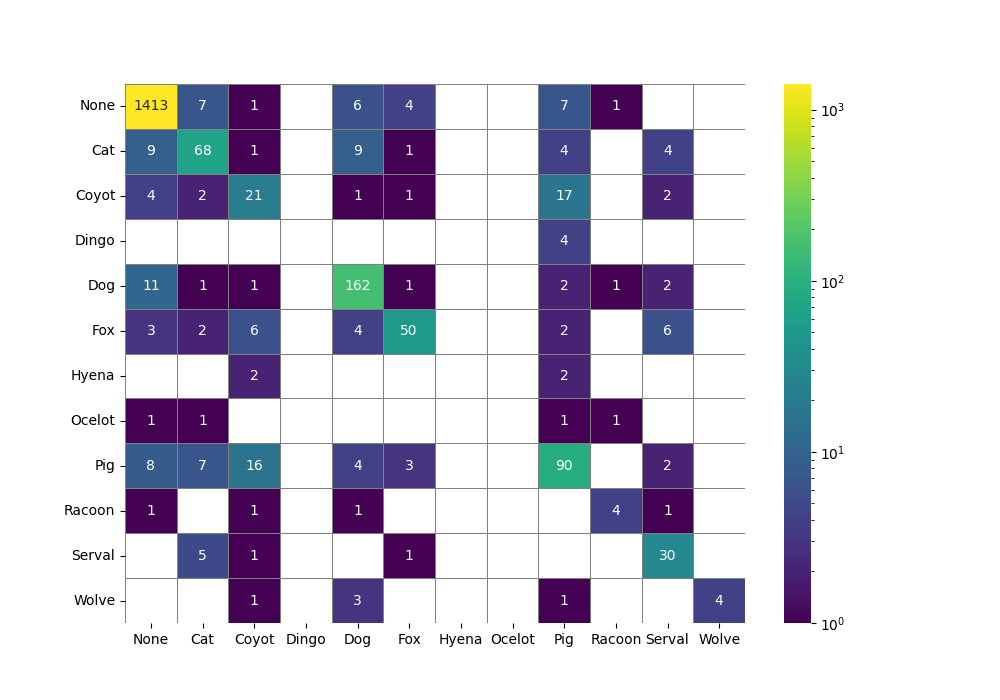
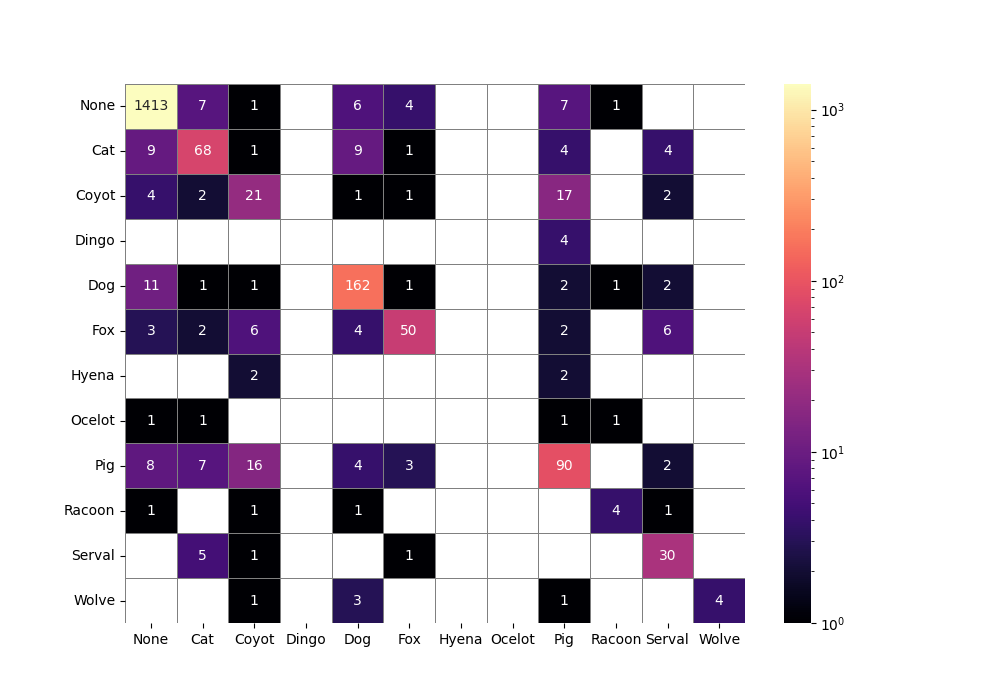
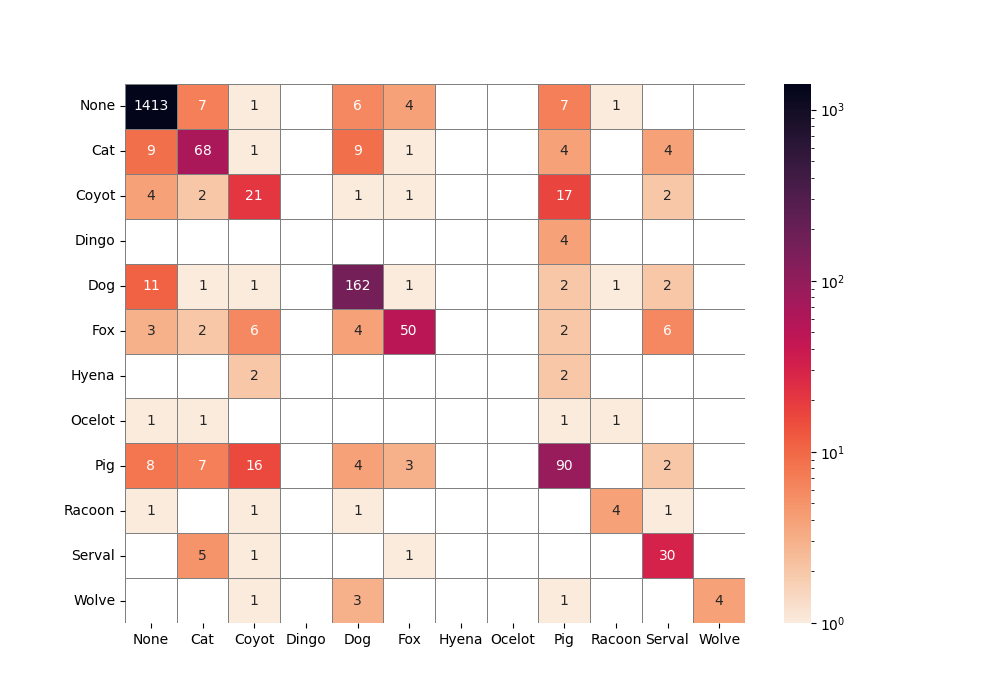
结论
玩弄颜色和格式似乎很浪费时间,因为数字才是最重要的。然而,正确的图表可能会显著提高我们数据的可读性和可访问性,尤其是当我们向不像我们那么熟悉这些数据的客户展示数据时。花点时间弄清楚是否有更好的方式来呈现原始数据和分析见解是值得的。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)